 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtuoso: Video-based Intelligence for real-time tuning on SOCs
Paper and Code
Dec 24, 2021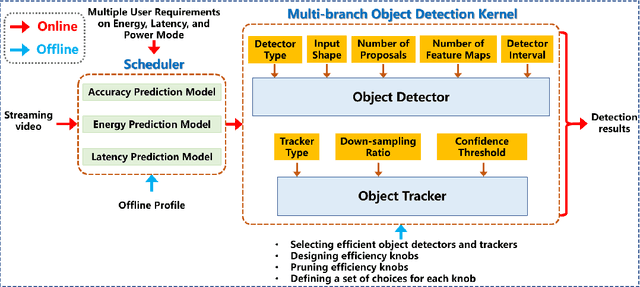
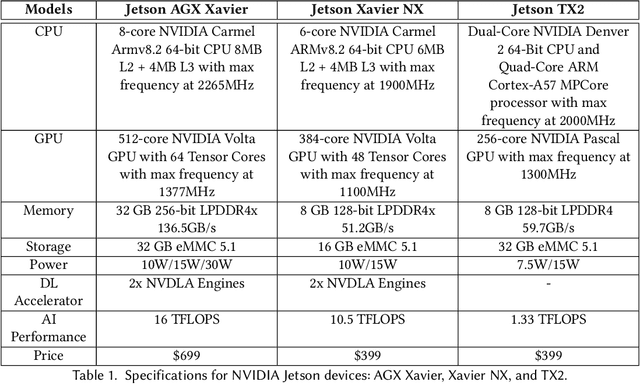
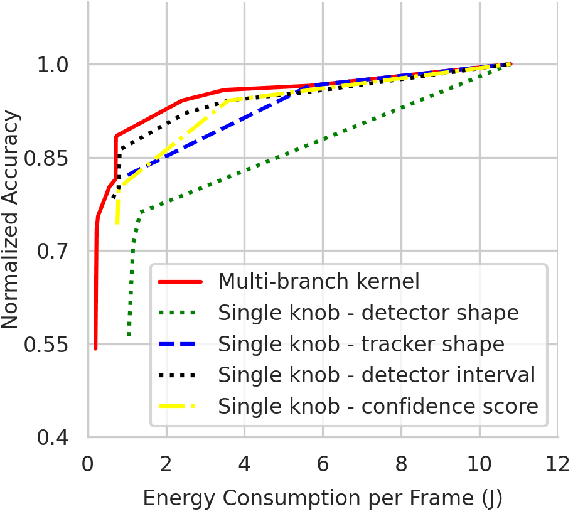
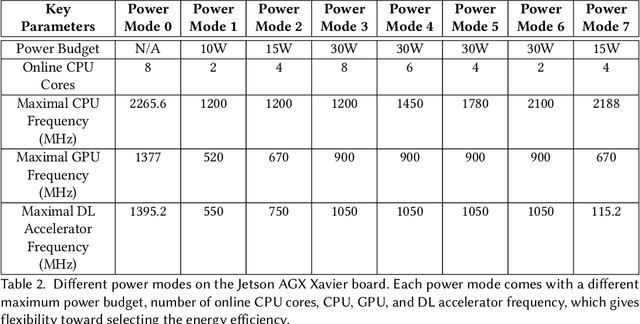
Efficient and adaptive computer vision systems have been proposed to make computer vision tasks, such as image classification and object detection, optimized for embedded or mobile devices. These solutions, quite recent in their origin, focus on optimizing the model (a deep neural network, DNN) or the system by designing an adaptive system with approximation knobs. In spite of several recent efforts, we show that existing solutions suffer from two major drawbacks. First, the system does not consider energy consumption of the models while making a decision on which model to run. Second, the evaluation does not consider the practical scenario of contention on the device, due to other co-resident workloads. In this work, we propose an efficient and adaptive video object detection system, Virtuoso, which is jointly optimized for accuracy, energy efficiency, and latency. Underlying Virtuoso is a multi-branch execution kernel that is capable of running at different operating points in the accuracy-energy-latency axes, and a lightweight runtime scheduler to select the best fit execution branch to satisfy the user requirement. To fairly compare with Virtuoso, we benchmark 15 state-of-the-art or widely used protocols, including Faster R-CNN (FRCNN), YOLO v3, SSD, EfficientDet, SELSA, MEGA, REPP, FastAdapt, and our in-house adaptive variants of FRCNN+, YOLO+, SSD+, and EfficientDet+ (our variants have enhanced efficiency for mobiles). With this comprehensive benchmark, Virtuoso has shown superiority to all the above protocols, leading the accuracy frontier at every efficiency level on NVIDIA Jetson mobile GPUs. Specifically, Virtuoso has achieved an accuracy of 63.9%, which is more than 10% higher than some of the popular object detection models, FRCNN at 51.1%, and YOLO at 49.5%.