 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LaViP:Language-Grounded Visual Prompts
Dec 18, 2023
We introduce a language-grounded visual prompting method to adapt the visual encoder of vision-language models for downstream tasks. By capitalizing on language integration, we devise a parameter-efficient strategy to adjust the input of the visual encoder, eliminating the need to modify or add to the model's parameters. Due to this design choice, our algorithm can operate even in black-box scenarios, showcasing adaptability in situations where access to the model's parameters is constrained. We will empirically demonstrate that, compared to prior art, grounding visual prompts with language enhances both the accuracy and speed of adaptation. Moreover, our algorithm excels in base-to-novel class generalization, overcoming limitations of visual prompting and exhibiting the capacity to generalize beyond seen classes. We thoroughly assess and evaluate our method across a variety of image recognition datasets, such as EuroSAT, UCF101, DTD, and CLEVR, spanning different learning situations, including few-shot learning, base-to-novel class generalization, and transfer learning.
Genixer: Empowering Multimodal Large Language Models as a Powerful Data Generator
Dec 11, 2023Large Language Models (LLMs) excel in understanding human instructions, driving the development of Multimodal LLMs (MLLMs) with instruction tuning. However, acquiring high-quality multimodal instruction tuning data poses a significant challenge. Previous approaches relying on GPT-4 for data generation proved expensive and exhibited unsatisfactory performance for certain tasks. To solve this, we present Genixer, an innovative data generation pipeline producing high-quality multimodal instruction tuning data for various tasks. Genixer collects datasets for ten prevalent multimodal tasks and designs instruction templates to transform these datasets into instruction-tuning data. It then trains pretrained MLLMs to generate task-specific instruction data and proposes an effective data filtering strategy to ensure high quality. To evaluate Genixer, a base MLLM model, Kakapo, is built and achieves SoTA performance in image captioning and visual question answering (VQA) tasks across multiple datasets. Experimental results show that filtered data from Genixer continually improves Kakapo for image captioning and VQA tasks. For the SoTA Shikra MLLM model on the image-region-related tasks, e.g., region caption and detection, Genixer also successfully generates corresponding data and improves its performance. Genixer opens avenues for generating high-quality multimodal instruction data for diverse tasks, enabling innovative applications across domains. The code and models will be released soon.
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models
Dec 15, 2023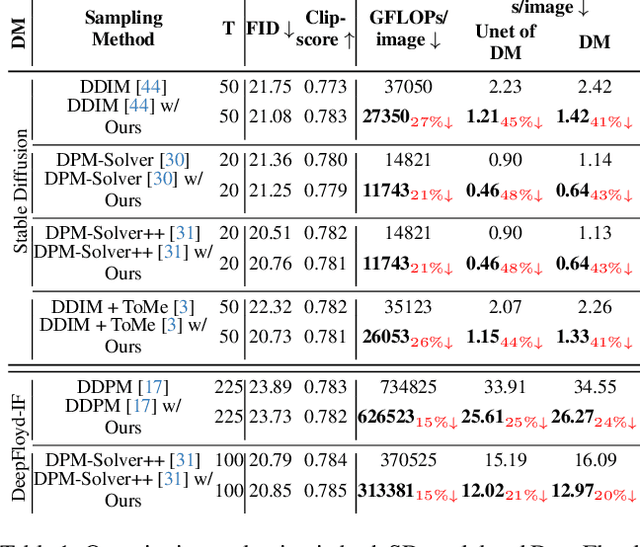
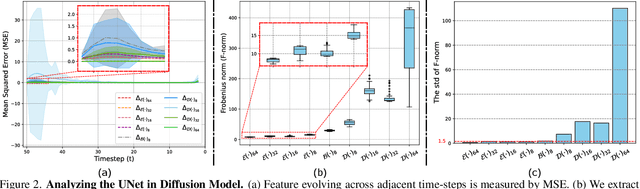
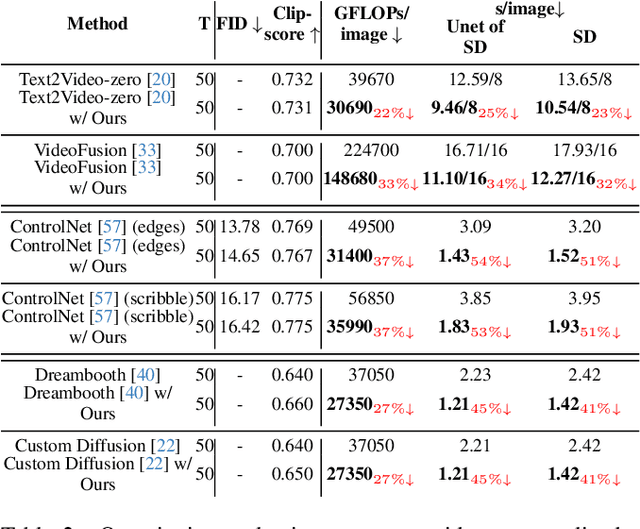
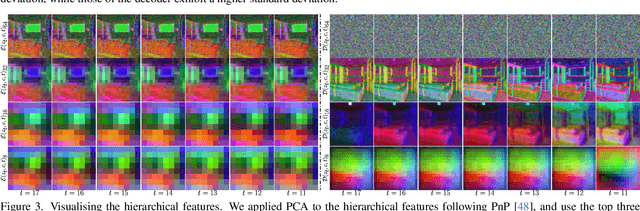
One of the key components within diffusion models is the UNet for noise prediction. While several works have explored basic properties of the UNet decoder, its encoder largely remains unexplored. In this work, we conduct the first comprehensive study of the UNet encoder. We empirically analyze the encoder features and provide insights to important questions regarding their changes at the inference process. In particular, we find that encoder features change gently, whereas the decoder features exhibit substantial variations across different time-steps. This finding inspired us to omit the encoder at certain adjacent time-steps and reuse cyclically the encoder features in the previous time-steps for the decoder. Further based on this observation, we introduce a simple yet effective encoder propagation scheme to accelerate the diffusion sampling for a diverse set of tasks. By benefiting from our propagation scheme, we are able to perform in parallel the decoder at certain adjacent time-steps. Additionally, we introduce a prior noise injection method to improve the texture details in the generated image. Besides the standard text-to-image task, we also validate our approach on other tasks: text-to-video, personalized generation and reference-guided generation. Without utilizing any knowledge distillation technique, our approach accelerates both the Stable Diffusion (SD) and the DeepFloyd-IF models sampling by 41$\%$ and 24$\%$ respectively, while maintaining high-quality generation performance. Our code is available in \href{https://github.com/hutaiHang/Faster-Diffusion}{FasterDiffusion}.
Anomaly Score: Evaluating Generative Models and Individual Generated Images based on Complexity and Vulnerability
Dec 17, 2023With the advancement of generative models, the assessment of generated images becomes more and more important. Previous methods measure distances between features of reference and generated images from trained vision models. In this paper, we conduct an extensive investigation into the relationship between the representation space and input space around generated images. We first propose two measures related to the presence of unnatural elements within images: complexity, which indicates how non-linear the representation space is, and vulnerability, which is related to how easily the extracted feature changes by adversarial input changes. Based on these, we introduce a new metric to evaluating image-generative models called anomaly score (AS). Moreover, we propose AS-i (anomaly score for individual images) that can effectively evaluate generated images individually. Experimental results demonstrate the validity of the proposed approach.
OT-Attack: Enhancing Adversarial Transferability of Vision-Language Models via Optimal Transport Optimization
Dec 07, 2023Vision-language pre-training (VLP) models demonstrate impressive abilities in processing both images and text. However, they are vulnerable to multi-modal adversarial examples (AEs). Investigating the generation of high-transferability adversarial examples is crucial for uncovering VLP models' vulnerabilities in practical scenarios. Recent works have indicated that leveraging data augmentation and image-text modal interactions can enhance the transferability of adversarial examples for VLP models significantly. However, they do not consider the optimal alignment problem between dataaugmented image-text pairs. This oversight leads to adversarial examples that are overly tailored to the source model, thus limiting improvements in transferability. In our research, we first explore the interplay between image sets produced through data augmentation and their corresponding text sets. We find that augmented image samples can align optimally with certain texts while exhibiting less relevance to others. Motivated by this, we propose an Optimal Transport-based Adversarial Attack, dubbed OT-Attack. The proposed method formulates the features of image and text sets as two distinct distributions and employs optimal transport theory to determine the most efficient mapping between them. This optimal mapping informs our generation of adversarial examples to effectively counteract the overfitting issues. Extensive experiments across various network architectures and datasets in image-text matching tasks reveal that our OT-Attack outperforms existing state-of-the-art methods in terms of adversarial transferability.
Beyond the Label Itself: Latent Labels Enhance Semi-supervised Point Cloud Panoptic Segmentation
Dec 13, 2023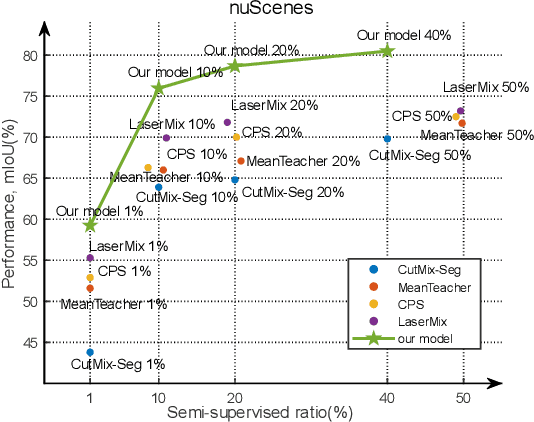
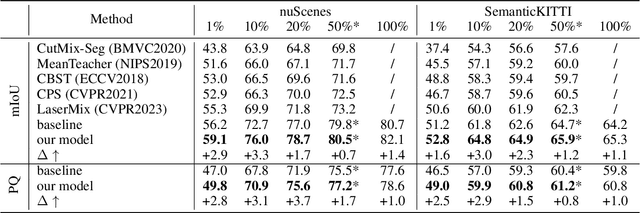

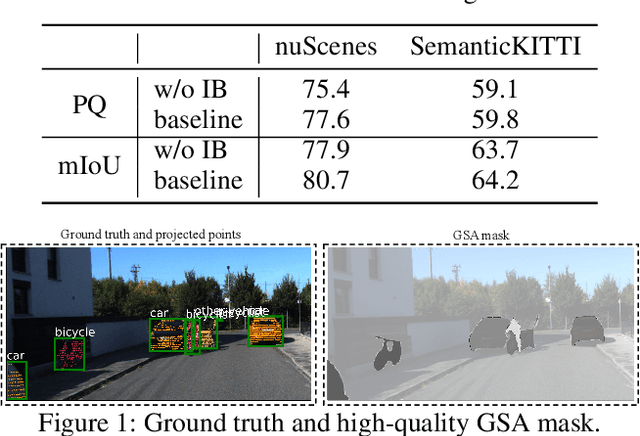
As the exorbitant expense of labeling autopilot datasets and the growing trend of utilizing unlabeled data, semi-supervised segmentation on point clouds becomes increasingly imperative. Intuitively, finding out more ``unspoken words'' (i.e., latent instance information) beyond the label itself should be helpful to improve performance. In this paper, we discover two types of latent labels behind the displayed label embedded in LiDAR and image data. First, in the LiDAR Branch, we propose a novel augmentation, Cylinder-Mix, which is able to augment more yet reliable samples for training. Second, in the Image Branch, we propose the Instance Position-scale Learning (IPSL) Module to learn and fuse the information of instance position and scale, which is from a 2D pre-trained detector and a type of latent label obtained from 3D to 2D projection. Finally, the two latent labels are embedded into the multi-modal panoptic segmentation network. The ablation of the IPSL module demonstrates its robust adaptability, and the experiments evaluated on SemanticKITTI and nuScenes demonstrate that our model outperforms the state-of-the-art method, LaserMix.
SGNet: Structure Guided Network via Gradient-Frequency Awareness for Depth Map Super-Resolution
Dec 13, 2023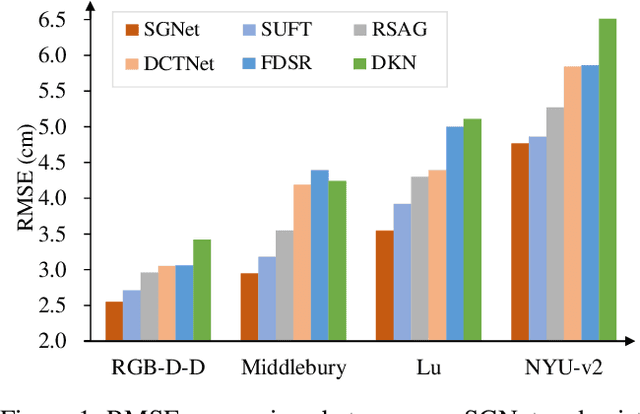

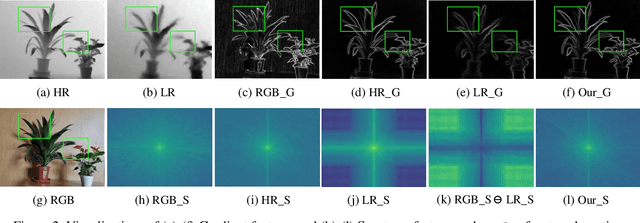
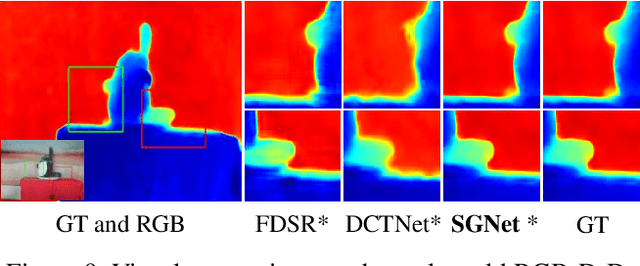
Depth super-resolution (DSR) aims to restore high-resolution (HR) depth from low-resolution (LR) one, where RGB image is often used to promote this task. Recent image guided DSR approaches mainly focus on spatial domain to rebuild depth structure. However, since the structure of LR depth is usually blurry, only considering spatial domain is not very sufficient to acquire satisfactory results. In this paper, we propose structure guided network (SGNet), a method that pays more attention to gradient and frequency domains, both of which have the inherent ability to capture high-frequency structure. Specifically, we first introduce the gradient calibration module (GCM), which employs the accurate gradient prior of RGB to sharpen the LR depth structure. Then we present the Frequency Awareness Module (FAM) that recursively conducts multiple spectrum differencing blocks (SDB), each of which propagates the precise high-frequency components of RGB into the LR depth. Extensive experimental results on both real and synthetic datasets demonstrate the superiority of our SGNet, reaching the state-of-the-art. Codes and pre-trained models are available at https://github.com/yanzq95/SGNet.
SISMIK for brain MRI: Deep-learning-based motion estimation and model-based motion correction in k-space
Dec 20, 2023MRI, a widespread non-invasive medical imaging modality, is highly sensitive to patient motion. Despite many attempts over the years, motion correction remains a difficult problem and there is no general method applicable to all situations. We propose a retrospective method for motion quantification and correction to tackle the problem of in-plane rigid-body motion, apt for classical 2D Spin-Echo scans of the brain, which are regularly used in clinical practice. Due to the sequential acquisition of k-space, motion artifacts are well localized. The method leverages the power of deep neural networks to estimate motion parameters in k-space and uses a model-based approach to restore degraded images to avoid ''hallucinations''. Notable advantages are its ability to estimate motion occurring in high spatial frequencies without the need of a motion-free reference. The proposed method operates on the whole k-space dynamic range and is moderately affected by the lower SNR of higher harmonics. As a proof of concept, we provide models trained using supervised learning on 600k motion simulations based on motion-free scans of 43 different subjects. Generalization performance was tested with simulations as well as in-vivo. Qualitative and quantitative evaluations are presented for motion parameter estimations and image reconstruction. Experimental results show that our approach is able to obtain good generalization performance on simulated data and in-vivo acquisitions.
VSR-Net: Vessel-like Structure Rehabilitation Network with Graph Clustering
Dec 20, 2023The morphologies of vessel-like structures, such as blood vessels and nerve fibres, play significant roles in disease diagnosis, e.g., Parkinson's disease. Deep network-based refinement segmentation methods have recently achieved promising vessel-like structure segmentation results. There are still two challenges: (1) existing methods have limitations in rehabilitating subsection ruptures in segmented vessel-like structures; (2) they are often overconfident in predicted segmentation results. To tackle these two challenges, this paper attempts to leverage the potential of spatial interconnection relationships among subsection ruptures from the structure rehabilitation perspective. Based on this, we propose a novel Vessel-like Structure Rehabilitation Network (VSR-Net) to rehabilitate subsection ruptures and improve the model calibration based on coarse vessel-like structure segmentation results. VSR-Net first constructs subsection rupture clusters with Curvilinear Clustering Module (CCM). Then, the well-designed Curvilinear Merging Module (CMM) is applied to rehabilitate the subsection ruptures to obtain the refined vessel-like structures. Extensive experiments on five 2D/3D medical image datasets show that VSR-Net significantly outperforms state-of-the-art (SOTA) refinement segmentation methods with lower calibration error. Additionally, we provide quantitative analysis to explain the morphological difference between the rehabilitation results of VSR-Net and ground truth (GT), which is smaller than SOTA methods and GT, demonstrating that our method better rehabilitates vessel-like structures by restoring subsection ruptures.
Generate E-commerce Product Background by Integrating Category Commonality and Personalized Style
Dec 20, 2023The state-of-the-art methods for e-commerce product background generation suffer from the inefficiency of designing product-wise prompts when scaling up the production, as well as the ineffectiveness of describing fine-grained styles when customizing personalized backgrounds for some specific brands. To address these obstacles, we integrate the category commonality and personalized style into diffusion models. Concretely, we propose a Category-Wise Generator to enable large-scale background generation for the first time. A unique identifier in the prompt is assigned to each category, whose attention is located on the background by a mask-guided cross attention layer to learn the category-wise style. Furthermore, for products with specific and fine-grained requirements in layout, elements, etc, a Personality-Wise Generator is devised to learn such personalized style directly from a reference image to resolve textual ambiguities, and is trained in a self-supervised manner for more efficient training data usage. To advance research in this field, the first large-scale e-commerce product background generation dataset BG60k is constructed, which covers more than 60k product images from over 2k categories. Experiments demonstrate that our method could generate high-quality backgrounds for different categories, and maintain the personalized background style of reference images. The link to BG60k and codes will be available soon.