 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Working with AI: Measuring the Occupational Implications of Generative AI
Jul 10, 2025Given the rapid adoption of generative AI and its potential to impact a wide range of tasks, understanding the effects of AI on the economy is one of society's most important questions. In this work, we take a step toward that goal by analyzing the work activities people do with AI, how successfully and broadly those activities are done, and combine that with data on what occupations do those activities. We analyze a dataset of 200k anonymized and privacy-scrubbed conversations between users and Microsoft Bing Copilot, a publicly available generative AI system. We find the most common work activities people seek AI assistance for involve gathering information and writing, while the most common activities that AI itself is performing are providing information and assistance, writing, teaching, and advising. Combining these activity classifications with measurements of task success and scope of impact, we compute an AI applicability score for each occupation. We find the highest AI applicability scores for knowledge work occupation groups such as computer and mathematical, and office and administrative support, as well as occupations such as sales whose work activities involve providing and communicating information. Additionally, we characterize the types of work activities performed most successfully, how wage and education correlate with AI applicability, and how real-world usage compares to predictions of occupational AI impact.
WatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025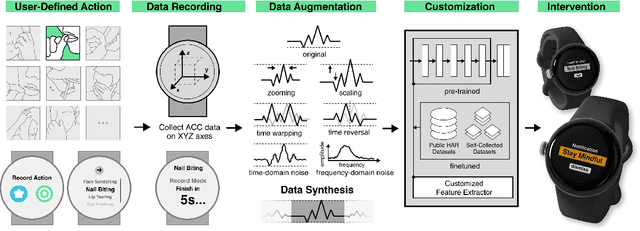
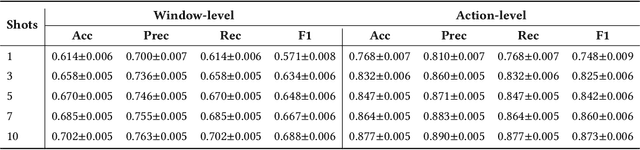
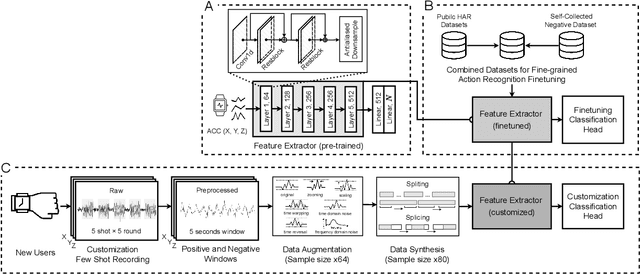
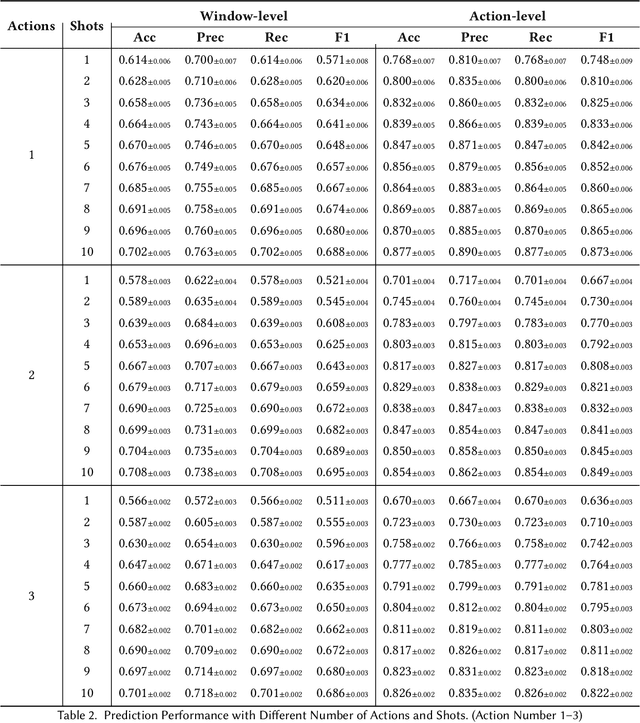
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
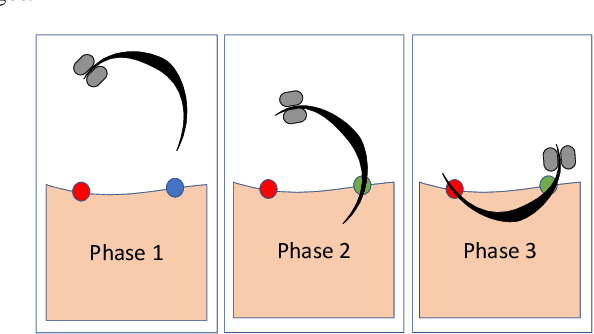
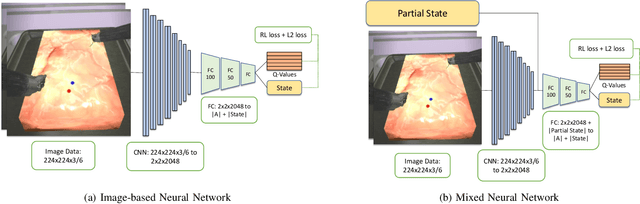
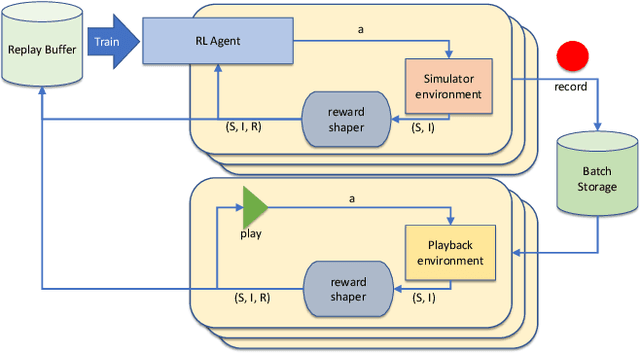
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.