 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy
Jan 07, 2024
While single task image restoration (IR) has achieved significant successes, it remains a challenging issue to train a single model which can tackle multiple IR tasks. In this work, we investigate in-depth the multiple-in-one (MiO) IR problem, which comprises seven popular IR tasks. We point out that MiO IR faces two pivotal challenges: the optimization of diverse objectives and the adaptation to multiple tasks. To tackle these challenges, we present two simple yet effective strategies. The first strategy, referred to as sequential learning, attempts to address how to optimize the diverse objectives, which guides the network to incrementally learn individual IR tasks in a sequential manner rather than mixing them together. The second strategy, i.e., prompt learning, attempts to address how to adapt to the different IR tasks, which assists the network to understand the specific task and improves the generalization ability. By evaluating on 19 test sets, we demonstrate that the sequential and prompt learning strategies can significantly enhance the MiO performance of commonly used CNN and Transformer backbones. Our experiments also reveal that the two strategies can supplement each other to learn better degradation representations and enhance the model robustness. It is expected that our proposed MiO IR formulation and strategies could facilitate the research on how to train IR models with higher generalization capabilities.
EEND-M2F: Masked-attention mask transformers for speaker diarization
Jan 23, 2024In this paper, we make the explicit connection between image segmentation methods and end-to-end diarization methods. From these insights, we propose a novel, fully end-to-end diarization model, EEND-M2F, based on the Mask2Former architecture. Speaker representations are computed in parallel using a stack of transformer decoders, in which irrelevant frames are explicitly masked from the cross attention using predictions from previous layers. EEND-M2F is lightweight, efficient, and truly end-to-end, as it does not require any additional diarization, speaker verification, or segmentation models to run, nor does it require running any clustering algorithms. Our model achieves state-of-the-art performance on several public datasets, such as AMI, AliMeeting and RAMC. Most notably our DER of 16.07% on DIHARD-III is the first major improvement upon the challenge winning system.
NWPU-MOC: A Benchmark for Fine-grained Multi-category Object Counting in Aerial Images
Jan 19, 2024Object counting is a hot topic in computer vision, which aims to estimate the number of objects in a given image. However, most methods only count objects of a single category for an image, which cannot be applied to scenes that need to count objects with multiple categories simultaneously, especially in aerial scenes. To this end, this paper introduces a Multi-category Object Counting (MOC) task to estimate the numbers of different objects (cars, buildings, ships, etc.) in an aerial image. Considering the absence of a dataset for this task, a large-scale Dataset (NWPU-MOC) is collected, consisting of 3,416 scenes with a resolution of 1024 $\times$ 1024 pixels, and well-annotated using 14 fine-grained object categories. Besides, each scene contains RGB and Near Infrared (NIR) images, of which the NIR spectrum can provide richer characterization information compared with only the RGB spectrum. Based on NWPU-MOC, the paper presents a multi-spectrum, multi-category object counting framework, which employs a dual-attention module to fuse the features of RGB and NIR and subsequently regress multi-channel density maps corresponding to each object category. In addition, to modeling the dependency between different channels in the density map with each object category, a spatial contrast loss is designed as a penalty for overlapping predictions at the same spatial position. Experimental results demonstrate that the proposed method achieves state-of-the-art performance compared with some mainstream counting algorithms. The dataset, code and models are publicly available at https://github.com/lyongo/NWPU-MOC.
Deep learning and random light structuring ensure robust free-space communications
Jan 18, 2024Having shown early promise, free-space optical communications (FSO) face formidable challenges in the age of information explosion. The ever-growing demand for greater channel communication capacity is one of the challenges. The inter-channel crosstalk, which severely degrades the quality of transmitted information, creates another roadblock in the way of efficient FSO implementation. Here we advance theoretically and realize experimentally a potentially high-capacity FSO protocol that enables high-fidelity transfer of an image, or set of images through a complex environment. In our protocol, we complement random light structuring at the transmitter with a deep learning image classification platform at the receiver. Multiplexing novel, independent, mutually orthogonal degrees of freedom available to structured random light can potentially significantly boost the channel communication capacity of our protocol without introducing any deleterious crosstalk. Specifically, we show how one can multiplex the degrees of freedom associated with the source coherence radius and a spatial position of a beamlet within an array of structured random beams to greatly enhance the capacity of our communication link. The superb resilience of structured random light to environmental noise, as well as extreme efficiency of deep learning networks at classifying images guarantees high-fidelity image transfer within the framework of our protocol.
BlenDA: Domain Adaptive Object Detection through diffusion-based blending
Jan 18, 2024Unsupervised domain adaptation (UDA) aims to transfer a model learned using labeled data from the source domain to unlabeled data in the target domain. To address the large domain gap issue between the source and target domains, we propose a novel regularization method for domain adaptive object detection, BlenDA, by generating the pseudo samples of the intermediate domains and their corresponding soft domain labels for adaptation training. The intermediate samples are generated by dynamically blending the source images with their corresponding translated images using an off-the-shelf pre-trained text-to-image diffusion model which takes the text label of the target domain as input and has demonstrated superior image-to-image translation quality. Based on experimental results from two adaptation benchmarks, our proposed approach can significantly enhance the performance of the state-of-the-art domain adaptive object detector, Adversarial Query Transformer (AQT). Particularly, in the Cityscapes to Foggy Cityscapes adaptation, we achieve an impressive 53.4% mAP on the Foggy Cityscapes dataset, surpassing the previous state-of-the-art by 1.5%. It is worth noting that our proposed method is also applicable to various paradigms of domain adaptive object detection. The code is available at:https://github.com/aiiu-lab/BlenDA
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Jan 20, 2024One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
Digital-analog hybrid matrix multiplication processor for optical neural networks
Jan 26, 2024The computational demands of modern AI have spurred interest in optical neural networks (ONNs) which offer the potential benefits of increased speed and lower power consumption. However, current ONNs face various challenges,most significantly a limited calculation precision (typically around 4 bits) and the requirement for high-resolution signal format converters (digital-to-analogue conversions (DACs) and analogue-to-digital conversions (ADCs)). These challenges are inherent to their analog computing nature and pose significant obstacles in practical implementation. Here, we propose a digital-analog hybrid optical computing architecture for ONNs, which utilizes digital optical inputs in the form of binary words. By introducing the logic levels and decisions based on thresholding, the calculation precision can be significantly enhanced. The DACs for input data can be removed and the resolution of the ADCs can be greatly reduced. This can increase the operating speed at a high calculation precision and facilitate the compatibility with microelectronics. To validate our approach, we have fabricated a proof-of-concept photonic chip and built up a hybrid optical processor (HOP) system for neural network applications. We have demonstrated an unprecedented 16-bit calculation precision for high-definition image processing, with a pixel error rate (PER) as low as $1.8\times10^{-3}$ at an signal-to-noise ratio (SNR) of 18.2 dB. We have also implemented a convolutional neural network for handwritten digit recognition that shows the same accuracy as the one achieved by a desktop computer. The concept of the digital-analog hybrid optical computing architecture offers a methodology that could potentially be applied to various ONN implementations and may intrigue new research into efficient and accurate domain-specific optical computing architectures for neural networks.
SimpleEgo: Predicting Probabilistic Body Pose from Egocentric Cameras
Jan 26, 2024Our work addresses the problem of egocentric human pose estimation from downwards-facing cameras on head-mounted devices (HMD). This presents a challenging scenario, as parts of the body often fall outside of the image or are occluded. Previous solutions minimize this problem by using fish-eye camera lenses to capture a wider view, but these can present hardware design issues. They also predict 2D heat-maps per joint and lift them to 3D space to deal with self-occlusions, but this requires large network architectures which are impractical to deploy on resource-constrained HMDs. We predict pose from images captured with conventional rectilinear camera lenses. This resolves hardware design issues, but means body parts are often out of frame. As such, we directly regress probabilistic joint rotations represented as matrix Fisher distributions for a parameterized body model. This allows us to quantify pose uncertainties and explain out-of-frame or occluded joints. This also removes the need to compute 2D heat-maps and allows for simplified DNN architectures which require less compute. Given the lack of egocentric datasets using rectilinear camera lenses, we introduce the SynthEgo dataset, a synthetic dataset with 60K stereo images containing high diversity of pose, shape, clothing and skin tone. Our approach achieves state-of-the-art results for this challenging configuration, reducing mean per-joint position error by 23% overall and 58% for the lower body. Our architecture also has eight times fewer parameters and runs twice as fast as the current state-of-the-art. Experiments show that training on our synthetic dataset leads to good generalization to real world images without fine-tuning.
Image Deblurring using GAN
Dec 15, 2023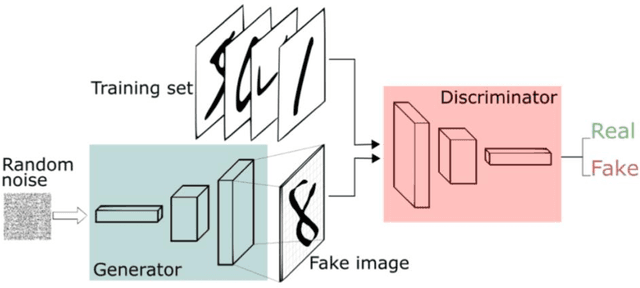
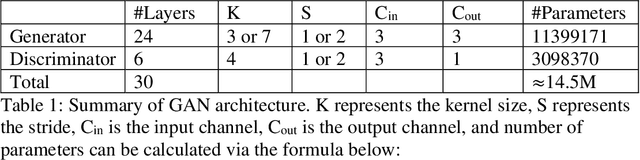
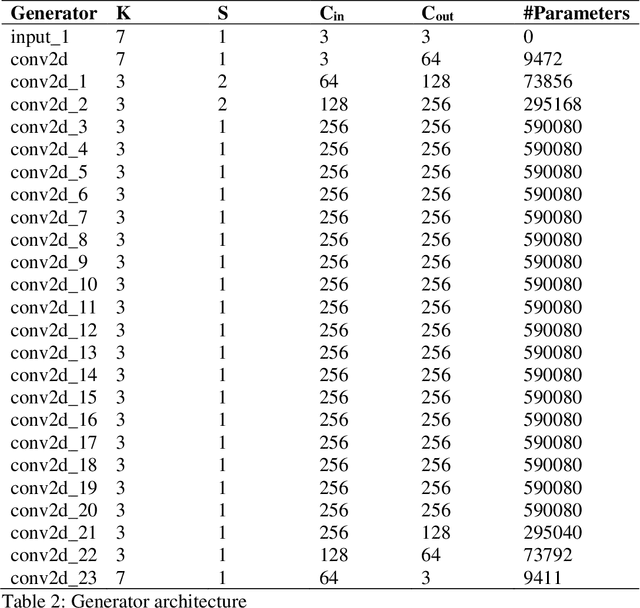

In recent years, deep generative models, such as Generative Adversarial Network (GAN), has grabbed significant attention in the field of computer vision. This project focuses on the application of GAN in image deblurring with the aim of generating clearer images from blurry inputs caused by factors such as motion blur. However, traditional image restoration techniques have limitations in handling complex blurring patterns. Hence, a GAN-based framework is proposed as a solution to generate high-quality deblurred images. The project defines a GAN model in Tensorflow and trains it with GoPRO dataset. The Generator will intake blur images directly to create fake images to convince the Discriminator which will receive clear images at the same time and distinguish between the real image and the fake image. After obtaining the trained parameters, the model was used to deblur motion-blur images taken in daily life as well as testing set for validation. The result shows that the pretrained network of GAN can obtain sharper pixels in image, achieving an average of 29.3 Peak Signal-to-Noise Ratio (PSNR) and 0.72 Structural Similarity Assessment (SSIM). This help to effectively address the challenges posed by image blurring, leading to the generation of visually pleasing and sharp images. By exploiting the adversarial learning framework, the proposed approach enhances the potential for real-world applications in image restoration.
Energy-Based Concept Bottleneck Models: Unifying Prediction, Concept Intervention, and Conditional Interpretations
Jan 25, 2024Existing methods, such as concept bottleneck models (CBMs), have been successful in providing concept-based interpretations for black-box deep learning models. They typically work by predicting concepts given the input and then predicting the final class label given the predicted concepts. However, (1) they often fail to capture the high-order, nonlinear interaction between concepts, e.g., correcting a predicted concept (e.g., "yellow breast") does not help correct highly correlated concepts (e.g., "yellow belly"), leading to suboptimal final accuracy; (2) they cannot naturally quantify the complex conditional dependencies between different concepts and class labels (e.g., for an image with the class label "Kentucky Warbler" and a concept "black bill", what is the probability that the model correctly predicts another concept "black crown"), therefore failing to provide deeper insight into how a black-box model works. In response to these limitations, we propose Energy-based Concept Bottleneck Models (ECBMs). Our ECBMs use a set of neural networks to define the joint energy of candidate (input, concept, class) tuples. With such a unified interface, prediction, concept correction, and conditional dependency quantification are then represented as conditional probabilities, which are generated by composing different energy functions. Our ECBMs address both limitations of existing CBMs, providing higher accuracy and richer concept interpretations. Empirical results show that our approach outperforms the state-of-the-art on real-world datasets.