 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Dec 06, 2021

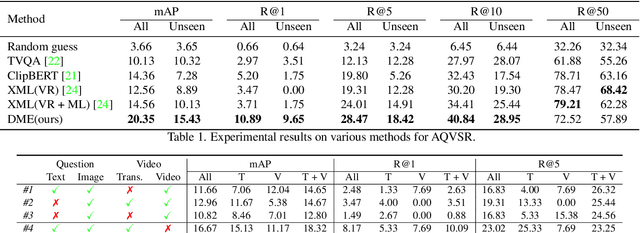
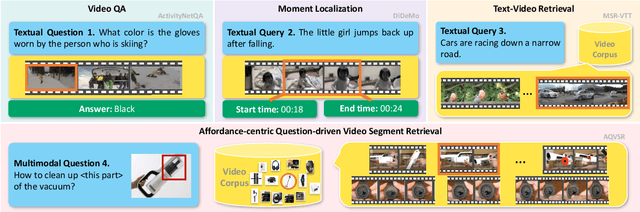
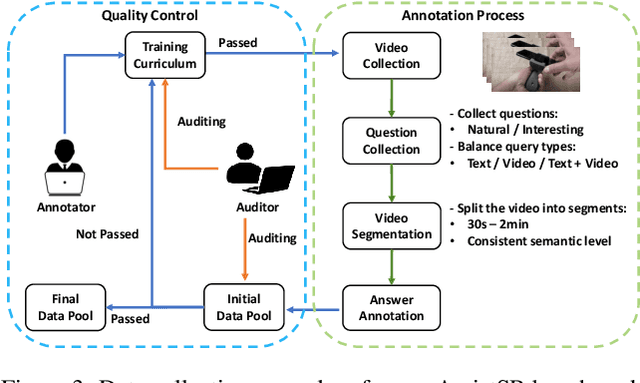
It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.
Few-Shot Hyperspectral Image Classification With Unknown Classes Using Multitask Deep Learning
Sep 08, 2020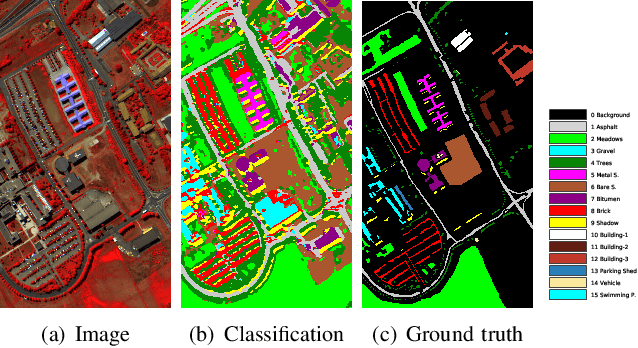
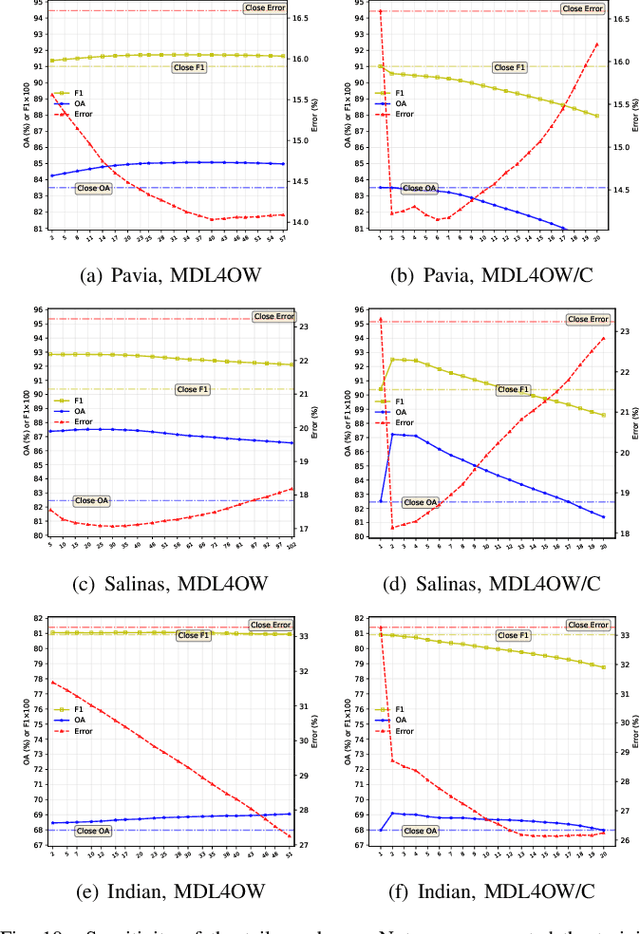
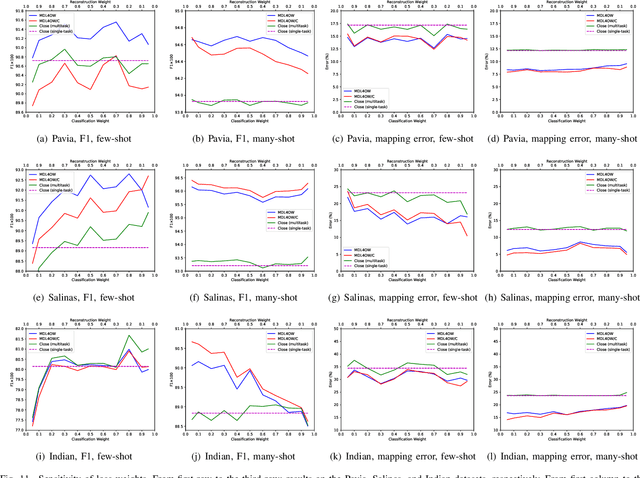
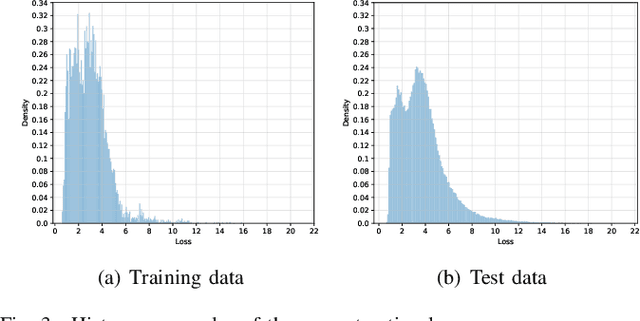
Current hyperspectral image classification assumes that a predefined classification system is closed and complete, and there are no unknown or novel classes in the unseen data. However, this assumption may be too strict for the real world. Often, novel classes are overlooked when the classification system is constructed. The closed nature forces a model to assign a label given a new sample and may lead to overestimation of known land covers (e.g., crop area). To tackle this issue, we propose a multitask deep learning method that simultaneously conducts classification and reconstruction in the open world (named MDL4OW) where unknown classes may exist. The reconstructed data are compared with the original data; those failing to be reconstructed are considered unknown, based on the assumption that they are not well represented in the latent features due to the lack of labels. A threshold needs to be defined to separate the unknown and known classes; we propose two strategies based on the extreme value theory for few-shot and many-shot scenarios. The proposed method was tested on real-world hyperspectral images; state-of-the-art results were achieved, e.g., improving the overall accuracy by 4.94% for the Salinas data. By considering the existence of unknown classes in the open world, our method achieved more accurate hyperspectral image classification, especially under the few-shot context.
TTPLA: An Aerial-Image Dataset for Detection and Segmentation of Transmission Towers and Power Lines
Oct 20, 2020
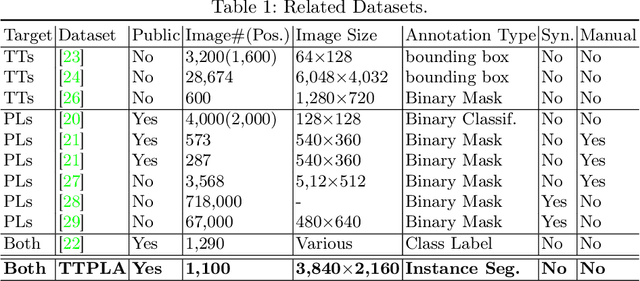

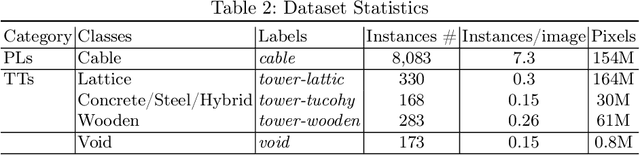
Accurate detection and segmentation of transmission towers~(TTs) and power lines~(PLs) from aerial images plays a key role in protecting power-grid security and low-altitude UAV safety. Meanwhile, aerial images of TTs and PLs pose a number of new challenges to the computer vision researchers who work on object detection and segmentation -- PLs are long and thin, and may show similar color as the background; TTs can be of various shapes and most likely made up of line structures of various sparsity; The background scene, lighting, and object sizes can vary significantly from one image to another. In this paper we collect and release a new TT/PL Aerial-image (TTPLA) dataset, consisting of 1,100 images with the resolution of 3,840$\times$2,160 pixels, as well as manually labeled 8,987 instances of TTs and PLs. We develop novel policies for collecting, annotating, and labeling the images in TTPLA. Different from other relevant datasets, TTPLA supports evaluation of instance segmentation, besides detection and semantic segmentation. To build a baseline for detection and segmentation tasks on TTPLA, we report the performance of several state-of-the-art deep learning models on our dataset. TTPLA dataset is publicly available at https://github.com/r3ab/ttpla_dataset
Image Disentanglement and Uncooperative Re-Entanglement for High-Fidelity Image-to-Image Translation
Jan 11, 2019
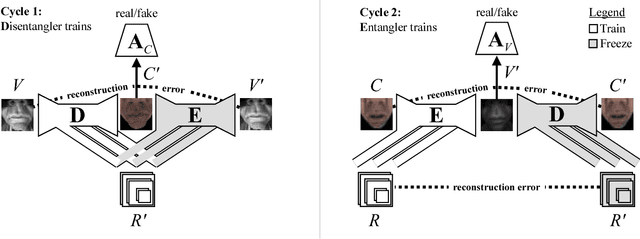
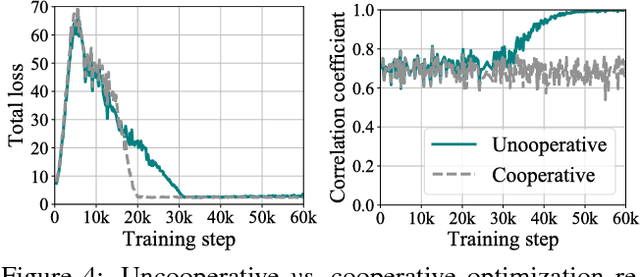
Cross-domain image-to-image translation should satisfy two requirements: (1) preserve the information that is common to both domains, and (2) generate convincing images covering variations that appear in the target domain. This is challenging, especially when there are no example translations available as supervision. Adversarial cycle consistency was recently proposed as a solution, with beautiful and creative results, yielding much follow-up work. However, augmented reality applications cannot readily use such techniques to provide users with compelling translations of real scenes, because the translations do not have high-fidelity constraints. In other words, current models are liable to change details that should be preserved: while re-texturing a face, they may alter the face's expression in an unpredictable way. In this paper, we introduce the problem of high-fidelity image-to-image translation, and present a method for solving it. Our main insight is that low-fidelity translations typically escape a cycle-consistency penalty, because the back-translator learns to compensate for the forward-translator's errors. We therefore introduce an optimization technique that prevents the networks from cooperating: simply train each network only when its input data is real. Prior works, in comparison, train each network with a mix of real and generated data. Experimental results show that our method accurately disentangles the factors that separate the domains, and converges to semantics-preserving translations that prior methods miss.
Turning Your Strength against You: Detecting and Mitigating Robust and Universal Adversarial Patch Attack
Aug 11, 2021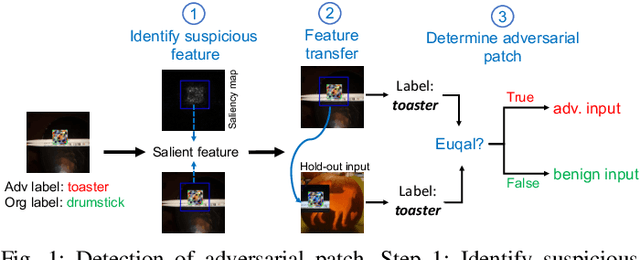
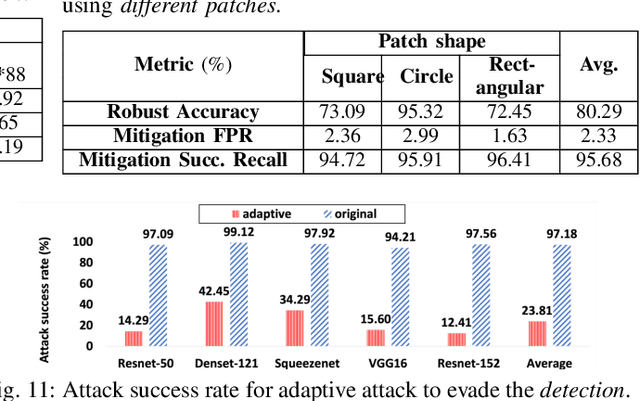
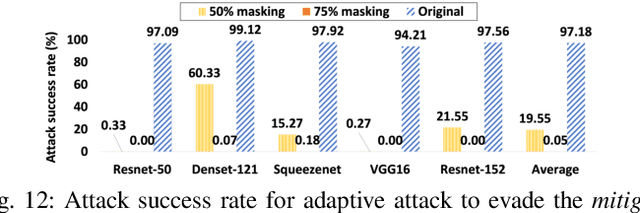

Adversarial patch attack against image classification deep neural networks (DNNs), in which the attacker can inject arbitrary distortions within a bounded region of an image, is able to generate adversarial perturbations that are robust (i.e., remain adversarial in physical world) and universal (i.e., remain adversarial on any input). It is thus important to detect and mitigate such attack to ensure the security of DNNs. This work proposes Jujutsu, a technique to detect and mitigate robust and universal adversarial patch attack. Jujutsu leverages the universal property of the patch attack for detection. It uses explainable AI technique to identify suspicious features that are potentially malicious, and verify their maliciousness by transplanting the suspicious features to new images. An adversarial patch continues to exhibit the malicious behavior on the new images and thus can be detected based on prediction consistency. Jujutsu leverages the localized nature of the patch attack for mitigation, by randomly masking the suspicious features to "remove" adversarial perturbations. However, the network might fail to classify the images as some of the contents are removed (masked). Therefore, Jujutsu uses image inpainting for synthesizing alternative contents from the pixels that are masked, which can reconstruct the "clean" image for correct prediction. We evaluate Jujutsu on five DNNs on two datasets, and show that Jujutsu achieves superior performance and significantly outperforms existing techniques. Jujutsu can further defend against various variants of the basic attack, including 1) physical-world attack; 2) attacks that target diverse classes; 3) attacks that use patches in different shapes and 4) adaptive attacks.
MonoPLFlowNet: Permutohedral Lattice FlowNet for Real-Scale 3D Scene FlowEstimation with Monocular Images
Nov 24, 2021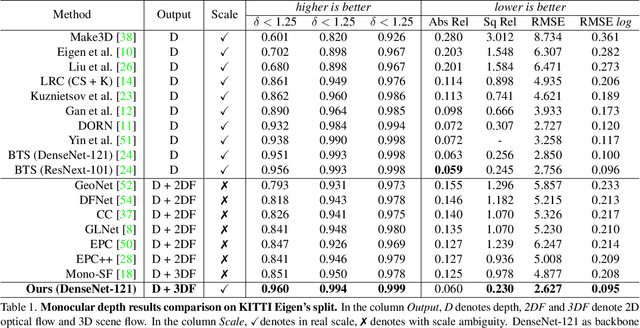
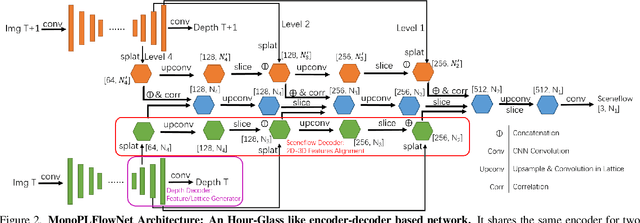


Real-scale scene flow estimation has become increasingly important for 3D computer vision. Some works successfully estimate real-scale 3D scene flow with LiDAR. However, these ubiquitous and expensive sensors are still unlikely to be equipped widely for real application. Other works use monocular images to estimate scene flow, but their scene flow estimations are normalized with scale ambiguity, where additional depth or point cloud ground truth are required to recover the real scale. Even though they perform well in 2D, these works do not provide accurate and reliable 3D estimates. We present a deep learning architecture on permutohedral lattice - MonoPLFlowNet. Different from all previous works, our MonoPLFlowNet is the first work where only two consecutive monocular images are used as input, while both depth and 3D scene flow are estimated in real scale. Our real-scale scene flow estimation outperforms all state-of-the-art monocular-image based works recovered to real scale by ground truth, and is comparable to LiDAR approaches. As a by-product, our real-scale depth estimation also outperforms other state-of-the-art works.
Learnable Triangulation for Deep Learning-based 3D Reconstruction of Objects of Arbitrary Topology from Single RGB Images
Sep 24, 2021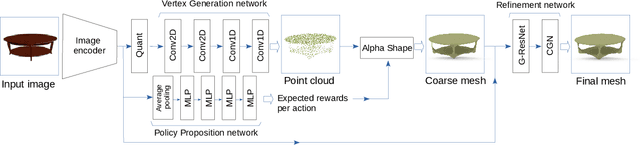
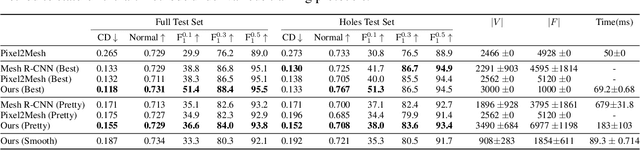
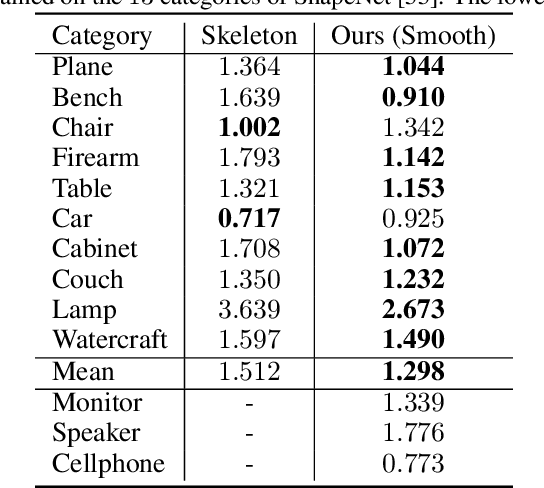
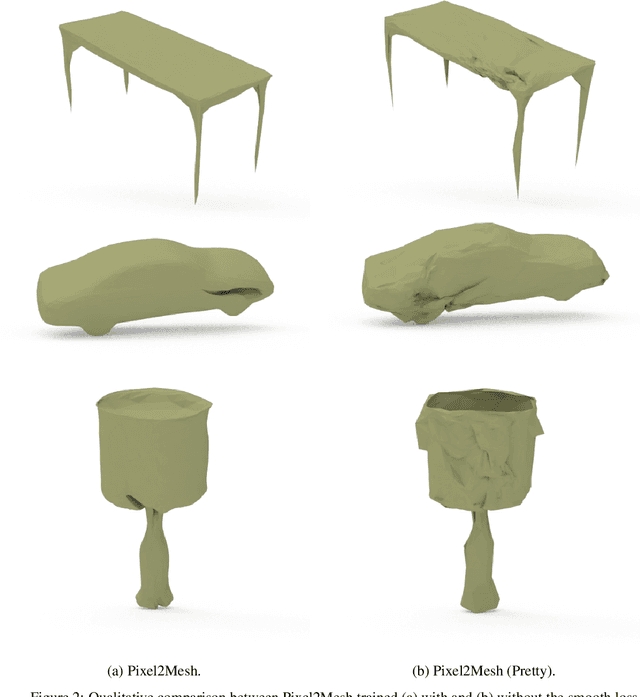
We propose a novel deep reinforcement learning-based approach for 3D object reconstruction from monocular images. Prior works that use mesh representations are template based. Thus, they are limited to the reconstruction of objects that have the same topology as the template. Methods that use volumetric grids as intermediate representations are computationally expensive, which limits their application in real-time scenarios. In this paper, we propose a novel end-to-end method that reconstructs 3D objects of arbitrary topology from a monocular image. It is composed of of (1) a Vertex Generation Network (VGN), which predicts the initial 3D locations of the object's vertices from an input RGB image, (2) a differentiable triangulation layer, which learns in a non-supervised manner, using a novel reinforcement learning algorithm, the best triangulation of the object's vertices, and finally, (3) a hierarchical mesh refinement network that uses graph convolutions to refine the initial mesh. Our key contribution is the learnable triangulation process, which recovers in an unsupervised manner the topology of the input shape. Our experiments on ShapeNet and Pix3D benchmarks show that the proposed method outperforms the state-of-the-art in terms of visual quality, reconstruction accuracy, and computational time.
Boosting Few-Shot Classification with View-Learnable Contrastive Learning
Jul 30, 2021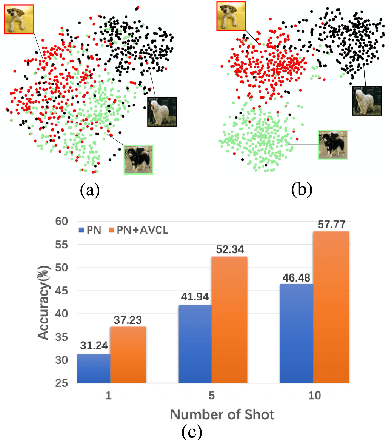
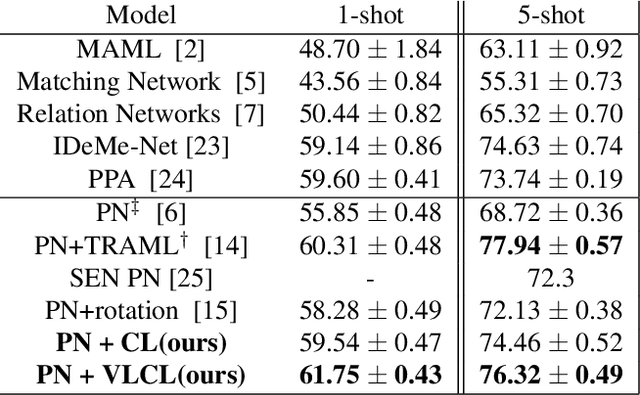
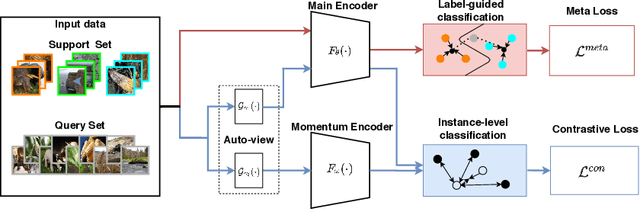
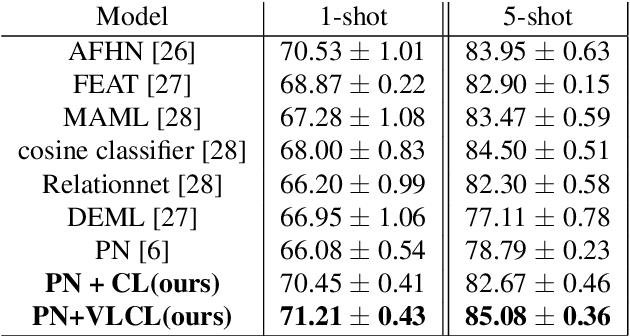
The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
Efficient Neural Radiance Fields with Learned Depth-Guided Sampling
Dec 06, 2021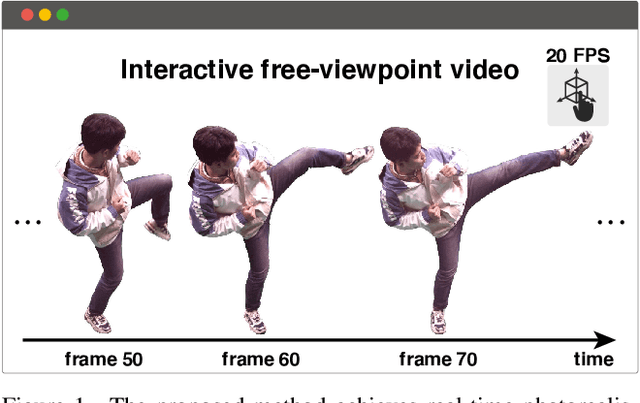
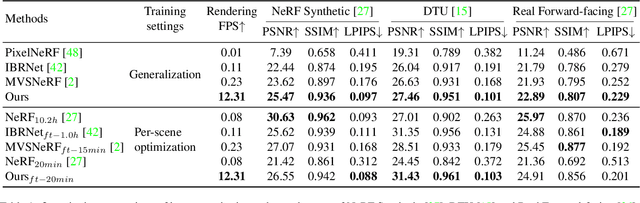
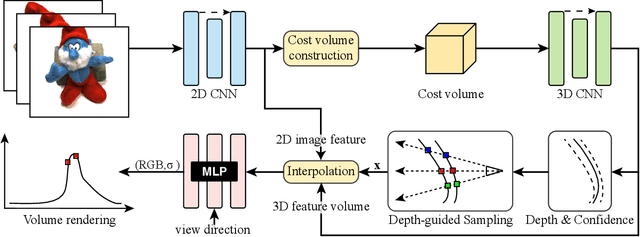
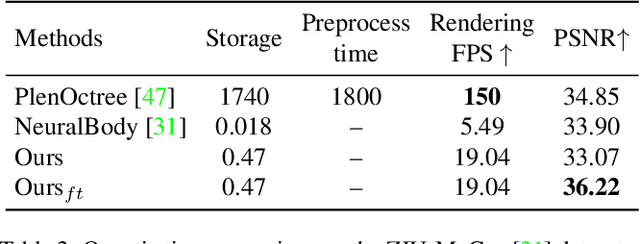
This paper aims to reduce the rendering time of generalizable radiance fields. Some recent works equip neural radiance fields with image encoders and are able to generalize across scenes, which avoids the per-scene optimization. However, their rendering process is generally very slow. A major factor is that they sample lots of points in empty space when inferring radiance fields. In this paper, we present a hybrid scene representation which combines the best of implicit radiance fields and explicit depth maps for efficient rendering. Specifically, we first build the cascade cost volume to efficiently predict the coarse geometry of the scene. The coarse geometry allows us to sample few points near the scene surface and significantly improves the rendering speed. This process is fully differentiable, enabling us to jointly learn the depth prediction and radiance field networks from only RGB images. Experiments show that the proposed approach exhibits state-of-the-art performance on the DTU, Real Forward-facing and NeRF Synthetic datasets, while being at least 50 times faster than previous generalizable radiance field methods. We also demonstrate the capability of our method to synthesize free-viewpoint videos of dynamic human performers in real-time. The code will be available at https://zju3dv.github.io/enerf/.
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
Sep 24, 2021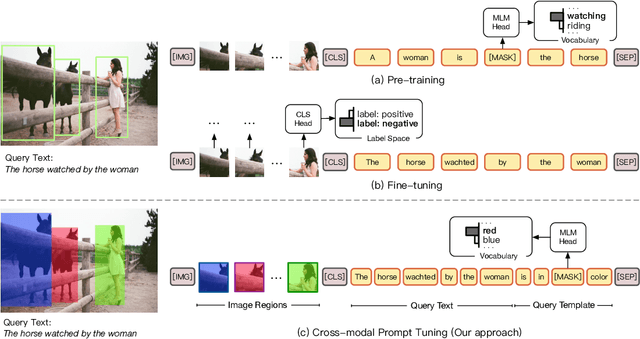
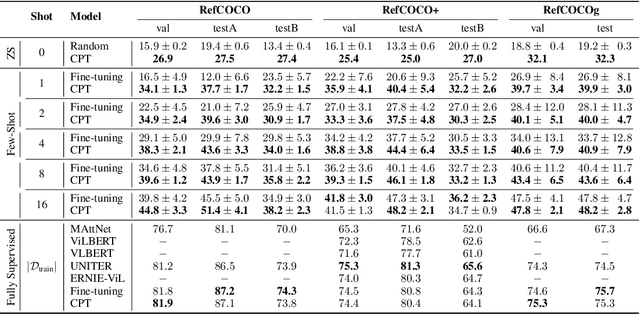
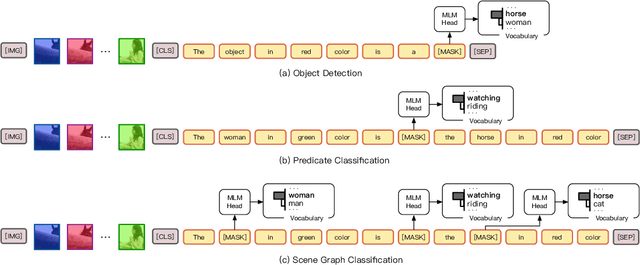
Pre-Trained Vision-Language Models (VL-PTMs) have shown promising capabilities in grounding natural language in image data, facilitating a broad variety of cross-modal tasks. However, we note that there exists a significant gap between the objective forms of model pre-training and fine-tuning, resulting in a need for quantities of labeled data to stimulate the visual grounding capability of VL-PTMs for downstream tasks. To address the challenge, we present Cross-modal Prompt Tuning (CPT, alternatively, Colorful Prompt Tuning), a novel paradigm for tuning VL-PTMs, which reformulates visual grounding into a fill-in-the-blank problem with color-based co-referential markers in image and text, maximally mitigating the gap. In this way, our prompt tuning approach enables strong few-shot and even zero-shot visual grounding capabilities of VL-PTMs. Comprehensive experimental results show that prompt tuned VL-PTMs outperform their fine-tuned counterparts by a large margin (e.g., 17.3% absolute accuracy improvement, and 73.8% relative standard deviation reduction on average with one shot in RefCOCO evaluation). All the data and code will be available to facilitate future research.