 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse2DGS: Sparse-View Surface Reconstruction using 2D Gaussian Splatting with Dense Point Cloud
May 26, 2025Gaussian Splatting (GS) has gained attention as a fast and effective method for novel view synthesis. It has also been applied to 3D reconstruction using multi-view images and can achieve fast and accurate 3D reconstruction. However, GS assumes that the input contains a large number of multi-view images, and therefore, the reconstruction accuracy significantly decreases when only a limited number of input images are available. One of the main reasons is the insufficient number of 3D points in the sparse point cloud obtained through Structure from Motion (SfM), which results in a poor initialization for optimizing the Gaussian primitives. We propose a new 3D reconstruction method, called Sparse2DGS, to enhance 2DGS in reconstructing objects using only three images. Sparse2DGS employs DUSt3R, a fundamental model for stereo images, along with COLMAP MVS to generate highly accurate and dense 3D point clouds, which are then used to initialize 2D Gaussians. Through experiments on the DTU dataset, we show that Sparse2DGS can accurately reconstruct the 3D shapes of objects using just three images.
OB3D: A New Dataset for Benchmarking Omnidirectional 3D Reconstruction Using Blender
May 26, 2025



Recent advancements in radiance field rendering, exemplified by Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have significantly progressed 3D modeling and reconstruction. The use of multiple 360-degree omnidirectional images for these tasks is increasingly favored due to advantages in data acquisition and comprehensive scene capture. However, the inherent geometric distortions in common omnidirectional representations, such as equirectangular projection (particularly severe in polar regions and varying with latitude), pose substantial challenges to achieving high-fidelity 3D reconstructions. Current datasets, while valuable, often lack the specific focus, scene composition, and ground truth granularity required to systematically benchmark and drive progress in overcoming these omnidirectional-specific challenges. To address this critical gap, we introduce Omnidirectional Blender 3D (OB3D), a new synthetic dataset curated for advancing 3D reconstruction from multiple omnidirectional images. OB3D features diverse and complex 3D scenes generated from Blender 3D projects, with a deliberate emphasis on challenging scenarios. The dataset provides comprehensive ground truth, including omnidirectional RGB images, precise omnidirectional camera parameters, and pixel-aligned equirectangular maps for depth and normals, alongside evaluation metrics. By offering a controlled yet challenging environment, OB3Daims to facilitate the rigorous evaluation of existing methods and prompt the development of new techniques to enhance the accuracy and reliability of 3D reconstruction from omnidirectional images.
ErpGS: Equirectangular Image Rendering enhanced with 3D Gaussian Regularization
May 26, 2025



The use of multi-view images acquired by a 360-degree camera can reconstruct a 3D space with a wide area. There are 3D reconstruction methods from equirectangular images based on NeRF and 3DGS, as well as Novel View Synthesis (NVS) methods. On the other hand, it is necessary to overcome the large distortion caused by the projection model of a 360-degree camera when equirectangular images are used. In 3DGS-based methods, the large distortion of the 360-degree camera model generates extremely large 3D Gaussians, resulting in poor rendering accuracy. We propose ErpGS, which is Omnidirectional GS based on 3DGS to realize NVS addressing the problems. ErpGS introduce some rendering accuracy improvement techniques: geometric regularization, scale regularization, and distortion-aware weights and a mask to suppress the effects of obstacles in equirectangular images. Through experiments on public datasets, we demonstrate that ErpGS can render novel view images more accurately than conventional methods.
EigenGS Representation: From Eigenspace to Gaussian Image Space
Mar 10, 2025Principal Component Analysis (PCA), a classical dimensionality reduction technique, and 2D Gaussian representation, an adaptation of 3D Gaussian Splatting for image representation, offer distinct approaches to modeling visual data. We present EigenGS, a novel method that bridges these paradigms through an efficient transformation pipeline connecting eigenspace and image-space Gaussian representations. Our approach enables instant initialization of Gaussian parameters for new images without requiring per-image optimization from scratch, dramatically accelerating convergence. EigenGS introduces a frequency-aware learning mechanism that encourages Gaussians to adapt to different scales, effectively modeling varied spatial frequencies and preventing artifacts in high-resolution reconstruction. Extensive experiments demonstrate that EigenGS not only achieves superior reconstruction quality compared to direct 2D Gaussian fitting but also reduces necessary parameter count and training time. The results highlight EigenGS's effectiveness and generalization ability across images with varying resolutions and diverse categories, making Gaussian-based image representation both high-quality and viable for real-time applications.
Segment Anything, Even Occluded
Mar 08, 2025Amodal instance segmentation, which aims to detect and segment both visible and invisible parts of objects in images, plays a crucial role in various applications including autonomous driving, robotic manipulation, and scene understanding. While existing methods require training both front-end detectors and mask decoders jointly, this approach lacks flexibility and fails to leverage the strengths of pre-existing modal detectors. To address this limitation, we propose SAMEO, a novel framework that adapts the Segment Anything Model (SAM) as a versatile mask decoder capable of interfacing with various front-end detectors to enable mask prediction even for partially occluded objects. Acknowledging the constraints of limited amodal segmentation datasets, we introduce Amodal-LVIS, a large-scale synthetic dataset comprising 300K images derived from the modal LVIS and LVVIS datasets. This dataset significantly expands the training data available for amodal segmentation research. Our experimental results demonstrate that our approach, when trained on the newly extended dataset, including Amodal-LVIS, achieves remarkable zero-shot performance on both COCOA-cls and D2SA benchmarks, highlighting its potential for generalization to unseen scenarios.
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing
Dec 05, 2023



We present a diffusion-based video editing framework, namely DiffusionAtlas, which can achieve both frame consistency and high fidelity in editing video object appearance. Despite the success in image editing, diffusion models still encounter significant hindrances when it comes to video editing due to the challenge of maintaining spatiotemporal consistency in the object's appearance across frames. On the other hand, atlas-based techniques allow propagating edits on the layered representations consistently back to frames. However, they often struggle to create editing effects that adhere correctly to the user-provided textual or visual conditions due to the limitation of editing the texture atlas on a fixed UV mapping field. Our method leverages a visual-textual diffusion model to edit objects directly on the diffusion atlases, ensuring coherent object identity across frames. We design a loss term with atlas-based constraints and build a pretrained text-driven diffusion model as pixel-wise guidance for refining shape distortions and correcting texture deviations. Qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in achieving consistent high-fidelity video-object editing.
Seg2Reg: Differentiable 2D Segmentation to 1D Regression Rendering for 360 Room Layout Reconstruction
Nov 30, 2023



State-of-the-art single-view 360-degree room layout reconstruction methods formulate the problem as a high-level 1D (per-column) regression task. On the other hand, traditional low-level 2D layout segmentation is simpler to learn and can represent occluded regions, but it requires complex post-processing for the targeting layout polygon and sacrifices accuracy. We present Seg2Reg to render 1D layout depth regression from the 2D segmentation map in a differentiable and occlusion-aware way, marrying the merits of both sides. Specifically, our model predicts floor-plan density for the input equirectangular 360-degree image. Formulating the 2D layout representation as a density field enables us to employ `flattened' volume rendering to form 1D layout depth regression. In addition, we propose a novel 3D warping augmentation on layout to improve generalization. Finally, we re-implement recent room layout reconstruction methods into our codebase for benchmarking and explore modern backbones and training techniques to serve as the strong baseline. Our model significantly outperforms previous arts. The code will be made available upon publication.
Hashing Neural Video Decomposition with Multiplicative Residuals in Space-Time
Sep 25, 2023



We present a video decomposition method that facilitates layer-based editing of videos with spatiotemporally varying lighting and motion effects. Our neural model decomposes an input video into multiple layered representations, each comprising a 2D texture map, a mask for the original video, and a multiplicative residual characterizing the spatiotemporal variations in lighting conditions. A single edit on the texture maps can be propagated to the corresponding locations in the entire video frames while preserving other contents' consistencies. Our method efficiently learns the layer-based neural representations of a 1080p video in 25s per frame via coordinate hashing and allows real-time rendering of the edited result at 71 fps on a single GPU. Qualitatively, we run our method on various videos to show its effectiveness in generating high-quality editing effects. Quantitatively, we propose to adopt feature-tracking evaluation metrics for objectively assessing the consistency of video editing. Project page: https://lightbulb12294.github.io/hashing-nvd/
Multiview Regenerative Morphing with Dual Flows
Aug 02, 2022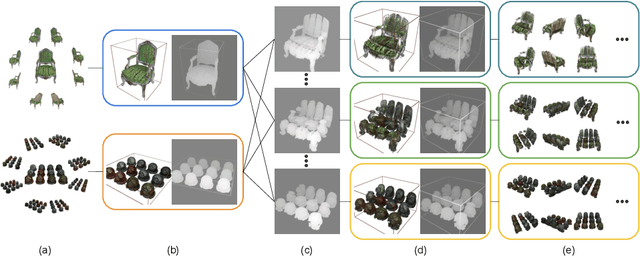



This paper aims to address a new task of image morphing under a multiview setting, which takes two sets of multiview images as the input and generates intermediate renderings that not only exhibit smooth transitions between the two input sets but also ensure visual consistency across different views at any transition state. To achieve this goal, we propose a novel approach called Multiview Regenerative Morphing that formulates the morphing process as an optimization to solve for rigid transformation and optimal-transport interpolation. Given the multiview input images of the source and target scenes, we first learn a volumetric representation that models the geometry and appearance for each scene to enable the rendering of novel views. Then, the morphing between the two scenes is obtained by solving optimal transport between the two volumetric representations in Wasserstein metrics. Our approach does not rely on user-specified correspondences or 2D/3D input meshes, and we do not assume any predefined categories of the source and target scenes. The proposed view-consistent interpolation scheme directly works on multiview images to yield a novel and visually plausible effect of multiview free-form morphing.
Mask2Hand: Learning to Predict the 3D Hand Pose and Shape from Shadow
May 31, 2022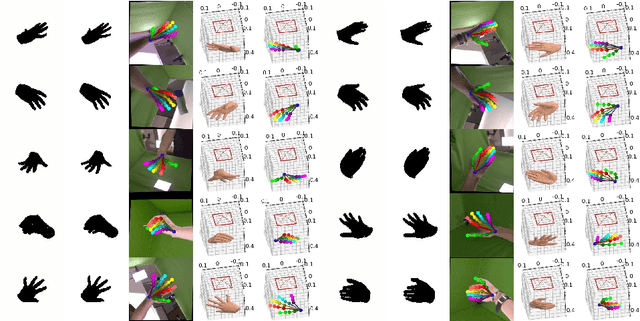

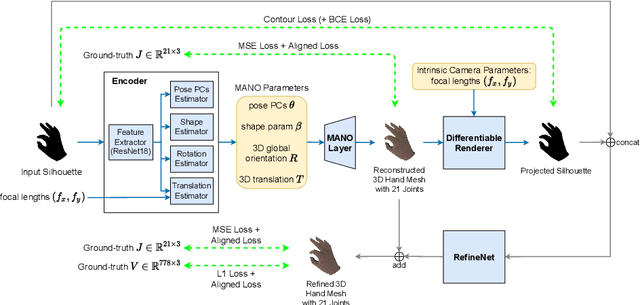

We present a self-trainable method, Mask2Hand, which learns to solve the challenging task of predicting 3D hand pose and shape from a 2D binary mask of hand silhouette/shadow without additional manually-annotated data. Given the intrinsic camera parameters and the parametric hand model in the camera space, we adopt the differentiable rendering technique to project 3D estimations onto the 2D binary silhouette space. By applying a tailored combination of losses between the rendered silhouette and the input binary mask, we are able to integrate the self-guidance mechanism into our end-to-end optimization process for constraining global mesh registration and hand pose estimation. The experiments show that our method, which takes a single binary mask as the input, can achieve comparable prediction accuracy on both unaligned and aligned settings as state-of-the-art methods that require RGB or depth inputs.