 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Rex: Tactile-Reactive Dexterous Manipulation
Jun 15, 2026The ability to react dynamically to tactile signals has long been considered crucial to agile human-level dexterity. Yet contemporary learning-based Vision-Language-Action (VLA) models for robotic manipulation generally either overlook the tactile modality or are limited to encoders with static cues, due in part to the scarcity of diverse training data and standardized evaluation, architectural constraints in current VLA models, and limitations of static tactile encoders. In this paper, we push the frontier of tactile-reactive manipulation by addressing all of these limitations. We propose a large-scale, 100-hour tactile-rich dataset collected via a novel, data-efficient recipe that prioritizes elementary motor primitives. To effectively exploit naturally high-frequency touch signals without sacrificing the existing capabilities of existing VLAs, we introduce a variable-rate Mixture-of-Transformers (MoT) architecture equipped with a novel temporal tactile VQ-VAE encoder. We demonstrate the effectiveness of tactile-reactive policies on 12 manipulation tasks requiring delicate force control and deformable object manipulation, achieving over 30% higher average success rate than the strongest baseline.
CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
Mar 23, 2026"Code-as-Policy" considers how executable code can complement data-intensive Vision-Language-Action (VLA) methods, yet their effectiveness as autonomous controllers for embodied manipulation remains underexplored. We present CaP-X, an open-access framework for systematically studying Code-as-Policy agents in robot manipulation. At its core is CaP-Gym, an interactive environment in which agents control robots by synthesizing and executing programs that compose perception and control primitives. Building on this foundation, CaP-Bench evaluates frontier language and vision-language models across varying levels of abstraction, interaction, and perceptual grounding. Across 12 models, CaP-Bench reveals a consistent trend: performance improves with human-crafted abstractions but degrades as these priors are removed, exposing a dependence on designer scaffolding. At the same time, we observe that this gap can be mitigated through scaling agentic test-time computation--through multi-turn interaction, structured execution feedback, visual differencing, automatic skill synthesis, and ensembled reasoning--substantially improves robustness even when agents operate over low-level primitives. These findings allow us to derive CaP-Agent0, a training-free framework that recovers human-level reliability on several manipulation tasks in simulation and on real embodiments. We further introduce CaP-RL, showing reinforcement learning with verifiable rewards improves success rates and transfers from sim2real with minimal gap. Together, CaP-X provides a principled, open-access platform for advancing embodied coding agents.
Mirage The Illusion of Visual Understanding
Mar 23, 2026Multimodal AI systems have achieved remarkable performance across a broad range of real-world tasks, yet the mechanisms underlying visual-language reasoning remain surprisingly poorly understood. We report three findings that challenge prevailing assumptions about how these systems process and integrate visual information. First, Frontier models readily generate detailed image descriptions and elaborate reasoning traces, including pathology-biased clinical findings, for images never provided; we term this phenomenon mirage reasoning. Second, without any image input, models also attain strikingly high scores across general and medical multimodal benchmarks, bringing into question their utility and design. In the most extreme case, our model achieved the top rank on a standard chest X-ray question-answering benchmark without access to any images. Third, when models were explicitly instructed to guess answers without image access, rather than being implicitly prompted to assume images were present, performance declined markedly. Explicit guessing appears to engage a more conservative response regime, in contrast to the mirage regime in which models behave as though images have been provided. These findings expose fundamental vulnerabilities in how visual-language models reason and are evaluated, pointing to an urgent need for private benchmarks that eliminate textual cues enabling non-visual inference, particularly in medical contexts where miscalibrated AI carries the greatest consequence. We introduce B-Clean as a principled solution for fair, vision-grounded evaluation of multimodal AI systems.
DDRprog: A CLEVR Differentiable Dynamic Reasoning Programmer
Mar 30, 2018



We present a novel Dynamic Differentiable Reasoning (DDR) framework for jointly learning branching programs and the functions composing them; this resolves a significant nondifferentiability inhibiting recent dynamic architectures. We apply our framework to two settings in two highly compact and data efficient architectures: DDRprog for CLEVR Visual Question Answering and DDRstack for reverse Polish notation expression evaluation. DDRprog uses a recurrent controller to jointly predict and execute modular neural programs that directly correspond to the underlying question logic; it explicitly forks subprocesses to handle logical branching. By effectively leveraging additional structural supervision, we achieve a large improvement over previous approaches in subtask consistency and a small improvement in overall accuracy. We further demonstrate the benefits of structural supervision in the RPN setting: the inclusion of a stack assumption in DDRstack allows our approach to generalize to long expressions where an LSTM fails the task.
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Feb 23, 2016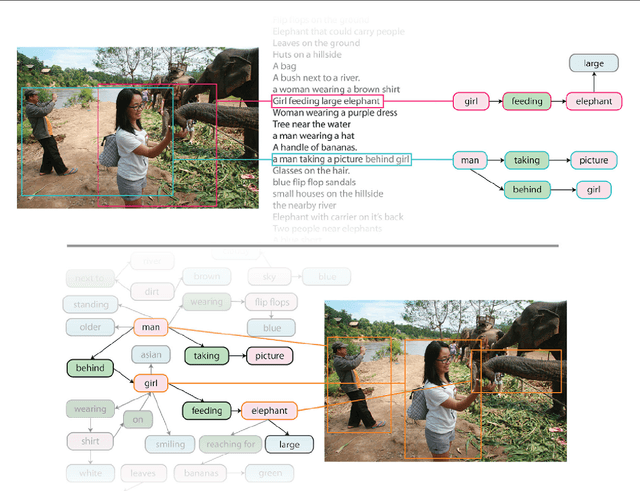
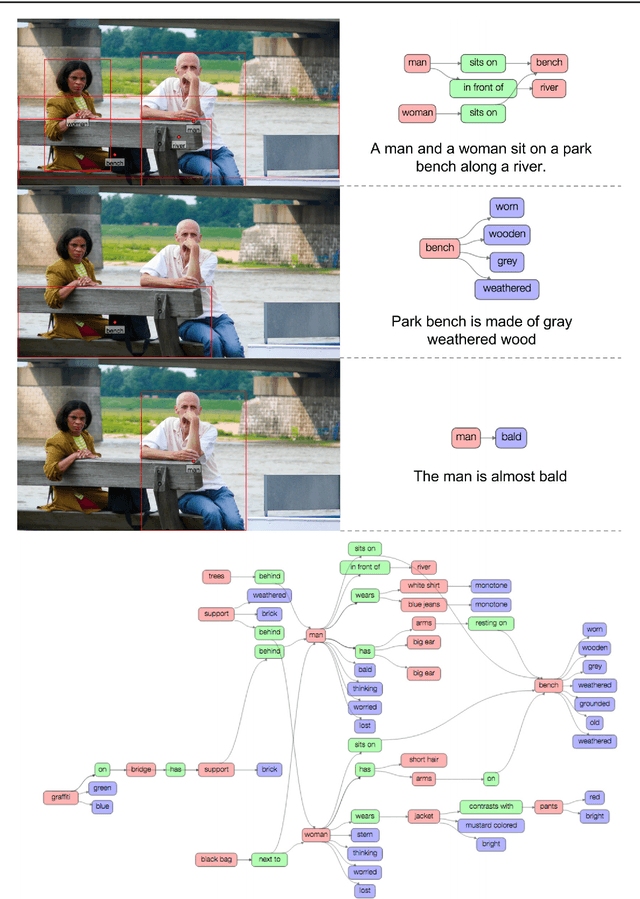

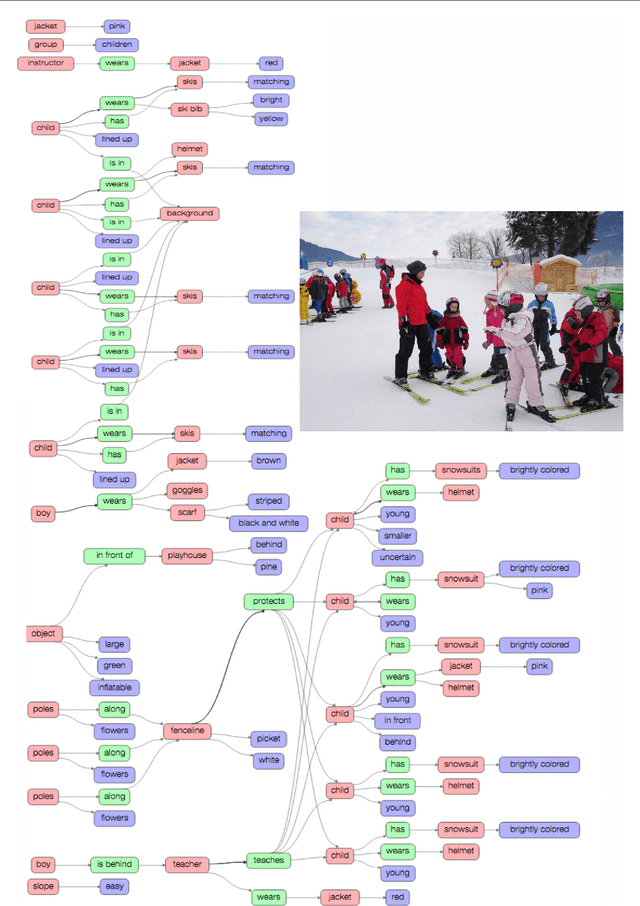
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked "What vehicle is the person riding?", computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) in order to answer correctly that "the person is riding a horse-drawn carriage". In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 100K images where each image has an average of 21 objects, 18 attributes, and 18 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answers.
Love Thy Neighbors: Image Annotation by Exploiting Image Metadata
Sep 22, 2015
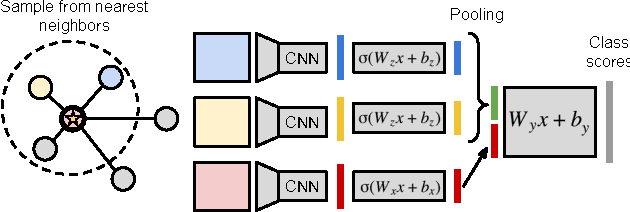
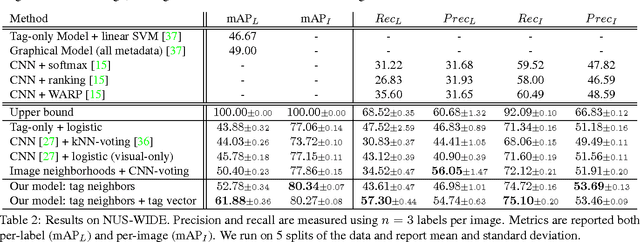
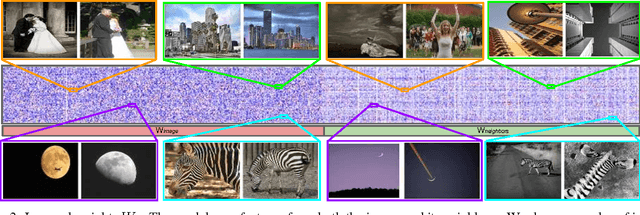
Some images that are difficult to recognize on their own may become more clear in the context of a neighborhood of related images with similar social-network metadata. We build on this intuition to improve multilabel image annotation. Our model uses image metadata nonparametrically to generate neighborhoods of related images using Jaccard similarities, then uses a deep neural network to blend visual information from the image and its neighbors. Prior work typically models image metadata parametrically, in contrast, our nonparametric treatment allows our model to perform well even when the vocabulary of metadata changes between training and testing. We perform comprehensive experiments on the NUS-WIDE dataset, where we show that our model outperforms state-of-the-art methods for multilabel image annotation even when our model is forced to generalize to new types of metadata.