 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 27, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Will It Zero-Shot?: Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 24, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
QuARI: Query Adaptive Retrieval Improvement
May 27, 2025



Massive-scale pretraining has made vision-language models increasingly popular for image-to-image and text-to-image retrieval across a broad collection of domains. However, these models do not perform well when used for challenging retrieval tasks, such as instance retrieval in very large-scale image collections. Recent work has shown that linear transformations of VLM features trained for instance retrieval can improve performance by emphasizing subspaces that relate to the domain of interest. In this paper, we explore a more extreme version of this specialization by learning to map a given query to a query-specific feature space transformation. Because this transformation is linear, it can be applied with minimal computational cost to millions of image embeddings, making it effective for large-scale retrieval or re-ranking. Results show that this method consistently outperforms state-of-the-art alternatives, including those that require many orders of magnitude more computation at query time.
ConText-CIR: Learning from Concepts in Text for Composed Image Retrieval
May 27, 2025



Composed image retrieval (CIR) is the task of retrieving a target image specified by a query image and a relative text that describes a semantic modification to the query image. Existing methods in CIR struggle to accurately represent the image and the text modification, resulting in subpar performance. To address this limitation, we introduce a CIR framework, ConText-CIR, trained with a Text Concept-Consistency loss that encourages the representations of noun phrases in the text modification to better attend to the relevant parts of the query image. To support training with this loss function, we also propose a synthetic data generation pipeline that creates training data from existing CIR datasets or unlabeled images. We show that these components together enable stronger performance on CIR tasks, setting a new state-of-the-art in composed image retrieval in both the supervised and zero-shot settings on multiple benchmark datasets, including CIRR and CIRCO. Source code, model checkpoints, and our new datasets are available at https://github.com/mvrl/ConText-CIR.
Design and Evaluation of Camera-Centric Mobile Crowdsourcing Applications
Sep 04, 2024



The data that underlies automated methods in computer vision and machine learning, such as image retrieval and fine-grained recognition, often comes from crowdsourcing. In contexts that rely on the intrinsic motivation of users, we seek to understand how the application design affects a user's willingness to contribute and the quantity and quality of the data they capture. In this project, we designed three versions of a camera-based mobile crowdsourcing application, which varied in the amount of labeling effort requested of the user and conducted a user study to evaluate the trade-off between the level of user-contributed information requested and the quantity and quality of labeled images collected. The results suggest that higher levels of user labeling do not lead to reduced contribution. Users collected and annotated the most images using the application version with the highest requested level of labeling with no decrease in user satisfaction. In preliminary experiments, the additional labeled data supported increased performance on an image retrieval task.
Vision-Language Pseudo-Labels for Single-Positive Multi-Label Learning
Oct 24, 2023



This paper presents a novel approach to Single-Positive Multi-label Learning. In general multi-label learning, a model learns to predict multiple labels or categories for a single input image. This is in contrast with standard multi-class image classification, where the task is predicting a single label from many possible labels for an image. Single-Positive Multi-label Learning (SPML) specifically considers learning to predict multiple labels when there is only a single annotation per image in the training data. Multi-label learning is in many ways a more realistic task than single-label learning as real-world data often involves instances belonging to multiple categories simultaneously; however, most common computer vision datasets predominantly contain single labels due to the inherent complexity and cost of collecting multiple high quality annotations for each instance. We propose a novel approach called Vision-Language Pseudo-Labeling (VLPL), which uses a vision-language model to suggest strong positive and negative pseudo-labels, and outperforms the current SOTA methods by 5.5% on Pascal VOC, 18.4% on MS-COCO, 15.2% on NUS-WIDE, and 8.4% on CUB-Birds. Our code and data are available at https://github.com/mvrl/VLPL.
What Does TERRA-REF's High Resolution, Multi Sensor Plant Sensing Public Domain Data Offer the Computer Vision Community?
Aug 18, 2021
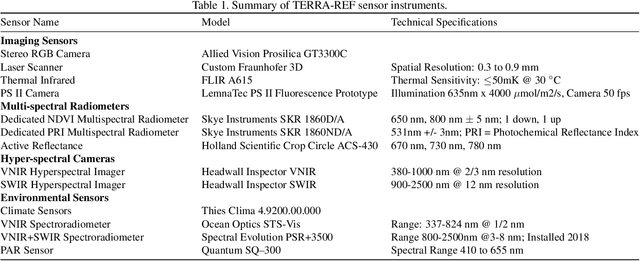


A core objective of the TERRA-REF project was to generate an open-access reference dataset for the evaluation of sensing technologies to study plants under field conditions. The TERRA-REF program deployed a suite of high-resolution, cutting edge technology sensors on a gantry system with the aim of scanning 1 hectare (10$^4$) at around 1 mm$^2$ spatial resolution multiple times per week. The system contains co-located sensors including a stereo-pair RGB camera, a thermal imager, a laser scanner to capture 3D structure, and two hyperspectral cameras covering wavelengths of 300-2500nm. This sensor data is provided alongside over sixty types of traditional plant phenotype measurements that can be used to train new machine learning models. Associated weather and environmental measurements, information about agronomic management and experimental design, and the genomic sequences of hundreds of plant varieties have been collected and are available alongside the sensor and plant phenotype data. Over the course of four years and ten growing seasons, the TERRA-REF system generated over 1 PB of sensor data and almost 45 million files. The subset that has been released to the public domain accounts for two seasons and about half of the total data volume. This provides an unprecedented opportunity for investigations far beyond the core biological scope of the project. The focus of this paper is to provide the Computer Vision and Machine Learning communities an overview of the available data and some potential applications of this one of a kind data.
Classification and Visualization of Genotype x Phenotype Interactions in Biomass Sorghum
Aug 09, 2021
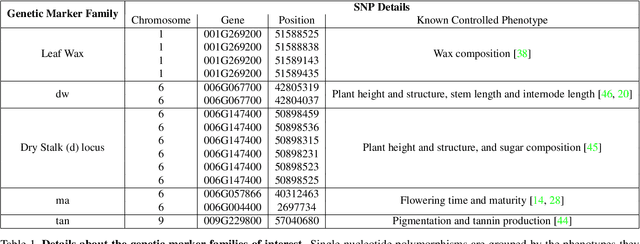

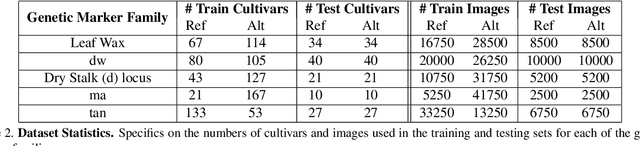
We introduce a simple approach to understanding the relationship between single nucleotide polymorphisms (SNPs), or groups of related SNPs, and the phenotypes they control. The pipeline involves training deep convolutional neural networks (CNNs) to differentiate between images of plants with reference and alternate versions of various SNPs, and then using visualization approaches to highlight what the classification networks key on. We demonstrate the capacity of deep CNNs at performing this classification task, and show the utility of these visualizations on RGB imagery of biomass sorghum captured by the TERRA-REF gantry. We focus on several different genetic markers with known phenotypic expression, and discuss the possibilities of using this approach to uncover genotype x phenotype relationships.
Multi-resolution Outlier Pooling for Sorghum Classification
Jun 22, 2021
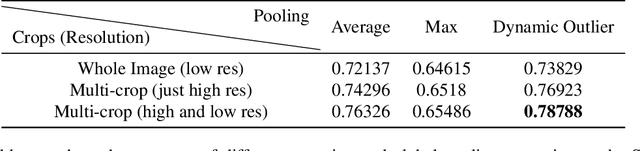


Automated high throughput plant phenotyping involves leveraging sensors, such as RGB, thermal and hyperspectral cameras (among others), to make large scale and rapid measurements of the physical properties of plants for the purpose of better understanding the difference between crops and facilitating rapid plant breeding programs. One of the most basic phenotyping tasks is to determine the cultivar, or species, in a particular sensor product. This simple phenotype can be used to detect errors in planting and to learn the most differentiating features between cultivars. It is also a challenging visual recognition task, as a large number of highly related crops are grown simultaneously, leading to a classification problem with low inter-class variance. In this paper, we introduce the Sorghum-100 dataset, a large dataset of RGB imagery of sorghum captured by a state-of-the-art gantry system, a multi-resolution network architecture that learns both global and fine-grained features on the crops, and a new global pooling strategy called Dynamic Outlier Pooling which outperforms standard global pooling strategies on this task.
The 2021 Hotel-ID to Combat Human Trafficking Competition Dataset
Jun 14, 2021
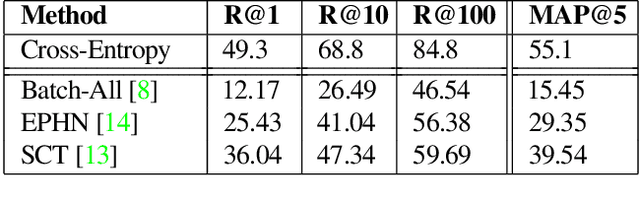

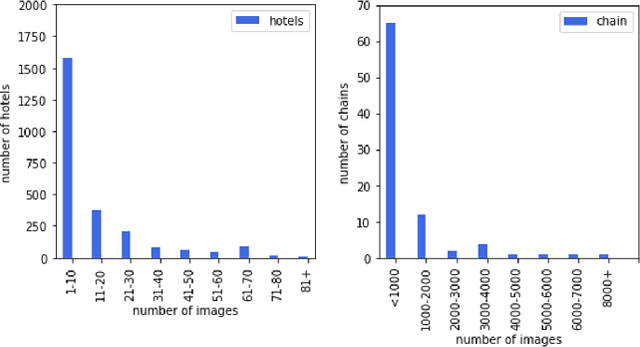
Hotel recognition is an important task for human trafficking investigations since victims are often photographed in hotel rooms. Identifying these hotels is vital to trafficking investigations since they can help track down current and future victims who might be taken to the same places. Hotel recognition is a challenging fine grained visual classification task as there can be little similarity between different rooms within the same hotel, and high similarity between rooms from different hotels (especially if they are from the same chain). Hotel recognition to combat human trafficking poses additional challenges as investigative images are often low quality, contain uncommon camera angles and are highly occluded. Here, we present the 2021 Hotel-ID dataset to help raise awareness for this problem and generate novel approaches. The dataset consists of hotel room images that have been crowd-sourced and uploaded through the TraffickCam mobile application. The quality of these images is similar to investigative images and hence models trained on these images have good chances of accurately narrowing down on the correct hotel.