 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvisible Backdoor Triggers in Image Editing Model via Deep Watermarking
Jun 05, 2025



Diffusion models have achieved remarkable progress in both image generation and editing. However, recent studies have revealed their vulnerability to backdoor attacks, in which specific patterns embedded in the input can manipulate the model's behavior. Most existing research in this area has proposed attack frameworks focused on the image generation pipeline, leaving backdoor attacks in image editing relatively unexplored. Among the few studies targeting image editing, most utilize visible triggers, which are impractical because they introduce noticeable alterations to the input image before editing. In this paper, we propose a novel attack framework that embeds invisible triggers into the image editing process via poisoned training data. We leverage off-the-shelf deep watermarking models to encode imperceptible watermarks as backdoor triggers. Our goal is to make the model produce the predefined backdoor target when it receives watermarked inputs, while editing clean images normally according to the given prompt. With extensive experiments across different watermarking models, the proposed method achieves promising attack success rates. In addition, the analysis results of the watermark characteristics in term of backdoor attack further support the effectiveness of our approach. The code is available at:https://github.com/aiiu-lab/BackdoorImageEditing
Gen-n-Val: Agentic Image Data Generation and Validation
Jun 05, 2025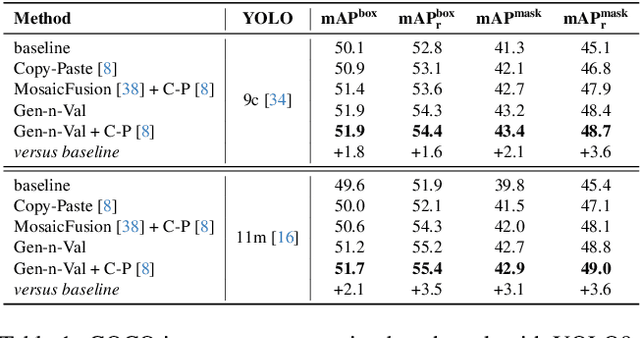



Recently, Large Language Models (LLMs) and Vision Large Language Models (VLLMs) have demonstrated impressive performance as agents across various tasks while data scarcity and label noise remain significant challenges in computer vision tasks, such as object detection and instance segmentation. A common solution for resolving these issues is to generate synthetic data. However, current synthetic data generation methods struggle with issues, such as multiple objects per mask, inaccurate segmentation, and incorrect category labels, limiting their effectiveness. To address these issues, we introduce Gen-n-Val, a novel agentic data generation framework that leverages Layer Diffusion (LD), LLMs, and VLLMs to produce high-quality, single-object masks and diverse backgrounds. Gen-n-Val consists of two agents: (1) The LD prompt agent, an LLM, optimizes prompts for LD to generate high-quality foreground instance images and segmentation masks. These optimized prompts ensure the generation of single-object synthetic data with precise instance masks and clean backgrounds. (2) The data validation agent, a VLLM, which filters out low-quality synthetic instance images. The system prompts for both agents are refined through TextGrad. Additionally, we use image harmonization to combine multiple instances within scenes. Compared to state-of-the-art synthetic data approaches like MosaicFusion, our approach reduces invalid synthetic data from 50% to 7% and improves performance by 1% mAP on rare classes in COCO instance segmentation with YOLOv9c and YOLO11m. Furthermore, Gen-n-Val shows significant improvements (7. 1% mAP) over YOLO-Worldv2-M in open-vocabulary object detection benchmarks with YOLO11m. Moreover, Gen-n-Val improves the performance of YOLOv9 and YOLO11 families in instance segmentation and object detection.
BlenDA: Domain Adaptive Object Detection through diffusion-based blending
Jan 18, 2024



Unsupervised domain adaptation (UDA) aims to transfer a model learned using labeled data from the source domain to unlabeled data in the target domain. To address the large domain gap issue between the source and target domains, we propose a novel regularization method for domain adaptive object detection, BlenDA, by generating the pseudo samples of the intermediate domains and their corresponding soft domain labels for adaptation training. The intermediate samples are generated by dynamically blending the source images with their corresponding translated images using an off-the-shelf pre-trained text-to-image diffusion model which takes the text label of the target domain as input and has demonstrated superior image-to-image translation quality. Based on experimental results from two adaptation benchmarks, our proposed approach can significantly enhance the performance of the state-of-the-art domain adaptive object detector, Adversarial Query Transformer (AQT). Particularly, in the Cityscapes to Foggy Cityscapes adaptation, we achieve an impressive 53.4% mAP on the Foggy Cityscapes dataset, surpassing the previous state-of-the-art by 1.5%. It is worth noting that our proposed method is also applicable to various paradigms of domain adaptive object detection. The code is available at:https://github.com/aiiu-lab/BlenDA
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023



This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io