 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel and Efficient Tumor Detection Framework for Pancreatic Cancer via CT Images
Feb 11, 2020
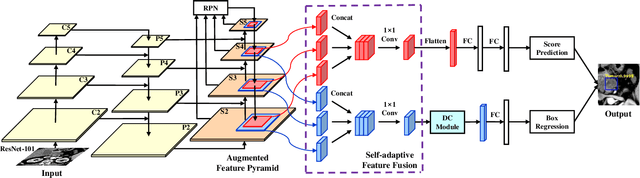
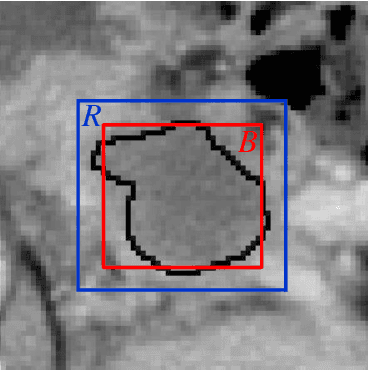
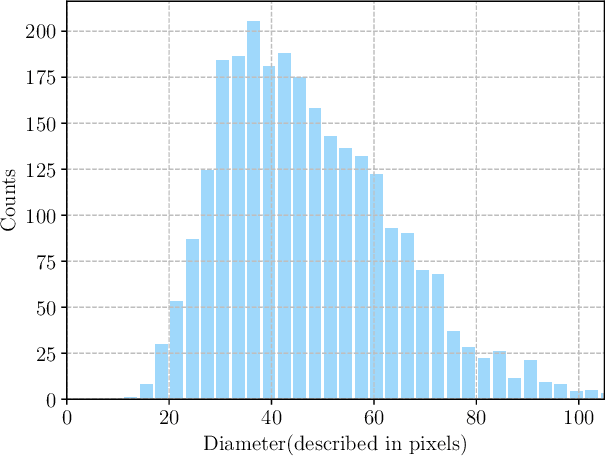
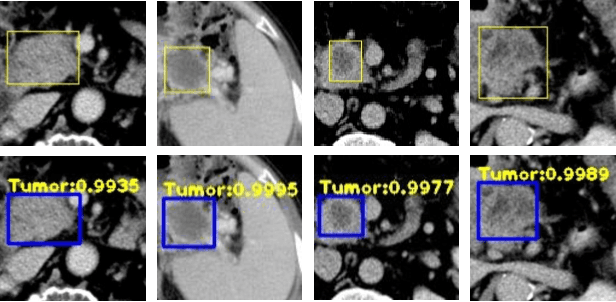
As Deep Convolutional Neural Networks (DCNNs) have shown robust performance and results in medical image analysis, a number of deep-learning-based tumor detection methods were developed in recent years. Nowadays, the automatic detection of pancreatic tumors using contrast-enhanced Computed Tomography (CT) is widely applied for the diagnosis and staging of pancreatic cancer. Traditional hand-crafted methods only extract low-level features. Normal convolutional neural networks, however, fail to make full use of effective context information, which causes inferior detection results. In this paper, a novel and efficient pancreatic tumor detection framework aiming at fully exploiting the context information at multiple scales is designed. More specifically, the contribution of the proposed method mainly consists of three components: Augmented Feature Pyramid networks, Self-adaptive Feature Fusion and a Dependencies Computation (DC) Module. A bottom-up path augmentation to fully extract and propagate low-level accurate localization information is established firstly. Then, the Self-adaptive Feature Fusion can encode much richer context information at multiple scales based on the proposed regions. Finally, the DC Module is specifically designed to capture the interaction information between proposals and surrounding tissues. Experimental results achieve competitive performance in detection with the AUC of 0.9455, which outperforms other state-of-the-art methods to our best of knowledge, demonstrating the proposed framework can detect the tumor of pancreatic cancer efficiently and accurately.
SESS: Self-Ensembling Semi-Supervised 3D Object Detection
Dec 26, 2019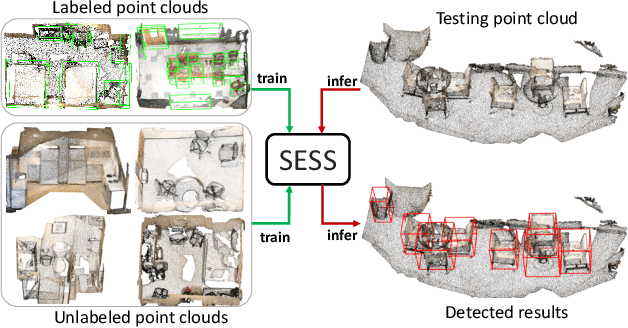
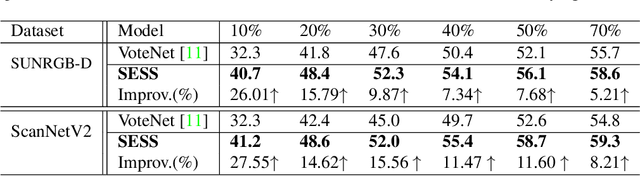
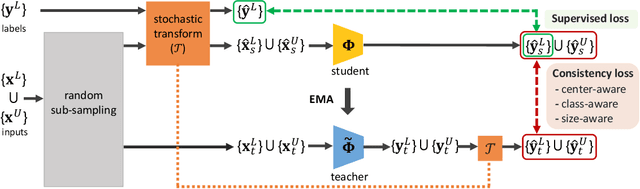

The performance of existing point cloud-based 3D object detection methods heavily relies on large-scale high-quality 3D annotations. However, such annotations are often tedious and expensive to collect. Semi-supervised learning is a good alternative to mitigate the data annotation issue, but has remained largely unexplored in 3D object detection. Inspired by the recent success of self-ensembling technique in semi-supervised image classification task, we propose SESS, a self-ensembling semi-supervised 3D object detection framework. Specifically, we design a thorough perturbation scheme to enhance generalization of the network on unlabeled and new unseen data. Furthermore, we propose three consistency losses to enforce the consistency between two sets of predicted 3D object proposals, to facilitate the learning of structure and semantic invariances of objects. Extensive experiments conducted on SUN RGB-D and ScanNet datasets demonstrate the effectiveness of SESS in both inductive and transductive semi-supervised 3D object detection. Our SESS achieves competitive performance compared to the state-of-the-art fully-supervised method by using only 50% labeled data.
Attention-Aware Age-Agnostic Visual Place Recognition
Sep 11, 2019
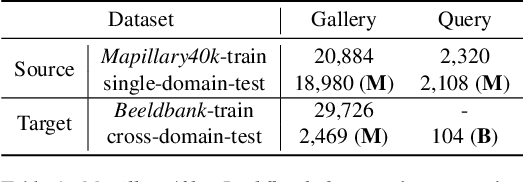
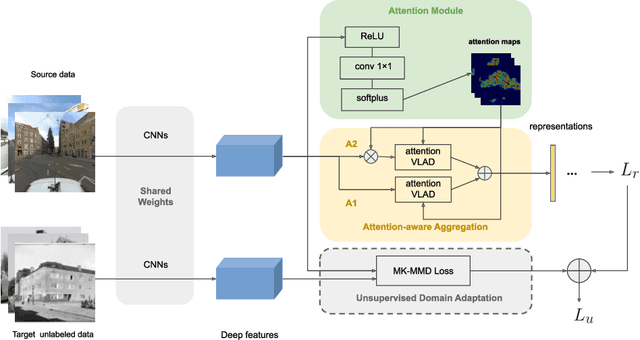
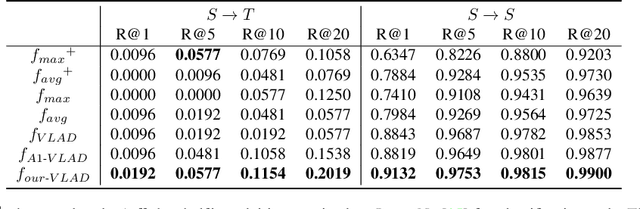
A cross-domain visual place recognition (VPR) task is proposed in this work, i.e., matching images of the same architectures depicted in different domains. VPR is commonly treated as an image retrieval task, where a query image from an unknown location is matched with relevant instances from geo-tagged gallery database. Different from conventional VPR settings where the query images and gallery images come from the same domain, we propose a more common but challenging setup where the query images are collected under a new unseen condition. The two domains involved in this work are contemporary street view images of Amsterdam from the Mapillary dataset (source domain) and historical images of the same city from Beeldbank dataset (target domain). We tailored an age-invariant feature learning CNN that can focus on domain invariant objects and learn to match images based on a weakly supervised ranking loss. We propose an attention aggregation module that is robust to domain discrepancy between the train and the test data. Further, a multi-kernel maximum mean discrepancy (MK-MMD) domain adaptation loss is adopted to improve the cross-domain ranking performance. Both attention and adaptation modules are unsupervised while the ranking loss uses weak supervision. Visual inspection shows that the attention module focuses on built forms while the dramatically changing environment are less weighed. Our proposed CNN achieves state of the art results (99% accuracy) on the single-domain VPR task and 20% accuracy at its best on the cross-domain VPR task, revealing the difficulty of age-invariant VPR.
Improved Few-Shot Visual Classification
Dec 07, 2019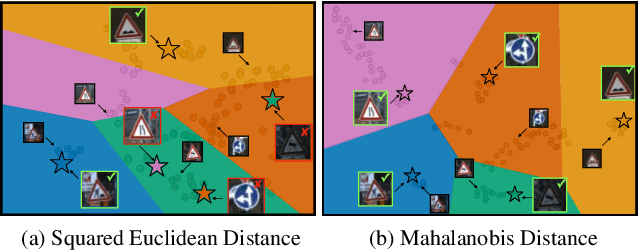

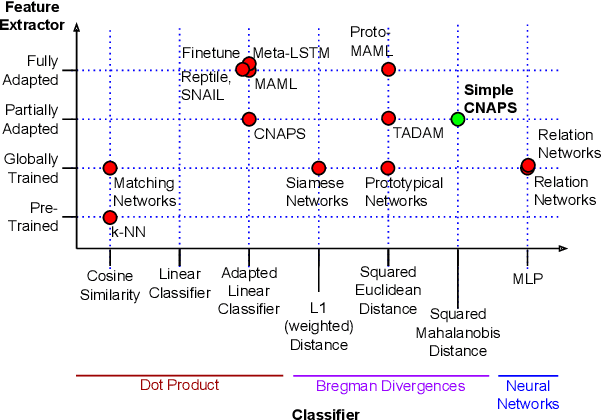

Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
Mar 27, 2019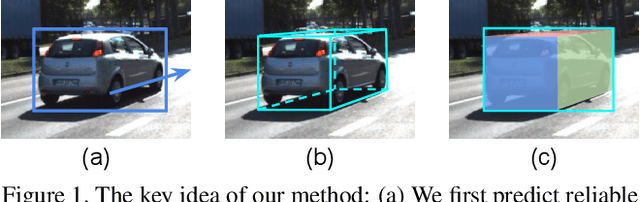
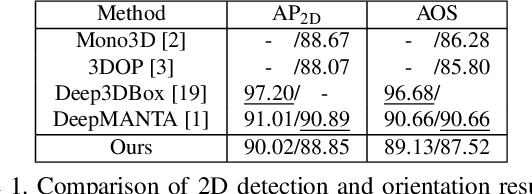

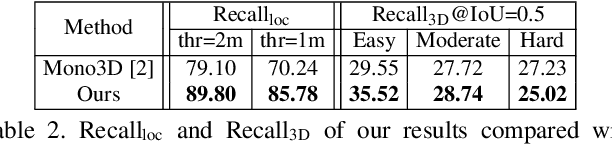
We present an efficient 3D object detection framework based on a single RGB image in the scenario of autonomous driving. Our efforts are put on extracting the underlying 3D information in a 2D image and determining the accurate 3D bounding box of the object without point cloud or stereo data. Leveraging the off-the-shelf 2D object detector, we propose an artful approach to efficiently obtain a coarse cuboid for each predicted 2D box. The coarse cuboid has enough accuracy to guide us to determine the 3D box of the object by refinement. In contrast to previous state-of-the-art methods that only use the features extracted from the 2D bounding box for box refinement, we explore the 3D structure information of the object by employing the visual features of visible surfaces. The new features from surfaces are utilized to eliminate the problem of representation ambiguity brought by only using a 2D bounding box. Moreover, we investigate different methods of 3D box refinement and discover that a classification formulation with quality aware loss has much better performance than regression. Evaluated on the KITTI benchmark, our approach outperforms current state-of-the-art methods for single RGB image based 3D object detection.
Scene Parsing via Dense Recurrent Neural Networks with Attentional Selection
Nov 09, 2018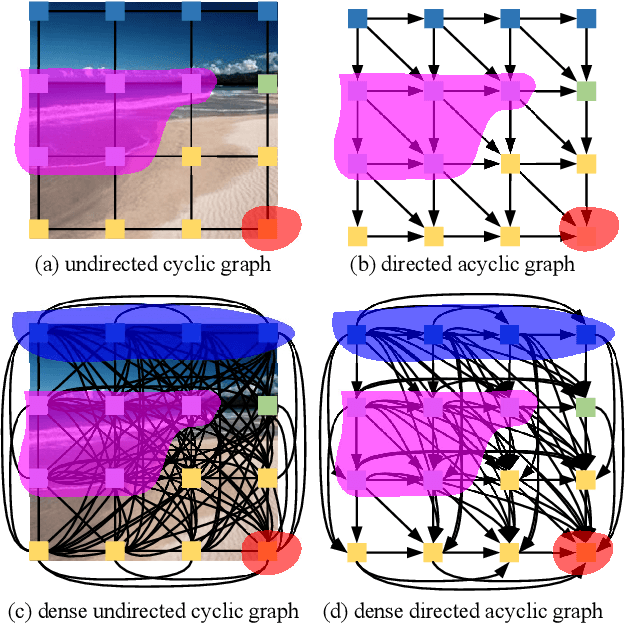

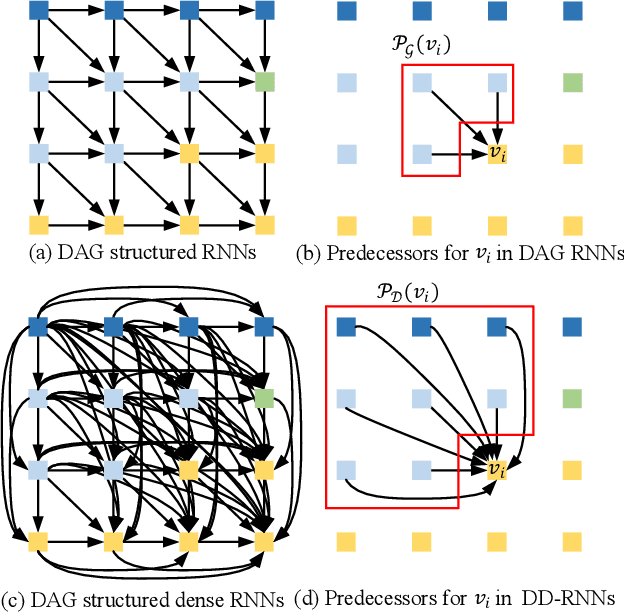
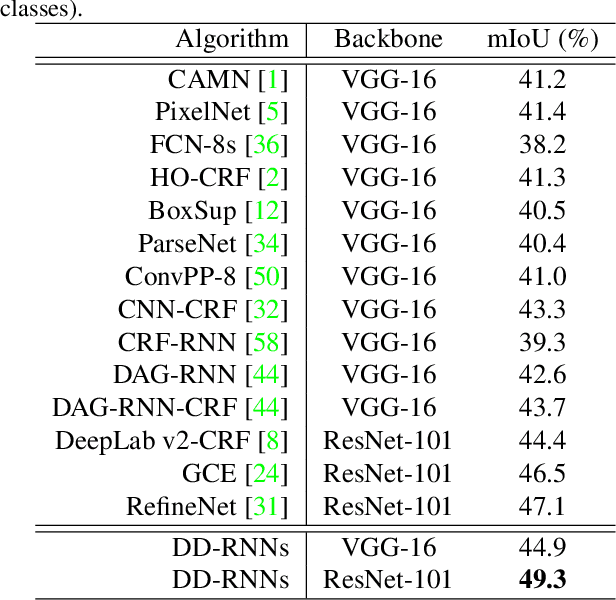
Recurrent neural networks (RNNs) have shown the ability to improve scene parsing through capturing long-range dependencies among image units. In this paper, we propose dense RNNs for scene labeling by exploring various long-range semantic dependencies among image units. Different from existing RNN based approaches, our dense RNNs are able to capture richer contextual dependencies for each image unit by enabling immediate connections between each pair of image units, which significantly enhances their discriminative power. Besides, to select relevant dependencies and meanwhile to restrain irrelevant ones for each unit from dense connections, we introduce an attention model into dense RNNs. The attention model allows automatically assigning more importance to helpful dependencies while less weight to unconcerned dependencies. Integrating with convolutional neural networks (CNNs), we develop an end-to-end scene labeling system. Extensive experiments on three large-scale benchmarks demonstrate that the proposed approach can improve the baselines by large margins and outperform other state-of-the-art algorithms.
PUGeo-Net: A Geometry-centric Network for 3D Point Cloud Upsampling
Mar 07, 2020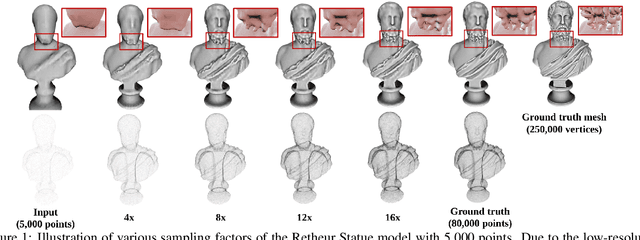
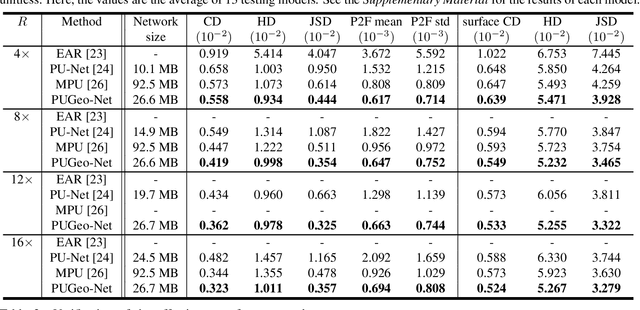
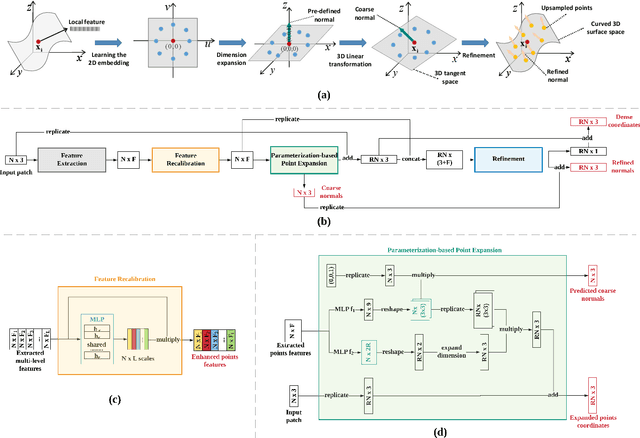
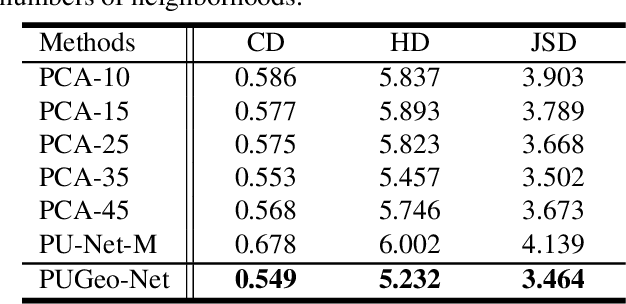
This paper addresses the problem of generating uniform dense point clouds to describe the underlying geometric structures from given sparse point clouds. Due to the irregular and unordered nature, point cloud densification as a generative task is challenging. To tackle the challenge, we propose a novel deep neural network based method, called PUGeo-Net, that learns a $3\times 3$ linear transformation matrix $\bf T$ for each input point. Matrix $\mathbf T$ approximates the augmented Jacobian matrix of a local parameterization and builds a one-to-one correspondence between the 2D parametric domain and the 3D tangent plane so that we can lift the adaptively distributed 2D samples (which are also learned from data) to 3D space. After that, we project the samples to the curved surface by computing a displacement along the normal of the tangent plane. PUGeo-Net is fundamentally different from the existing deep learning methods that are largely motivated by the image super-resolution techniques and generate new points in the abstract feature space. Thanks to its geometry-centric nature, PUGeo-Net works well for both CAD models with sharp features and scanned models with rich geometric details. Moreover, PUGeo-Net can compute the normal for the original and generated points, which is highly desired by the surface reconstruction algorithms. Computational results show that PUGeo-Net, the first neural network that can jointly generate vertex coordinates and normals, consistently outperforms the state-of-the-art in terms of accuracy and efficiency for upsampling factor $4\sim 16$.
Adversarial Examples in Modern Machine Learning: A Review
Nov 15, 2019
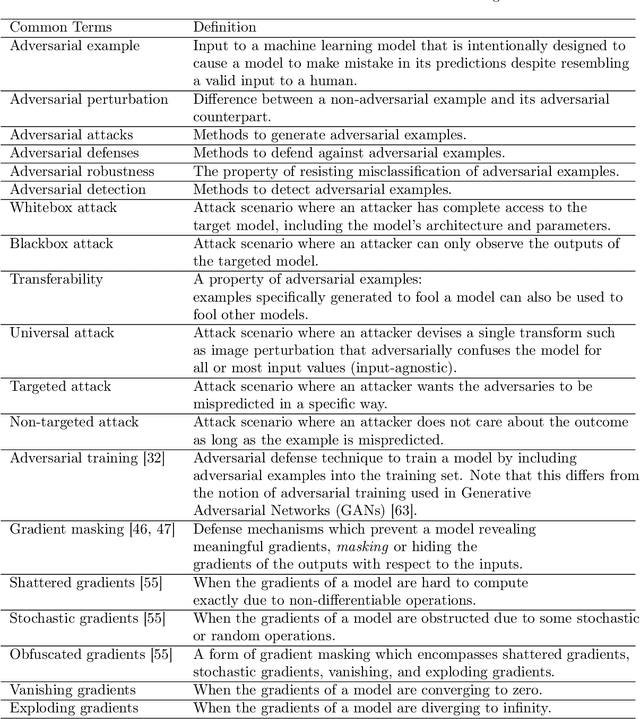

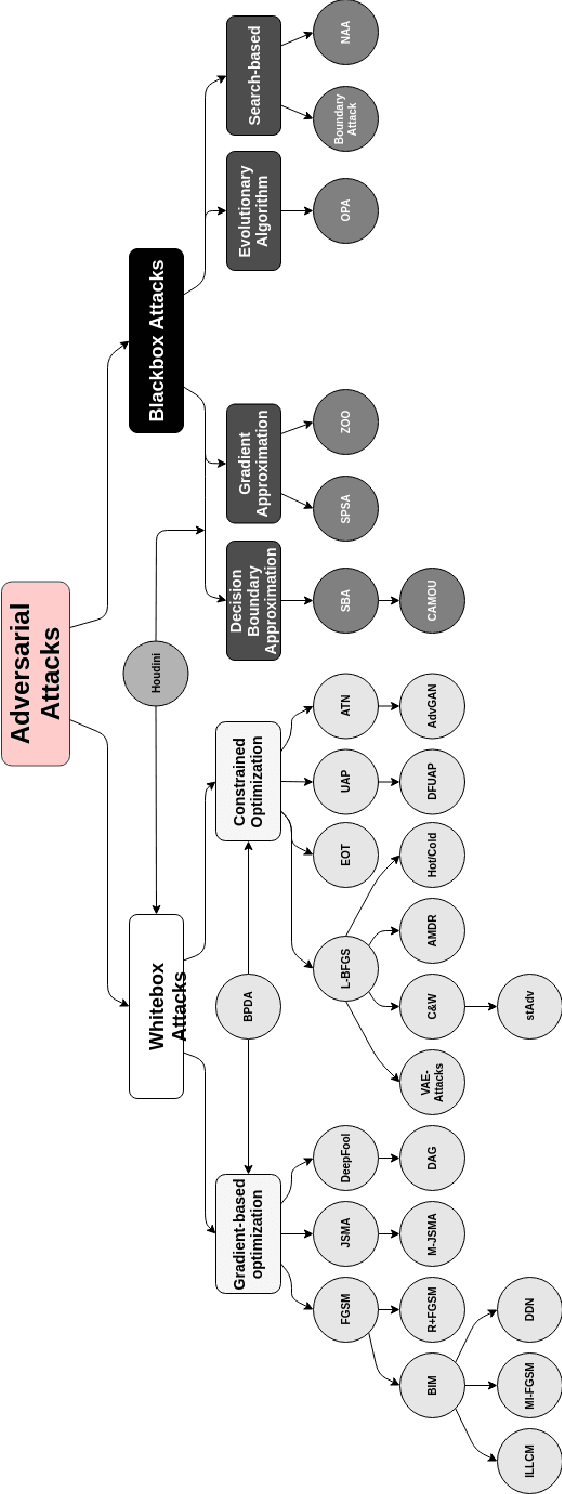
Recent research has found that many families of machine learning models are vulnerable to adversarial examples: inputs that are specifically designed to cause the target model to produce erroneous outputs. In this survey, we focus on machine learning models in the visual domain, where methods for generating and detecting such examples have been most extensively studied. We explore a variety of adversarial attack methods that apply to image-space content, real world adversarial attacks, adversarial defenses, and the transferability property of adversarial examples. We also discuss strengths and weaknesses of various methods of adversarial attack and defense. Our aim is to provide an extensive coverage of the field, furnishing the reader with an intuitive understanding of the mechanics of adversarial attack and defense mechanisms and enlarging the community of researchers studying this fundamental set of problems.
No Peeking through My Windows: Conserving Privacy in Personal Drones
Aug 26, 2019



The drone technology has been increasingly used by many tech-savvy consumers, a number of defense companies, hobbyists and enthusiasts during the last ten years. Drones often come in various sizes and are designed for a multitude of purposes. Nowadays many people have small-sized personal drones for entertainment, filming, or transporting items from one place to another. However, personal drones lack a privacy-preserving mechanism. While in mission, drones often trespass into the personal territories of other people and capture photos or videos through windows without their knowledge and consent. They may also capture video or pictures of people walking, sitting, or doing private things within the drones' reach in clear form without their go permission. This could potentially invade people's personal privacy. This paper, therefore, proposes a lightweight privacy-preserving-by-design method that prevents drones from peeking through windows of houses and capturing people doing private things at home. It is a fast window object detection and scrambling technology built based on image-enhancing, morphological transformation, segmentation and contouring processes (MASP). Besides, a chaotic scrambling technique is incorporated into it for privacy purpose. Hence, this mechanism detects window objects in every image or frame of a real-time video and masks them chaotically to protect the privacy of people. The experimental results validated that the proposed MASP method is lightweight and suitable to be employed in drones, considered as edge devices.
Towards Photo-Realistic Visible Watermark Removal with Conditional Generative Adversarial Networks
May 31, 2019
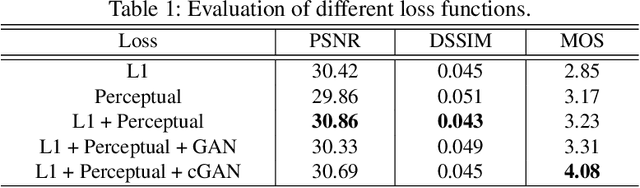
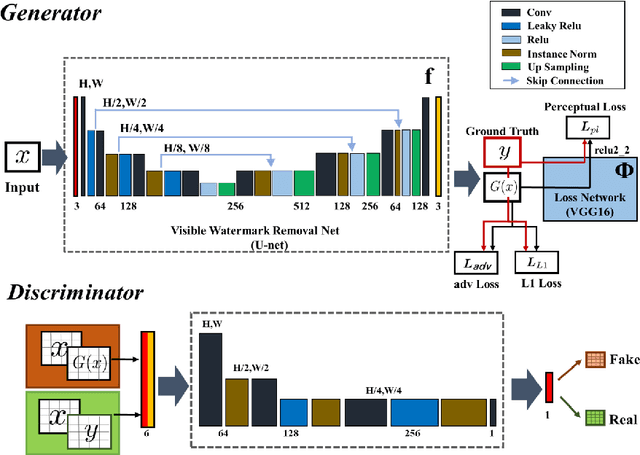
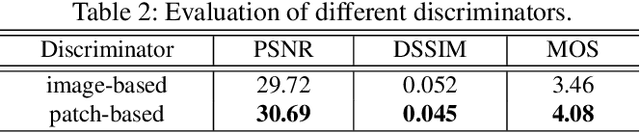
Visible watermark plays an important role in image copyright protection and the robustness of a visible watermark to an attack is shown to be essential. To evaluate and improve the effectiveness of watermark, watermark removal attracts increasing attention and becomes a hot research top. Current methods cast the watermark removal as an image-to-image translation problem where the encode-decode architectures with pixel-wise loss are adopted to transfer the transparent watermarked pixels into unmarked pixels. However, when a number of realistic images are presented, the watermarks are more likely to be unknown and diverse (i.e., the watermarks might be opaque or semi-transparent; the category and pattern of watermarks are unknown). When applying existing methods to the real-world scenarios, they mostly can not satisfactorily reconstruct the hidden information obscured under the complex and various watermarks (i.e., the residual watermark traces remain and the reconstructed images lack reality). To address this difficulty, in this paper, we present a new watermark processing framework using the conditional generative adversarial networks (cGANs) for visible watermark removal in the real-world application. The proposed method enables the watermark removal solution to be more closed to the photo-realistic reconstruction using a patch-based discriminator conditioned on the watermarked images, which is adversarially trained to differentiate the difference between the recovered images and original watermark-free images. Extensive experimental results on a large-scale visible watermark dataset demonstrate the effectiveness of the proposed method and clearly indicate that our proposed approach can produce more photo-realistic and convincing results compared with the state-of-the-art methods.