 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 27, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Will It Zero-Shot?: Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 24, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
ConText-CIR: Learning from Concepts in Text for Composed Image Retrieval
May 27, 2025



Composed image retrieval (CIR) is the task of retrieving a target image specified by a query image and a relative text that describes a semantic modification to the query image. Existing methods in CIR struggle to accurately represent the image and the text modification, resulting in subpar performance. To address this limitation, we introduce a CIR framework, ConText-CIR, trained with a Text Concept-Consistency loss that encourages the representations of noun phrases in the text modification to better attend to the relevant parts of the query image. To support training with this loss function, we also propose a synthetic data generation pipeline that creates training data from existing CIR datasets or unlabeled images. We show that these components together enable stronger performance on CIR tasks, setting a new state-of-the-art in composed image retrieval in both the supervised and zero-shot settings on multiple benchmark datasets, including CIRR and CIRCO. Source code, model checkpoints, and our new datasets are available at https://github.com/mvrl/ConText-CIR.
QuARI: Query Adaptive Retrieval Improvement
May 27, 2025



Massive-scale pretraining has made vision-language models increasingly popular for image-to-image and text-to-image retrieval across a broad collection of domains. However, these models do not perform well when used for challenging retrieval tasks, such as instance retrieval in very large-scale image collections. Recent work has shown that linear transformations of VLM features trained for instance retrieval can improve performance by emphasizing subspaces that relate to the domain of interest. In this paper, we explore a more extreme version of this specialization by learning to map a given query to a query-specific feature space transformation. Because this transformation is linear, it can be applied with minimal computational cost to millions of image embeddings, making it effective for large-scale retrieval or re-ranking. Results show that this method consistently outperforms state-of-the-art alternatives, including those that require many orders of magnitude more computation at query time.
Dissecting the impact of different loss functions with gradient surgery
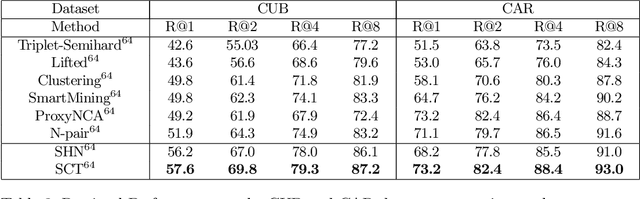
Jan 27, 2022Pair-wise loss is an approach to metric learning that learns a semantic embedding by optimizing a loss function that encourages images from the same semantic class to be mapped closer than images from different classes. The literature reports a large and growing set of variations of the pair-wise loss strategies. Here we decompose the gradient of these loss functions into components that relate to how they push the relative feature positions of the anchor-positive and anchor-negative pairs. This decomposition allows the unification of a large collection of current pair-wise loss functions. Additionally, explicitly constructing pair-wise gradient updates to separate out these effects gives insights into which have the biggest impact, and leads to a simple algorithm that beats the state of the art for image retrieval on the CAR, CUB and Stanford Online products datasets.
Classification and Visualization of Genotype x Phenotype Interactions in Biomass Sorghum
Aug 09, 2021
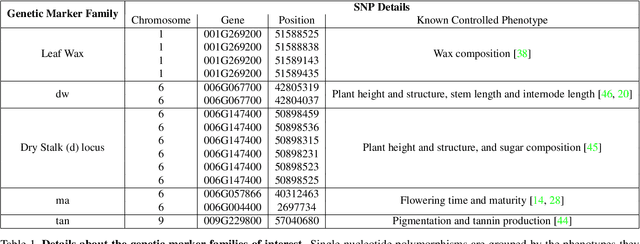

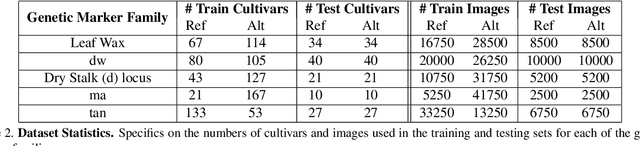
We introduce a simple approach to understanding the relationship between single nucleotide polymorphisms (SNPs), or groups of related SNPs, and the phenotypes they control. The pipeline involves training deep convolutional neural networks (CNNs) to differentiate between images of plants with reference and alternate versions of various SNPs, and then using visualization approaches to highlight what the classification networks key on. We demonstrate the capacity of deep CNNs at performing this classification task, and show the utility of these visualizations on RGB imagery of biomass sorghum captured by the TERRA-REF gantry. We focus on several different genetic markers with known phenotypic expression, and discuss the possibilities of using this approach to uncover genotype x phenotype relationships.
DCAP: Deep Cross Attentional Product Network for User Response Prediction
May 18, 2021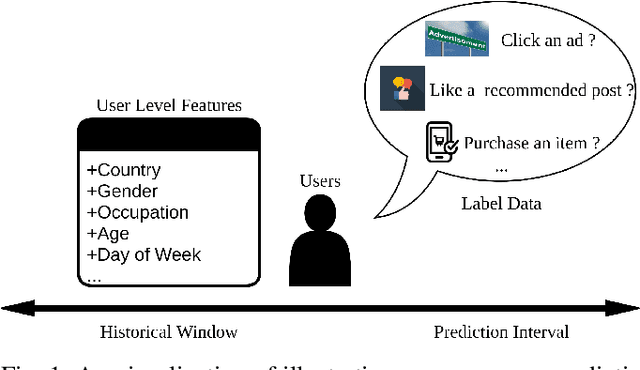
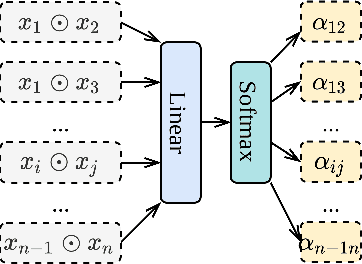
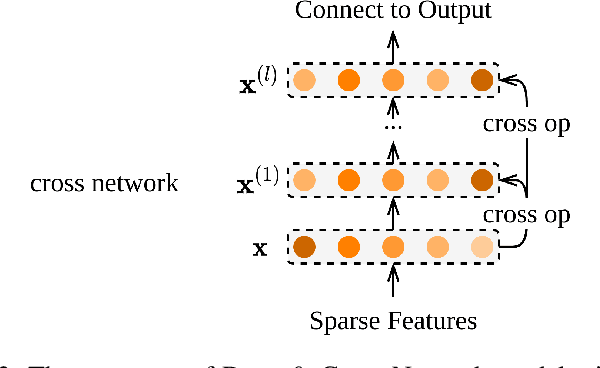
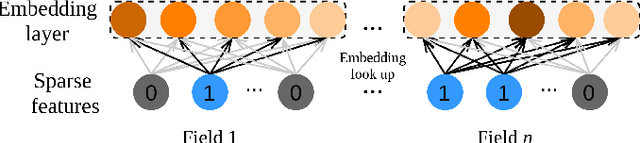
User response prediction, which aims to predict the probability that a user will provide a predefined positive response in a given context such as clicking on an ad or purchasing an item, is crucial to many industrial applications such as online advertising, recommender systems, and search ranking. However, due to the high dimensionality and super sparsity of the data collected in these tasks, handcrafting cross features is inevitably time expensive. Prior studies in predicting user response leveraged the feature interactions by enhancing feature vectors with products of features to model second-order or high-order cross features, either explicitly or implicitly. Nevertheless, these existing methods can be hindered by not learning sufficient cross features due to model architecture limitations or modeling all high-order feature interactions with equal weights. This work aims to fill this gap by proposing a novel architecture Deep Cross Attentional Product Network (DCAP), which keeps cross network's benefits in modeling high-order feature interactions explicitly at the vector-wise level. Beyond that, it can differentiate the importance of different cross features in each network layer inspired by the multi-head attention mechanism and Product Neural Network (PNN), allowing practitioners to perform a more in-depth analysis of user behaviors. Additionally, our proposed model can be easily implemented and train in parallel. We conduct comprehensive experiments on three real-world datasets. The results have robustly demonstrated that our proposed model DCAP achieves superior prediction performance compared with the state-of-the-art models.
Hard negative examples are hard, but useful
Jul 24, 2020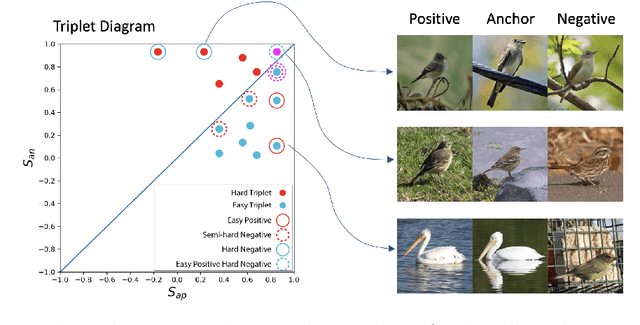

Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.
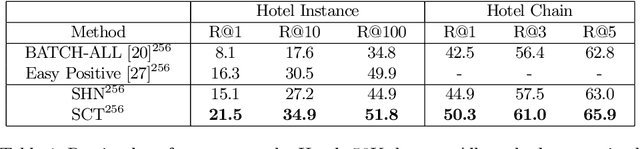
TraffickCam: Explainable Image Matching For Sex Trafficking Investigations
Oct 08, 2019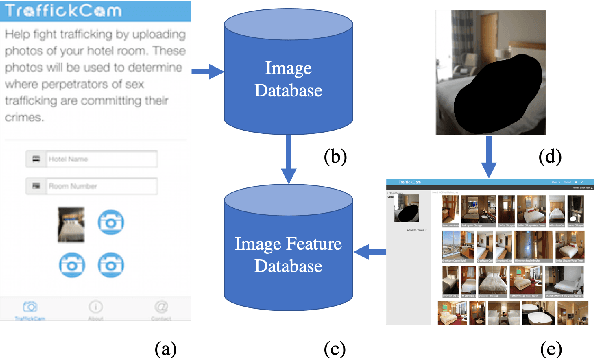
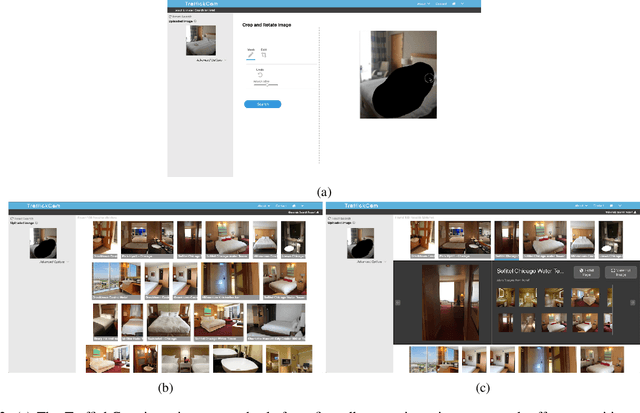

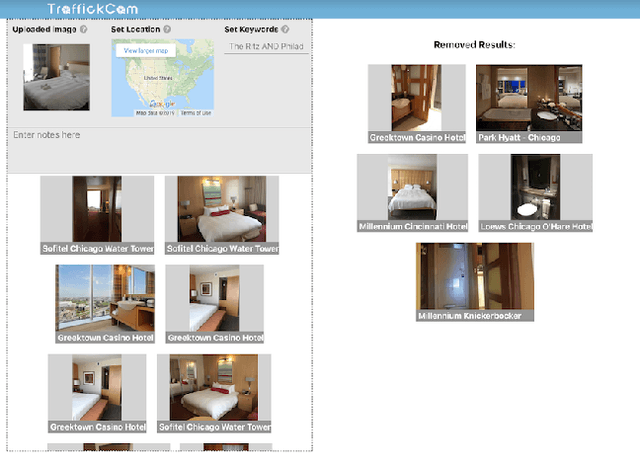
Investigations of sex trafficking sometimes have access to photographs of victims in hotel rooms. These images directly link victims to places, which can help verify where victims have been trafficked or where traffickers might operate in the future. Current machine learning approaches give promising results in image search to find the matching hotel. This paper explores approaches to make this end-to-end system better support government and law enforcement requirements, including improved performance, visualization approaches that explain what parts of the image led to a match, and infrastructure to support exporting the results of a query.
Learning Geo-Temporal Image Features
Sep 16, 2019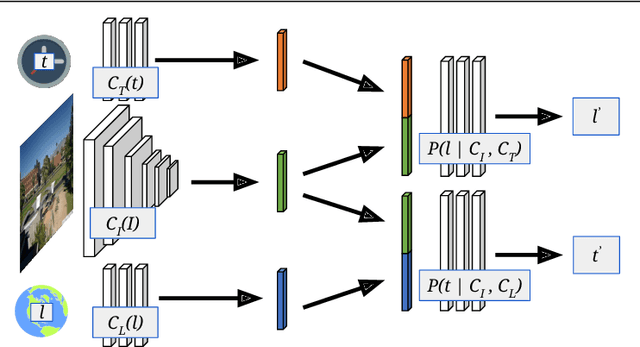

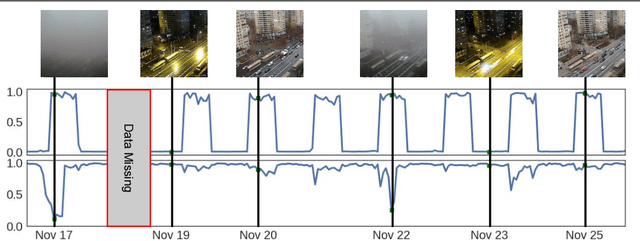
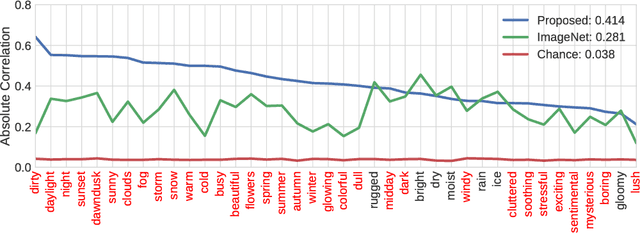
We propose to implicitly learn to extract geo-temporal image features, which are mid-level features related to when and where an image was captured, by explicitly optimizing for a set of location and time estimation tasks. To train our method, we take advantage of a large image dataset, captured by outdoor webcams and cell phones. The only form of supervision we provide are the known capture time and location of each image. We find that our approach learns features that are related to natural appearance changes in outdoor scenes. Additionally, we demonstrate the application of these geo-temporal features to time and location estimation.