 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Single-Image Super-Resolution Network with Attentive Auxiliary Feature Learning
Paper and Code
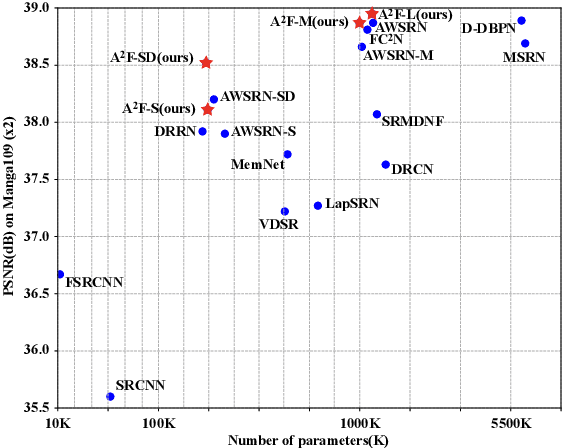
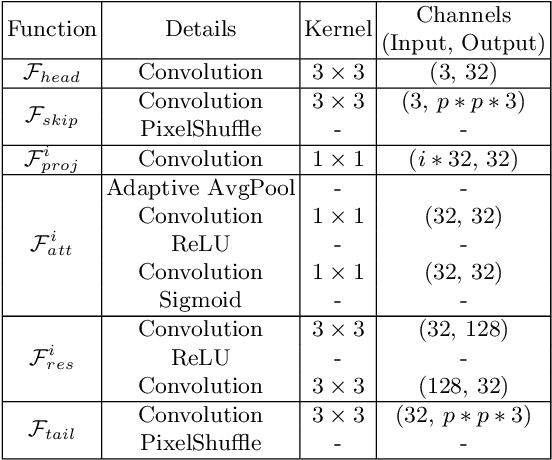
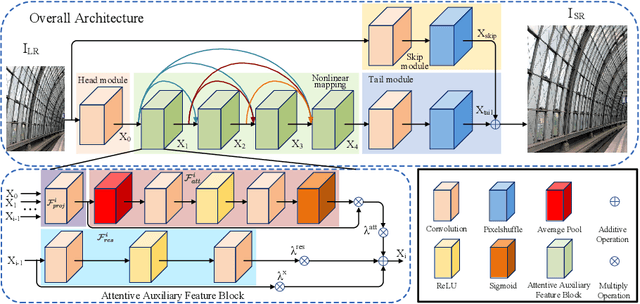
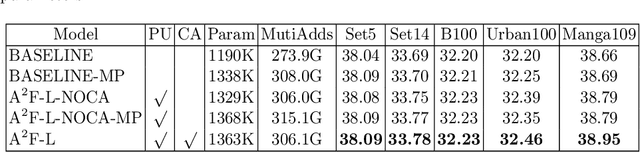
Despite convolutional network-based methods have boosted the performance of single image super-resolution (SISR), the huge computation costs restrict their practical applicability. In this paper, we develop a computation efficient yet accurate network based on the proposed attentive auxiliary features (A$^2$F) for SISR. Firstly, to explore the features from the bottom layers, the auxiliary feature from all the previous layers are projected into a common space. Then, to better utilize these projected auxiliary features and filter the redundant information, the channel attention is employed to select the most important common feature based on current layer feature. We incorporate these two modules into a block and implement it with a lightweight network. Experimental results on large-scale dataset demonstrate the effectiveness of the proposed model against the state-of-the-art (SOTA) SR methods. Notably, when parameters are less than 320k, A$^2$F outperforms SOTA methods for all scales, which proves its ability to better utilize the auxiliary features. Codes are available at https://github.com/wxxxxxxh/A2F-SR.