 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scene-based Factored Attention for Image Captioning
Aug 18, 2019
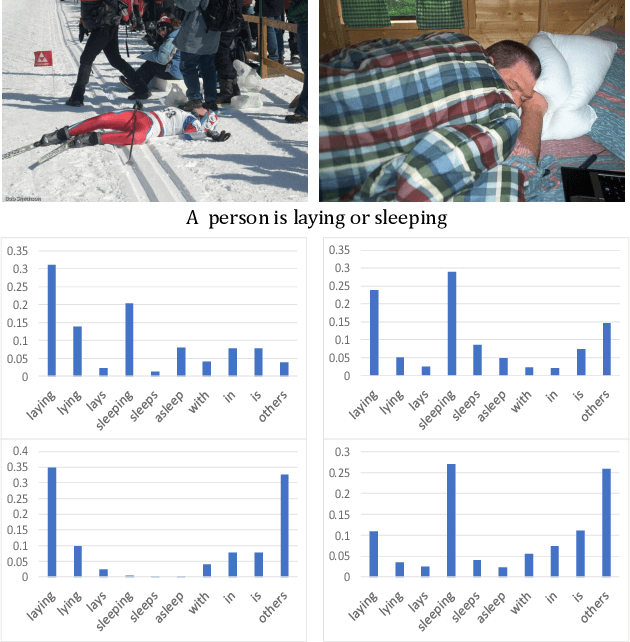
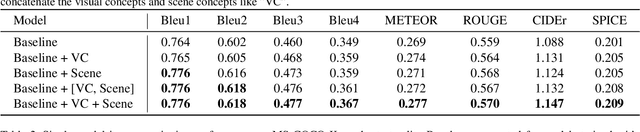
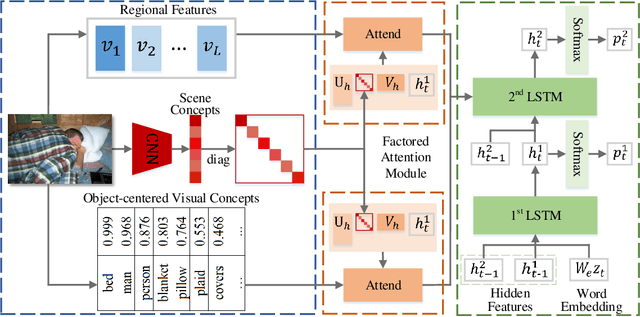
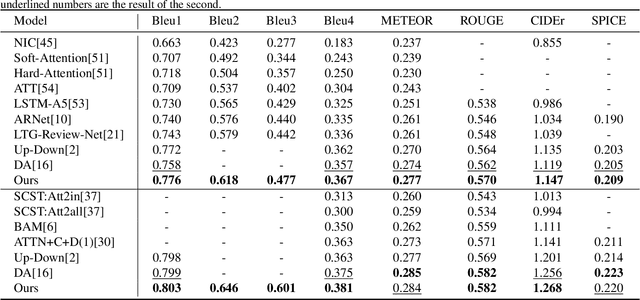
Image captioning has attracted ever-increasing research attention in the multimedia community. To this end, most cutting-edge works rely on an encoder-decoder framework with attention mechanisms, which have achieved remarkable progress. However, such a framework does not consider scene concepts to attend visual information, which leads to sentence bias in caption generation and defects the performance correspondingly. We argue that such scene concepts capture higher-level visual semantics and serve as an important cue in describing images. In this paper, we propose a novel scene-based factored attention module for image captioning. Specifically, the proposed module first embeds the scene concepts into factored weights explicitly and attends the visual information extracted from the input image. Then, an adaptive LSTM is used to generate captions for specific scene types. Experimental results on Microsoft COCO benchmark show that the proposed scene-based attention module improves model performance a lot, which outperforms the state-of-the-art approaches under various evaluation metrics.
Generative Image Inpainting with Submanifold Alignment
Aug 01, 2019
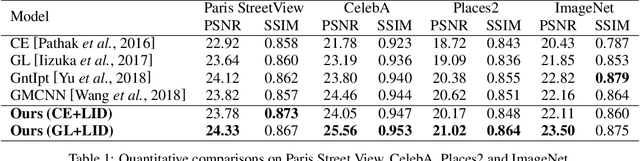
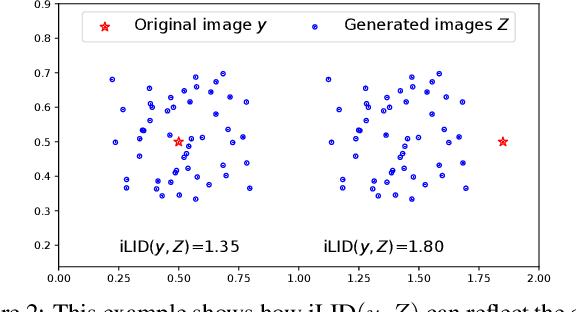
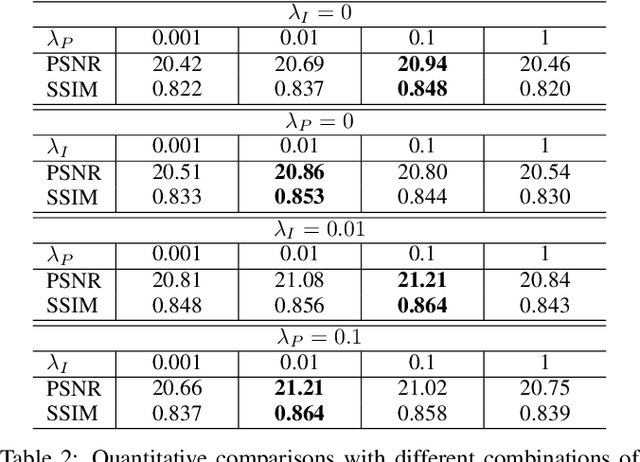
Image inpainting aims at restoring missing regions of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based generative inpainting models do not explicitly exploit the structural or textural consistency between restored contents and their surrounding contexts.To address this limitation, we propose to enforce the alignment (or closeness) between the local data submanifolds (or subspaces) around restored images and those around the original (uncorrupted) images during the learning process of GAN-based inpainting models. We exploit Local Intrinsic Dimensionality (LID) to measure, in deep feature space, the alignment between data submanifolds learned by a GAN model and those of the original data, from a perspective of both images (denoted as iLID) and local patches (denoted as pLID) of images. We then apply iLID and pLID as regularizations for GAN-based inpainting models to encourage two levels of submanifold alignment: 1) an image-level alignment for improving structural consistency, and 2) a patch-level alignment for improving textural details. Experimental results on four benchmark datasets show that our proposed model can generate more accurate results than state-of-the-art models.
A nonlocal feature-driven exemplar-based approach for image inpainting
Sep 20, 2019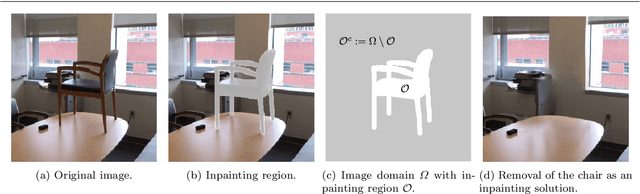
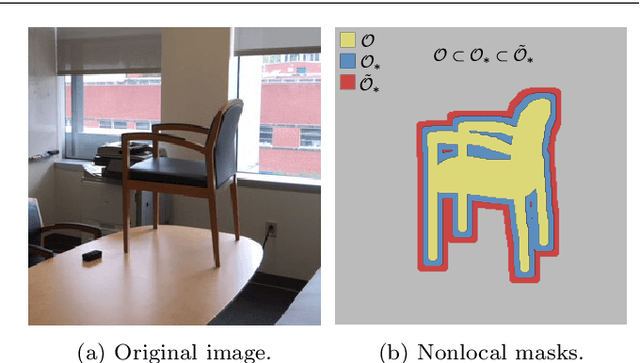


We present a nonlocal variational image completion technique which admits simultaneous inpainting of multiple structures and textures in a unified framework. The recovery of geometric structures is achieved by using general convolution operators as a measure of behavior within an image. These are combined with a nonlocal exemplar-based approach to exploit the self-similarity of an image in the selected feature domains and to ensure the inpainting of textures. We also introduce an anisotropic patch distance metric to allow for better control of the feature selection within an image and present a nonlocal energy functional based on this metric. Finally, we derive an optimization algorithm for the proposed variational model and examine its validity experimentally with various test images.
Image-Dependent Local Entropy Models for Learned Image Compression
May 31, 2018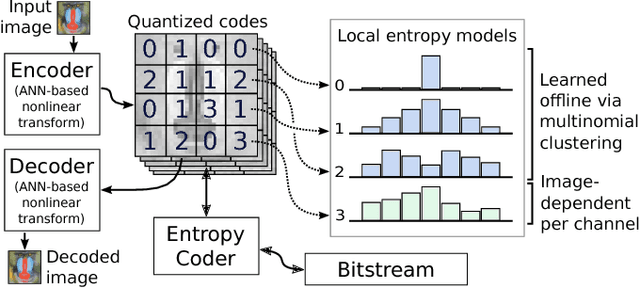

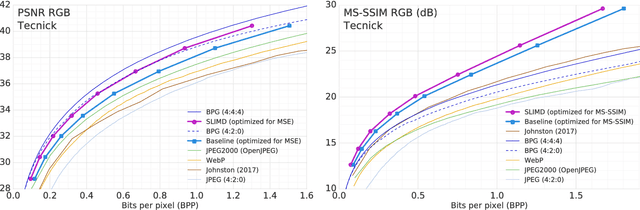
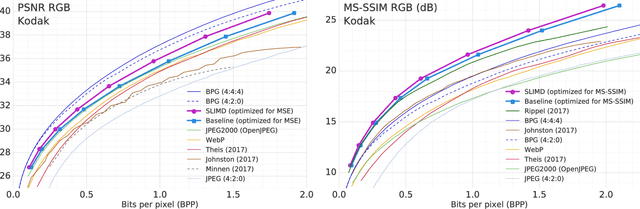
The leading approach for image compression with artificial neural networks (ANNs) is to learn a nonlinear transform and a fixed entropy model that are optimized for rate-distortion performance. We show that this approach can be significantly improved by incorporating spatially local, image-dependent entropy models. The key insight is that existing ANN-based methods learn an entropy model that is shared between the encoder and decoder, but they do not transmit any side information that would allow the model to adapt to the structure of a specific image. We present a method for augmenting ANN-based image coders with image-dependent side information that leads to a 17.8% rate reduction over a state-of-the-art ANN-based baseline model on a standard evaluation set, and 70-98% reductions on images with low visual complexity that are poorly captured by a fixed, global entropy model.
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning
Jun 04, 2021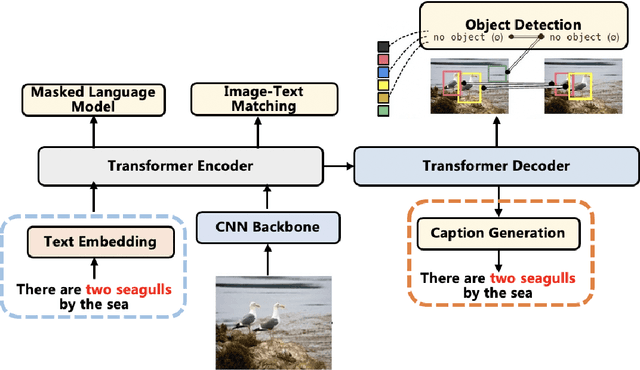
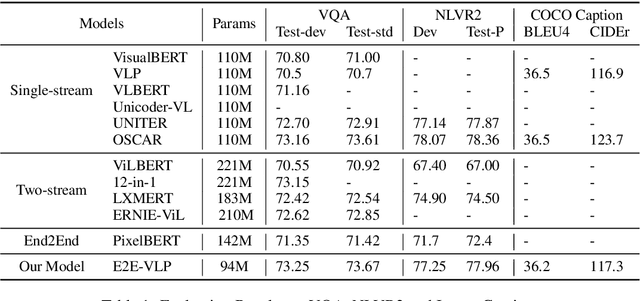
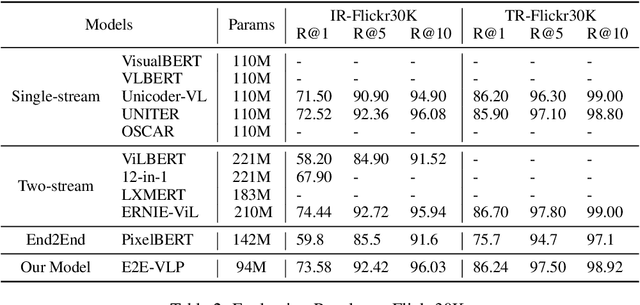
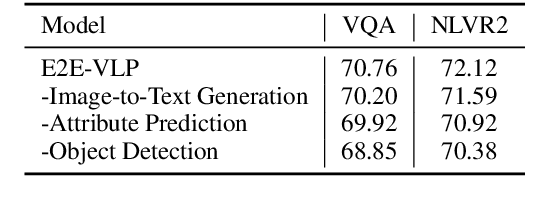
Vision-language pre-training (VLP) on large-scale image-text pairs has achieved huge success for the cross-modal downstream tasks. The most existing pre-training methods mainly adopt a two-step training procedure, which firstly employs a pre-trained object detector to extract region-based visual features, then concatenates the image representation and text embedding as the input of Transformer to train. However, these methods face problems of using task-specific visual representation of the specific object detector for generic cross-modal understanding, and the computation inefficiency of two-stage pipeline. In this paper, we propose the first end-to-end vision-language pre-trained model for both V+L understanding and generation, namely E2E-VLP, where we build a unified Transformer framework to jointly learn visual representation, and semantic alignments between image and text. We incorporate the tasks of object detection and image captioning into pre-training with a unified Transformer encoder-decoder architecture for enhancing visual learning. An extensive set of experiments have been conducted on well-established vision-language downstream tasks to demonstrate the effectiveness of this novel VLP paradigm.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021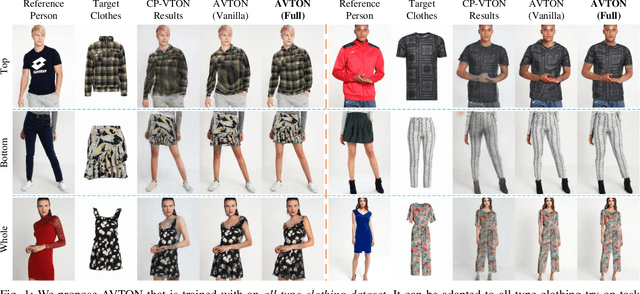
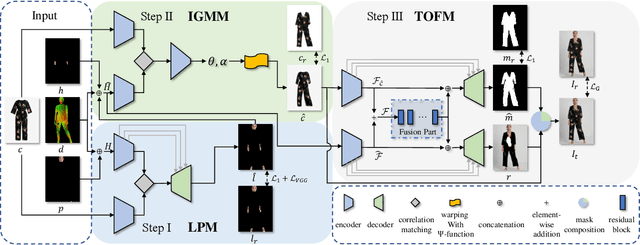


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.
Fiducial marker recovery and detection from severely truncated data in navigation assisted spine surgery
Sep 01, 2021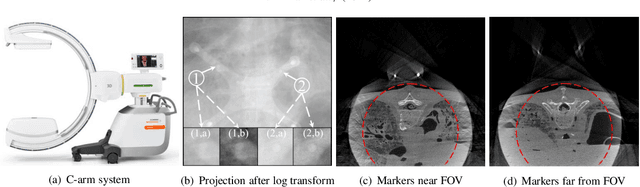
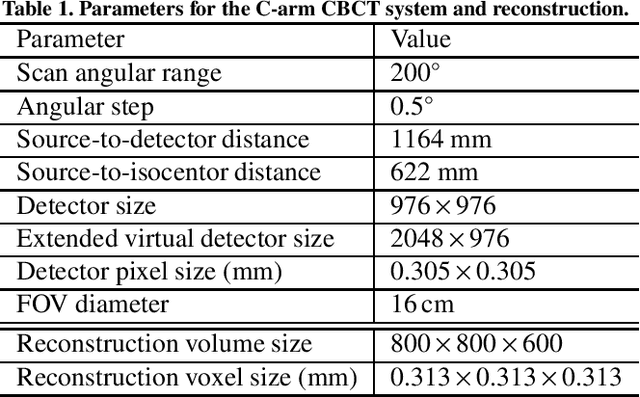
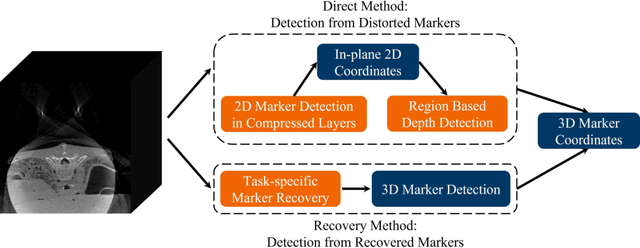

Fiducial markers are commonly used in navigation assisted minimally invasive spine surgery (MISS) and they help transfer image coordinates into real world coordinates. In practice, these markers might be located outside the field-of-view (FOV), due to the limited detector sizes of C-arm cone-beam computed tomography (CBCT) systems used in intraoperative surgeries. As a consequence, reconstructed markers in CBCT volumes suffer from artifacts and have distorted shapes, which sets an obstacle for navigation. In this work, we propose two fiducial marker detection methods: direct detection from distorted markers (direct method) and detection after marker recovery (recovery method). For direct detection from distorted markers in reconstructed volumes, an efficient automatic marker detection method using two neural networks and a conventional circle detection algorithm is proposed. For marker recovery, a task-specific learning strategy is proposed to recover markers from severely truncated data. Afterwards, a conventional marker detection algorithm is applied for position detection. The two methods are evaluated on simulated data and real data, both achieving a marker registration error smaller than 0.2 mm. Our experiments demonstrate that the direct method is capable of detecting distorted markers accurately and the recovery method with task-specific learning has high robustness and generalizability on various data sets. In addition, the task-specific learning is able to reconstruct other structures of interest accurately, e.g. ribs for image-guided needle biopsy, from severely truncated data, which empowers CBCT systems with new potential applications.
Light Field Synthesis by Training Deep Network in the Refocused Image Domain
Nov 07, 2019

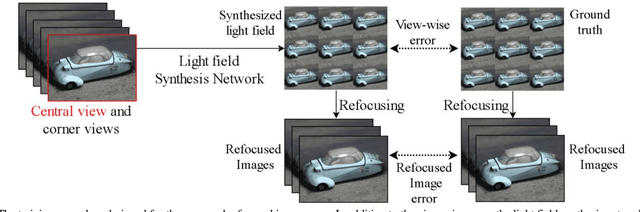
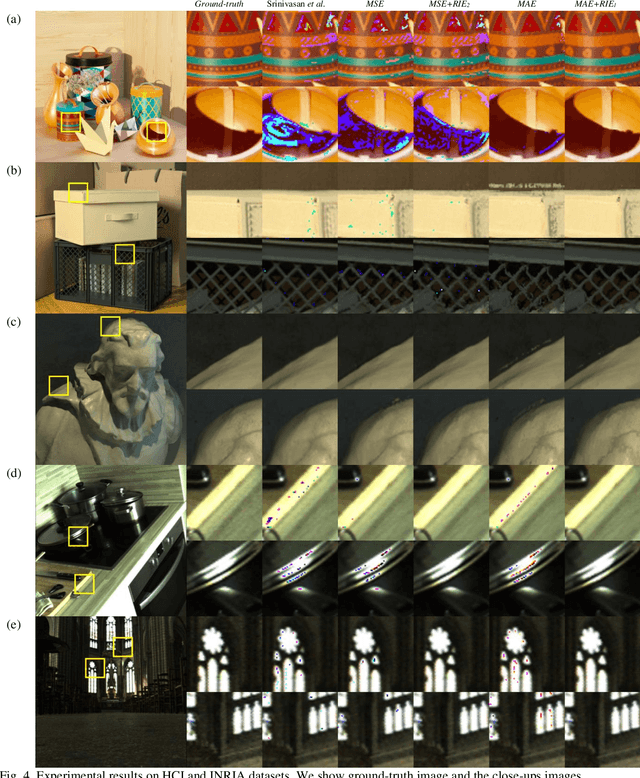
Light field imaging, which captures spatio-angular information of incident light on image sensor, enables many interesting applications like image refocusing and augmented reality. However, due to the limited sensor resolution, a trade-off exists between the spatial and angular resolution. To increase the angular resolution, view synthesis techniques have been adopted to generate new views from existing views. However, traditional learning-based view synthesis mainly considers the image quality of each view of the light field and neglects the quality of the refocused images. In this paper, we propose a new loss function called refocused image error (RIE) to address the issue. The main idea is that the image quality of the synthesized light field should be optimized in the refocused image domain because it is where the light field is perceived. We analyze the behavior of RIL in the spectral domain and test the performance of our approach against previous approaches on both real and software-rendered light field datasets using objective assessment metrics such as MSE, MAE, PSNR, SSIM, and GMSD. Experimental results show that the light field generated by our method results in better refocused images than previous methods.
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021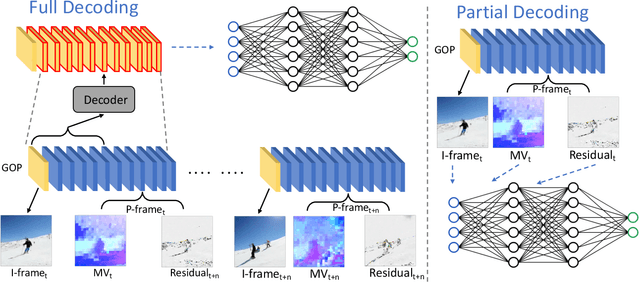


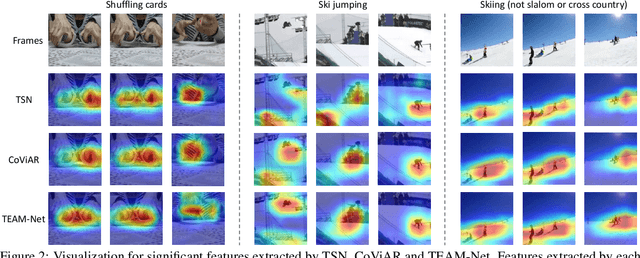
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
An Image Based Visual Servo Approach with Deep Learning for Robotic Manipulation
Sep 17, 2019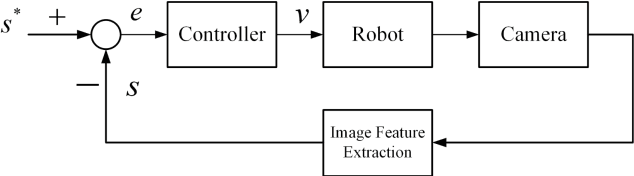
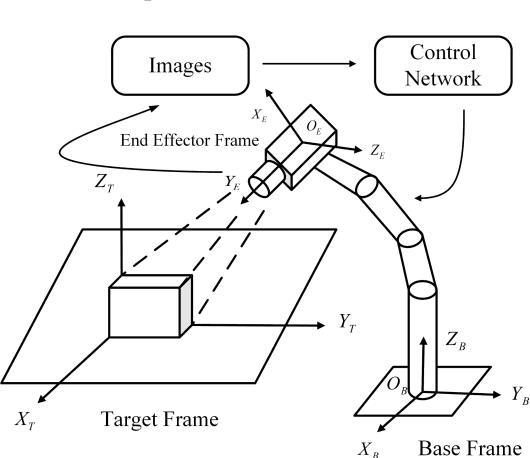
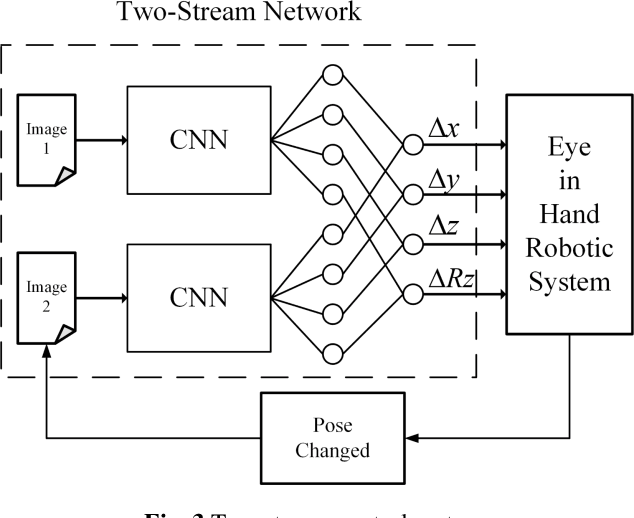
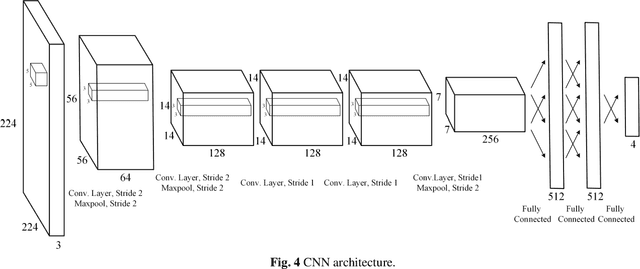
Aiming at the difficulty of extracting image features and estimating the Jacobian matrix in image based visual servo, this paper proposes an image based visual servo approach with deep learning. With the powerful learning capabilities of convolutional neural networks(CNN), autonomous learning to extract features from images and fitting the nonlinear relationships from image space to task space is achieved, which can greatly facilitate the image based visual servo procedure. Based on the above ideas a two-stream network based on convolutional neural network is designed and the corresponding control scheme is proposed to realize the four degrees of freedom visual servo of the robot manipulator. Collecting images of observed target under different pose parameters of the manipulator as training samples for CNN, the trained network can be used to estimate the nonlinear relationship from 2D image space to 3D Cartesian space. The two-stream network takes the current image and the desirable image as inputs and makes them equal to guide the manipulator to the desirable pose. The effectiveness of the approach is verified with experimental results.