 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA plug-and-play generative framework for multi-satellite precipitation estimation
May 14, 2026Reliable precipitation monitoring is essential for disaster risk reduction, water resources management, and agricultural decision-making. Multi-source satellite observations, particularly the combination of geostationary infrared and passive microwave measurements, have become a primary means of precipitation detection. Traditional multi-source satellite precipitation estimation methods remain computationally inefficient, and many deep learning methods lack the flexibility to incorporate new sensors without retraining the full model. Here we introduce PRISMA (Precipitation Inference from Satellite Modalities via generAtive modeling), a plug-and-play latent generative framework for multi-sensor precipitation estimation. PRISMA learns an unconditional precipitation prior from IMERG Final fields and constrains it through independently trained, sensor-specific conditional branches, allowing new observation sources to be incorporated without retraining the generative backbone. Applied to FY-4B AGRI infrared and GPM GMI microwave observations, PRISMA improves Critical Success Index by up to 40.3% and reduces root-mean-square error by 22.6% relative to infrared-only estimation within microwave swaths, while also improving probabilistic skill and maintaining an average inference time of about 37 s. Independent rain-gauge validation across China confirms consistent gains, and typhoon case studies show that microwave conditioning restores eyewall and spiral rainband structures, reducing storm-core mean absolute error by up to 42.3%. PRISMA thus provides an extensible and efficient framework for multi-sensor precipitation estimation.
CSPO: Alleviating Reward Ambiguity for Structured Table-to-LaTeX Generation
Apr 13, 2026Tables contain rich structured information, yet when stored as images their contents remain "locked" within pixels. Converting table images into LaTeX code enables faithful digitization and reuse, but current multimodal large language models (MLLMs) often fail to preserve structural, style, or content fidelity. Conventional post-training with reinforcement learning (RL) typically relies on a single aggregated reward, leading to reward ambiguity that conflates multiple behavioral aspects and hinders effective optimization. We propose Component-Specific Policy Optimization (CSPO), an RL framework that disentangles optimization across LaTeX tables components-structure, style, and content. In particular, CSPO assigns component-specific rewards and backpropagates each signal only through the tokens relevant to its component, alleviating reward ambiguity and enabling targeted component-wise optimization. To comprehensively assess performance, we introduce a set of hierarchical evaluation metrics. Extensive experiments demonstrate the effectiveness of CSPO, underscoring the importance of component-specific optimization for reliable structured generation.
Nowcast3D: Reliable precipitation nowcasting via gray-box learning
Nov 06, 2025Extreme precipitation nowcasting demands high spatiotemporal fidelity and extended lead times, yet existing approaches remain limited. Numerical Weather Prediction (NWP) and its deep-learning emulations are too slow and coarse for rapidly evolving convection, while extrapolation and purely data-driven models suffer from error accumulation and excessive smoothing. Hybrid 2D radar-based methods discard crucial vertical information, preventing accurate reconstruction of height-dependent dynamics. We introduce a gray-box, fully three-dimensional nowcasting framework that directly processes volumetric radar reflectivity and couples physically constrained neural operators with datadriven learning. The model learns vertically varying 3D advection fields under a conservative advection operator, parameterizes spatially varying diffusion, and introduces a Brownian-motion--inspired stochastic term to represent unresolved motions. A residual branch captures small-scale convective initiation and microphysical variability, while a diffusion-based stochastic module estimates uncertainty. The framework achieves more accurate forecasts up to three-hour lead time across precipitation regimes and ranked first in 57\% of cases in a blind evaluation by 160 meteorologists. By restoring full 3D dynamics with physical consistency, it offers a scalable and robust pathway for skillful and reliable nowcasting of extreme precipitation.
Debiased Prompt Tuning in Vision-Language Model without Annotations
Mar 11, 2025



Prompt tuning of Vision-Language Models (VLMs) such as CLIP, has demonstrated the ability to rapidly adapt to various downstream tasks. However, recent studies indicate that tuned VLMs may suffer from the problem of spurious correlations, where the model relies on spurious features (e.g. background and gender) in the data. This may lead to the model having worse robustness in out-of-distribution data. Standard methods for eliminating spurious correlation typically require us to know the spurious attribute labels of each sample, which is hard in the real world. In this work, we explore improving the group robustness of prompt tuning in VLMs without relying on manual annotation of spurious features. We notice the zero - shot image recognition ability of VLMs and use this ability to identify spurious features, thus avoiding the cost of manual annotation. By leveraging pseudo-spurious attribute annotations, we further propose a method to automatically adjust the training weights of different groups. Extensive experiments show that our approach efficiently improves the worst-group accuracy on CelebA, Waterbirds, and MetaShift datasets, achieving the best robustness gap between the worst-group accuracy and the overall accuracy.
Debiasing Vison-Language Models with Text-Only Training
Oct 12, 2024



Pre-trained vision-language models (VLMs), such as CLIP, have exhibited remarkable performance across various downstream tasks by aligning text and images in a unified embedding space. However, due to the imbalanced distribution of pre-trained datasets, CLIP suffers from the bias problem in real-world applications. Existing debiasing methods struggle to obtain sufficient image samples for minority groups and incur high costs for group labeling. To address the limitations, we propose a Text-Only Debiasing framework called TOD, leveraging a text-as-image training paradigm to mitigate visual biases. Specifically, this approach repurposes the text encoder to function as an image encoder, thereby eliminating the need for image data. Simultaneously, it utilizes a large language model (LLM) to generate a balanced text dataset, which is then used for prompt tuning. However, we observed that the model overfits to the text modality because label names, serving as supervision signals, appear explicitly in the texts. To address this issue, we further introduce a Multi-Target Prediction (MTP) task that motivates the model to focus on complex contexts and distinguish between target and biased information. Extensive experiments on the Waterbirds and CelebA datasets show that our method significantly improves group robustness, achieving state-of-the-art results among image-free methods and even competitive performance compared to image-supervised methods. Furthermore, the proposed method can be adapted to challenging scenarios with multiple or unknown bias attributes, demonstrating its strong generalization and robustness.
AnyAttack: Towards Large-scale Self-supervised Generation of Targeted Adversarial Examples for Vision-Language Models
Oct 07, 2024



Due to their multimodal capabilities, Vision-Language Models (VLMs) have found numerous impactful applications in real-world scenarios. However, recent studies have revealed that VLMs are vulnerable to image-based adversarial attacks, particularly targeted adversarial images that manipulate the model to generate harmful content specified by the adversary. Current attack methods rely on predefined target labels to create targeted adversarial attacks, which limits their scalability and applicability for large-scale robustness evaluations. In this paper, we propose AnyAttack, a self-supervised framework that generates targeted adversarial images for VLMs without label supervision, allowing any image to serve as a target for the attack. To address the limitation of existing methods that require label supervision, we introduce a contrastive loss that trains a generator on a large-scale unlabeled image dataset, LAION-400M dataset, for generating targeted adversarial noise. This large-scale pre-training endows our method with powerful transferability across a wide range of VLMs. Extensive experiments on five mainstream open-source VLMs (CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4) across three multimodal tasks (image-text retrieval, multimodal classification, and image captioning) demonstrate the effectiveness of our attack. Additionally, we successfully transfer AnyAttack to multiple commercial VLMs, including Google's Gemini, Claude's Sonnet, and Microsoft's Copilot. These results reveal an unprecedented risk to VLMs, highlighting the need for effective countermeasures.
Efficient Encoding of Graphics Primitives with Simplex-based Structures
Nov 26, 2023Grid-based structures are commonly used to encode explicit features for graphics primitives such as images, signed distance functions (SDF), and neural radiance fields (NeRF) due to their simple implementation. However, in $n$-dimensional space, calculating the value of a sampled point requires interpolating the values of its $2^n$ neighboring vertices. The exponential scaling with dimension leads to significant computational overheads. To address this issue, we propose a simplex-based approach for encoding graphics primitives. The number of vertices in a simplex-based structure increases linearly with dimension, making it a more efficient and generalizable alternative to grid-based representations. Using the non-axis-aligned simplicial structure property, we derive and prove a coordinate transformation, simplicial subdivision, and barycentric interpolation scheme for efficient sampling, which resembles transformation procedures in the simplex noise algorithm. Finally, we use hash tables to store multiresolution features of all interest points in the simplicial grid, which are passed into a tiny fully connected neural network to parameterize graphics primitives. We implemented a detailed simplex-based structure encoding algorithm in C++ and CUDA using the methods outlined in our approach. In the 2D image fitting task, the proposed method is capable of fitting a giga-pixel image with 9.4% less time compared to the baseline method proposed by instant-ngp, while maintaining the same quality and compression rate. In the volumetric rendering setup, we observe a maximum 41.2% speedup when the samples are dense enough.
Promoting Open-domain Dialogue Generation through Learning Pattern Information between Contexts and Responses
Sep 06, 2023



Recently, utilizing deep neural networks to build the opendomain dialogue models has become a hot topic. However, the responses generated by these models suffer from many problems such as responses not being contextualized and tend to generate generic responses that lack information content, damaging the user's experience seriously. Therefore, many studies try introducing more information into the dialogue models to make the generated responses more vivid and informative. Unlike them, this paper improves the quality of generated responses by learning the implicit pattern information between contexts and responses in the training samples. In this paper, we first build an open-domain dialogue model based on the pre-trained language model (i.e., GPT-2). And then, an improved scheduled sampling method is proposed for pre-trained models, by which the responses can be used to guide the response generation in the training phase while avoiding the exposure bias problem. More importantly, we design a response-aware mechanism for mining the implicit pattern information between contexts and responses so that the generated replies are more diverse and approximate to human replies. Finally, we evaluate the proposed model (RAD) on the Persona-Chat and DailyDialog datasets; and the experimental results show that our model outperforms the baselines on most automatic and manual metrics.
Towards Black-box Adversarial Example Detection: A Data Reconstruction-based Method
Jun 03, 2023



Adversarial example detection is known to be an effective adversarial defense method. Black-box attack, which is a more realistic threat and has led to various black-box adversarial training-based defense methods, however, does not attract considerable attention in adversarial example detection. In this paper, we fill this gap by positioning the problem of black-box adversarial example detection (BAD). Data analysis under the introduced BAD settings demonstrates (1) the incapability of existing detectors in addressing the black-box scenario and (2) the potential of exploring BAD solutions from a data perspective. To tackle the BAD problem, we propose a data reconstruction-based adversarial example detection method. Specifically, we use variational auto-encoder (VAE) to capture both pixel and frequency representations of normal examples. Then we use reconstruction error to detect adversarial examples. Compared with existing detection methods, the proposed method achieves substantially better detection performance in BAD, which helps promote the deployment of adversarial example detection-based defense solutions in real-world models.
Local Binary Pattern Networks
Mar 22, 2018
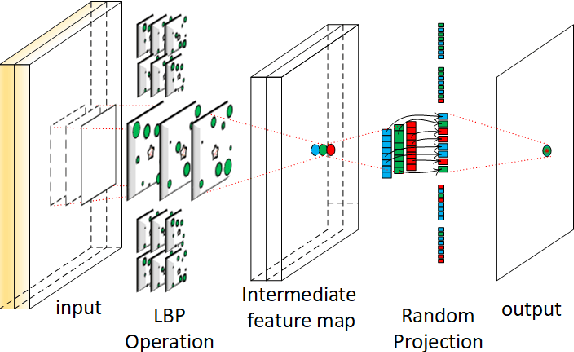
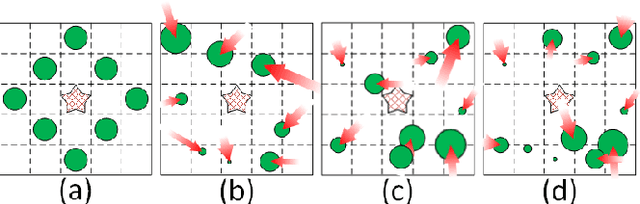
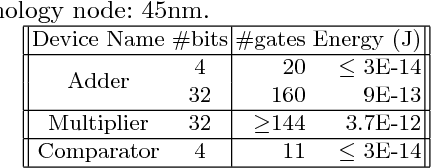
Memory and computation efficient deep learning architec- tures are crucial to continued proliferation of machine learning capabili- ties to new platforms and systems. Binarization of operations in convo- lutional neural networks has shown promising results in reducing model size and computing efficiency. In this paper, we tackle the problem us- ing a strategy different from the existing literature by proposing local binary pattern networks or LBPNet, that is able to learn and perform binary operations in an end-to-end fashion. LBPNet1 uses local binary comparisons and random projection in place of conventional convolu- tion (or approximation of convolution) operations. These operations can be implemented efficiently on different platforms including direct hard- ware implementation. We applied LBPNet and its variants on standard benchmarks. The results are promising across benchmarks while provid- ing an important means to improve memory and speed efficiency that is particularly suited for small footprint devices and hardware accelerators.