 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distorted Representation Space Characterization Through Backpropagated Gradients
Aug 27, 2019
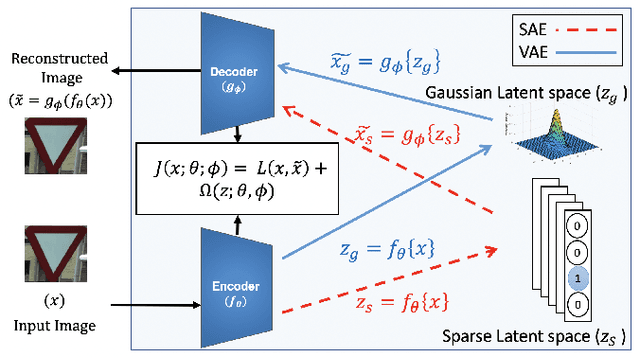
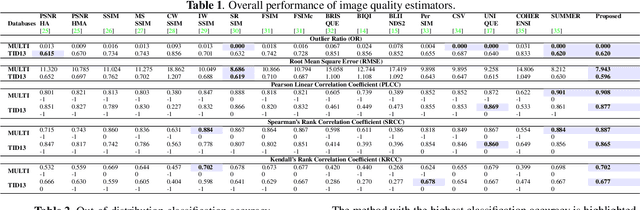
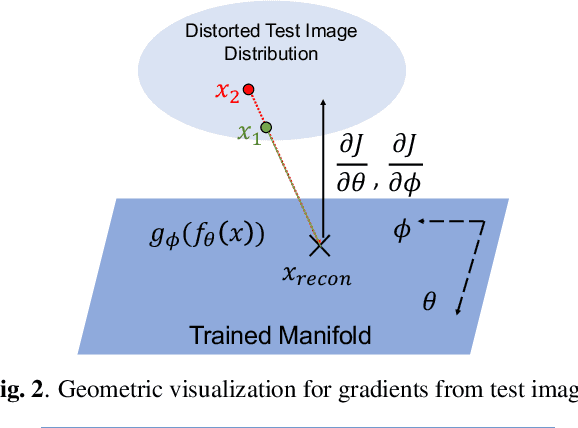
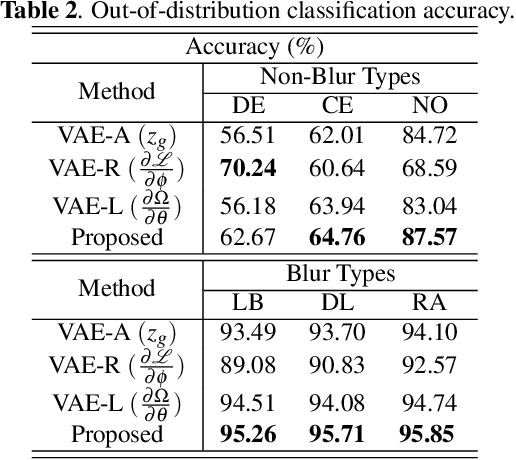
In this paper, we utilize weight gradients from backpropagation to characterize the representation space learned by deep learning algorithms. We demonstrate the utility of such gradients in applications including perceptual image quality assessment and out-of-distribution classification. The applications are chosen to validate the effectiveness of gradients as features when the test image distribution is distorted from the train image distribution. In both applications, the proposed gradient based features outperform activation features. In image quality assessment, the proposed approach is compared with other state of the art approaches and is generally the top performing method on TID 2013 and MULTI-LIVE databases in terms of accuracy, consistency, linearity, and monotonic behavior. Finally, we analyze the effect of regularization on gradients using CURE-TSR dataset for out-of-distribution classification.
RS-MetaNet: Deep meta metric learning for few-shot remote sensing scene classification
Sep 28, 2020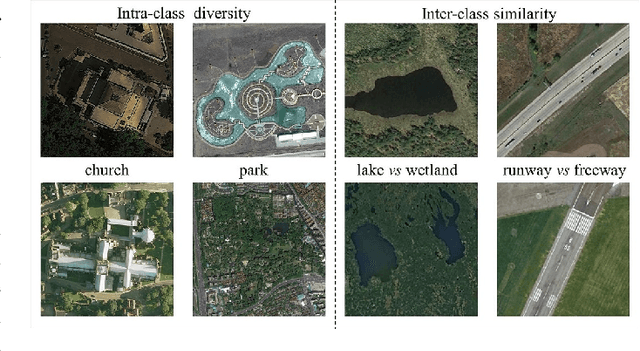
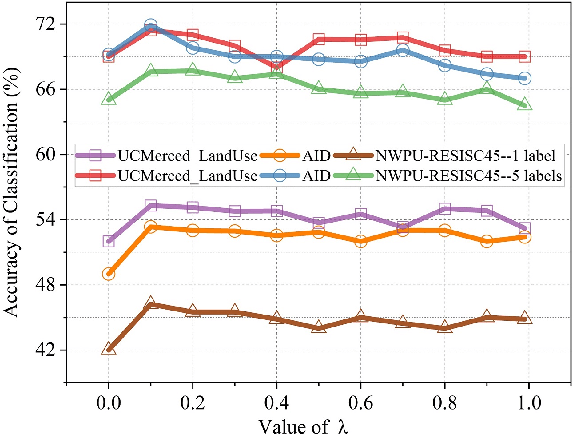
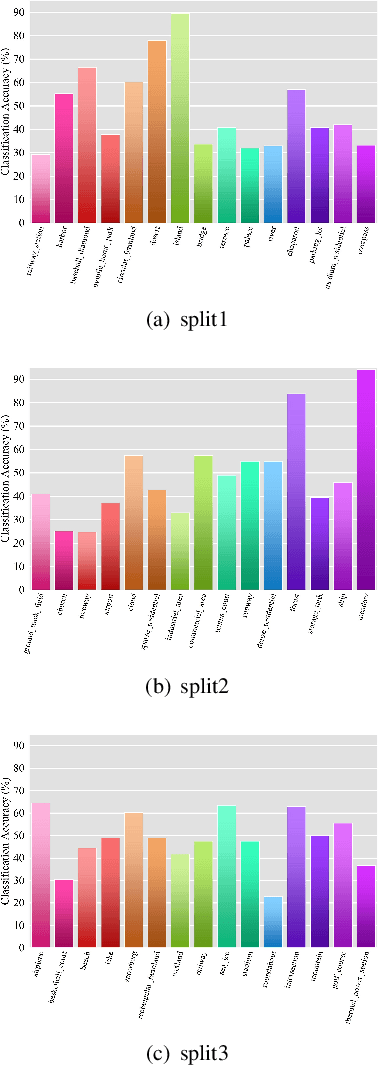
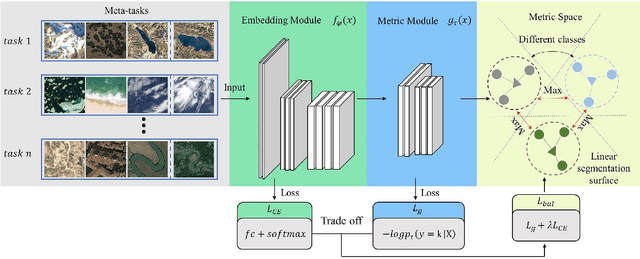
Training a modern deep neural network on massive labeled samples is the main paradigm in solving the scene classification problem for remote sensing, but learning from only a few data points remains a challenge. Existing methods for few-shot remote sensing scene classification are performed in a sample-level manner, resulting in easy overfitting of learned features to individual samples and inadequate generalization of learned category segmentation surfaces. To solve this problem, learning should be organized at the task level rather than the sample level. Learning on tasks sampled from a task family can help tune learning algorithms to perform well on new tasks sampled in that family. Therefore, we propose a simple but effective method, called RS-MetaNet, to resolve the issues related to few-shot remote sensing scene classification in the real world. On the one hand, RS-MetaNet raises the level of learning from the sample to the task by organizing training in a meta way, and it learns to learn a metric space that can well classify remote sensing scenes from a series of tasks. We also propose a new loss function, called Balance Loss, which maximizes the generalization ability of the model to new samples by maximizing the distance between different categories, providing the scenes in different categories with better linear segmentation planes while ensuring model fit. The experimental results on three open and challenging remote sensing datasets, UCMerced\_LandUse, NWPU-RESISC45, and Aerial Image Data, demonstrate that our proposed RS-MetaNet method achieves state-of-the-art results in cases where there are only 1-20 labeled samples.
* 13 pages, 11 figures
An Overview of Deep Learning Architectures in Few-Shot Learning Domain
Aug 19, 2020
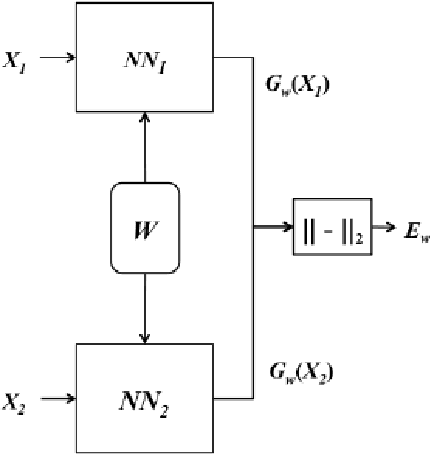
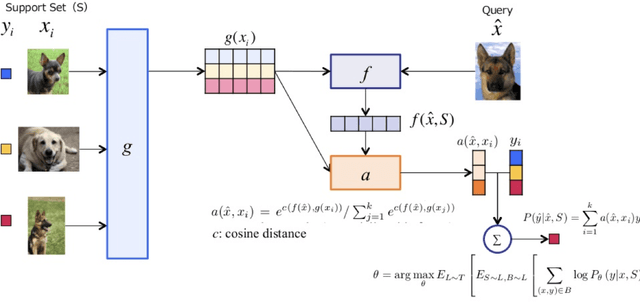
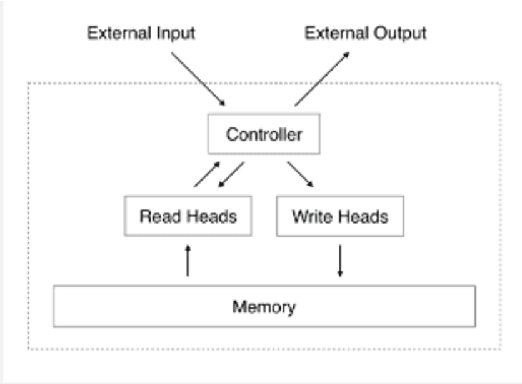
Since 2012, Deep learning has revolutionized Artificial Intelligence and has achieved state-of-the-art outcomes in different domains, ranging from Image Classification to Speech Generation. Though it has many potentials, our current architectures come with the pre-requisite of large amounts of data. Few-Shot Learning (also known as one-shot learning) is a sub-field of machine learning that aims to create such models that can learn the desired objective with less data, similar to how humans learn. In this paper, we have reviewed some of the well-known deep learning-based approaches towards few-shot learning. We have discussed the recent achievements, challenges, and possibilities of improvement of few-shot learning based deep learning architectures. Our aim for this paper is threefold: (i) Give a brief introduction to deep learning architectures for few-shot learning with pointers to core references. (ii) Indicate how deep learning has been applied to the low-data regime, from data preparation to model training. and, (iii) Provide a starting point for people interested in experimenting and perhaps contributing to the field of few-shot learning by pointing out some useful resources and open-source code. Our code is available at Github: https://github.com/shruti-jadon/Hands-on-One-Shot-Learning.
Scene Text Recognition via Transformer
Apr 10, 2020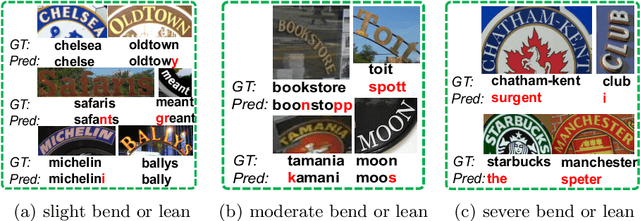
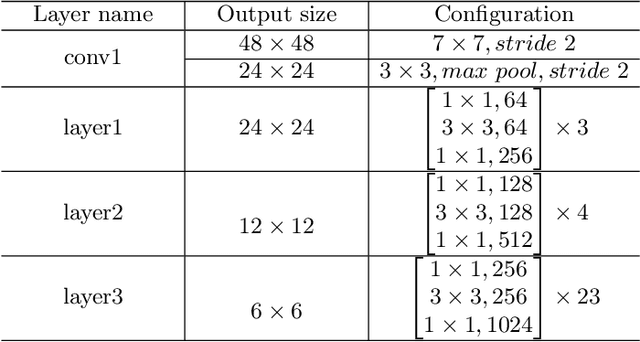
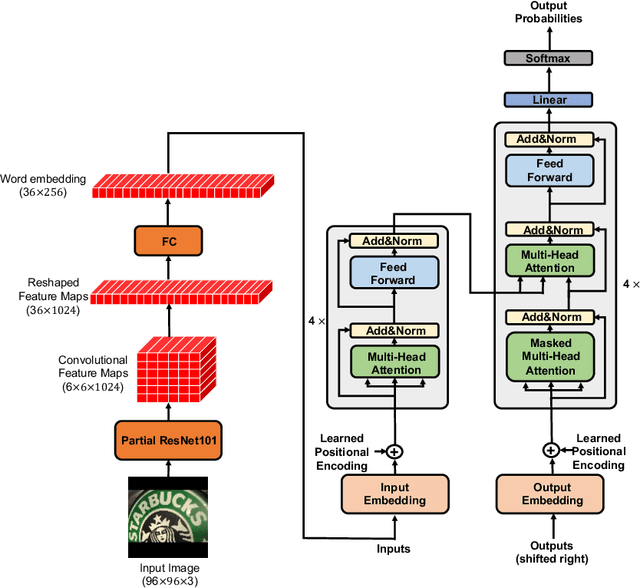
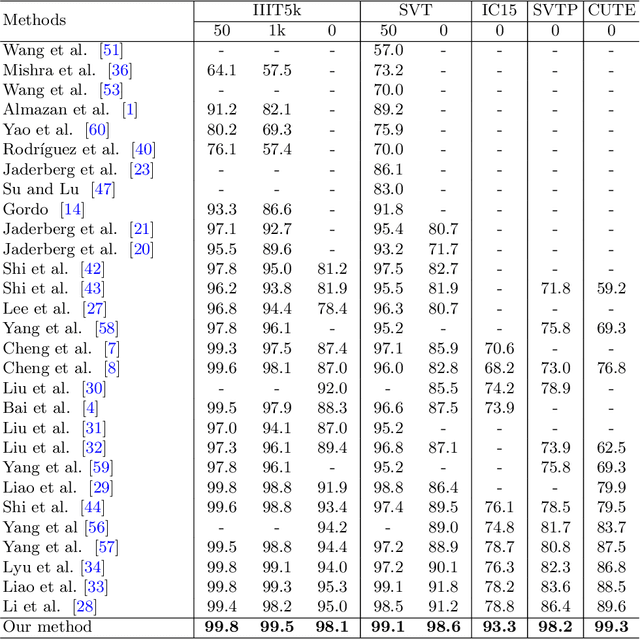
Scene text recognition with arbitrary shape is very challenging due to large variations in text shapes, fonts, colors, backgrounds, etc. Most state-of-the-art algorithms rectify the input image into the normalized image, then treat the recognition as a sequence prediction task. The bottleneck of such methods is the rectification, which will cause errors due to distortion perspective. In this paper, we find that the rectification is completely unnecessary. What all we need is the spatial attention. We therefore propose a simple but extremely effective scene text recognition method based on transformer [50]. Different from previous transformer based models [56,34], which just use the decoder of the transformer to decode the convolutional attention, the proposed method use a convolutional feature maps as word embedding input into transformer. In such a way, our method is able to make full use of the powerful attention mechanism of the transformer. Extensive experimental results show that the proposed method significantly outperforms state-of-the-art methods by a very large margin on both regular and irregular text datasets. On one of the most challenging CUTE dataset whose state-of-the-art prediction accuracy is 89.6%, our method achieves 99.3%, which is a pretty surprising result. We will release our source code and believe that our method will be a new benchmark of scene text recognition with arbitrary shapes.
Automatic Segmentation of Non-Tumor Tissues in Glioma MR Brain Images Using Deformable Registration with Partial Convolutional Networks
Jul 10, 2020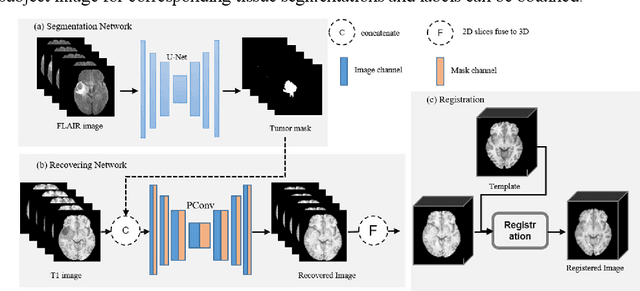

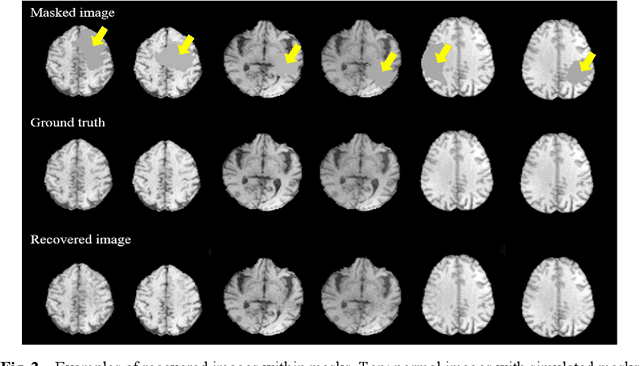
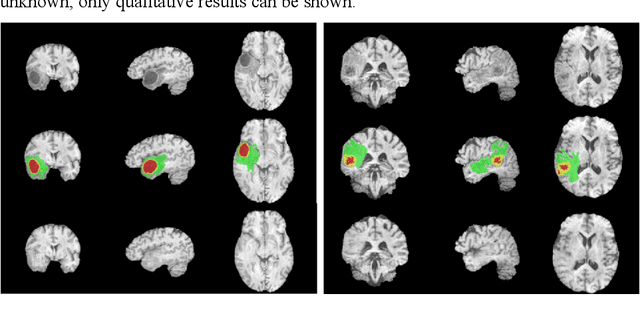
In brain tumor diagnosis and surgical planning, segmentation of tumor regions and accurate analysis of surrounding normal tissues are necessary for physicians. Pathological variability often renders difficulty to register a well-labeled normal atlas to such images and to automatic segment/label surrounding normal brain tissues. In this paper, we propose a new registration approach that first segments brain tumor using a U-Net and then simulates missed normal tissues within the tumor region using a partial convolutional network. Then, a standard normal brain atlas image is registered onto such tumor-removed images in order to segment/label the normal brain tissues. In this way, our new approach greatly reduces the effects of pathological variability in deformable registration and segments the normal tissues surrounding brain tumor well. In experiments, we used MICCAI BraTS2018 T1 tumor images to evaluate the proposed algorithm. By comparing direct registration with the proposed algorithm, the results showed that the Dice coefficient for gray matters was significantly improved for surrounding normal brain tissues.
Boundary Guidance Hierarchical Network for Real-Time Tongue Segmentation
Mar 14, 2020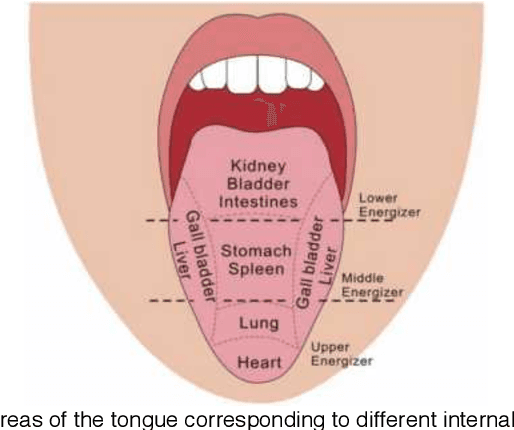
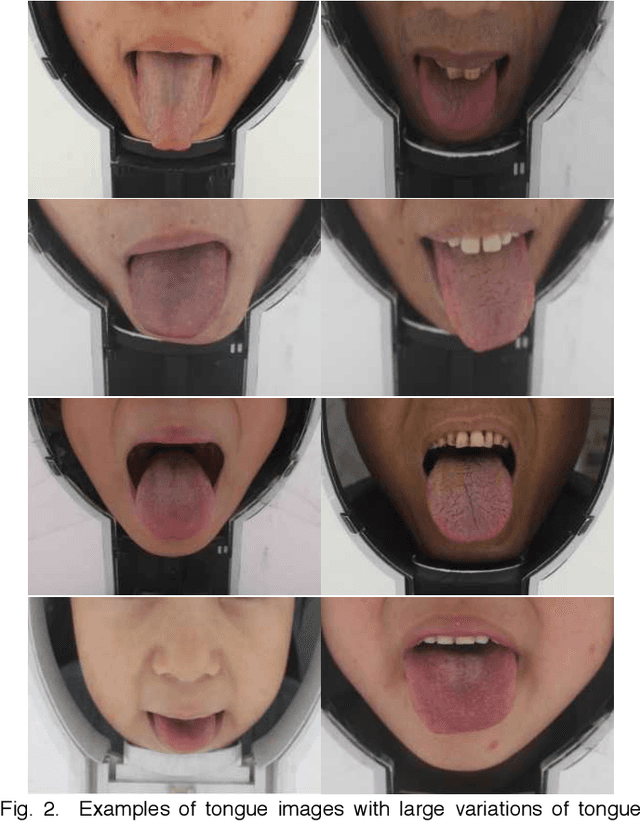
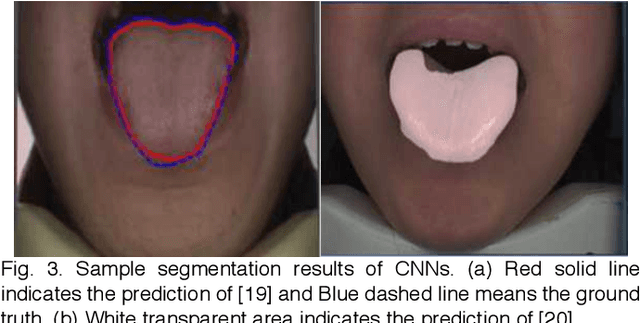
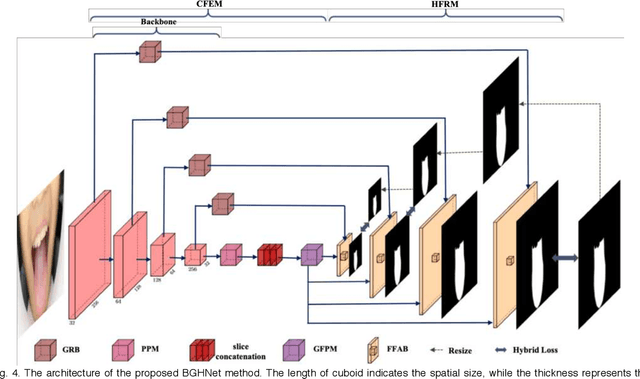
Automated tongue image segmentation in tongue images is a challenging task for two reasons: 1) there are many pathological details on the tongue surface, which affect the extraction of the boundary; 2) the shapes of the tongues captured from various persons (with different diseases) are quite different. To deal with the challenge, a novel end-to-end Boundary Guidance Hierarchical Network (BGHNet) with a new hybrid loss is proposed in this paper. In the new approach, firstly Context Feature Encoder Module (CFEM) is built upon the bottomup pathway to confront with the shrinkage of the receptive field. Secondly, a novel hierarchical recurrent feature fusion module (HRFFM) is adopt to progressively and hierarchically refine object maps to recover image details by integrating local context information. Finally, the proposed hybrid loss in a four hierarchy-pixel, patch, map and boundary guides the network to effectively segment the tongue regions and accurate tongue boundaries. BGHNet is applied to a set of tongue images. The experimental results suggest that the proposed approach can achieve the latest tongue segmentation performance. And in the meantime, the lightweight network contains only 15.45M parameters and performs only 11.22GFLOPS.
NanoFlow: Scalable Normalizing Flows with Sublinear Parameter Complexity
Jun 15, 2020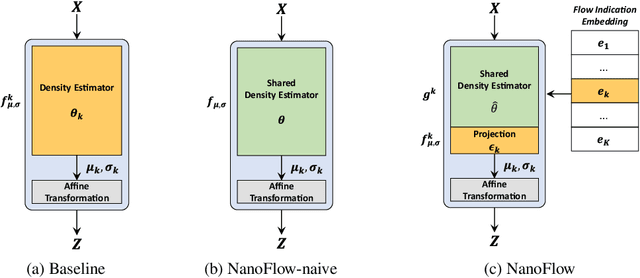
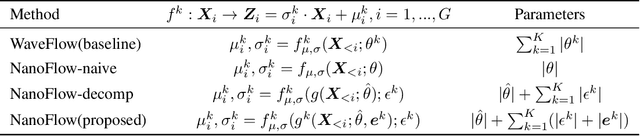
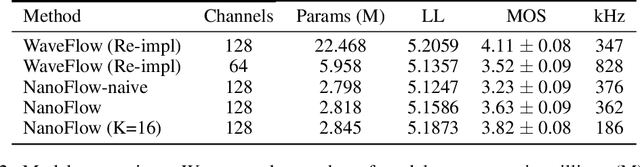
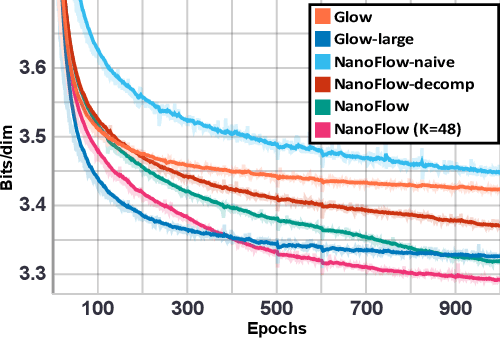
Normalizing flows (NFs) have become a prominent method for deep generative models that allow for an analytic probability density estimation and efficient synthesis. However, a flow-based network is considered to be inefficient in parameter complexity because of reduced expressiveness of bijective mapping, which renders the models prohibitively expensive in terms of parameters. We present an alternative of parameterization scheme, called NanoFlow, which uses a single neural density estimator to model multiple transformation stages. Hence, we propose an efficient parameter decomposition method and the concept of flow indication embedding, which are key missing components that enable density estimation from a single neural network. Experiments performed on audio and image models confirm that our method provides a new parameter-efficient solution for scalable NFs with significantly sublinear parameter complexity.
Hard negative examples are hard, but useful
Jul 24, 2020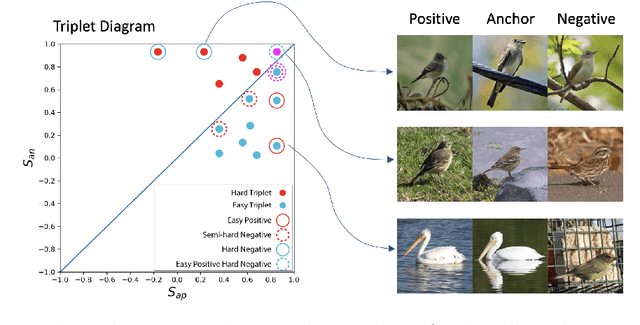
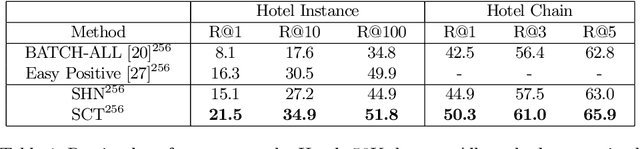

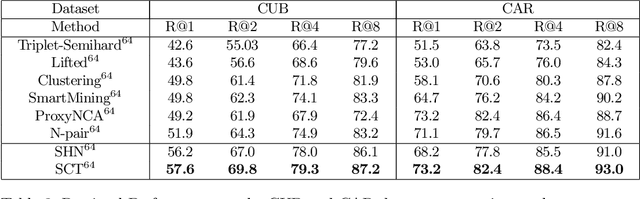
Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.
Bio-Inspired Foveated Technique for Augmented-Range Vehicle Detection Using Deep Neural Networks
Oct 02, 2019

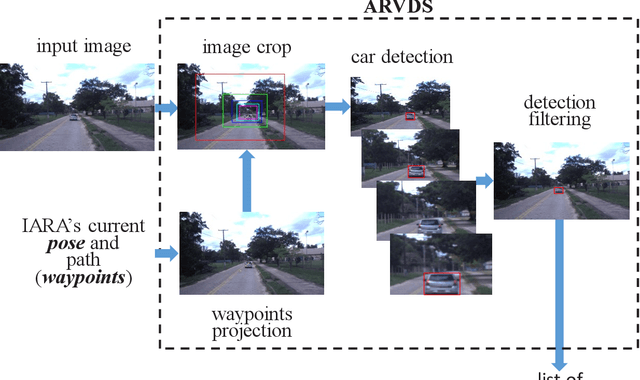
We propose a bio-inspired foveated technique to detect cars in a long range camera view using a deep convolutional neural network (DCNN) for the IARA self-driving car. The DCNN receives as input (i) an image, which is captured by a camera installed on IARA's roof; and (ii) crops of the image, which are centered in the waypoints computed by IARA's path planner and whose sizes increase with the distance from IARA. We employ an overlap filter to discard detections of the same car in different crops of the same image based on the percentage of overlap of detections' bounding boxes. We evaluated the performance of the proposed augmented-range vehicle detection system (ARVDS) using the hardware and software infrastructure available in the IARA self-driving car. Using IARA, we captured thousands of images of real traffic situations containing cars in a long range. Experimental results show that ARVDS increases the Average Precision (AP) of long range car detection from 29.51% (using a single whole image) to 63.15%.
Real-world Person Re-Identification via Degradation Invariance Learning
Apr 10, 2020


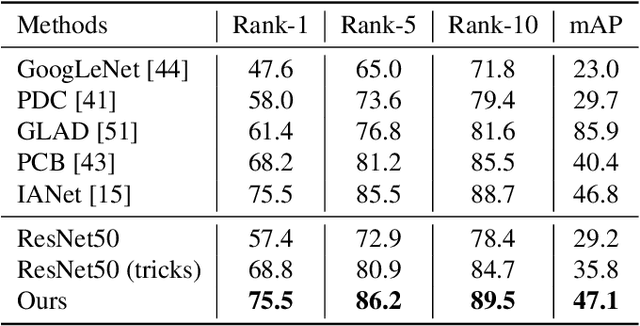
Person re-identification (Re-ID) in real-world scenarios usually suffers from various degradation factors, e.g., low-resolution, weak illumination, blurring and adverse weather. On the one hand, these degradations lead to severe discriminative information loss, which significantly obstructs identity representation learning; on the other hand, the feature mismatch problem caused by low-level visual variations greatly reduces retrieval performance. An intuitive solution to this problem is to utilize low-level image restoration methods to improve the image quality. However, existing restoration methods cannot directly serve to real-world Re-ID due to various limitations, e.g., the requirements of reference samples, domain gap between synthesis and reality, and incompatibility between low-level and high-level methods. In this paper, to solve the above problem, we propose a degradation invariance learning framework for real-world person Re-ID. By introducing a self-supervised disentangled representation learning strategy, our method is able to simultaneously extract identity-related robust features and remove real-world degradations without extra supervision. We use low-resolution images as the main demonstration, and experiments show that our approach is able to achieve state-of-the-art performance on several Re-ID benchmarks. In addition, our framework can be easily extended to other real-world degradation factors, such as weak illumination, with only a few modifications.