 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital-analog hybrid matrix multiplication processor for optical neural networks
Jan 26, 2024The computational demands of modern AI have spurred interest in optical neural networks (ONNs) which offer the potential benefits of increased speed and lower power consumption. However, current ONNs face various challenges,most significantly a limited calculation precision (typically around 4 bits) and the requirement for high-resolution signal format converters (digital-to-analogue conversions (DACs) and analogue-to-digital conversions (ADCs)). These challenges are inherent to their analog computing nature and pose significant obstacles in practical implementation. Here, we propose a digital-analog hybrid optical computing architecture for ONNs, which utilizes digital optical inputs in the form of binary words. By introducing the logic levels and decisions based on thresholding, the calculation precision can be significantly enhanced. The DACs for input data can be removed and the resolution of the ADCs can be greatly reduced. This can increase the operating speed at a high calculation precision and facilitate the compatibility with microelectronics. To validate our approach, we have fabricated a proof-of-concept photonic chip and built up a hybrid optical processor (HOP) system for neural network applications. We have demonstrated an unprecedented 16-bit calculation precision for high-definition image processing, with a pixel error rate (PER) as low as $1.8\times10^{-3}$ at an signal-to-noise ratio (SNR) of 18.2 dB. We have also implemented a convolutional neural network for handwritten digit recognition that shows the same accuracy as the one achieved by a desktop computer. The concept of the digital-analog hybrid optical computing architecture offers a methodology that could potentially be applied to various ONN implementations and may intrigue new research into efficient and accurate domain-specific optical computing architectures for neural networks.
E-NER -- An Annotated Named Entity Recognition Corpus of Legal Text
Dec 19, 2022



Identifying named entities such as a person, location or organization, in documents can highlight key information to readers. Training Named Entity Recognition (NER) models requires an annotated data set, which can be a time-consuming labour-intensive task. Nevertheless, there are publicly available NER data sets for general English. Recently there has been interest in developing NER for legal text. However, prior work and experimental results reported here indicate that there is a significant degradation in performance when NER methods trained on a general English data set are applied to legal text. We describe a publicly available legal NER data set, called E-NER, based on legal company filings available from the US Securities and Exchange Commission's EDGAR data set. Training a number of different NER algorithms on the general English CoNLL-2003 corpus but testing on our test collection confirmed significant degradations in accuracy, as measured by the F1-score, of between 29.4\% and 60.4\%, compared to training and testing on the E-NER collection.
Estimating the Uncertainty of Neural Network Forecasts for Influenza Prevalence Using Web Search Activity
May 26, 2021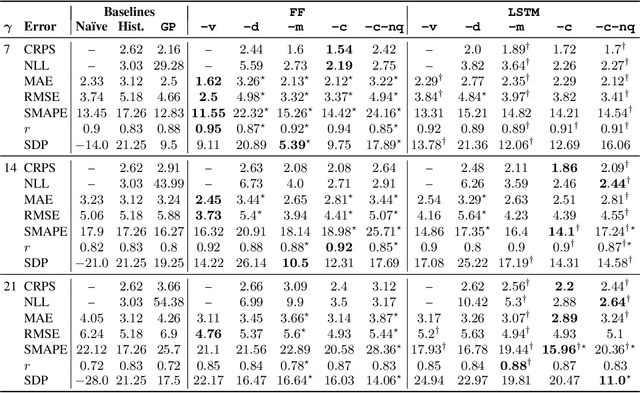
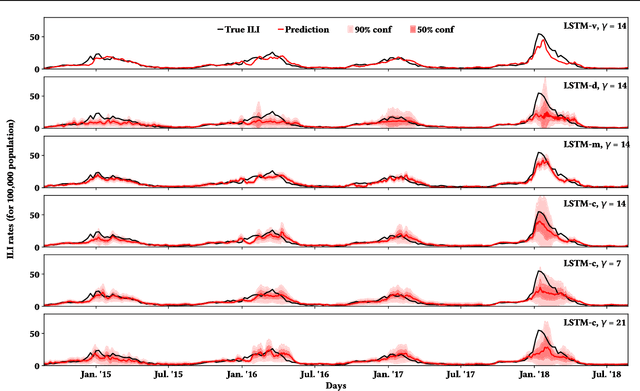
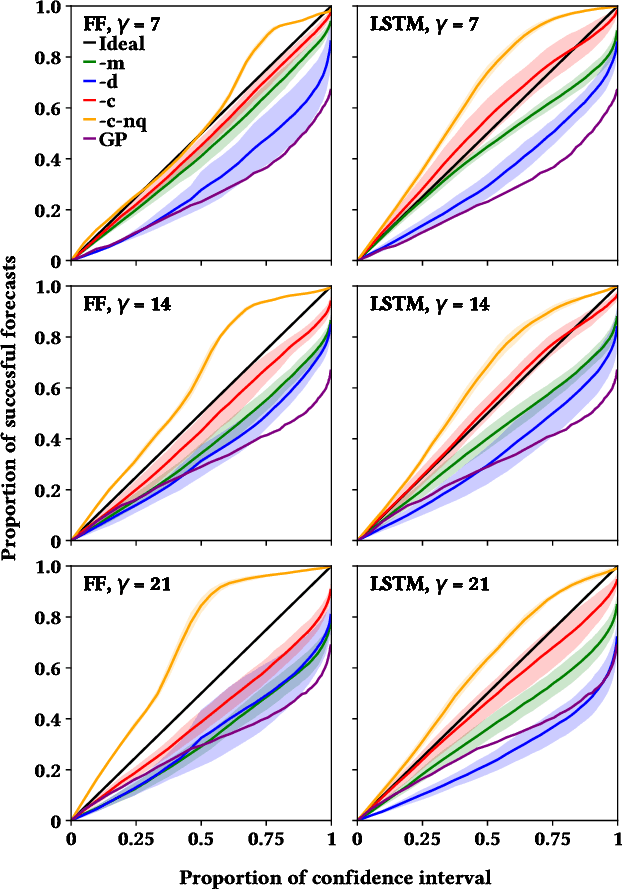
Influenza is an infectious disease with the potential to become a pandemic, and hence, forecasting its prevalence is an important undertaking for planning an effective response. Research has found that web search activity can be used to improve influenza models. Neural networks (NN) can provide state-of-the-art forecasting accuracy but do not commonly incorporate uncertainty in their estimates, something essential for using them effectively during decision making. In this paper, we demonstrate how Bayesian Neural Networks (BNNs) can be used to both provide a forecast and a corresponding uncertainty without significant loss in forecasting accuracy compared to traditional NNs. Our method accounts for two sources of uncertainty: data and model uncertainty, arising due to measurement noise and model specification, respectively. Experiments are conducted using 14 years of data for England, assessing the model's accuracy over the last 4 flu seasons in this dataset. We evaluate the performance of different models including competitive baselines with conventional metrics as well as error functions that incorporate uncertainty estimates. Our empirical analysis indicates that considering both sources of uncertainty simultaneously is superior to considering either one separately. We also show that a BNN with recurrent layers that models both sources of uncertainty yields superior accuracy for these metrics for forecasting horizons greater than 7 days.
Multi-Dueling Bandits and Their Application to Online Ranker Evaluation
Aug 22, 2016



New ranking algorithms are continually being developed and refined, necessitating the development of efficient methods for evaluating these rankers. Online ranker evaluation focuses on the challenge of efficiently determining, from implicit user feedback, which ranker out of a finite set of rankers is the best. Online ranker evaluation can be modeled by dueling ban- dits, a mathematical model for online learning under limited feedback from pairwise comparisons. Comparisons of pairs of rankers is performed by interleaving their result sets and examining which documents users click on. The dueling bandits model addresses the key issue of which pair of rankers to compare at each iteration, thereby providing a solution to the exploration-exploitation trade-off. Recently, methods for simultaneously comparing more than two rankers have been developed. However, the question of which rankers to compare at each iteration was left open. We address this question by proposing a generalization of the dueling bandits model that uses simultaneous comparisons of an unrestricted number of rankers. We evaluate our algorithm on synthetic data and several standard large-scale online ranker evaluation datasets. Our experimental results show that the algorithm yields orders of magnitude improvement in performance compared to stateof- the-art dueling bandit algorithms.