 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothVLA: Aligning Vision-Language-Action Models with Physical Constraints via Intrinsic Smoothness Optimization
Mar 14, 2026Vision-Language-Action (VLA) models have emerged as a powerful paradigm for robotic manipulation. However, existing post-training methods face a dilemma between stability and exploration: Supervised Fine-Tuning (SFT) is constrained by demonstration quality and lacks generalization, whereas Reinforcement Learning (RL) improves exploration but often induces erratic, jittery trajectories that violate physical constraints. To bridge this gap, we propose SmoothVLA, a novel reinforcement learning fine-tuning framework that synergistically optimizes task performance and motion smoothness. The technical core is a physics-informed hybrid reward function that integrates binary sparse task rewards with a continuous dense term derived from trajectory jerk. Crucially, this reward is intrinsic, that computing directly from policy rollouts, without requiring extrinsic environment feedback or laborious reward engineering. Leveraging the Group Relative Policy Optimization (GRPO), SmoothVLA establishes trajectory smoothness as an explicit optimization prior, guiding the model toward physically feasible and stable control. Extensive experiments on the LIBERO benchmark demonstrate that SmoothVLA outperforms standard RL by 13.8\% in smoothness and significantly surpasses SFT in generalization across diverse tasks. Our work offers a scalable approach to aligning VLA models with physical-world constraints through intrinsic reward optimization.
Fairness Begins with State: Purifying Latent Preferences for Hierarchical Reinforcement Learning in Interactive Recommendation
Mar 04, 2026Interactive recommender systems (IRS) are increasingly optimized with Reinforcement Learning (RL) to capture the sequential nature of user-system dynamics. However, existing fairness-aware methods often suffer from a fundamental oversight: they assume the observed user state is a faithful representation of true preferences. In reality, implicit feedback is contaminated by popularity-driven noise and exposure bias, creating a distorted state that misleads the RL agent. We argue that the persistent conflict between accuracy and fairness is not merely a reward-shaping issue, but a state estimation failure. In this work, we propose \textbf{DSRM-HRL}, a framework that reformulates fairness-aware recommendation as a latent state purification problem followed by decoupled hierarchical decision-making. We introduce a Denoising State Representation Module (DSRM) based on diffusion models to recover the low-entropy latent preference manifold from high-entropy, noisy interaction histories. Built upon this purified state, a Hierarchical Reinforcement Learning (HRL) agent is employed to decouple conflicting objectives: a high-level policy regulates long-term fairness trajectories, while a low-level policy optimizes short-term engagement under these dynamic constraints. Extensive experiments on high-fidelity simulators (KuaiRec, KuaiRand) demonstrate that DSRM-HRL effectively breaks the "rich-get-richer" feedback loop, achieving a superior Pareto frontier between recommendation utility and exposure equity.
Empowering Clinical Trial Design through AI: A Randomized Evaluation of PowerGPT
Sep 15, 2025



Sample size calculations for power analysis are critical for clinical research and trial design, yet their complexity and reliance on statistical expertise create barriers for many researchers. We introduce PowerGPT, an AI-powered system integrating large language models (LLMs) with statistical engines to automate test selection and sample size estimation in trial design. In a randomized trial to evaluate its effectiveness, PowerGPT significantly improved task completion rates (99.3% vs. 88.9% for test selection, 99.3% vs. 77.8% for sample size calculation) and accuracy (94.1% vs. 55.4% in sample size estimation, p < 0.001), while reducing average completion time (4.0 vs. 9.3 minutes, p < 0.001). These gains were consistent across various statistical tests and benefited both statisticians and non-statisticians as well as bridging expertise gaps. Already under deployment across multiple institutions, PowerGPT represents a scalable AI-driven approach that enhances accessibility, efficiency, and accuracy in statistical power analysis for clinical research.
Why Studying Cut-ins? Comparing Cut-ins and Other Lane Changes Based on Naturalistic Driving Data
Feb 13, 2024Extensive research has been conducted to explore vehicle lane changes, while the study on cut-ins has not received sufficient attention. The existing studies have not addressed the fundamental question of why studying cut-ins is crucial, despite the extensive investigation into lane changes. To tackle this issue, it is important to demonstrate how cut-ins, as a special type of lane change, differ from other lane changes. In this paper, we explore to compare driving characteristics of cut-ins and other lane changes based on naturalistic driving data. The highD dataset is employed to conduct the comparison. We extract all lane-change events from the dataset and exclude events that are not suitable for our comparison. Lane-change events are then categorized into the cut-in events and other lane-change events based on various gap-based rules. Several performance metrics are designed to measure the driving characteristics of the two types of events. We prove the significant differences between the cut-in behavior and other lane-change behavior by using the Wilcoxon rank-sum test. The results suggest the necessity of conducting specialized studies on cut-ins, offering valuable insights for future research in this field.
Privacy-Utility Tradeoff of OLS with Random Projections
Sep 03, 2023



We study the differential privacy (DP) of a core ML problem, linear ordinary least squares (OLS), a.k.a. $\ell_2$-regression. Our key result is that the approximate LS algorithm (ALS) (Sarlos, 2006), a randomized solution to the OLS problem primarily used to improve performance on large datasets, also preserves privacy. ALS achieves a better privacy/utility tradeoff, without modifications or further noising, when compared to alternative private OLS algorithms which modify and/or noise OLS. We give the first {\em tight} DP-analysis for the ALS algorithm and the standard Gaussian mechanism (Dwork et al., 2014) applied to OLS. Our methodology directly improves the privacy analysis of (Blocki et al., 2012) and (Sheffet, 2019)) and introduces new tools which may be of independent interest: (1) the exact spectrum of $(\epsilon, \delta)$-DP parameters (``DP spectrum") for mechanisms whose output is a $d$-dimensional Gaussian, and (2) an improved DP spectrum for random projection (compared to (Blocki et al., 2012) and (Sheffet, 2019)). All methods for private OLS (including ours) assume, often implicitly, restrictions on the input database, such as bounds on leverage and residuals. We prove that such restrictions are necessary. Hence, computing the privacy of mechanisms such as ALS must estimate these database parameters, which can be infeasible in big datasets. For more complex ML models, DP bounds may not even be tractable. There is a need for blackbox DP-estimators (Lu et al., 2022) which empirically estimate a data-dependent privacy. We demonstrate the effectiveness of such a DP-estimator by empirically recovering a DP-spectrum that matches our theory for OLS. This validates the DP-estimator in a nontrivial ML application, opening the door to its use in more complex nonlinear ML settings where theory is unavailable.
A Novel and Efficient Tumor Detection Framework for Pancreatic Cancer via CT Images
Feb 11, 2020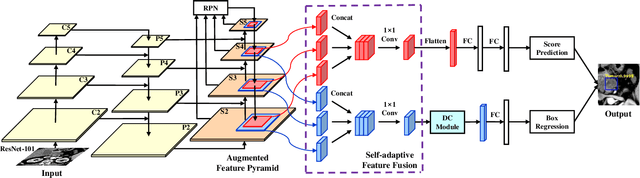
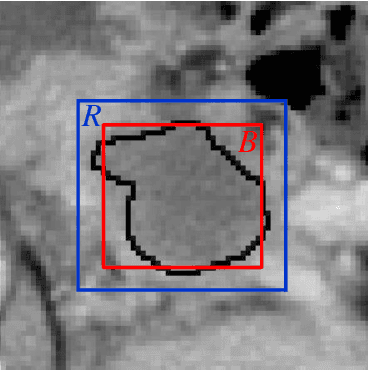
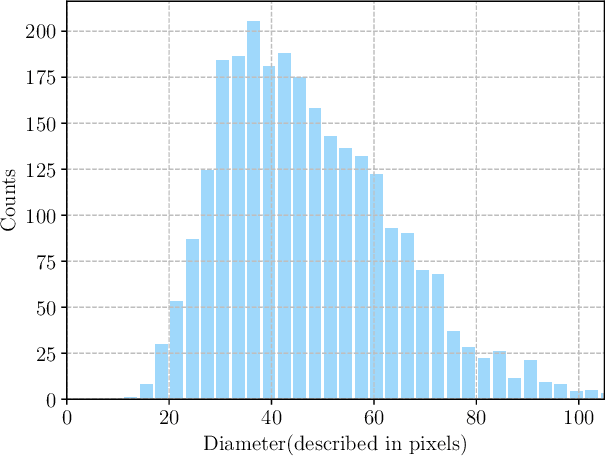
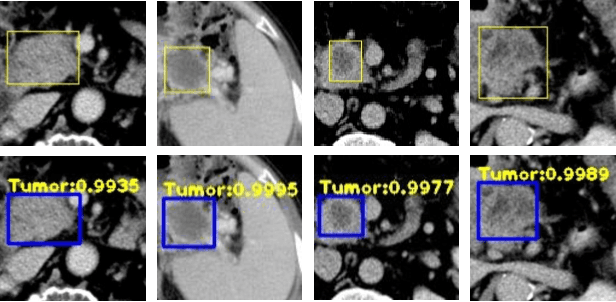
As Deep Convolutional Neural Networks (DCNNs) have shown robust performance and results in medical image analysis, a number of deep-learning-based tumor detection methods were developed in recent years. Nowadays, the automatic detection of pancreatic tumors using contrast-enhanced Computed Tomography (CT) is widely applied for the diagnosis and staging of pancreatic cancer. Traditional hand-crafted methods only extract low-level features. Normal convolutional neural networks, however, fail to make full use of effective context information, which causes inferior detection results. In this paper, a novel and efficient pancreatic tumor detection framework aiming at fully exploiting the context information at multiple scales is designed. More specifically, the contribution of the proposed method mainly consists of three components: Augmented Feature Pyramid networks, Self-adaptive Feature Fusion and a Dependencies Computation (DC) Module. A bottom-up path augmentation to fully extract and propagate low-level accurate localization information is established firstly. Then, the Self-adaptive Feature Fusion can encode much richer context information at multiple scales based on the proposed regions. Finally, the DC Module is specifically designed to capture the interaction information between proposals and surrounding tissues. Experimental results achieve competitive performance in detection with the AUC of 0.9455, which outperforms other state-of-the-art methods to our best of knowledge, demonstrating the proposed framework can detect the tumor of pancreatic cancer efficiently and accurately.