 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Encoding of Graphics Primitives with Simplex-based Structures
Nov 26, 2023
Grid-based structures are commonly used to encode explicit features for graphics primitives such as images, signed distance functions (SDF), and neural radiance fields (NeRF) due to their simple implementation. However, in $n$-dimensional space, calculating the value of a sampled point requires interpolating the values of its $2^n$ neighboring vertices. The exponential scaling with dimension leads to significant computational overheads. To address this issue, we propose a simplex-based approach for encoding graphics primitives. The number of vertices in a simplex-based structure increases linearly with dimension, making it a more efficient and generalizable alternative to grid-based representations. Using the non-axis-aligned simplicial structure property, we derive and prove a coordinate transformation, simplicial subdivision, and barycentric interpolation scheme for efficient sampling, which resembles transformation procedures in the simplex noise algorithm. Finally, we use hash tables to store multiresolution features of all interest points in the simplicial grid, which are passed into a tiny fully connected neural network to parameterize graphics primitives. We implemented a detailed simplex-based structure encoding algorithm in C++ and CUDA using the methods outlined in our approach. In the 2D image fitting task, the proposed method is capable of fitting a giga-pixel image with 9.4% less time compared to the baseline method proposed by instant-ngp, while maintaining the same quality and compression rate. In the volumetric rendering setup, we observe a maximum 41.2% speedup when the samples are dense enough.
On the Adversarial Robustness of Graph Contrastive Learning Methods
Nov 29, 2023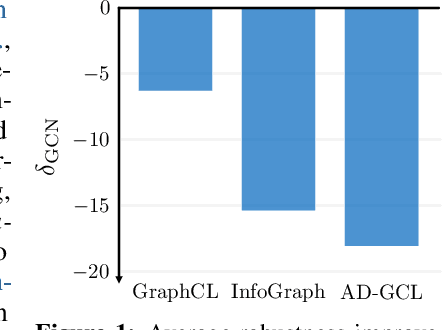
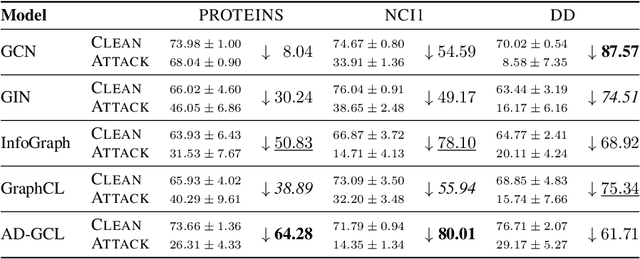
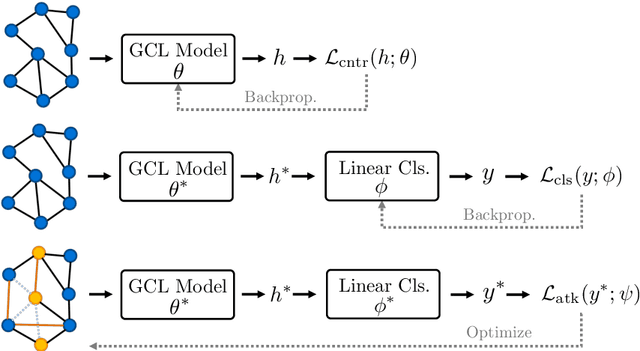
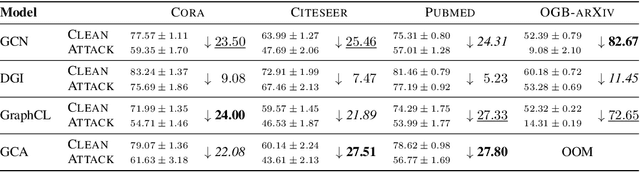
Contrastive learning (CL) has emerged as a powerful framework for learning representations of images and text in a self-supervised manner while enhancing model robustness against adversarial attacks. More recently, researchers have extended the principles of contrastive learning to graph-structured data, giving birth to the field of graph contrastive learning (GCL). However, whether GCL methods can deliver the same advantages in adversarial robustness as their counterparts in the image and text domains remains an open question. In this paper, we introduce a comprehensive robustness evaluation protocol tailored to assess the robustness of GCL models. We subject these models to adaptive adversarial attacks targeting the graph structure, specifically in the evasion scenario. We evaluate node and graph classification tasks using diverse real-world datasets and attack strategies. With our work, we aim to offer insights into the robustness of GCL methods and hope to open avenues for potential future research directions.
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
Nov 29, 2023


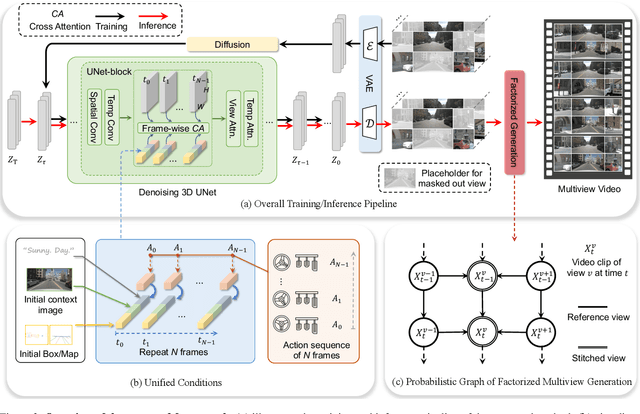
In autonomous driving, predicting future events in advance and evaluating the foreseeable risks empowers autonomous vehicles to better plan their actions, enhancing safety and efficiency on the road. To this end, we propose Drive-WM, the first driving world model compatible with existing end-to-end planning models. Through a joint spatial-temporal modeling facilitated by view factorization, our model generates high-fidelity multiview videos in driving scenes. Building on its powerful generation ability, we showcase the potential of applying the world model for safe driving planning for the first time. Particularly, our Drive-WM enables driving into multiple futures based on distinct driving maneuvers, and determines the optimal trajectory according to the image-based rewards. Evaluation on real-world driving datasets verifies that our method could generate high-quality, consistent, and controllable multiview videos, opening up possibilities for real-world simulations and safe planning.
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
Heterogeneous Graph-based Trajectory Prediction using Local Map Context and Social Interactions
Nov 30, 2023Precisely predicting the future trajectories of surrounding traffic participants is a crucial but challenging problem in autonomous driving, due to complex interactions between traffic agents, map context and traffic rules. Vector-based approaches have recently shown to achieve among the best performances on trajectory prediction benchmarks. These methods model simple interactions between traffic agents but don't distinguish between relation-type and attributes like their distance along the road. Furthermore, they represent lanes only by sequences of vectors representing center lines and ignore context information like lane dividers and other road elements. We present a novel approach for vector-based trajectory prediction that addresses these shortcomings by leveraging three crucial sources of information: First, we model interactions between traffic agents by a semantic scene graph, that accounts for the nature and important features of their relation. Second, we extract agent-centric image-based map features to model the local map context. Finally, we generate anchor paths to enforce the policy in multi-modal prediction to permitted trajectories only. Each of these three enhancements shows advantages over the baseline model HoliGraph.
Seg2Reg: Differentiable 2D Segmentation to 1D Regression Rendering for 360 Room Layout Reconstruction
Nov 30, 2023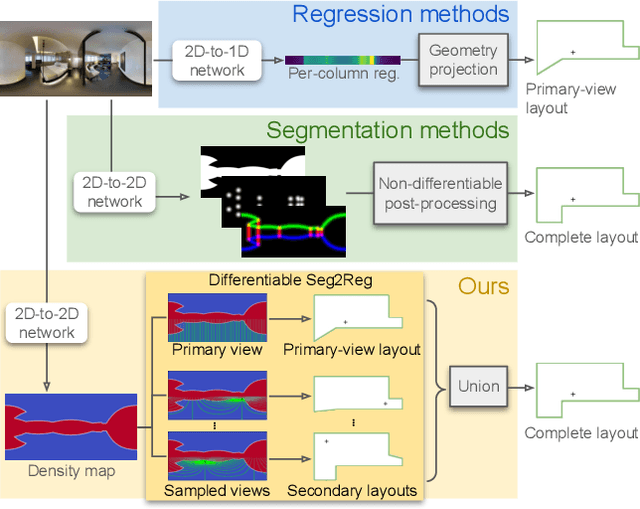
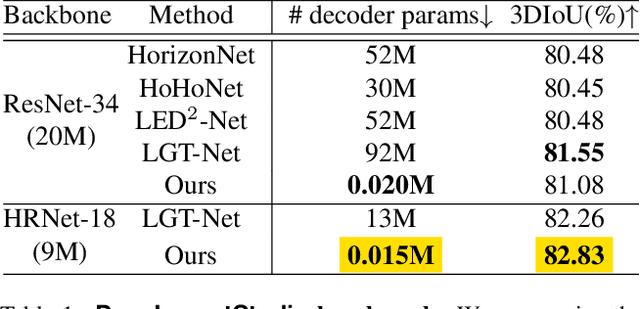

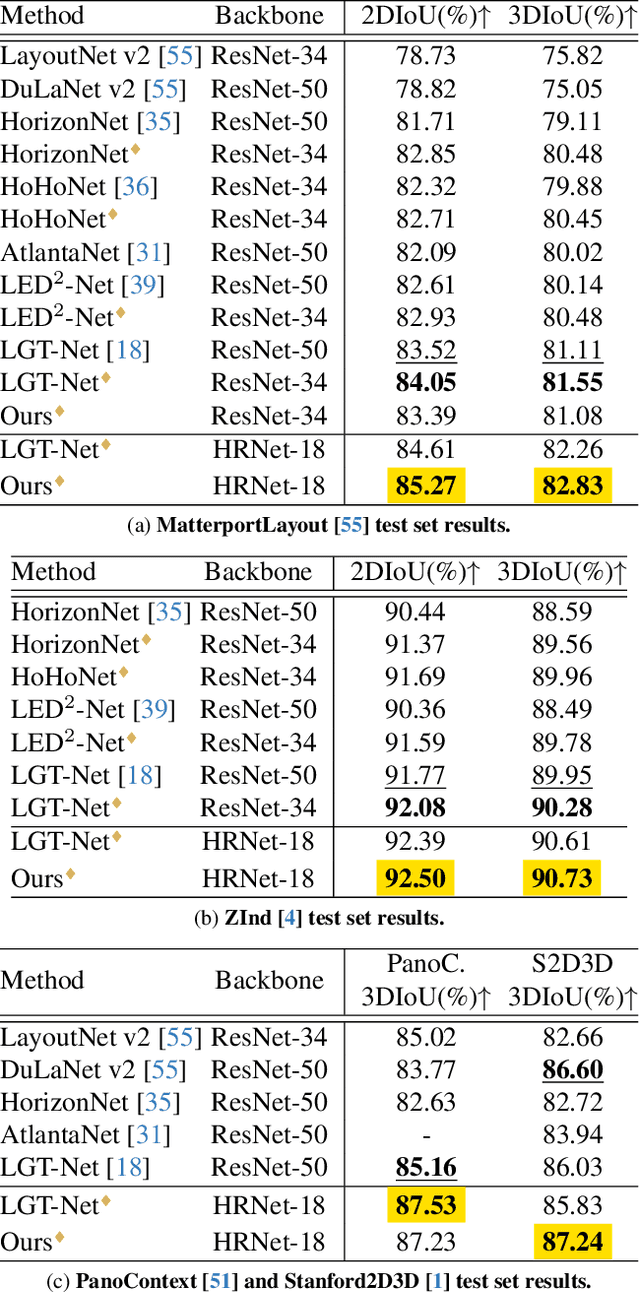
State-of-the-art single-view 360-degree room layout reconstruction methods formulate the problem as a high-level 1D (per-column) regression task. On the other hand, traditional low-level 2D layout segmentation is simpler to learn and can represent occluded regions, but it requires complex post-processing for the targeting layout polygon and sacrifices accuracy. We present Seg2Reg to render 1D layout depth regression from the 2D segmentation map in a differentiable and occlusion-aware way, marrying the merits of both sides. Specifically, our model predicts floor-plan density for the input equirectangular 360-degree image. Formulating the 2D layout representation as a density field enables us to employ `flattened' volume rendering to form 1D layout depth regression. In addition, we propose a novel 3D warping augmentation on layout to improve generalization. Finally, we re-implement recent room layout reconstruction methods into our codebase for benchmarking and explore modern backbones and training techniques to serve as the strong baseline. Our model significantly outperforms previous arts. The code will be made available upon publication.
X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning
Nov 30, 2023Vision-language pre-training and instruction tuning have demonstrated general-purpose capabilities in 2D visual reasoning tasks by aligning visual encoders with state-of-the-art large language models (LLMs). In this paper, we introduce a simple, yet effective, cross-modality framework built atop frozen LLMs that allows the integration of various modalities without extensive modality-specific customization. To facilitate instruction-modality fine-tuning, we collect high-quality instruction tuning data in an automatic and scalable manner, composed of 24K QA samples for audio and 250K QA samples for 3D. Leveraging instruction-aware representations, our model performs comparably with leading-edge counterparts without the need of extensive modality-specific pre-training or customization. Furthermore, our approach demonstrates cross-modal reasoning abilities across two or more input modalities, despite each modality projection being trained individually. To study the model's cross-modal abilities, we contribute a novel Discriminative Cross-modal Reasoning (DisCRn) evaluation task, comprising 9K audio-video QA samples and 28K image-3D QA samples that require the model to reason discriminatively across disparate input modalities.
Anisotropic Neural Representation Learning for High-Quality Neural Rendering
Nov 30, 2023Neural radiance fields (NeRFs) have achieved impressive view synthesis results by learning an implicit volumetric representation from multi-view images. To project the implicit representation into an image, NeRF employs volume rendering that approximates the continuous integrals of rays as an accumulation of the colors and densities of the sampled points. Although this approximation enables efficient rendering, it ignores the direction information in point intervals, resulting in ambiguous features and limited reconstruction quality. In this paper, we propose an anisotropic neural representation learning method that utilizes learnable view-dependent features to improve scene representation and reconstruction. We model the volumetric function as spherical harmonic (SH)-guided anisotropic features, parameterized by multilayer perceptrons, facilitating ambiguity elimination while preserving the rendering efficiency. To achieve robust scene reconstruction without anisotropy overfitting, we regularize the energy of the anisotropic features during training. Our method is flexiable and can be plugged into NeRF-based frameworks. Extensive experiments show that the proposed representation can boost the rendering quality of various NeRFs and achieve state-of-the-art rendering performance on both synthetic and real-world scenes.
Label-efficient Training of Small Task-specific Models by Leveraging Vision Foundation Models
Nov 30, 2023Large Vision Foundation Models (VFMs) pretrained on massive datasets exhibit impressive performance on various downstream tasks, especially with limited labeled target data. However, due to their high memory and compute requirements, these models cannot be deployed in resource constrained settings. This raises an important question: How can we utilize the knowledge from a large VFM to train a small task-specific model for a new target task with limited labeled training data? In this work, we answer this question by proposing a simple and highly effective task-oriented knowledge transfer approach to leverage pretrained VFMs for effective training of small task-specific models. Our experimental results on four target tasks under limited labeled data settings show that the proposed knowledge transfer approach outperforms task-agnostic VFM distillation, web-scale CLIP pretraining and supervised ImageNet pretraining by 1-10.5%, 2-22% and 2-14%, respectively. We also show that the dataset used for transferring knowledge has a significant effect on the final target task performance, and propose an image retrieval-based approach for curating effective transfer sets.
Universal Backdoor Attacks
Nov 30, 2023Web-scraped datasets are vulnerable to data poisoning, which can be used for backdooring deep image classifiers during training. Since training on large datasets is expensive, a model is trained once and re-used many times. Unlike adversarial examples, backdoor attacks often target specific classes rather than any class learned by the model. One might expect that targeting many classes through a naive composition of attacks vastly increases the number of poison samples. We show this is not necessarily true and more efficient, universal data poisoning attacks exist that allow controlling misclassifications from any source class into any target class with a small increase in poison samples. Our idea is to generate triggers with salient characteristics that the model can learn. The triggers we craft exploit a phenomenon we call inter-class poison transferability, where learning a trigger from one class makes the model more vulnerable to learning triggers for other classes. We demonstrate the effectiveness and robustness of our universal backdoor attacks by controlling models with up to 6,000 classes while poisoning only 0.15% of the training dataset.