 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Infrared and Visible Image Fusion using a Deep Learning Framework
May 19, 2018
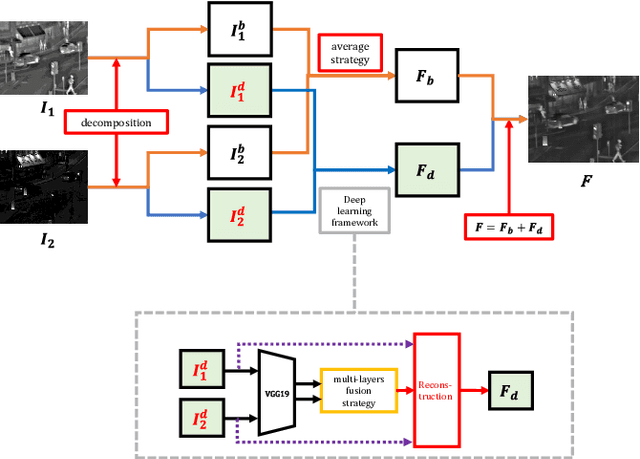
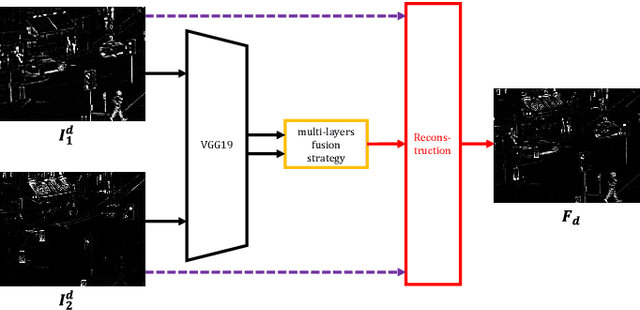
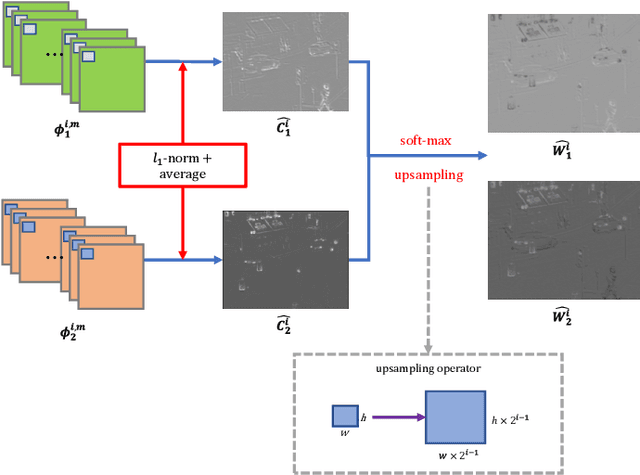

In recent years, deep learning has become a very active research tool which is used in many image processing fields. In this paper, we propose an effective image fusion method using a deep learning framework to generate a single image which contains all the features from infrared and visible images. First, the source images are decomposed into base parts and detail content. Then the base parts are fused by weighted-averaging. For the detail content, we use a deep learning network to extract multi-layer features. Using these features, we use l_1-norm and weighted-average strategy to generate several candidates of the fused detail content. Once we get these candidates, the max selection strategy is used to get final fused detail content. Finally, the fused image will be reconstructed by combining the fused base part and detail content. The experimental results demonstrate that our proposed method achieves state-of-the-art performance in both objective assessment and visual quality. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_deeplearning
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
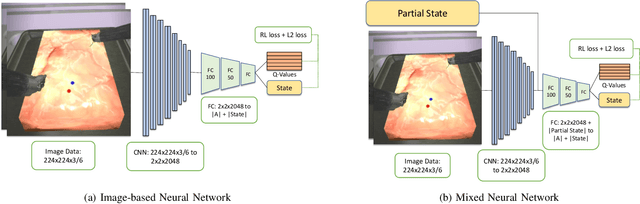
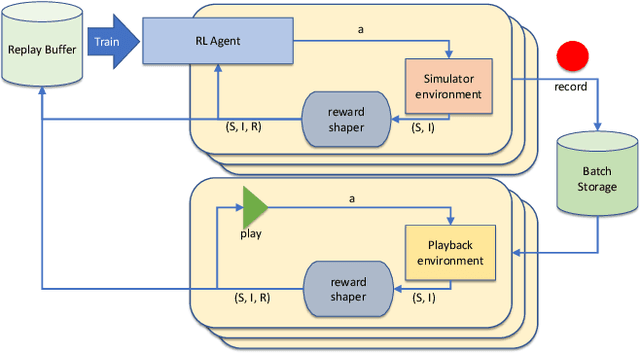
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.
Learn Fine-grained Adaptive Loss for Multiple Anatomical Landmark Detection in Medical Images
May 19, 2021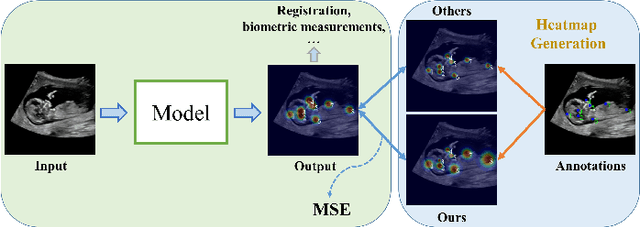
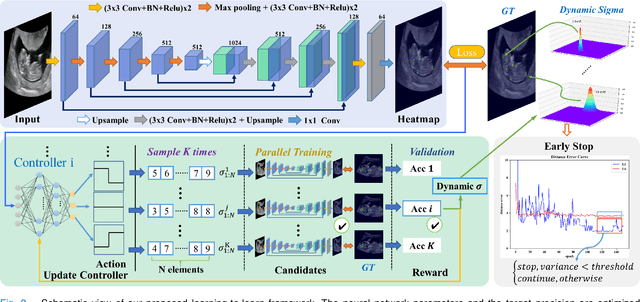
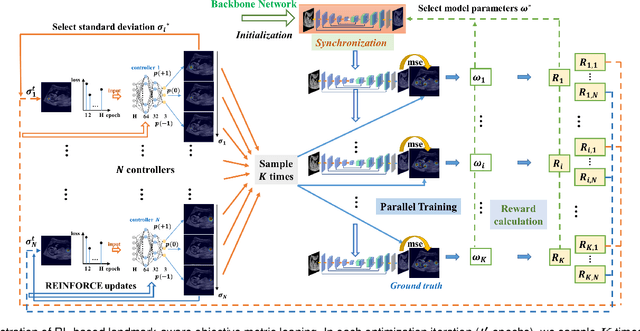
Automatic and accurate detection of anatomical landmarks is an essential operation in medical image analysis with a multitude of applications. Recent deep learning methods have improved results by directly encoding the appearance of the captured anatomy with the likelihood maps (i.e., heatmaps). However, most current solutions overlook another essence of heatmap regression, the objective metric for regressing target heatmaps and rely on hand-crafted heuristics to set the target precision, thus being usually cumbersome and task-specific. In this paper, we propose a novel learning-to-learn framework for landmark detection to optimize the neural network and the target precision simultaneously. The pivot of this work is to leverage the reinforcement learning (RL) framework to search objective metrics for regressing multiple heatmaps dynamically during the training process, thus avoiding setting problem-specific target precision. We also introduce an early-stop strategy for active termination of the RL agent's interaction that adapts the optimal precision for separate targets considering exploration-exploitation tradeoffs. This approach shows better stability in training and improved localization accuracy in inference. Extensive experimental results on two different applications of landmark localization: 1) our in-house prenatal ultrasound (US) dataset and 2) the publicly available dataset of cephalometric X-Ray landmark detection, demonstrate the effectiveness of our proposed method. Our proposed framework is general and shows the potential to improve the efficiency of anatomical landmark detection.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021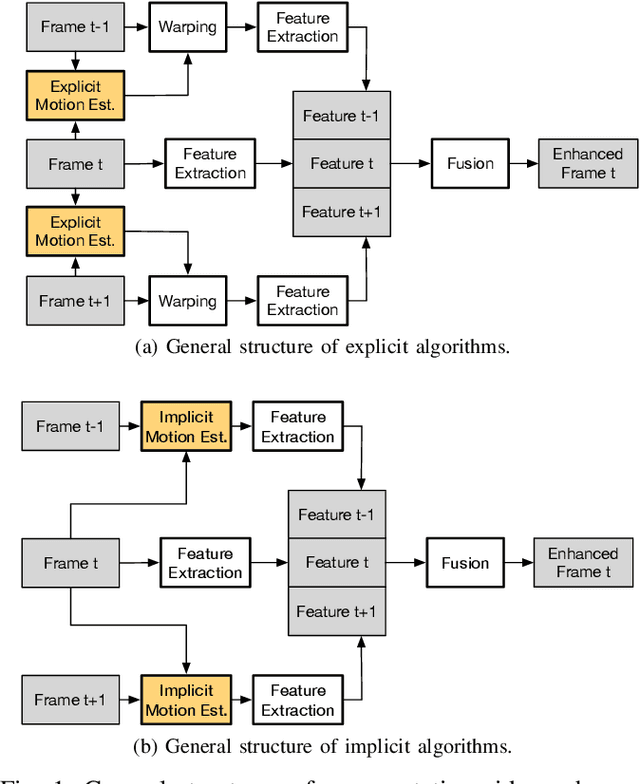

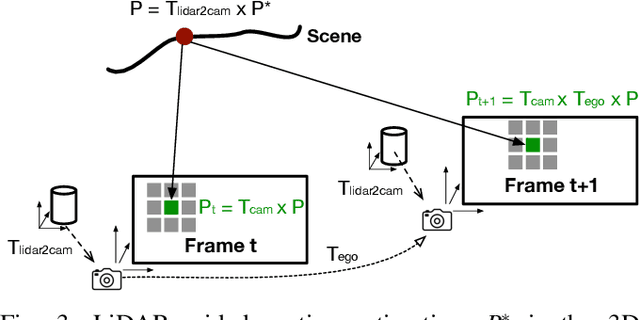

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
Automatic Liver Segmentation Using an Adversarial Image-to-Image Network
Jul 25, 2017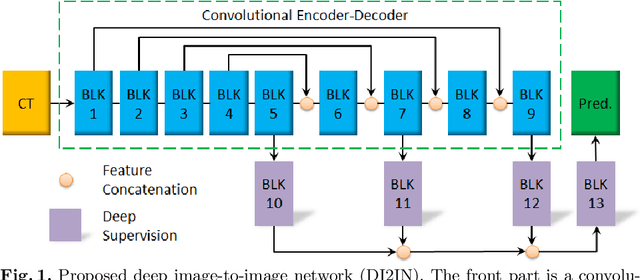
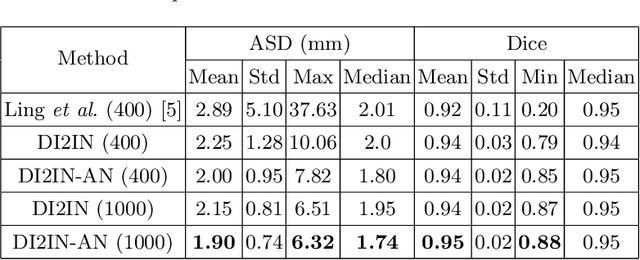
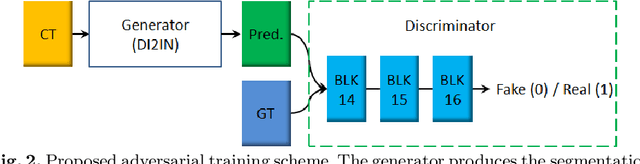
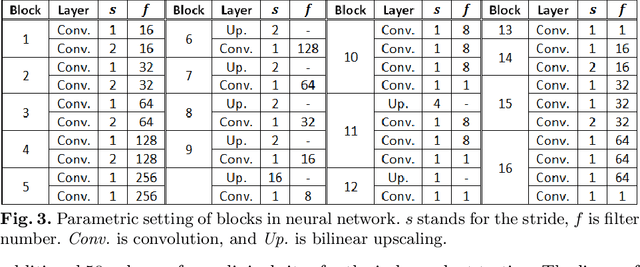
Automatic liver segmentation in 3D medical images is essential in many clinical applications, such as pathological diagnosis of hepatic diseases, surgical planning, and postoperative assessment. However, it is still a very challenging task due to the complex background, fuzzy boundary, and various appearance of liver. In this paper, we propose an automatic and efficient algorithm to segment liver from 3D CT volumes. A deep image-to-image network (DI2IN) is first deployed to generate the liver segmentation, employing a convolutional encoder-decoder architecture combined with multi-level feature concatenation and deep supervision. Then an adversarial network is utilized during training process to discriminate the output of DI2IN from ground truth, which further boosts the performance of DI2IN. The proposed method is trained on an annotated dataset of 1000 CT volumes with various different scanning protocols (e.g., contrast and non-contrast, various resolution and position) and large variations in populations (e.g., ages and pathology). Our approach outperforms the state-of-the-art solutions in terms of segmentation accuracy and computing efficiency.
Love Thy Neighbors: Image Annotation by Exploiting Image Metadata
Sep 22, 2015
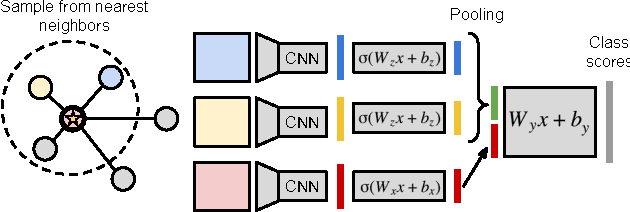
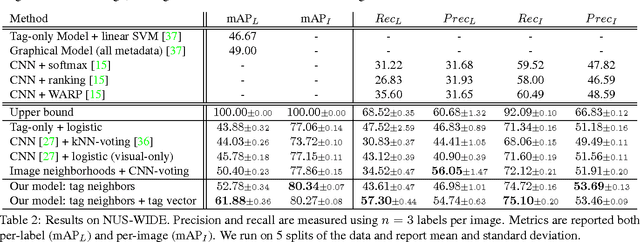
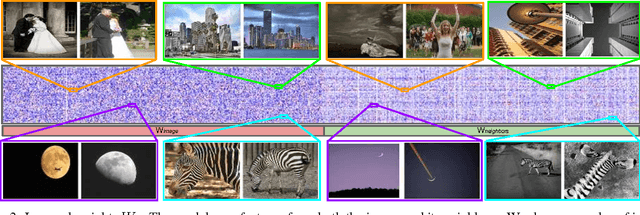
Some images that are difficult to recognize on their own may become more clear in the context of a neighborhood of related images with similar social-network metadata. We build on this intuition to improve multilabel image annotation. Our model uses image metadata nonparametrically to generate neighborhoods of related images using Jaccard similarities, then uses a deep neural network to blend visual information from the image and its neighbors. Prior work typically models image metadata parametrically, in contrast, our nonparametric treatment allows our model to perform well even when the vocabulary of metadata changes between training and testing. We perform comprehensive experiments on the NUS-WIDE dataset, where we show that our model outperforms state-of-the-art methods for multilabel image annotation even when our model is forced to generalize to new types of metadata.
Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
Feb 12, 2021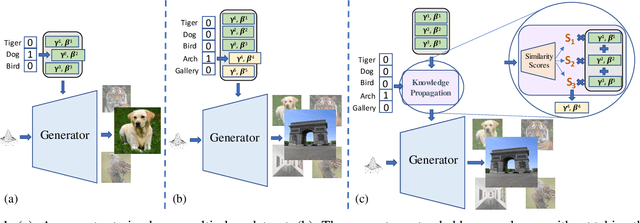



Generative adversarial networks (GANs) have shown impressive results in both unconditional and conditional image generation. In recent literature, it is shown that pre-trained GANs, on a different dataset, can be transferred to improve the image generation from a small target data. The same, however, has not been well-studied in the case of conditional GANs (cGANs), which provides new opportunities for knowledge transfer compared to unconditional setup. In particular, the new classes may borrow knowledge from the related old classes, or share knowledge among themselves to improve the training. This motivates us to study the problem of efficient conditional GAN transfer with knowledge propagation across classes. To address this problem, we introduce a new GAN transfer method to explicitly propagate the knowledge from the old classes to the new classes. The key idea is to enforce the popularly used conditional batch normalization (BN) to learn the class-specific information of the new classes from that of the old classes, with implicit knowledge sharing among the new ones. This allows for an efficient knowledge propagation from the old classes to the new classes, with the BN parameters increasing linearly with the number of new classes. The extensive evaluation demonstrates the clear superiority of the proposed method over state-of-the-art competitors for efficient conditional GAN transfer tasks. The code will be available at: https://github.com/mshahbazi72/cGANTransfer
HNMTP Conv: Optimize Convolution Algorithm for Single-Image Convolution Neural Network Inference on Mobile GPUs
Sep 06, 2019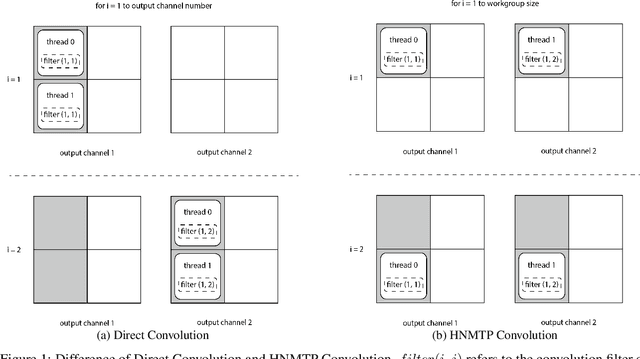


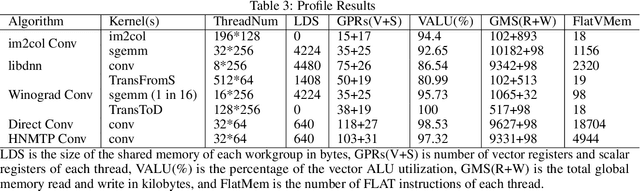
Convolution neural networks are widely used for mobile applications. However, GPU convolution algorithms are designed for mini-batch neural network training, the single-image convolution neural network inference algorithm on mobile GPUs is not well-studied. After discussing the usage difference and examining the existing convolution algorithms, we proposed the HNTMP convolution algorithm. The HNTMP convolution algorithm achieves $14.6 \times$ speedup than the most popular \textit{im2col} convolution algorithm, and $2.1 \times$ speedup than the fastest existing convolution algorithm (direct convolution) as far as we know.
Wider Channel Attention Network for Remote Sensing Image Super-resolution
Dec 13, 2018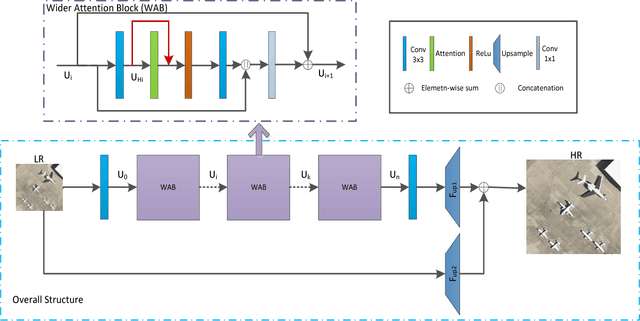



Recently, deep convolutional neural networks (CNNs) have obtained promising results in image processing tasks including super-resolution (SR). However, most CNN-based SR methods treat low-resolution (LR) inputs and features equally across channels, rarely notice the loss of information flow caused by the activation function and fail to leverage the representation ability of CNNs. In this letter, we propose a novel single-image super-resolution (SISR) algorithm named Wider Channel Attention Network (WCAN) for remote sensing images. Firstly, the channel attention mechanism is used to adaptively recalibrate the importance of each channel at the middle of the wider attention block (WAB). Secondly, we propose the Local Memory Connection (LMC) to enhance the information flow. Finally, the features within each WAB are fused to take advantage of the network's representation capability and further improve information and gradient flow. Analytic experiments on a public remote sensing data set (UC Merced) show that our WCAN achieves better accuracy and visual improvements against most state-of-the-art methods.
Noise2Noise: Learning Image Restoration without Clean Data
Oct 29, 2018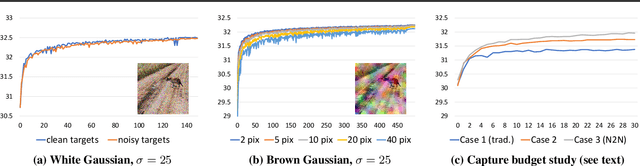
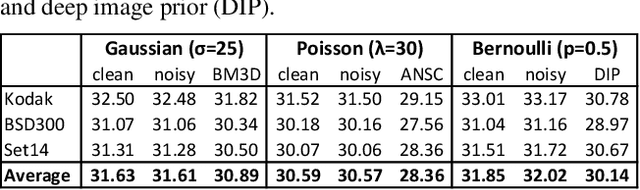

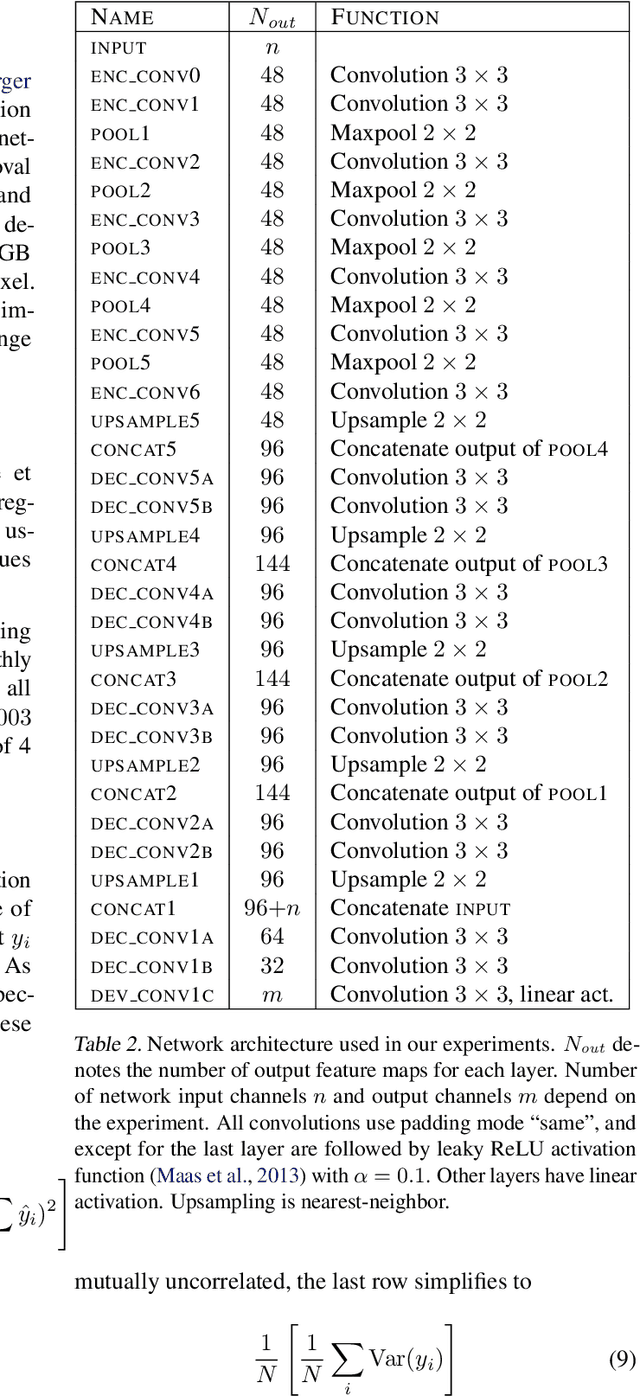
We apply basic statistical reasoning to signal reconstruction by machine learning -- learning to map corrupted observations to clean signals -- with a simple and powerful conclusion: it is possible to learn to restore images by only looking at corrupted examples, at performance at and sometimes exceeding training using clean data, without explicit image priors or likelihood models of the corruption. In practice, we show that a single model learns photographic noise removal, denoising synthetic Monte Carlo images, and reconstruction of undersampled MRI scans -- all corrupted by different processes -- based on noisy data only.