 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Addressing Class Imbalance in Scene Graph Parsing by Learning to Contrast and Score
Oct 05, 2020
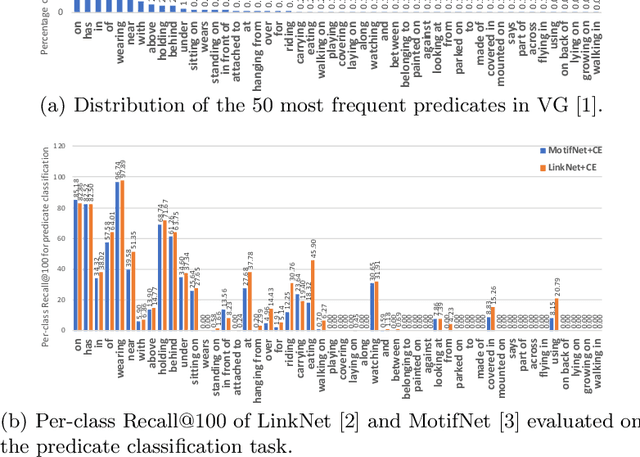
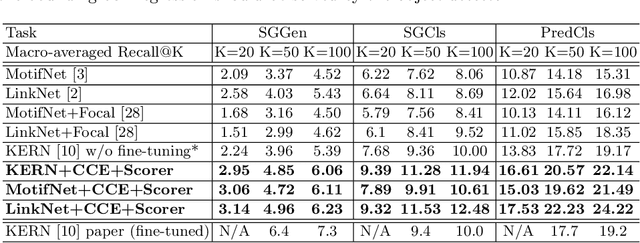
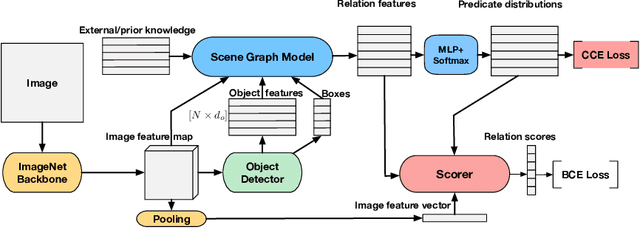
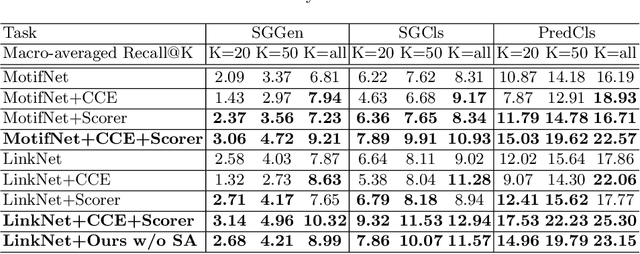
Scene graph parsing aims to detect objects in an image scene and recognize their relations. Recent approaches have achieved high average scores on some popular benchmarks, but fail in detecting rare relations, as the highly long-tailed distribution of data biases the learning towards frequent labels. Motivated by the fact that detecting these rare relations can be critical in real-world applications, this paper introduces a novel integrated framework of classification and ranking to resolve the class imbalance problem in scene graph parsing. Specifically, we design a new Contrasting Cross-Entropy loss, which promotes the detection of rare relations by suppressing incorrect frequent ones. Furthermore, we propose a novel scoring module, termed as Scorer, which learns to rank the relations based on the image features and relation features to improve the recall of predictions. Our framework is simple and effective, and can be incorporated into current scene graph models. Experimental results show that the proposed approach improves the current state-of-the-art methods, with a clear advantage of detecting rare relations.
Scan-Specific MRI Reconstruction using Zero-Shot Physics-Guided Deep Learning
Feb 15, 2021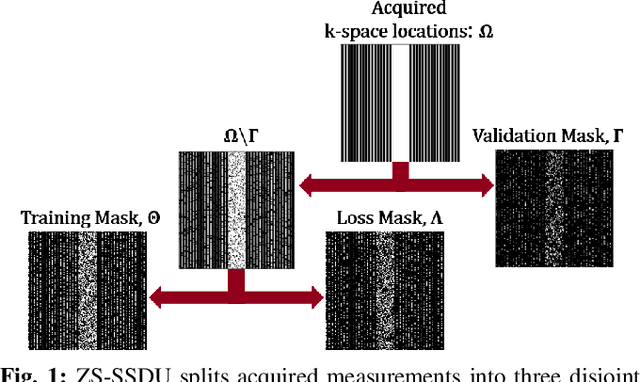
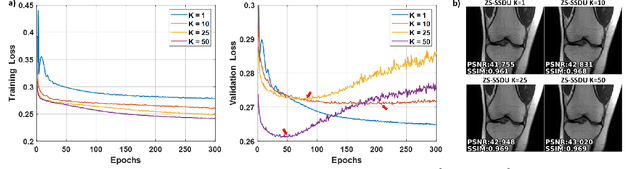
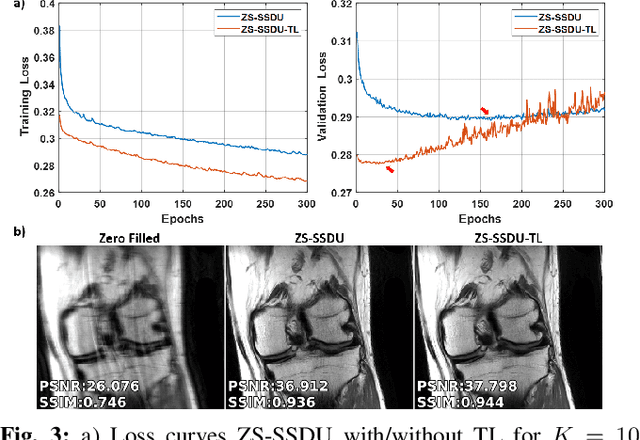
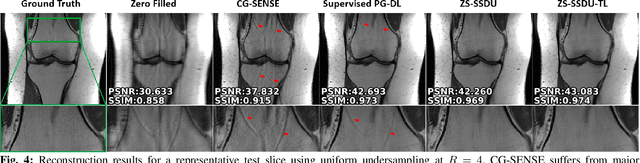
Physics-guided deep learning (PG-DL) has emerged as a powerful tool for accelerated MRI reconstruction, while often necessitating a database of fully-sampled measurements for training. Recent self-supervised and unsupervised learning approaches enable training without fully-sampled data. However, a database of undersampled measurements may not be available in many scenarios, especially for scans involving contrast or recently developed sequences, necessitating new methodology for scan-specific PG-DL reconstructions. A main challenge for developing scan-specific PG-DL methods is the large number of parameters, making it prone to over-fitting. Moreover, database-trained models may not generalize to unseen measurements that differ in terms of SNR, image contrast or sampling pattern. In this work, we propose a zero-shot self-supervised learning approach to perform scan-specific PG-DL reconstruction to tackle these issues. The proposed approach splits available measurements for each scan into three disjoint sets. Two of these sets are used to enforce data consistency and define loss during training, while the last set is used to establish an early stopping criterion. In the presence of models pre-trained on a database, we show that the proposed approach can be adapted as scan-specific fine-tuning via transfer learning to further improve reconstruction quality.
Learning the Prediction Distribution for Semi-Supervised Learning with Normalising Flows
Jul 06, 2020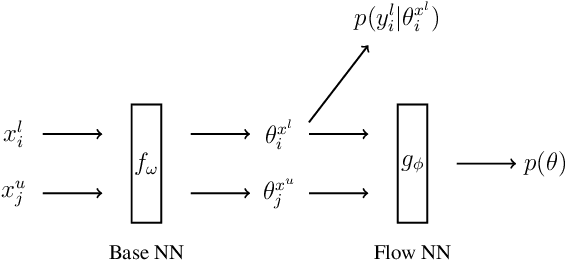
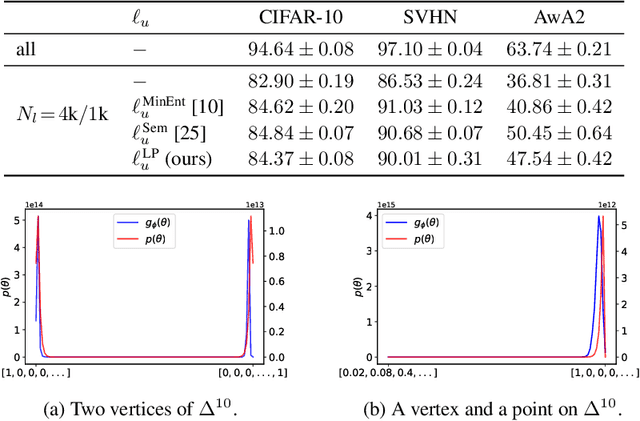

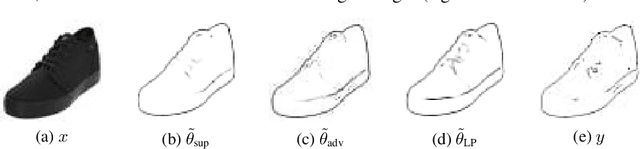
As data volumes continue to grow, the labelling process increasingly becomes a bottleneck, creating demand for methods that leverage information from unlabelled data. Impressive results have been achieved in semi-supervised learning (SSL) for image classification, nearing fully supervised performance, with only a fraction of the data labelled. In this work, we propose a probabilistically principled general approach to SSL that considers the distribution over label predictions, for labels of different complexity, from "one-hot" vectors to binary vectors and images. Our method regularises an underlying supervised model, using a normalising flow that learns the posterior distribution over predictions for labelled data, to serve as a prior over the predictions on unlabelled data. We demonstrate the general applicability of this approach on a range of computer vision tasks with varying output complexity: classification, attribute prediction and image-to-image translation.
Lie Algebrized Gaussians for Image Representation
May 09, 2017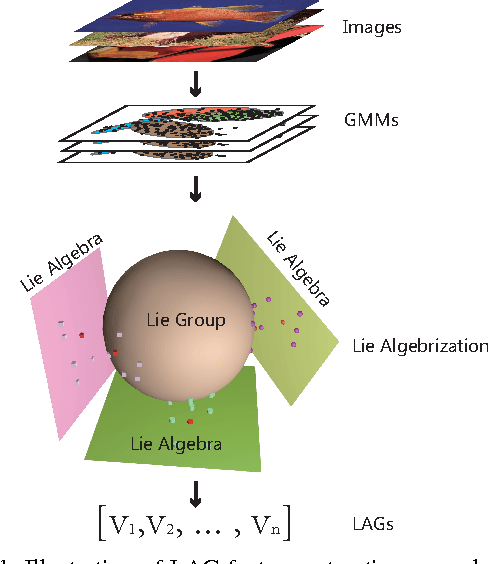

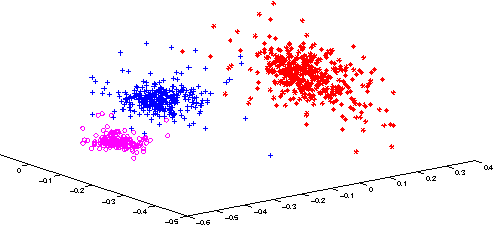
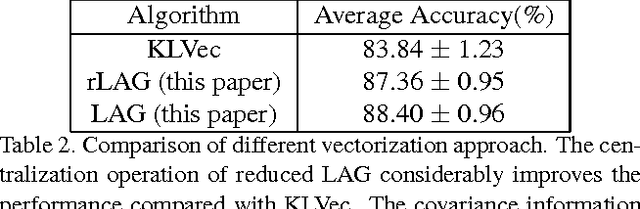
We present an image representation method which is derived from analyzing Gaussian probability density function (\emph{pdf}) space using Lie group theory. In our proposed method, images are modeled by Gaussian mixture models (GMMs) which are adapted from a globally trained GMM called universal background model (UBM). Then we vectorize the GMMs based on two facts: (1) components of image-specific GMMs are closely grouped together around their corresponding component of the UBM due to the characteristic of the UBM adaption procedure; (2) Gaussian \emph{pdf}s form a Lie group, which is a differentiable manifold rather than a vector space. We map each Gaussian component to the tangent vector space (named Lie algebra) of Lie group at the manifold position of UBM. The final feature vector, named Lie algebrized Gaussians (LAG) is then constructed by combining the Lie algebrized Gaussian components with mixture weights. We apply LAG features to scene category recognition problem and observe state-of-the-art performance on 15Scenes benchmark.
Efficient Image Splicing Localization via Contrastive Feature Extraction
Jan 22, 2019
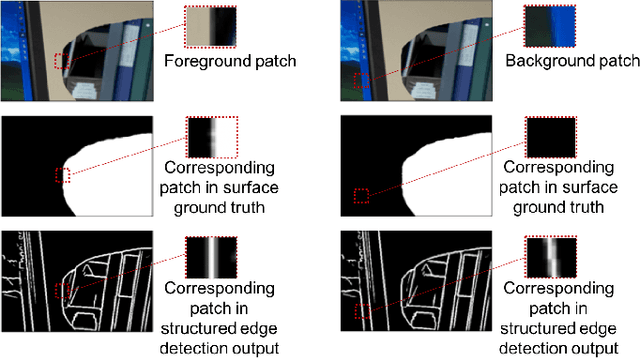
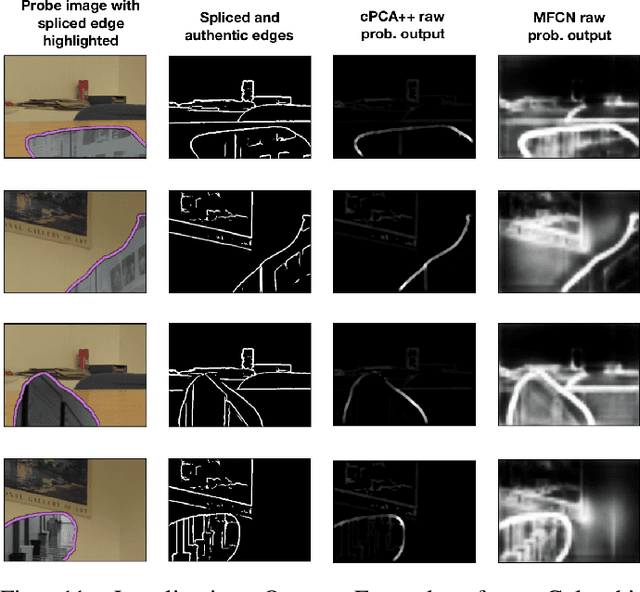

In this work, we propose a new data visualization and clustering technique for discovering discriminative structures in high-dimensional data. This technique, referred to as cPCA++, utilizes the fact that the interesting features of a "target" dataset may be obscured by high variance components during traditional PCA. By analyzing what is referred to as a "background" dataset (i.e., one that exhibits the high variance principal components but not the interesting structures), our technique is capable of efficiently highlighting the structure that is unique to the "target" dataset. Similar to another recently proposed algorithm called "contrastive PCA" (cPCA), the proposed cPCA++ method identifies important dataset specific patterns that are not detected by traditional PCA in a wide variety of settings. However, the proposed cPCA++ method is significantly more efficient than cPCA, because it does not require the parameter sweep in the latter approach. We applied the cPCA++ method to the problem of image splicing localization. In this application, we utilize authentic edges as the background dataset and the spliced edges as the target dataset. The proposed method is significantly more efficient than state-of-the-art methods, as the former does not require iterative updates of filter weights via stochastic gradient descent and backpropagation, nor the training of a classifier. Furthermore, the cPCA++ method is shown to provide performance scores comparable to the state-of-the-art Multi-task Fully Convolutional Network (MFCN).
HAVANA: Hierarchical and Variation-Normalized Autoencoder for Person Re-identification
Jan 09, 2021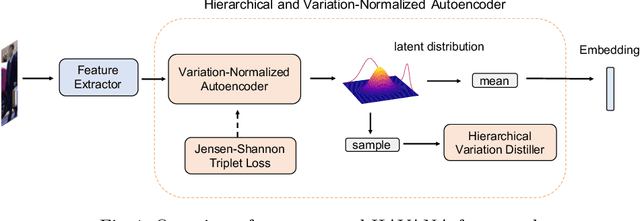

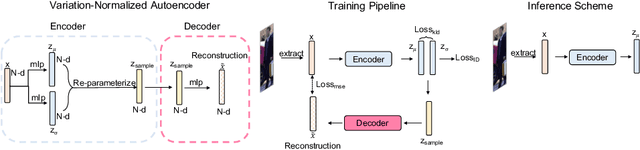
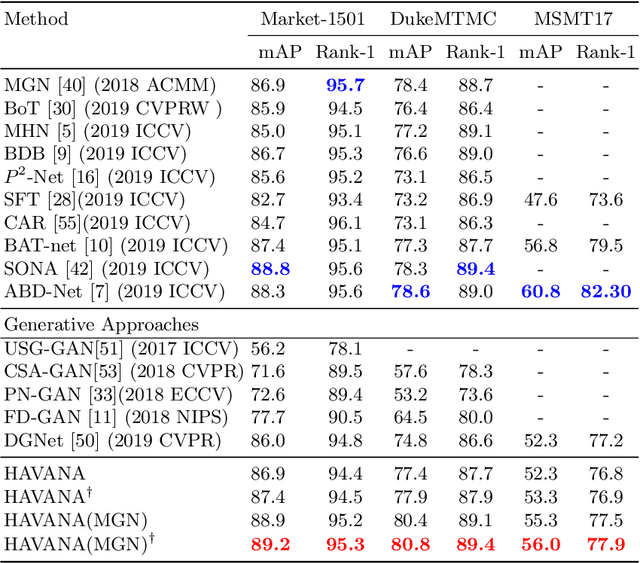
Person Re-Identification (Re-ID) is of great importance to the many video surveillance systems. Learning discriminative features for Re-ID remains a challenge due to the large variations in the image space, e.g., continuously changing human poses, illuminations and point of views. In this paper, we propose HAVANA, a novel extensible, light-weight HierArchical and VAriation-Normalized Autoencoder that learns features robust to intra-class variations. In contrast to existing generative approaches that prune the variations with heavy extra supervised signals, HAVANA suppresses the intra-class variations with a Variation-Normalized Autoencoder trained with no additional supervision. We also introduce a novel Jensen-Shannon triplet loss for contrastive distribution learning in Re-ID. In addition, we present Hierarchical Variation Distiller, a hierarchical VAE to factorize the latent representation and explicitly model the variations. To the best of our knowledge, HAVANA is the first VAE-based framework for person ReID.
Image Matters: Visually modeling user behaviors using Advanced Model Server
Sep 04, 2018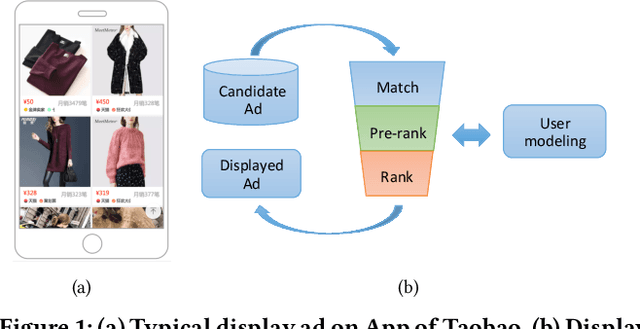

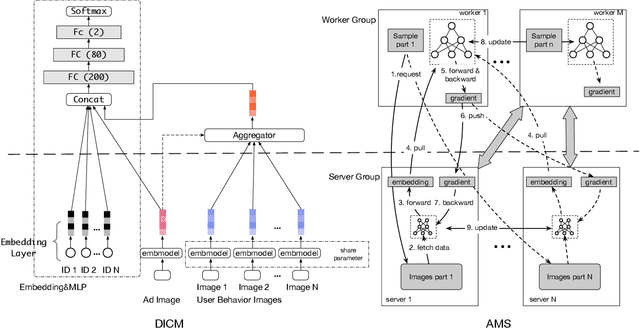
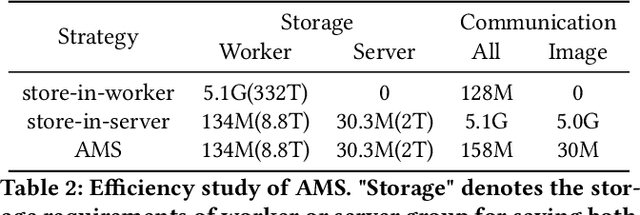
In Taobao, the largest e-commerce platform in China, billions of items are provided and typically displayed with their images. For better user experience and business effectiveness, Click Through Rate (CTR) prediction in online advertising system exploits abundant user historical behaviors to identify whether a user is interested in a candidate ad. Enhancing behavior representations with user behavior images will help understand user's visual preference and improve the accuracy of CTR prediction greatly. So we propose to model user preference jointly with user behavior ID features and behavior images. However, training with user behavior images brings tens to hundreds of images in one sample, giving rise to a great challenge in both communication and computation. To handle these challenges, we propose a novel and efficient distributed machine learning paradigm called Advanced Model Server (AMS). With the well known Parameter Server (PS) framework, each server node handles a separate part of parameters and updates them independently. AMS goes beyond this and is designed to be capable of learning a unified image descriptor model shared by all server nodes which embeds large images into low dimensional high level features before transmitting images to worker nodes. AMS thus dramatically reduces the communication load and enables the arduous joint training process. Based on AMS, the methods of effectively combining the images and ID features are carefully studied, and then we propose a Deep Image CTR Model. Our approach is shown to achieve significant improvements in both online and offline evaluations, and has been deployed in Taobao display advertising system serving the main traffic.
Deep Learning based Automated Forest Health Diagnosis from Aerial Images
Oct 16, 2020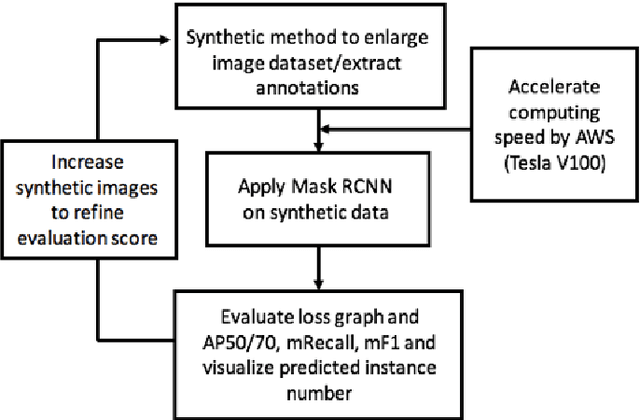
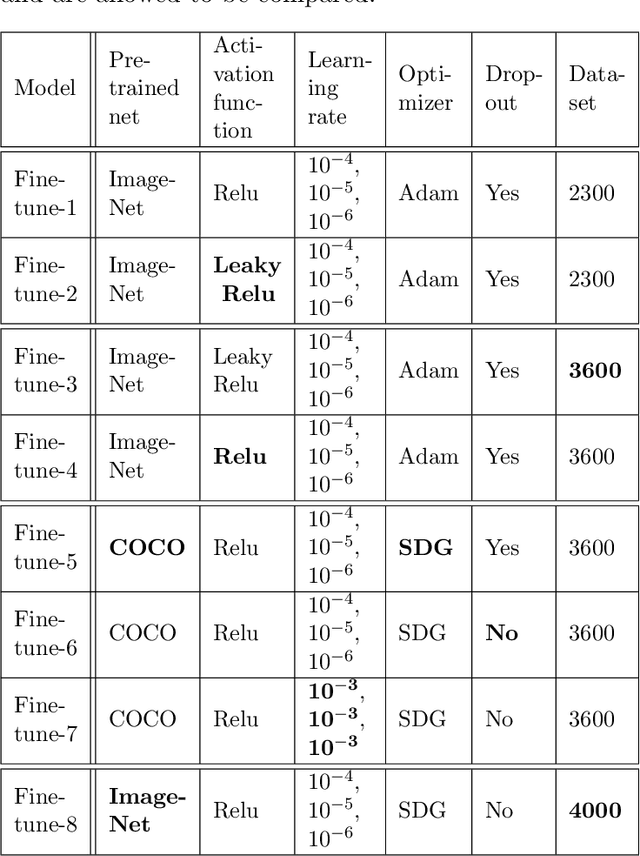

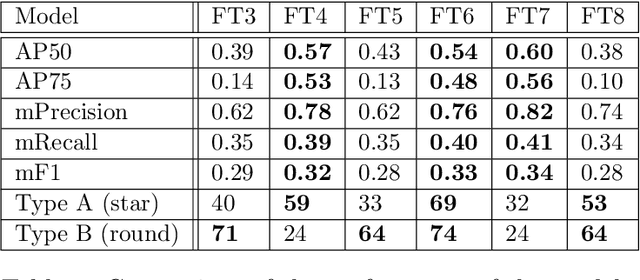
Global climate change has had a drastic impact on our environment. Previous study showed that pest disaster occured from global climate change may cause a tremendous number of trees died and they inevitably became a factor of forest fire. An important portent of the forest fire is the condition of forests. Aerial image-based forest analysis can give an early detection of dead trees and living trees. In this paper, we applied a synthetic method to enlarge imagery dataset and present a new framework for automated dead tree detection from aerial images using a re-trained Mask RCNN (Mask Region-based Convolutional Neural Network) approach, with a transfer learning scheme. We apply our framework to our aerial imagery datasets,and compare eight fine-tuned models. The mean average precision score (mAP) for the best of these models reaches 54%. Following the automated detection, we are able to automatically produce and calculate number of dead tree masks to label the dead trees in an image, as an indicator of forest health that could be linked to the causal analysis of environmental changes and the predictive likelihood of forest fire.
* 16 pages
Augmentation Inside the Network
Dec 19, 2020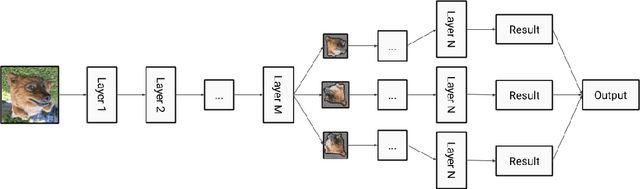
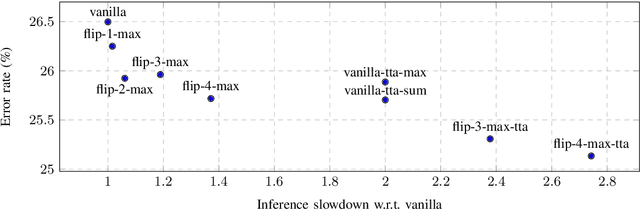
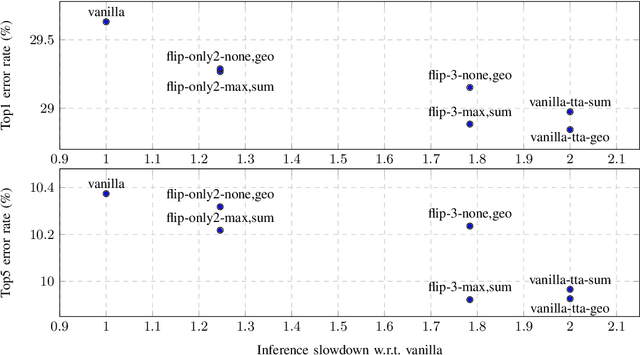
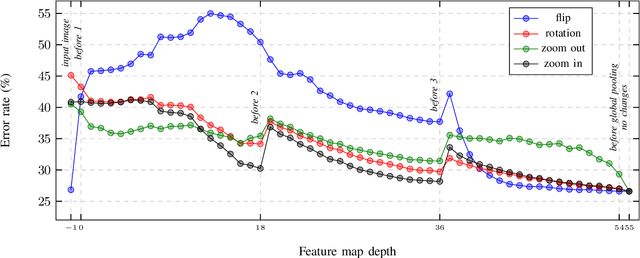
In this paper, we present augmentation inside the network, a method that simulates data augmentation techniques for computer vision problems on intermediate features of a convolutional neural network. We perform these transformations, changing the data flow through the network, and sharing common computations when it is possible. Our method allows us to obtain smoother speed-accuracy trade-off adjustment and achieves better results than using standard test-time augmentation (TTA) techniques. Additionally, our approach can improve model performance even further when coupled with test-time augmentation. We validate our method on the ImageNet-2012 and CIFAR-100 datasets for image classification. We propose a modification that is 30% faster than the flip test-time augmentation and achieves the same results for CIFAR-100.
Automatic Social Distance Estimation From Images: Performance Evaluation, Test Benchmark, and Algorithm
Mar 11, 2021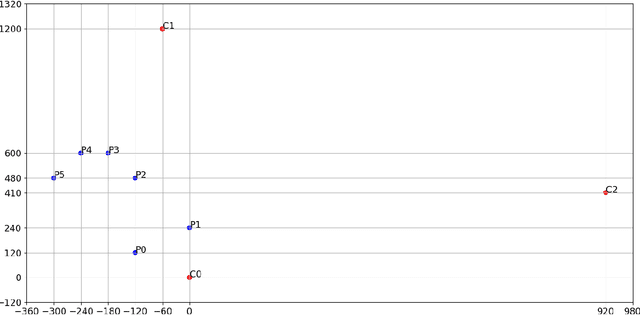
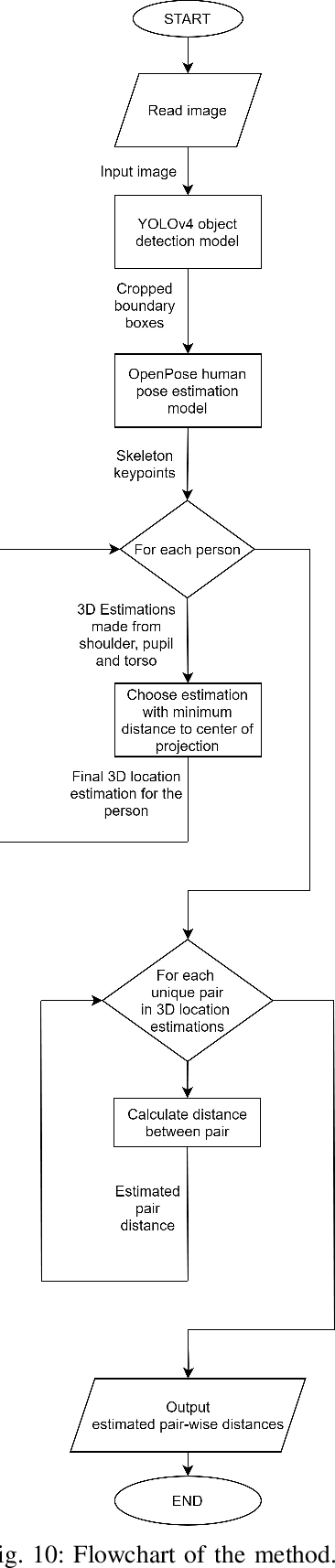
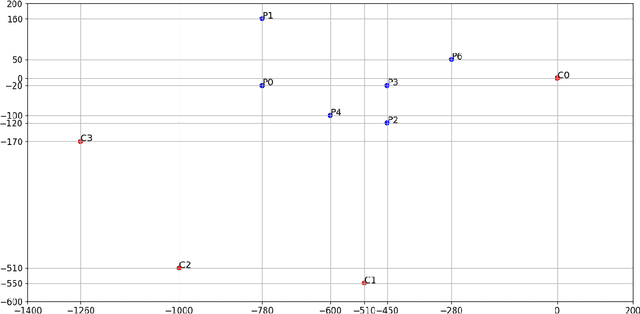

The COVID-19 virus has caused a global pandemic since March 2020. The World Health Organization (WHO) has provided guidelines on how to reduce the spread of the virus and one of the most important measures is social distancing. Maintaining a minimum of one meter distance from other people is strongly suggested to reduce the risk of infection. This has created a strong interest in monitoring the social distances either as a safety measure or to study how the measures have affected human behavior and country-wise differences in this. The need for automatic social distance estimation algorithms is evident, but there is no suitable test benchmark for such algorithms. Collecting images with measured ground-truth pair-wise distances between all the people using different camera settings is cumbersome. Furthermore, performance evaluation for social distance estimation algorithms is not straightforward and there is no widely accepted evaluation protocol. In this paper, we provide a dataset of varying images with measured pair-wise social distances under different camera positionings and focal length values. We suggest a performance evaluation protocol and provide a benchmark to easily evaluate social distance estimation algorithms. We also propose a method for automatic social distance estimation. Our method takes advantage of object detection and human pose estimation. It can be applied on any single image as long as focal length and sensor size information are known. The results on our benchmark are encouraging with 92% human detection rate and only 28.9% average error in distance estimation among the detected people.