 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-CSEA: A Graph-Based Conflict Set Extraction Algorithm for Identifying Infeasibility in Pseudo-Boolean Models
Sep 16, 2025Workforce scheduling involves a variety of rule-based constraints-such as shift limits, staffing policies, working hour restrictions, and many similar scheduling rules-which can interact in conflicting ways, leading to infeasible models. Identifying the underlying causes of such infeasibility is critical for resolving scheduling issues and restoring feasibility. A common diagnostic approach is to compute Irreducible Infeasible Subsets (IISs): minimal sets of constraints that are jointly infeasible but become feasible when any one is removed. We consider models formulated using pseudo-Boolean constraints with inequality relations over binary variables, which naturally encode scheduling logic. Existing IIS extraction methods such as Additive Deletion and QuickXplain rely on repeated feasibility checks, often incurring large numbers of solver calls. Dual ray analysis, while effective for LP-based models, may fail when the relaxed problem is feasible but the underlying pseudo-Boolean model is not. To address these limitations, we propose Graph-based Conflict Set Extraction Algorithm (G-CSEA) to extract a conflict set, an approach inspired by Conflict-Driven Clause Learning (CDCL) in SAT solvers. Our method constructs an implication graph during constraint propagation and, upon detecting a conflict, traces all contributing constraints across both decision branches. The resulting conflict set can optionally be minimized using QuickXplain to produce an IIS.
Discretized Approximate Ancestral Sampling
May 09, 2025The Fourier Basis Density Model (FBM) was recently introduced as a flexible probability model for band-limited distributions, i.e. ones which are smooth in the sense of having a characteristic function with limited support around the origin. Its density and cumulative distribution functions can be efficiently evaluated and trained with stochastic optimization methods, which makes the model suitable for deep learning applications. However, the model lacked support for sampling. Here, we introduce a method inspired by discretization--interpolation methods common in Digital Signal Processing, which directly take advantage of the band-limited property. We review mathematical properties of the FBM, and prove quality bounds of the sampled distribution in terms of the total variation (TV) and Wasserstein--1 divergences from the model. These bounds can be used to inform the choice of hyperparameters to reach any desired sample quality. We discuss these results in comparison to a variety of other sampling techniques, highlighting tradeoffs between computational complexity and sampling quality.
Fourier Head: Helping Large Language Models Learn Complex Probability Distributions
Oct 29, 2024As the quality of large language models has improved, there has been increased interest in using them to model non-linguistic tokens. For example, the Decision Transformer recasts agentic decision making as a sequence modeling problem, using a decoder-only LLM to model the distribution over the discrete action space for an Atari agent. However, when adapting LLMs to non-linguistic domains, it remains unclear if softmax over discrete bins captures the continuous structure of the tokens and the potentially complex distributions needed for high quality token generation. We introduce a neural network layer, constructed using Fourier series, which we can easily substitute for any linear layer if we want the outputs to have a more continuous structure. We perform extensive analysis on synthetic datasets, as well as on large-scale decision making and time series forecasting tasks. We also provide theoretical evidence that this layer can better learn signal from data while ignoring high-frequency noise. All of our results support the effectiveness of our proposed Fourier head in scenarios where the underlying data distribution has a natural continuous structure. For example, the Fourier head improves a Decision Transformer agent's returns by 46% on the Atari Seaquest game, and increases a state-of-the-art times series foundation model's forecasting performance by 3.5% across 20 benchmarks unseen during training.
Stochastic Sampling from Deterministic Flow Models
Oct 03, 2024



Deterministic flow models, such as rectified flows, offer a general framework for learning a deterministic transport map between two distributions, realized as the vector field for an ordinary differential equation (ODE). However, they are sensitive to model estimation and discretization errors and do not permit different samples conditioned on an intermediate state, limiting their application. We present a general method to turn the underlying ODE of such flow models into a family of stochastic differential equations (SDEs) that have the same marginal distributions. This method permits us to derive families of \emph{stochastic samplers}, for fixed (e.g., previously trained) \emph{deterministic} flow models, that continuously span the spectrum of deterministic and stochastic sampling, given access to the flow field and the score function. Our method provides additional degrees of freedom that help alleviate the issues with the deterministic samplers and empirically outperforms them. We empirically demonstrate advantages of our method on a toy Gaussian setup and on the large scale ImageNet generation task. Further, our family of stochastic samplers provide an additional knob for controlling the diversity of generation, which we qualitatively demonstrate in our experiments.
Fourier Basis Density Model
Feb 23, 2024



We introduce a lightweight, flexible and end-to-end trainable probability density model parameterized by a constrained Fourier basis. We assess its performance at approximating a range of multi-modal 1D densities, which are generally difficult to fit. In comparison to the deep factorized model introduced in [1], our model achieves a lower cross entropy at a similar computational budget. In addition, we also evaluate our method on a toy compression task, demonstrating its utility in learned compression.
ssVERDICT: Self-Supervised VERDICT-MRI for Enhanced Prostate Tumour Characterisation
Sep 27, 2023
Purpose: Demonstrating and assessing self-supervised machine learning fitting of the VERDICT (Vascular, Extracellular and Restricted DIffusion for Cytometry in Tumours) model for prostate. Methods: We derive a self-supervised neural network for fitting VERDICT (ssVERDICT) that estimates parameter maps without training data. We compare the performance of ssVERDICT to two established baseline methods for fitting diffusion MRI models: conventional nonlinear least squares (NLLS) and supervised deep learning. We do this quantitatively on simulated data, by comparing the Pearson's correlation coefficient, mean-squared error (MSE), bias, and variance with respect to the simulated ground truth. We also calculate in vivo parameter maps on a cohort of 20 prostate cancer patients and compare the methods' performance in discriminating benign from cancerous tissue via Wilcoxon's signed-rank test. Results: In simulations, ssVERDICT outperforms the baseline methods (NLLS and supervised DL) in estimating all the parameters from the VERDICT prostate model in terms of Pearson's correlation coefficient, bias, and MSE. In vivo, ssVERDICT shows stronger lesion conspicuity across all parameter maps, and improves discrimination between benign and cancerous tissue over the baseline methods. Conclusion: ssVERDICT significantly outperforms state-of-the-art methods for VERDICT model fitting, and shows for the first time, fitting of a complex three-compartment biophysical model with machine learning without the requirement of explicit training labels.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022



Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
LilNetX: Lightweight Networks with EXtreme Model Compression and Structured Sparsification
Apr 06, 2022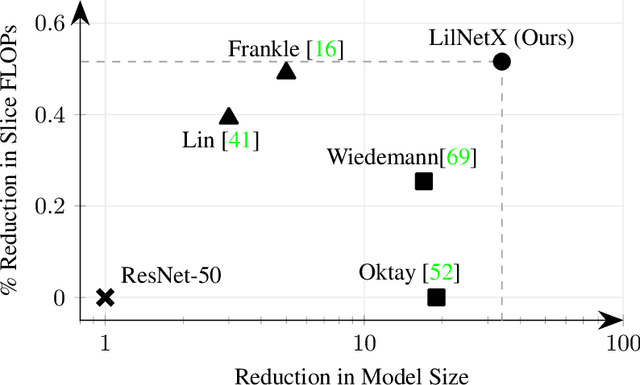

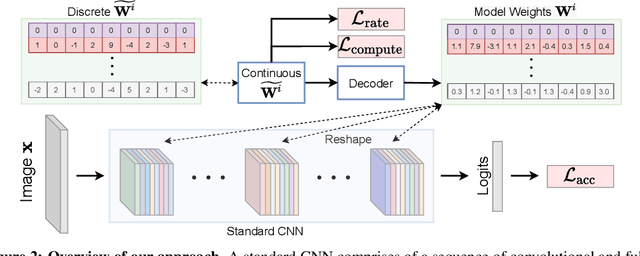
We introduce LilNetX, an end-to-end trainable technique for neural networks that enables learning models with specified accuracy-rate-computation trade-off. Prior works approach these problems one at a time and often require post-processing or multistage training which become less practical and do not scale very well for large datasets or architectures. Our method constructs a joint training objective that penalizes the self-information of network parameters in a reparameterized latent space to encourage small model size while also introducing priors to increase structured sparsity in the parameter space to reduce computation. We achieve up to 50% smaller model size and 98% model sparsity on ResNet-20 while retaining the same accuracy on the CIFAR-10 dataset as well as 35% smaller model size and 42% structured sparsity on ResNet-50 trained on ImageNet, when compared to existing state-of-the-art model compression methods. Code is available at https://github.com/Sharath-girish/LilNetX.
3D Scene Compression through Entropy Penalized Neural Representation Functions
Apr 26, 2021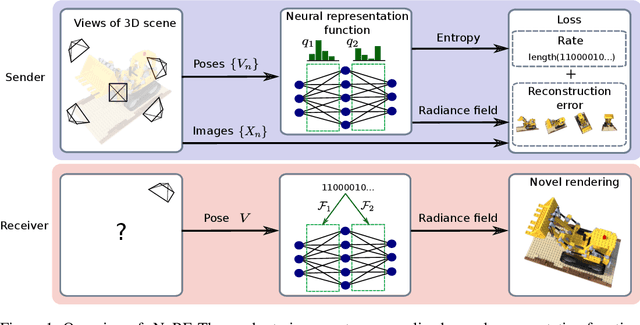
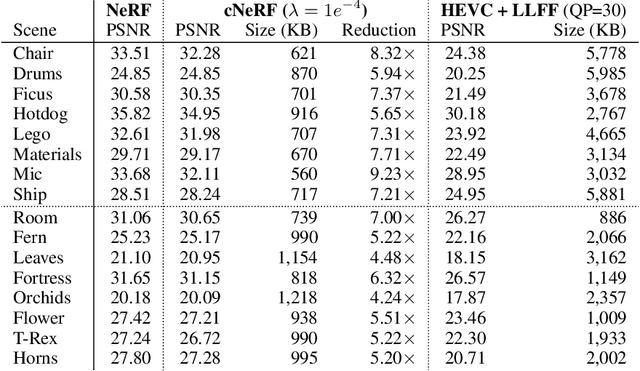
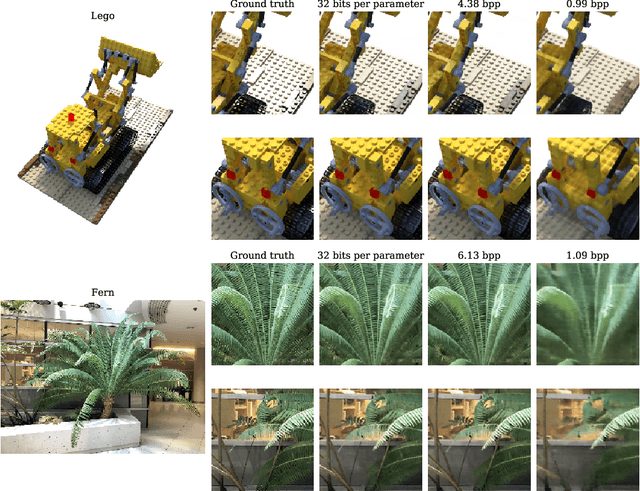
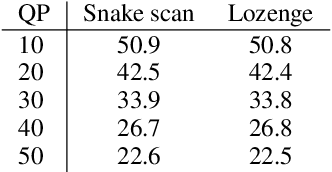
Some forms of novel visual media enable the viewer to explore a 3D scene from arbitrary viewpoints, by interpolating between a discrete set of original views. Compared to 2D imagery, these types of applications require much larger amounts of storage space, which we seek to reduce. Existing approaches for compressing 3D scenes are based on a separation of compression and rendering: each of the original views is compressed using traditional 2D image formats; the receiver decompresses the views and then performs the rendering. We unify these steps by directly compressing an implicit representation of the scene, a function that maps spatial coordinates to a radiance vector field, which can then be queried to render arbitrary viewpoints. The function is implemented as a neural network and jointly trained for reconstruction as well as compressibility, in an end-to-end manner, with the use of an entropy penalty on the parameters. Our method significantly outperforms a state-of-the-art conventional approach for scene compression, achieving simultaneously higher quality reconstructions and lower bitrates. Furthermore, we show that the performance at lower bitrates can be improved by jointly representing multiple scenes using a soft form of parameter sharing.
A Review on Cyber Crimes on the Internet of Things
Sep 12, 2020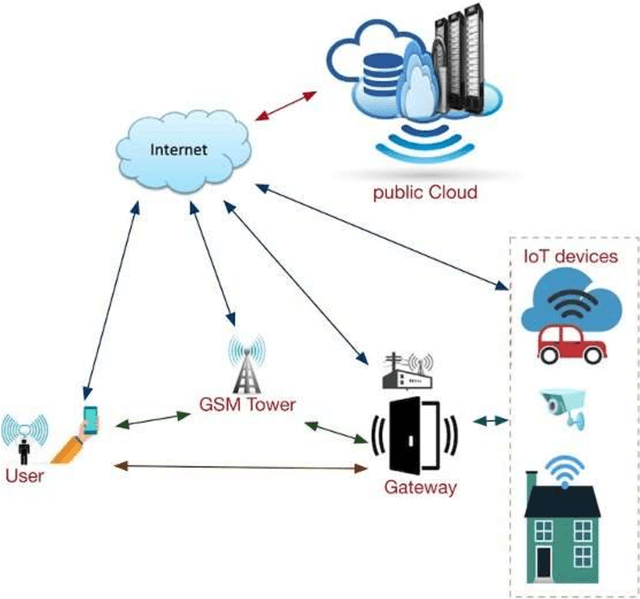
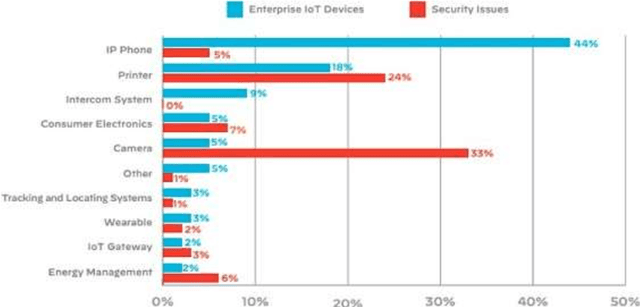
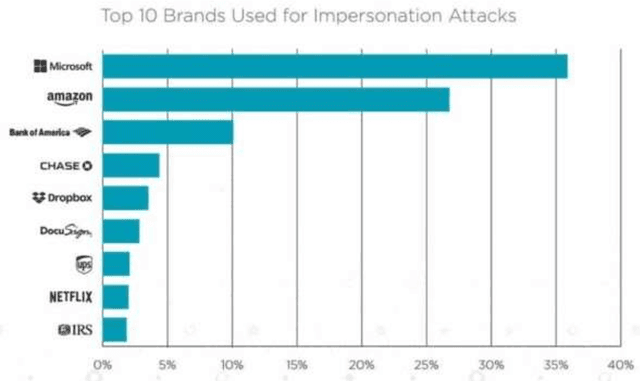
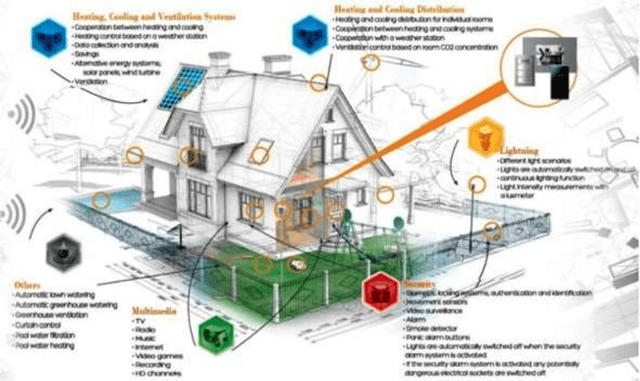
Internet of Things (IoT) devices are rapidly becoming universal. The success of IoT cannot be ignored in the scenario today, along with its attacks and threats on IoT devices and facilities are also increasing day by day. Cyber attacks become a part of IoT and affecting the life and society of users, so steps must be taken to defend cyber seriously. Cybercrimes threaten the infrastructure of governments and businesses globally and can damage the users in innumerable ways. With the global cybercrime damages predicted to cost up to 6 trillion dollars annually on the global economy by cyber crime. Estimated of 328 Million Dollar annual losses with the cyber attacks in Australia itself. Various steps are taken to slow down these attacks but unfortunately not able to achieve success properly. Therefor secure IoT is the need of this time and understanding of attacks and threats in IoT structure should be studied. The reasons for cyber-attacks can be Countries having week cyber securities, Cybercriminals use new technologies to attack, Cybercrime is possible with services and other business schemes. MSP (Managed Service Providers) face different difficulties in fighting with Cyber-crime. They have to ensure that security of the customer as well as their security in terms of their servers, devices, and systems. Hence, they must use effective, fast, and easily usable antivirus and antimalware tools.