 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Safety Evaluations Lack Robustness
Mar 04, 2025In this paper, we argue that current safety alignment research efforts for large language models are hindered by many intertwined sources of noise, such as small datasets, methodological inconsistencies, and unreliable evaluation setups. This can, at times, make it impossible to evaluate and compare attacks and defenses fairly, thereby slowing progress. We systematically analyze the LLM safety evaluation pipeline, covering dataset curation, optimization strategies for automated red-teaming, response generation, and response evaluation using LLM judges. At each stage, we identify key issues and highlight their practical impact. We also propose a set of guidelines for reducing noise and bias in evaluations of future attack and defense papers. Lastly, we offer an opposing perspective, highlighting practical reasons for existing limitations. We believe that addressing the outlined problems in future research will improve the field's ability to generate easily comparable results and make measurable progress.
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence
Feb 24, 2025The safety alignment of large language models (LLMs) can be circumvented through adversarially crafted inputs, yet the mechanisms by which these attacks bypass safety barriers remain poorly understood. Prior work suggests that a single refusal direction in the model's activation space determines whether an LLM refuses a request. In this study, we propose a novel gradient-based approach to representation engineering and use it to identify refusal directions. Contrary to prior work, we uncover multiple independent directions and even multi-dimensional concept cones that mediate refusal. Moreover, we show that orthogonality alone does not imply independence under intervention, motivating the notion of representational independence that accounts for both linear and non-linear effects. Using this framework, we identify mechanistically independent refusal directions. We show that refusal mechanisms in LLMs are governed by complex spatial structures and identify functionally independent directions, confirming that multiple distinct mechanisms drive refusal behavior. Our gradient-based approach uncovers these mechanisms and can further serve as a foundation for future work on understanding LLMs.
REINFORCE Adversarial Attacks on Large Language Models: An Adaptive, Distributional, and Semantic Objective
Feb 24, 2025To circumvent the alignment of large language models (LLMs), current optimization-based adversarial attacks usually craft adversarial prompts by maximizing the likelihood of a so-called affirmative response. An affirmative response is a manually designed start of a harmful answer to an inappropriate request. While it is often easy to craft prompts that yield a substantial likelihood for the affirmative response, the attacked model frequently does not complete the response in a harmful manner. Moreover, the affirmative objective is usually not adapted to model-specific preferences and essentially ignores the fact that LLMs output a distribution over responses. If low attack success under such an objective is taken as a measure of robustness, the true robustness might be grossly overestimated. To alleviate these flaws, we propose an adaptive and semantic optimization problem over the population of responses. We derive a generally applicable objective via the REINFORCE policy-gradient formalism and demonstrate its efficacy with the state-of-the-art jailbreak algorithms Greedy Coordinate Gradient (GCG) and Projected Gradient Descent (PGD). For example, our objective doubles the attack success rate (ASR) on Llama3 and increases the ASR from 2% to 50% with circuit breaker defense.
Graph Neural Networks for Edge Signals: Orientation Equivariance and Invariance
Oct 22, 2024



Many applications in traffic, civil engineering, or electrical engineering revolve around edge-level signals. Such signals can be categorized as inherently directed, for example, the water flow in a pipe network, and undirected, like the diameter of a pipe. Topological methods model edge signals with inherent direction by representing them relative to a so-called orientation assigned to each edge. These approaches can neither model undirected edge signals nor distinguish if an edge itself is directed or undirected. We address these shortcomings by (i) revising the notion of orientation equivariance to enable edge direction-aware topological models, (ii) proposing orientation invariance as an additional requirement to describe signals without inherent direction, and (iii) developing EIGN, an architecture composed of novel direction-aware edge-level graph shift operators, that provably fulfills the aforementioned desiderata. It is the first general-purpose topological GNN for edge-level signals that can model directed and undirected signals while distinguishing between directed and undirected edges. A comprehensive evaluation shows that EIGN outperforms prior work in edge-level tasks, for example, improving in RMSE on flow simulation tasks by up to 43.5%.
Relaxing Graph Transformers for Adversarial Attacks
Jul 16, 2024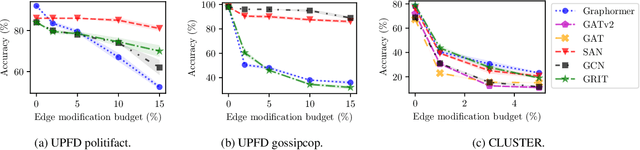
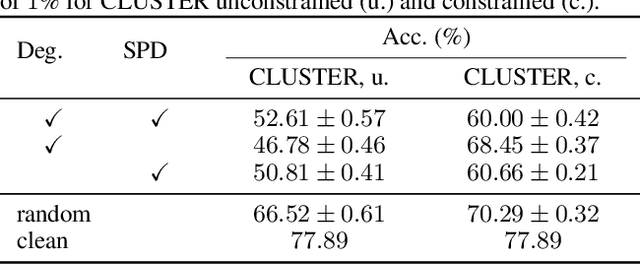
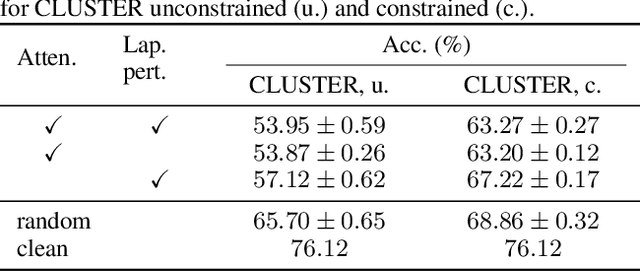
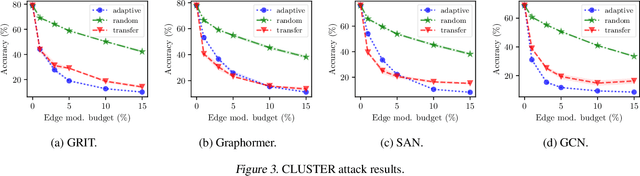
Existing studies have shown that Graph Neural Networks (GNNs) are vulnerable to adversarial attacks. Even though Graph Transformers (GTs) surpassed Message-Passing GNNs on several benchmarks, their adversarial robustness properties are unexplored. However, attacking GTs is challenging due to their Positional Encodings (PEs) and special attention mechanisms which can be difficult to differentiate. We overcome these challenges by targeting three representative architectures based on (1) random-walk PEs, (2) pair-wise-shortest-path PEs, and (3) spectral PEs - and propose the first adaptive attacks for GTs. We leverage our attacks to evaluate robustness to (a) structure perturbations on node classification; and (b) node injection attacks for (fake-news) graph classification. Our evaluation reveals that they can be catastrophically fragile and underlines our work's importance and the necessity for adaptive attacks.
Explainable Graph Neural Networks Under Fire
Jun 10, 2024



Predictions made by graph neural networks (GNNs) usually lack interpretability due to their complex computational behavior and the abstract nature of graphs. In an attempt to tackle this, many GNN explanation methods have emerged. Their goal is to explain a model's predictions and thereby obtain trust when GNN models are deployed in decision critical applications. Most GNN explanation methods work in a post-hoc manner and provide explanations in the form of a small subset of important edges and/or nodes. In this paper we demonstrate that these explanations can unfortunately not be trusted, as common GNN explanation methods turn out to be highly susceptible to adversarial perturbations. That is, even small perturbations of the original graph structure that preserve the model's predictions may yield drastically different explanations. This calls into question the trustworthiness and practical utility of post-hoc explanation methods for GNNs. To be able to attack GNN explanation models, we devise a novel attack method dubbed \textit{GXAttack}, the first \textit{optimization-based} adversarial attack method for post-hoc GNN explanations under such settings. Due to the devastating effectiveness of our attack, we call for an adversarial evaluation of future GNN explainers to demonstrate their robustness.
Spatio-Spectral Graph Neural Networks
May 29, 2024



Spatial Message Passing Graph Neural Networks (MPGNNs) are widely used for learning on graph-structured data. However, key limitations of l-step MPGNNs are that their "receptive field" is typically limited to the l-hop neighborhood of a node and that information exchange between distant nodes is limited by over-squashing. Motivated by these limitations, we propose Spatio-Spectral Graph Neural Networks (S$^2$GNNs) -- a new modeling paradigm for Graph Neural Networks (GNNs) that synergistically combines spatially and spectrally parametrized graph filters. Parameterizing filters partially in the frequency domain enables global yet efficient information propagation. We show that S$^2$GNNs vanquish over-squashing and yield strictly tighter approximation-theoretic error bounds than MPGNNs. Further, rethinking graph convolutions at a fundamental level unlocks new design spaces. For example, S$^2$GNNs allow for free positional encodings that make them strictly more expressive than the 1-Weisfeiler-Lehman (WL) test. Moreover, to obtain general-purpose S$^2$GNNs, we propose spectrally parametrized filters for directed graphs. S$^2$GNNs outperform spatial MPGNNs, graph transformers, and graph rewirings, e.g., on the peptide long-range benchmark tasks, and are competitive with state-of-the-art sequence modeling. On a 40 GB GPU, S$^2$GNNs scale to millions of nodes.
Attacking Large Language Models with Projected Gradient Descent
Feb 14, 2024Current LLM alignment methods are readily broken through specifically crafted adversarial prompts. While crafting adversarial prompts using discrete optimization is highly effective, such attacks typically use more than 100,000 LLM calls. This high computational cost makes them unsuitable for, e.g., quantitative analyses and adversarial training. To remedy this, we revisit Projected Gradient Descent (PGD) on the continuously relaxed input prompt. Although previous attempts with ordinary gradient-based attacks largely failed, we show that carefully controlling the error introduced by the continuous relaxation tremendously boosts their efficacy. Our PGD for LLMs is up to one order of magnitude faster than state-of-the-art discrete optimization to achieve the same devastating attack results.
Poisoning $\times$ Evasion: Symbiotic Adversarial Robustness for Graph Neural Networks
Dec 09, 2023



It is well-known that deep learning models are vulnerable to small input perturbations. Such perturbed instances are called adversarial examples. Adversarial examples are commonly crafted to fool a model either at training time (poisoning) or test time (evasion). In this work, we study the symbiosis of poisoning and evasion. We show that combining both threat models can substantially improve the devastating efficacy of adversarial attacks. Specifically, we study the robustness of Graph Neural Networks (GNNs) under structure perturbations and devise a memory-efficient adaptive end-to-end attack for the novel threat model using first-order optimization.
On the Adversarial Robustness of Graph Contrastive Learning Methods
Nov 30, 2023Contrastive learning (CL) has emerged as a powerful framework for learning representations of images and text in a self-supervised manner while enhancing model robustness against adversarial attacks. More recently, researchers have extended the principles of contrastive learning to graph-structured data, giving birth to the field of graph contrastive learning (GCL). However, whether GCL methods can deliver the same advantages in adversarial robustness as their counterparts in the image and text domains remains an open question. In this paper, we introduce a comprehensive robustness evaluation protocol tailored to assess the robustness of GCL models. We subject these models to adaptive adversarial attacks targeting the graph structure, specifically in the evasion scenario. We evaluate node and graph classification tasks using diverse real-world datasets and attack strategies. With our work, we aim to offer insights into the robustness of GCL methods and hope to open avenues for potential future research directions.