 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Guided Undersampling Mask Design for MR Image Reconstruction
Mar 08, 2020

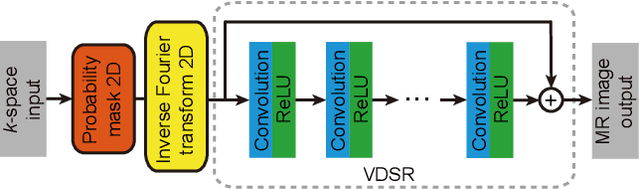
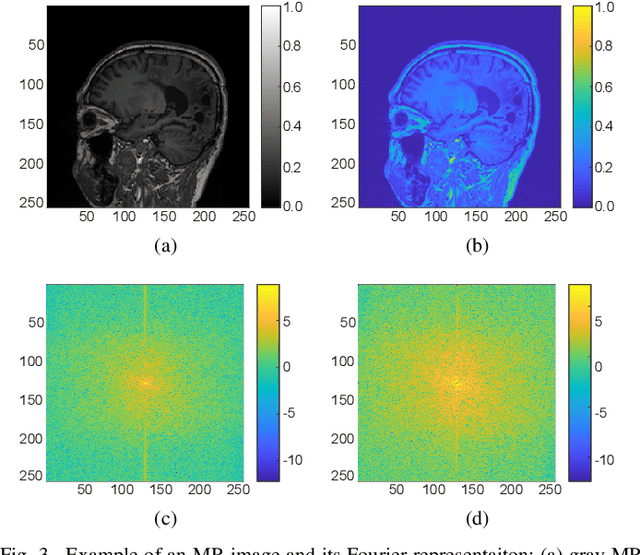
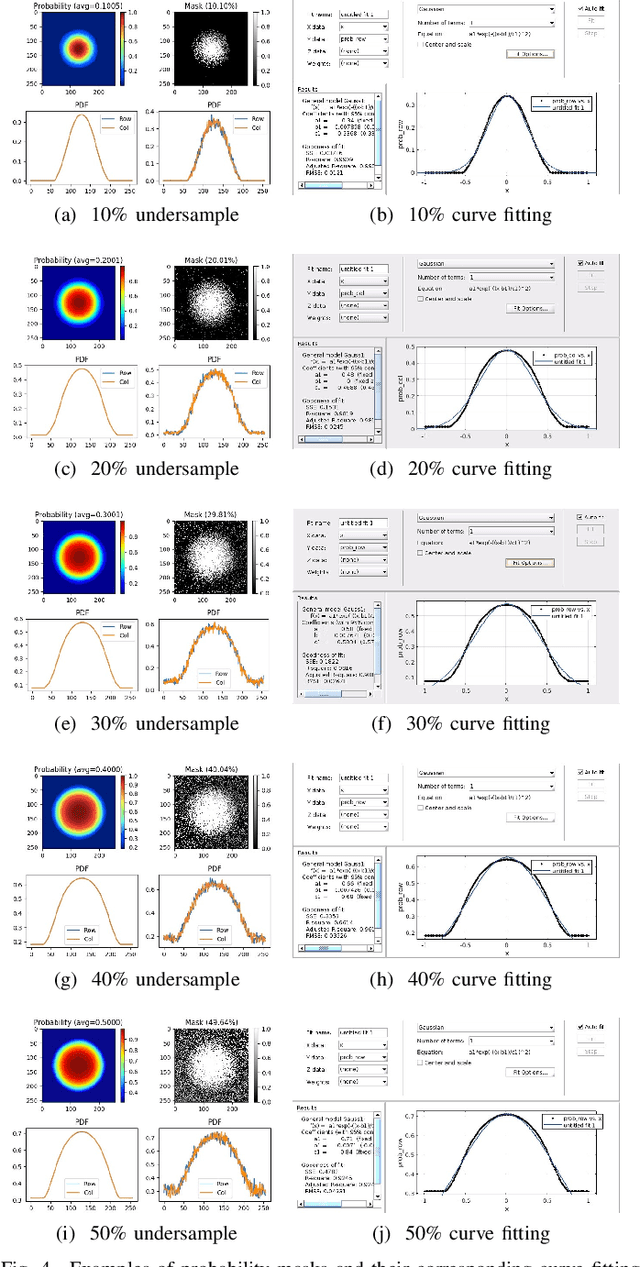
In this paper, we propose a cross-domain networks that can achieve undersampled MR image reconstruction from raw k-space space. We design a 2D probability sampling mask layer to simulate real undersampling operation. Then the 2D Inverse FFT is deployed to reconstruct MR image from frequency domain to spatial domain. By minimizing the Euclidean loss between ground-truth image and output, we train the parameters in our probability mask layer. We discover the probability appears special patterns that is quite different from universal common sense that mask should be Poisson-like, under certain undersampled rates. We analyze the probability mask is subjected to Gaussian or Quadratic distributions, and discuss this pattern will be more accurate and robust than traditional ones. Extensive experiments proves that the rules we discovered are adaptive to most cases. This can be a useful guidance to further MR reconstruction mask designs.
Virtuoso: Video-based Intelligence for real-time tuning on SOCs
Dec 24, 2021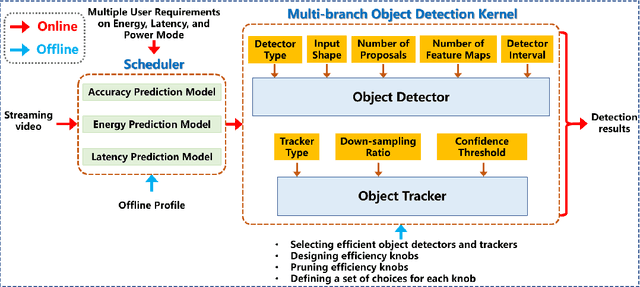
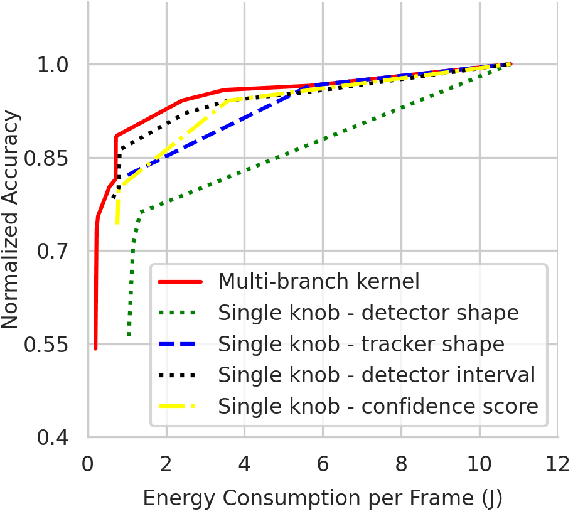
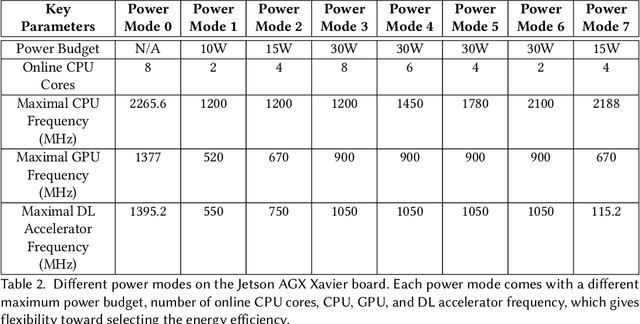
Efficient and adaptive computer vision systems have been proposed to make computer vision tasks, such as image classification and object detection, optimized for embedded or mobile devices. These solutions, quite recent in their origin, focus on optimizing the model (a deep neural network, DNN) or the system by designing an adaptive system with approximation knobs. In spite of several recent efforts, we show that existing solutions suffer from two major drawbacks. First, the system does not consider energy consumption of the models while making a decision on which model to run. Second, the evaluation does not consider the practical scenario of contention on the device, due to other co-resident workloads. In this work, we propose an efficient and adaptive video object detection system, Virtuoso, which is jointly optimized for accuracy, energy efficiency, and latency. Underlying Virtuoso is a multi-branch execution kernel that is capable of running at different operating points in the accuracy-energy-latency axes, and a lightweight runtime scheduler to select the best fit execution branch to satisfy the user requirement. To fairly compare with Virtuoso, we benchmark 15 state-of-the-art or widely used protocols, including Faster R-CNN (FRCNN), YOLO v3, SSD, EfficientDet, SELSA, MEGA, REPP, FastAdapt, and our in-house adaptive variants of FRCNN+, YOLO+, SSD+, and EfficientDet+ (our variants have enhanced efficiency for mobiles). With this comprehensive benchmark, Virtuoso has shown superiority to all the above protocols, leading the accuracy frontier at every efficiency level on NVIDIA Jetson mobile GPUs. Specifically, Virtuoso has achieved an accuracy of 63.9%, which is more than 10% higher than some of the popular object detection models, FRCNN at 51.1%, and YOLO at 49.5%.
Less is More: Generating Grounded Navigation Instructions from Landmarks
Nov 29, 2021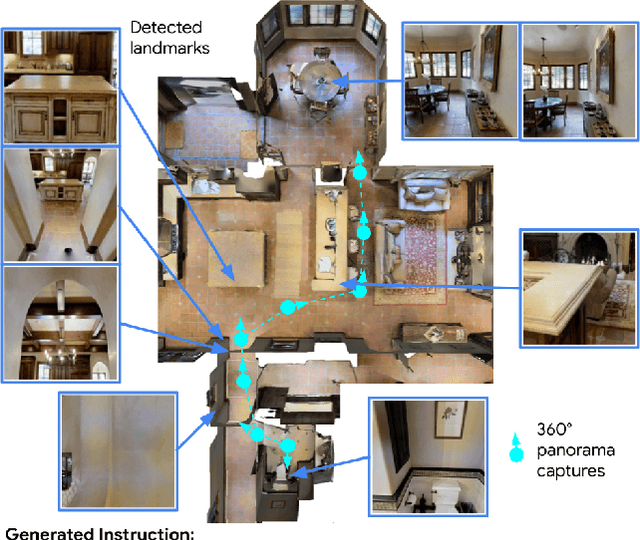
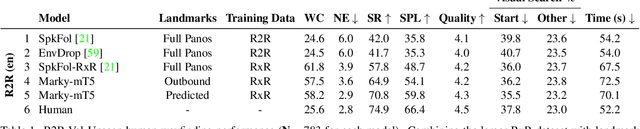


We study the automatic generation of navigation instructions from 360-degree images captured on indoor routes. Existing generators suffer from poor visual grounding, causing them to rely on language priors and hallucinate objects. Our MARKY-MT5 system addresses this by focusing on visual landmarks; it comprises a first stage landmark detector and a second stage generator -- a multimodal, multilingual, multitask encoder-decoder. To train it, we bootstrap grounded landmark annotations on top of the Room-across-Room (RxR) dataset. Using text parsers, weak supervision from RxR's pose traces, and a multilingual image-text encoder trained on 1.8b images, we identify 1.1m English, Hindi and Telugu landmark descriptions and ground them to specific regions in panoramas. On Room-to-Room, human wayfinders obtain success rates (SR) of 71% following MARKY-MT5's instructions, just shy of their 75% SR following human instructions -- and well above SRs with other generators. Evaluations on RxR's longer, diverse paths obtain 61-64% SRs on three languages. Generating such high-quality navigation instructions in novel environments is a step towards conversational navigation tools and could facilitate larger-scale training of instruction-following agents.
Light Lies: Optical Adversarial Attack
Jul 14, 2021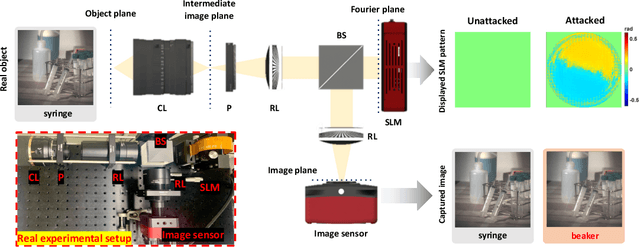

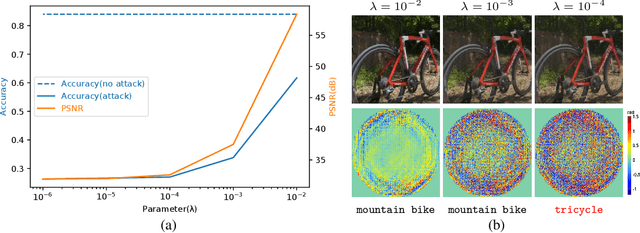
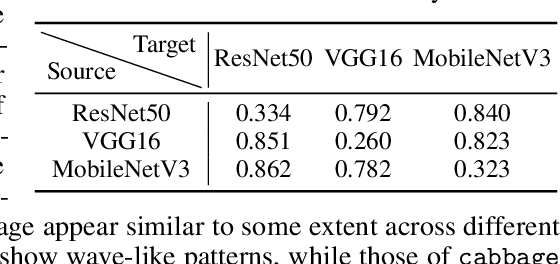
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 23, 2021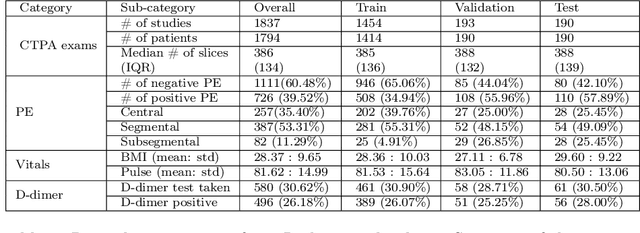
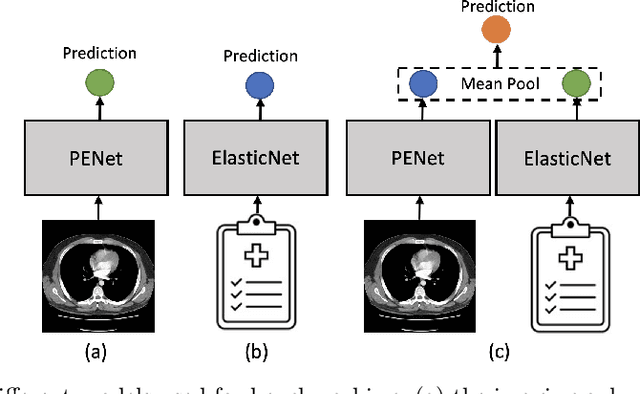
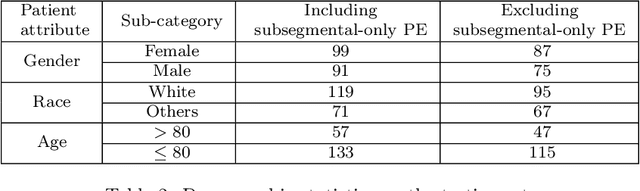
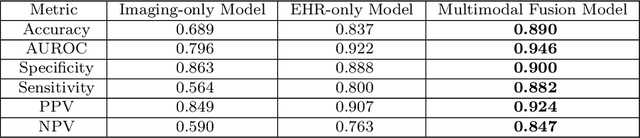
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.
Monte Carlo dropout increases model repeatability
Nov 12, 2021
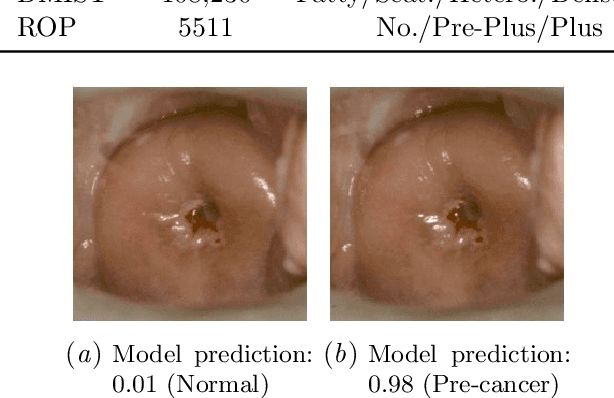
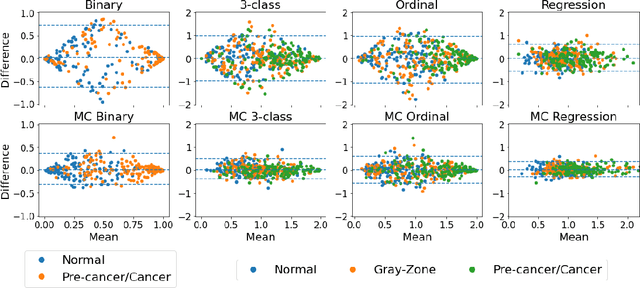
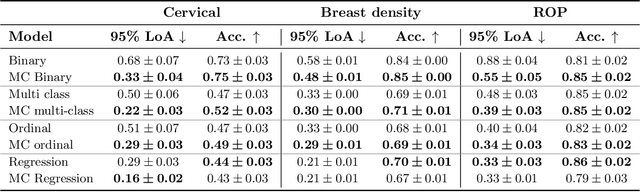
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Among the main features of robustness is repeatability. Much attention is given to classification performance without assessing the model repeatability, leading to the development of models that turn out to be unusable in practice. In this work, we evaluate the repeatability of four model types on images from the same patient that were acquired during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on three medical image analysis tasks: cervical cancer screening, breast density estimation, and retinopathy of prematurity classification. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95% limits of agreement by 17% points.
Certified Patch Robustness via Smoothed Vision Transformers
Oct 11, 2021
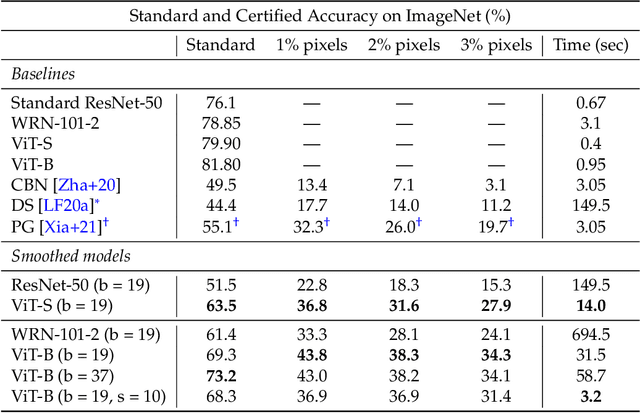
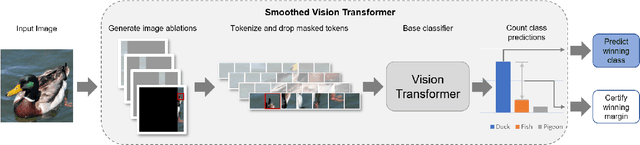
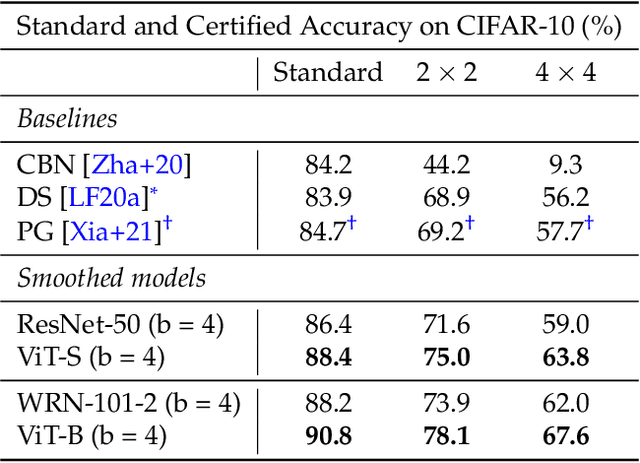
Certified patch defenses can guarantee robustness of an image classifier to arbitrary changes within a bounded contiguous region. But, currently, this robustness comes at a cost of degraded standard accuracies and slower inference times. We demonstrate how using vision transformers enables significantly better certified patch robustness that is also more computationally efficient and does not incur a substantial drop in standard accuracy. These improvements stem from the inherent ability of the vision transformer to gracefully handle largely masked images. Our code is available at https://github.com/MadryLab/smoothed-vit.
Lightweight Single-Image Super-Resolution Network with Attentive Auxiliary Feature Learning
Nov 13, 2020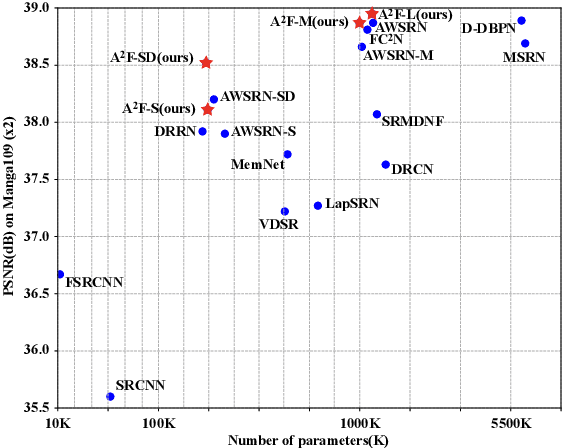
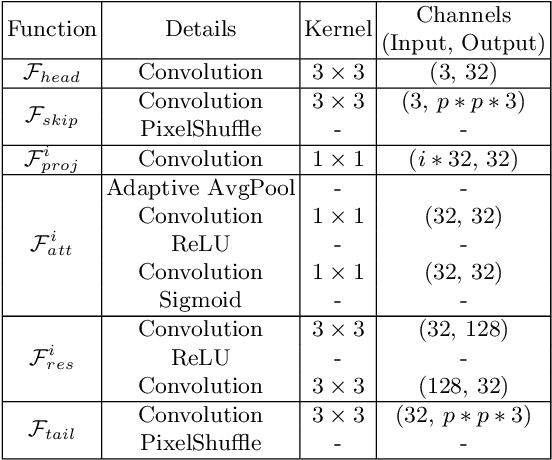
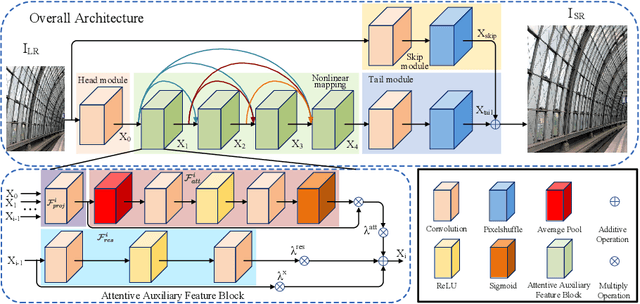
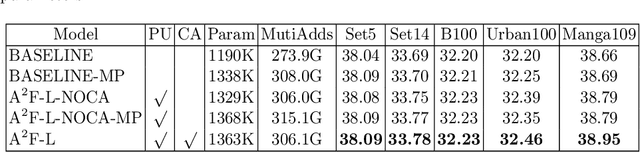
Despite convolutional network-based methods have boosted the performance of single image super-resolution (SISR), the huge computation costs restrict their practical applicability. In this paper, we develop a computation efficient yet accurate network based on the proposed attentive auxiliary features (A$^2$F) for SISR. Firstly, to explore the features from the bottom layers, the auxiliary feature from all the previous layers are projected into a common space. Then, to better utilize these projected auxiliary features and filter the redundant information, the channel attention is employed to select the most important common feature based on current layer feature. We incorporate these two modules into a block and implement it with a lightweight network. Experimental results on large-scale dataset demonstrate the effectiveness of the proposed model against the state-of-the-art (SOTA) SR methods. Notably, when parameters are less than 320k, A$^2$F outperforms SOTA methods for all scales, which proves its ability to better utilize the auxiliary features. Codes are available at https://github.com/wxxxxxxh/A2F-SR.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos
Dec 15, 2021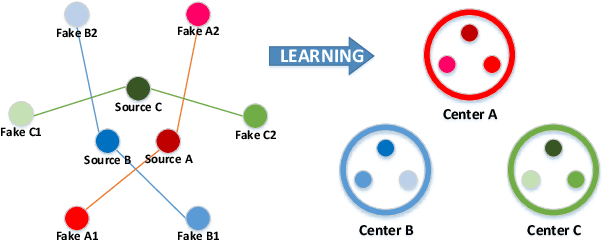
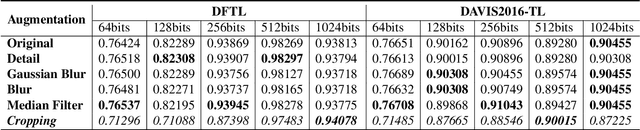
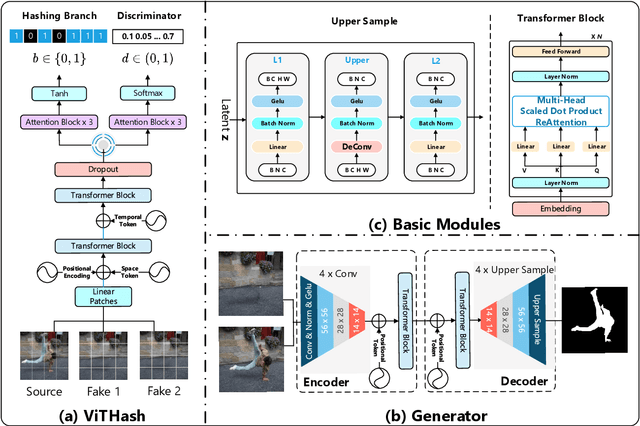

Conventional fake video detection methods outputs a possibility value or a suspected mask of tampering images. However, such unexplainable results cannot be used as convincing evidence. So it is better to trace the sources of fake videos. The traditional hashing methods are used to retrieve semantic-similar images, which can't discriminate the nuances of the image. Specifically, the sources tracing compared with traditional video retrieval. It is a challenge to find the real one from similar source videos. We designed a novel loss Hash Triplet Loss to solve the problem that the videos of people are very similar: the same scene with different angles, similar scenes with the same person. We propose Vision Transformer based models named Video Tracing and Tampering Localization (VTL). In the first stage, we train the hash centers by ViTHash (VTL-T). Then, a fake video is inputted to ViTHash, which outputs a hash code. The hash code is used to retrieve the source video from hash centers. In the second stage, the source video and fake video are inputted to generator (VTL-L). Then, the suspect regions are masked to provide auxiliary information. Moreover, we constructed two datasets: DFTL and DAVIS2016-TL. Experiments on DFTL clearly show the superiority of our framework in sources tracing of similar videos. In particular, the VTL also achieved comparable performance with state-of-the-art methods on DAVIS2016-TL. Our source code and datasets have been released on GitHub: \url{https://github.com/lajlksdf/vtl}.
Cross Domain Image Matching in Presence of Outliers
Sep 08, 2019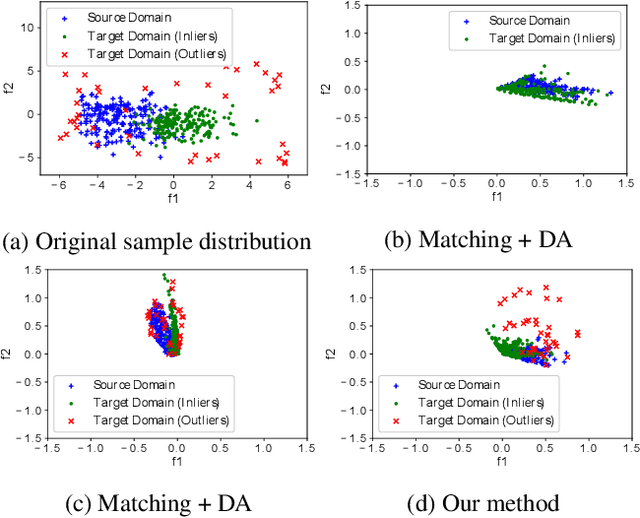

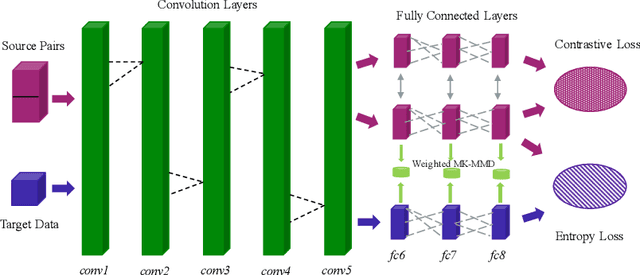

Cross domain image matching between image collections from different source and target domains is challenging in times of deep learning due to i) limited variation of image conditions in a training set, ii) lack of paired-image labels during training, iii) the existing of outliers that makes image matching domains not fully overlap. To this end, we propose an end-to-end architecture that can match cross domain images without labels in the target domain and handle non-overlapping domains by outlier detection. We leverage domain adaptation and triplet constraints for training a network capable of learning domain invariant and identity distinguishable representations, and iteratively detecting the outliers with an entropy loss and our proposed weighted MK-MMD. Extensive experimental evidence on Office [17] dataset and our proposed datasets Shape, Pitts-CycleGAN shows that the proposed approach yields state-of-the-art cross domain image matching and outlier detection performance on different benchmarks. The code will be made publicly available.