 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition via Transformer
Paper and Code
Apr 10, 2020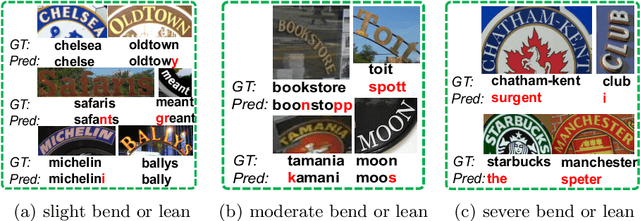
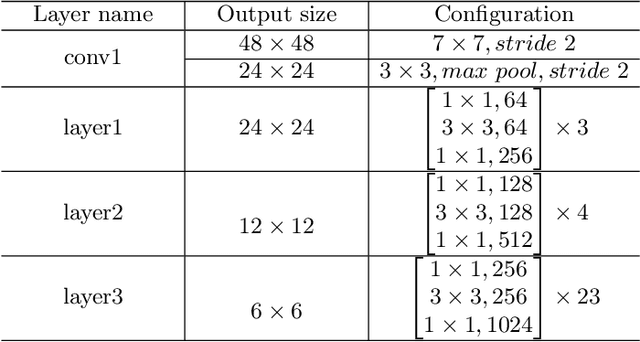
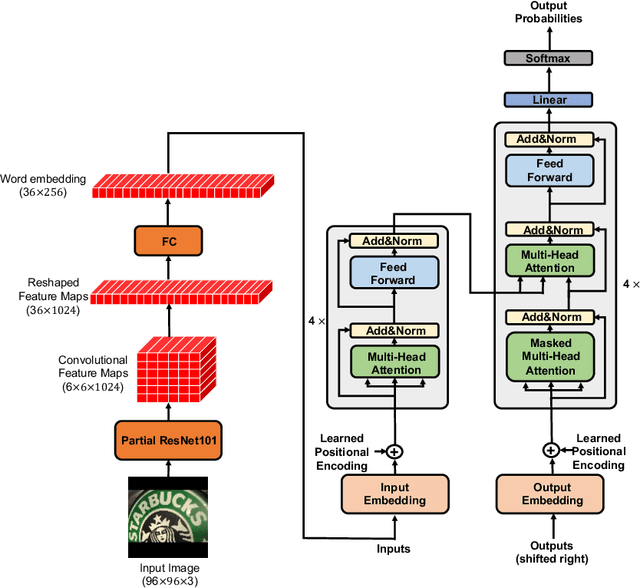
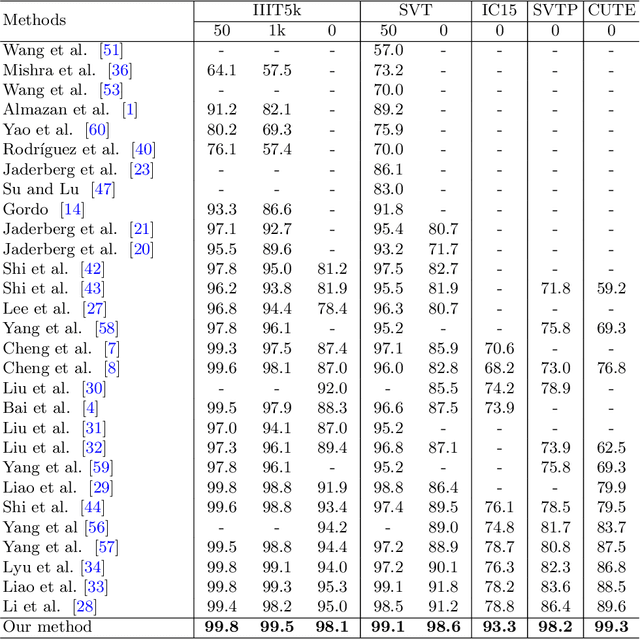
Scene text recognition with arbitrary shape is very challenging due to large variations in text shapes, fonts, colors, backgrounds, etc. Most state-of-the-art algorithms rectify the input image into the normalized image, then treat the recognition as a sequence prediction task. The bottleneck of such methods is the rectification, which will cause errors due to distortion perspective. In this paper, we find that the rectification is completely unnecessary. What all we need is the spatial attention. We therefore propose a simple but extremely effective scene text recognition method based on transformer [50]. Different from previous transformer based models [56,34], which just use the decoder of the transformer to decode the convolutional attention, the proposed method use a convolutional feature maps as word embedding input into transformer. In such a way, our method is able to make full use of the powerful attention mechanism of the transformer. Extensive experimental results show that the proposed method significantly outperforms state-of-the-art methods by a very large margin on both regular and irregular text datasets. On one of the most challenging CUTE dataset whose state-of-the-art prediction accuracy is 89.6%, our method achieves 99.3%, which is a pretty surprising result. We will release our source code and believe that our method will be a new benchmark of scene text recognition with arbitrary shapes.