 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocalAD: Local Motion Planning for End-to-End Autonomous Driving
Jun 13, 2025In end-to-end autonomous driving,the motion prediction plays a pivotal role in ego-vehicle planning. However, existing methods often rely on globally aggregated motion features, ignoring the fact that planning decisions are primarily influenced by a small number of locally interacting agents. Failing to attend to these critical local interactions can obscure potential risks and undermine planning reliability. In this work, we propose FocalAD, a novel end-to-end autonomous driving framework that focuses on critical local neighbors and refines planning by enhancing local motion representations. Specifically, FocalAD comprises two core modules: the Ego-Local-Agents Interactor (ELAI) and the Focal-Local-Agents Loss (FLA Loss). ELAI conducts a graph-based ego-centric interaction representation that captures motion dynamics with local neighbors to enhance both ego planning and agent motion queries. FLA Loss increases the weights of decision-critical neighboring agents, guiding the model to prioritize those more relevant to planning. Extensive experiments show that FocalAD outperforms existing state-of-the-art methods on the open-loop nuScenes datasets and closed-loop Bench2Drive benchmark. Notably, on the robustness-focused Adv-nuScenes dataset, FocalAD achieves even greater improvements, reducing the average colilision rate by 41.9% compared to DiffusionDrive and by 15.6% compared to SparseDrive.
A Multi-modal Fusion Network for Terrain Perception Based on Illumination Aware
May 16, 2025Road terrains play a crucial role in ensuring the driving safety of autonomous vehicles (AVs). However, existing sensors of AVs, including cameras and Lidars, are susceptible to variations in lighting and weather conditions, making it challenging to achieve real-time perception of road conditions. In this paper, we propose an illumination-aware multi-modal fusion network (IMF), which leverages both exteroceptive and proprioceptive perception and optimizes the fusion process based on illumination features. We introduce an illumination-perception sub-network to accurately estimate illumination features. Moreover, we design a multi-modal fusion network which is able to dynamically adjust weights of different modalities according to illumination features. We enhance the optimization process by pre-training of the illumination-perception sub-network and incorporating illumination loss as one of the training constraints. Extensive experiments demonstrate that the IMF shows a superior performance compared to state-of-the-art methods. The comparison results with single modality perception methods highlight the comprehensive advantages of multi-modal fusion in accurately perceiving road terrains under varying lighting conditions. Our dataset is available at: https://github.com/lindawang2016/IMF.
Scene Text Recognition via Transformer
Apr 10, 2020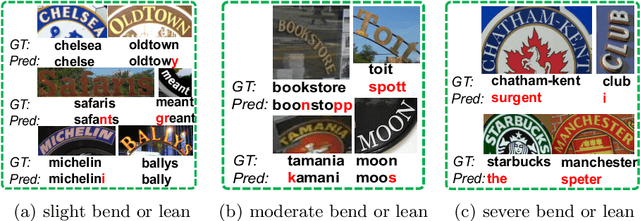
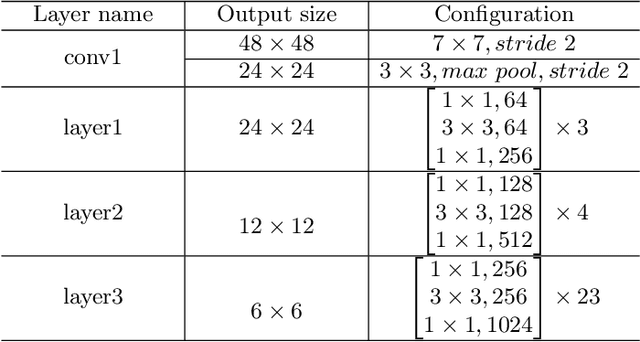
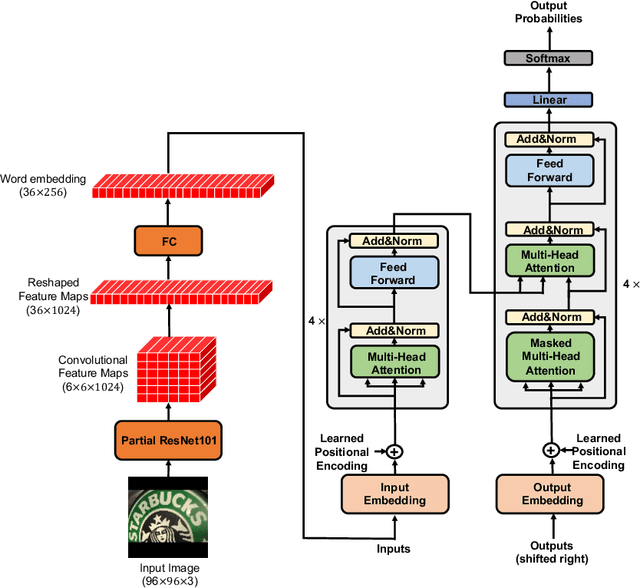
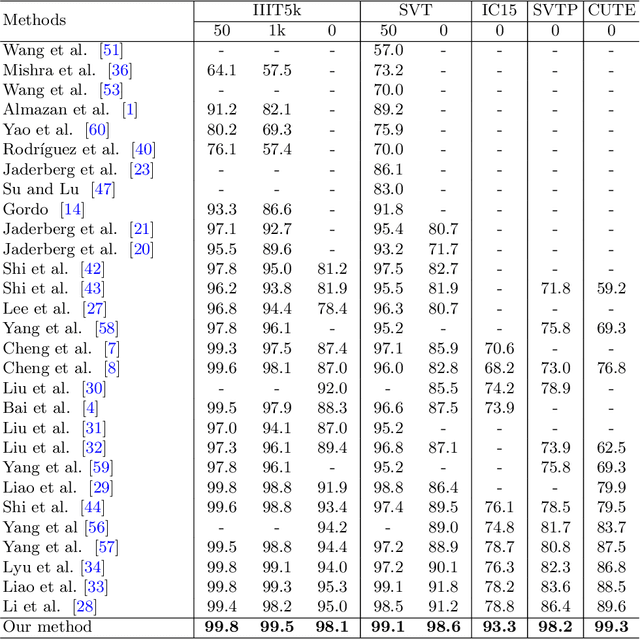
Scene text recognition with arbitrary shape is very challenging due to large variations in text shapes, fonts, colors, backgrounds, etc. Most state-of-the-art algorithms rectify the input image into the normalized image, then treat the recognition as a sequence prediction task. The bottleneck of such methods is the rectification, which will cause errors due to distortion perspective. In this paper, we find that the rectification is completely unnecessary. What all we need is the spatial attention. We therefore propose a simple but extremely effective scene text recognition method based on transformer [50]. Different from previous transformer based models [56,34], which just use the decoder of the transformer to decode the convolutional attention, the proposed method use a convolutional feature maps as word embedding input into transformer. In such a way, our method is able to make full use of the powerful attention mechanism of the transformer. Extensive experimental results show that the proposed method significantly outperforms state-of-the-art methods by a very large margin on both regular and irregular text datasets. On one of the most challenging CUTE dataset whose state-of-the-art prediction accuracy is 89.6%, our method achieves 99.3%, which is a pretty surprising result. We will release our source code and believe that our method will be a new benchmark of scene text recognition with arbitrary shapes.