 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LiftReg: Limited Angle 2D/3D Deformable Registration
Mar 10, 2022
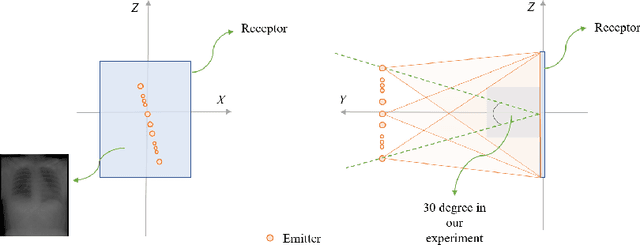

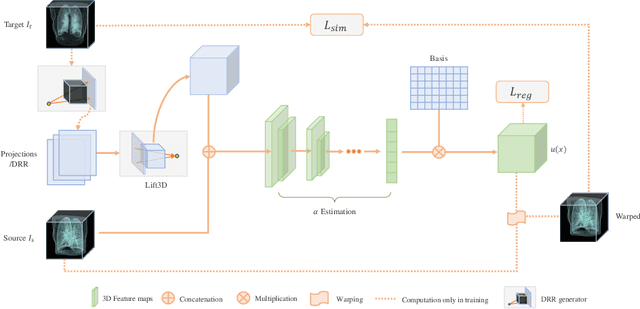
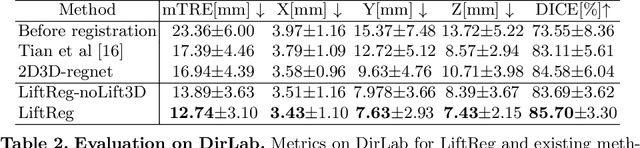
We propose LiftReg, a 2D/3D deformable registration approach. LiftReg is a deep registration framework which is trained using sets of digitally reconstructed radiographs (DRR) and computed tomography (CT) image pairs. By using simulated training data, LiftReg can use a high-quality CT-CT image similarity measure, which helps the network to learn a high-quality deformation space. To further improve registration quality and to address the inherent depth ambiguities of very limited angle acquisitions, we propose to use features extracted from the backprojected 2D images and a statistical deformation model. We test our approach on the DirLab lung registration dataset and show that it outperforms an existing learning-based pairwise registration approach.
Deep Self-Adaptive Hashing for Image Retrieval
Aug 16, 2021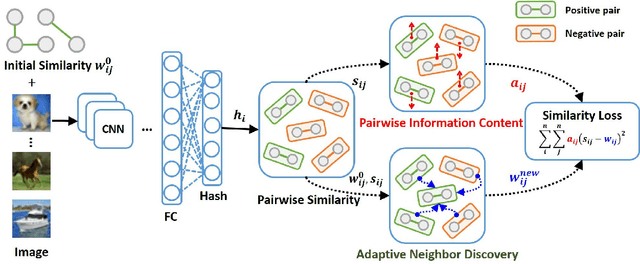
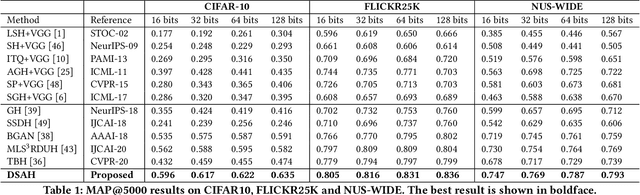
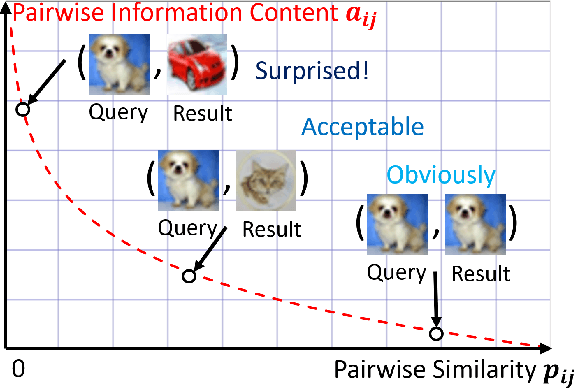
Hashing technology has been widely used in image retrieval due to its computational and storage efficiency. Recently, deep unsupervised hashing methods have attracted increasing attention due to the high cost of human annotations in the real world and the superiority of deep learning technology. However, most deep unsupervised hashing methods usually pre-compute a similarity matrix to model the pairwise relationship in the pre-trained feature space. Then this similarity matrix would be used to guide hash learning, in which most of the data pairs are treated equivalently. The above process is confronted with the following defects: 1) The pre-computed similarity matrix is inalterable and disconnected from the hash learning process, which cannot explore the underlying semantic information. 2) The informative data pairs may be buried by the large number of less-informative data pairs. To solve the aforementioned problems, we propose a \textbf{Deep Self-Adaptive Hashing~(DSAH)} model to adaptively capture the semantic information with two special designs: \textbf{Adaptive Neighbor Discovery~(AND)} and \textbf{Pairwise Information Content~(PIC)}. Firstly, we adopt the AND to initially construct a neighborhood-based similarity matrix, and then refine this initial similarity matrix with a novel update strategy to further investigate the semantic structure behind the learned representation. Secondly, we measure the priorities of data pairs with PIC and assign adaptive weights to them, which is relies on the assumption that more dissimilar data pairs contain more discriminative information for hash learning. Extensive experiments on several benchmark datasets demonstrate that the above two technologies facilitate the deep hashing model to achieve superior performance in a self-adaptive manner.
Super Vision Transformer
May 23, 2022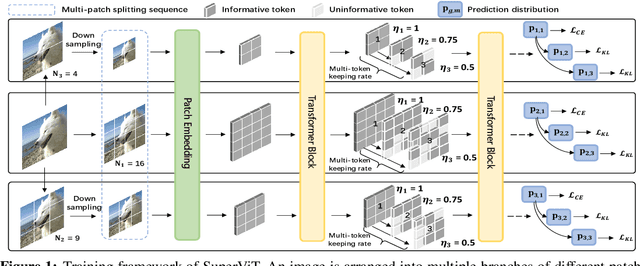
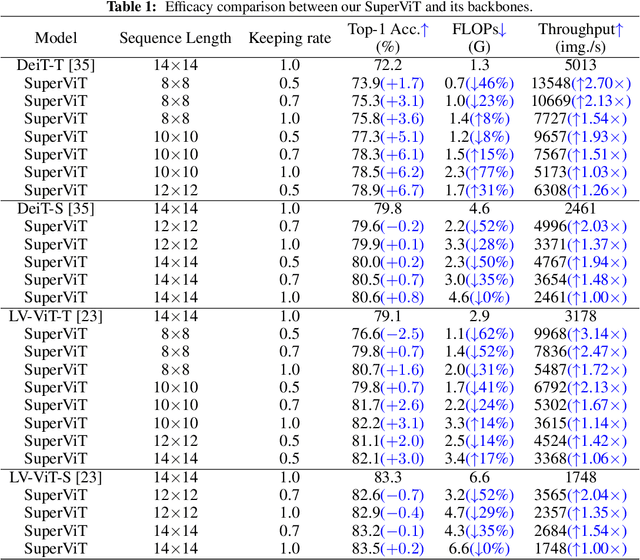
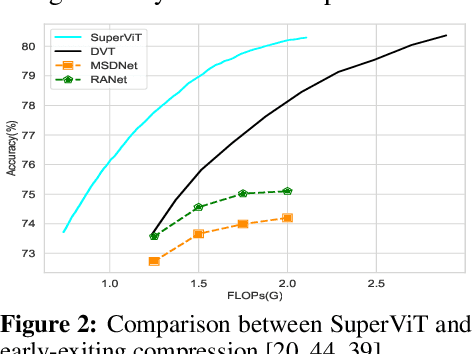
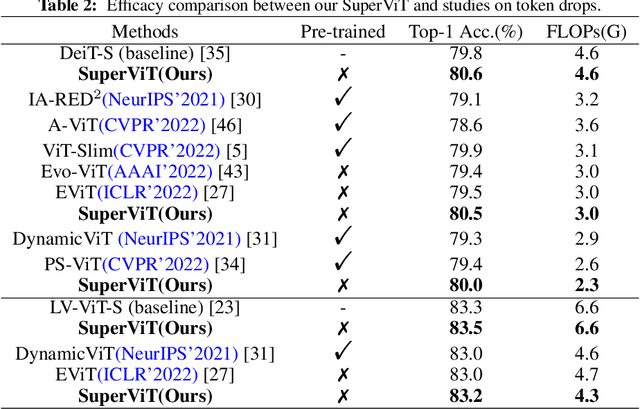
We attempt to reduce the computational costs in vision transformers (ViTs), which increase quadratically in the token number. We present a novel training paradigm that trains only one ViT model at a time, but is capable of providing improved image recognition performance with various computational costs. Here, the trained ViT model, termed super vision transformer (SuperViT), is empowered with the versatile ability to solve incoming patches of multiple sizes as well as preserve informative tokens with multiple keeping rates (the ratio of keeping tokens) to achieve good hardware efficiency for inference, given that the available hardware resources often change from time to time. Experimental results on ImageNet demonstrate that our SuperViT can considerably reduce the computational costs of ViT models with even performance increase. For example, we reduce 2x FLOPs of DeiT-S while increasing the Top-1 accuracy by 0.2% and 0.7% for 1.5x reduction. Also, our SuperViT significantly outperforms existing studies on efficient vision transformers. For example, when consuming the same amount of FLOPs, our SuperViT surpasses the recent state-of-the-art (SoTA) EViT by 1.1% when using DeiT-S as their backbones. The project of this work is made publicly available at https://github.com/lmbxmu/SuperViT.
TRT-ViT: TensorRT-oriented Vision Transformer
May 23, 2022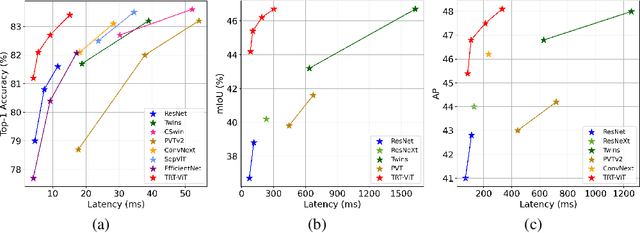
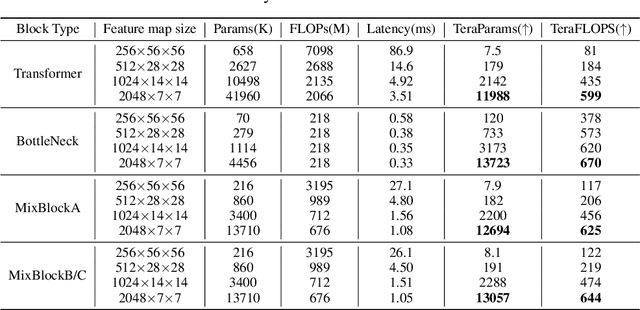
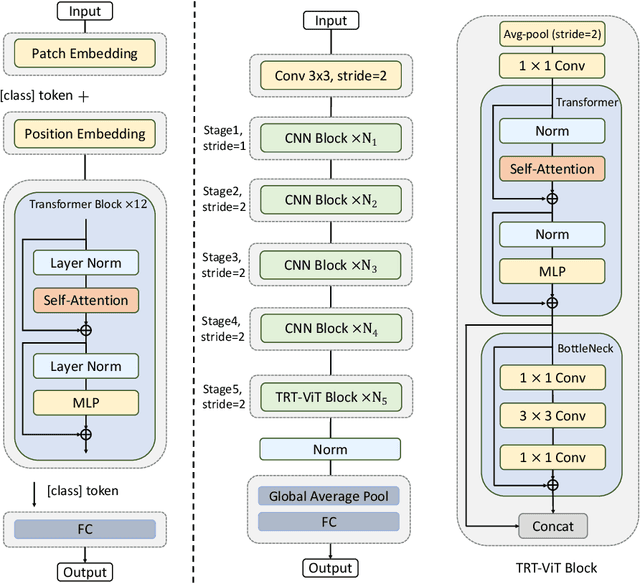
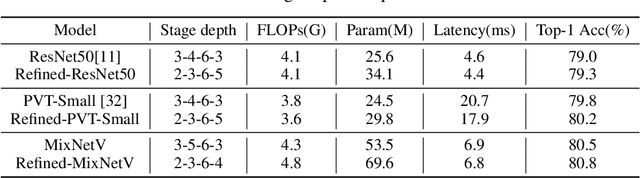
We revisit the existing excellent Transformers from the perspective of practical application. Most of them are not even as efficient as the basic ResNets series and deviate from the realistic deployment scenario. It may be due to the current criterion to measure computation efficiency, such as FLOPs or parameters is one-sided, sub-optimal, and hardware-insensitive. Thus, this paper directly treats the TensorRT latency on the specific hardware as an efficiency metric, which provides more comprehensive feedback involving computational capacity, memory cost, and bandwidth. Based on a series of controlled experiments, this work derives four practical guidelines for TensorRT-oriented and deployment-friendly network design, e.g., early CNN and late Transformer at stage-level, early Transformer and late CNN at block-level. Accordingly, a family of TensortRT-oriented Transformers is presented, abbreviated as TRT-ViT. Extensive experiments demonstrate that TRT-ViT significantly outperforms existing ConvNets and vision Transformers with respect to the latency/accuracy trade-off across diverse visual tasks, e.g., image classification, object detection and semantic segmentation. For example, at 82.7% ImageNet-1k top-1 accuracy, TRT-ViT is 2.7$\times$ faster than CSWin and 2.0$\times$ faster than Twins. On the MS-COCO object detection task, TRT-ViT achieves comparable performance with Twins, while the inference speed is increased by 2.8$\times$.
A trainable monogenic ConvNet layer robust in front of large contrast changes in image classification
Sep 14, 2021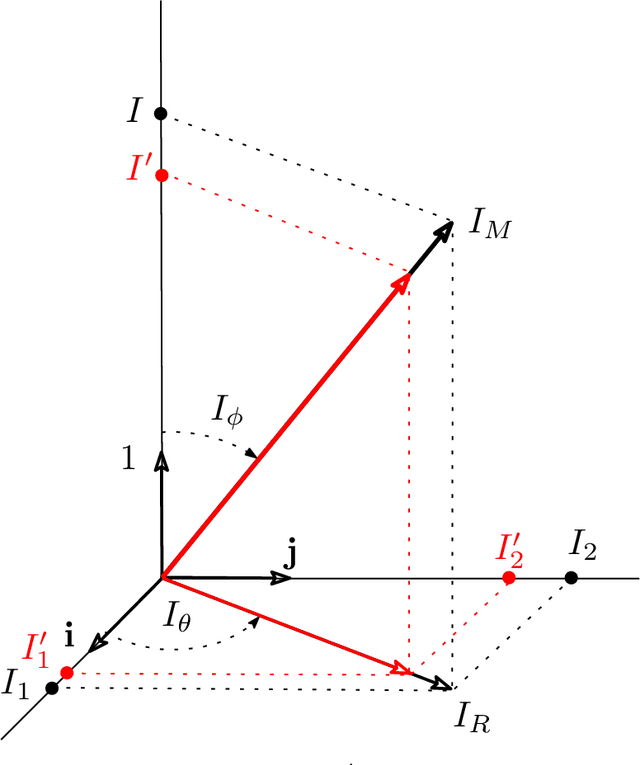
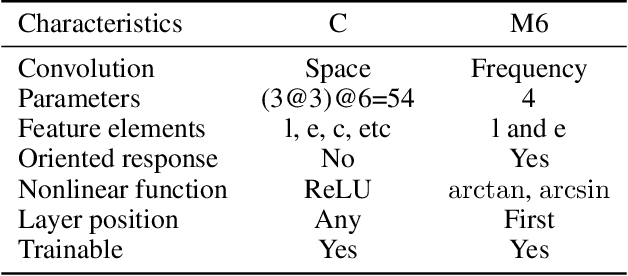

Convolutional Neural Networks (ConvNets) at present achieve remarkable performance in image classification tasks. However, current ConvNets cannot guarantee the capabilities of the mammalian visual systems such as invariance to contrast and illumination changes. Some ideas to overcome the illumination and contrast variations usually have to be tuned manually and tend to fail when tested with other types of data degradation. In this context, we present a new bio-inspired {entry} layer, M6, which detects low-level geometric features (lines, edges, and orientations) which are similar to patterns detected by the V1 visual cortex. This new trainable layer is capable of coping with image classification even with large contrast variations. The explanation for this behavior is the monogenic signal geometry, which represents each pixel value in a 3D space using quaternions, a fact that confers a degree of explainability to the networks. We compare M6 with a conventional convolutional layer (C) and a deterministic quaternion local phase layer (Q9). The experimental setup {is designed to evaluate the robustness} of our M6 enriched ConvNet model and includes three architectures, four datasets, three types of contrast degradation (including non-uniform haze degradations). The numerical results reveal that the models with M6 are the most robust in front of any kind of contrast variations. This amounts to a significant enhancement of the C models, which usually have reasonably good performance only when the same training and test degradation are used, except for the case of maximum degradation. Moreover, the Structural Similarity Index Measure (SSIM) is used to analyze and explain the robustness effect of the M6 feature maps under any kind of contrast degradations.
One-Sided Box Filter for Edge Preserving Image Smoothing
Aug 11, 2021
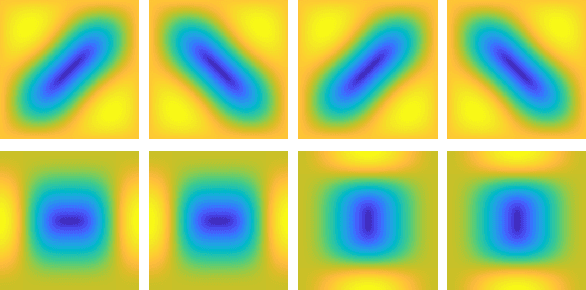
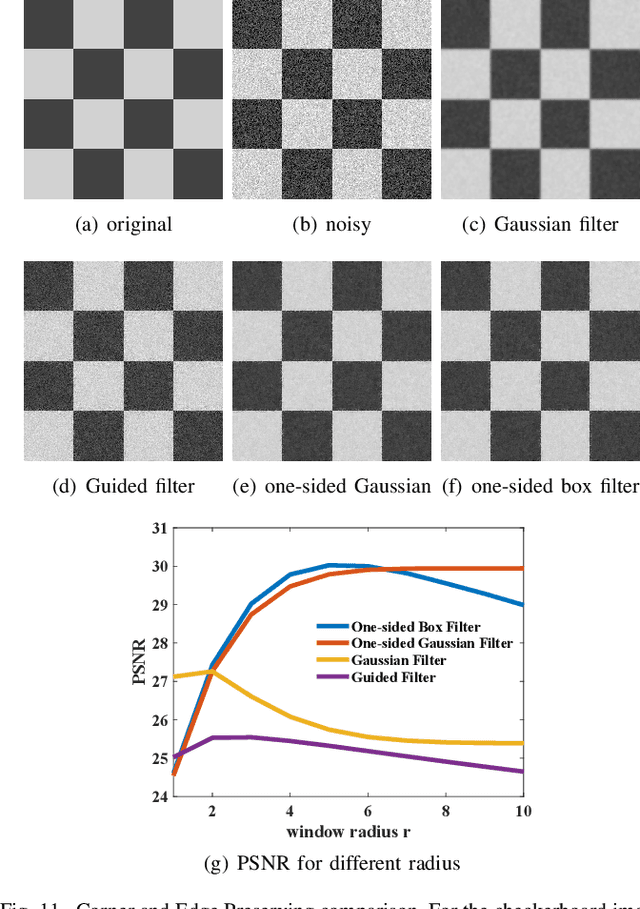
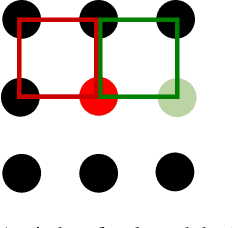
Image smoothing is a fundamental task in signal processing. For such task, box filter is well-known. However, box filter can not keep some features of the signal, such as edges, corners and the jump in the step function. In this paper, we present a one-sided box filter that can smooth the signal but keep the discontinuous features in the signal. More specifically, we perform box filter on eight one-sided windows, leading to a one-sided box filter that can preserve corners and edges. Our filter inherits the constant $O(1)$ computational complexity of the original box filter with respect to the window size and also the linear $O(N)$ computational complexity with respect to the total number of samples. We performance several experiments to show the efficiency and effectiveness of this filter. We further compare our filter with other the-state-of-the-art edge preserving methods. Our filter can be deployed in a large range of applications where the classical box filter is adopted.
ViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Mar 14, 2022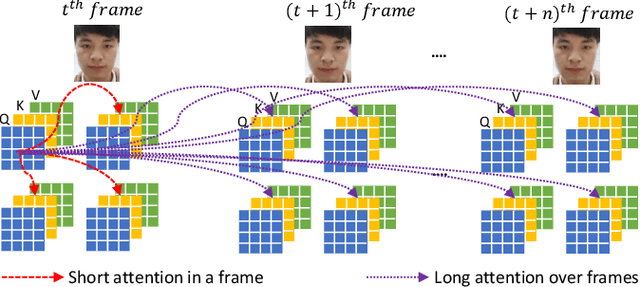
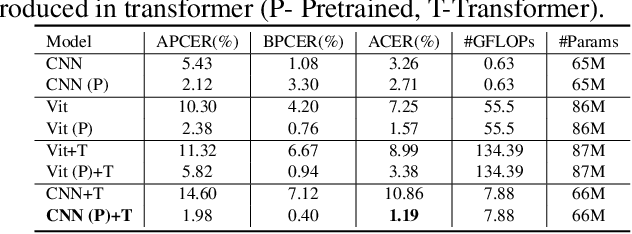
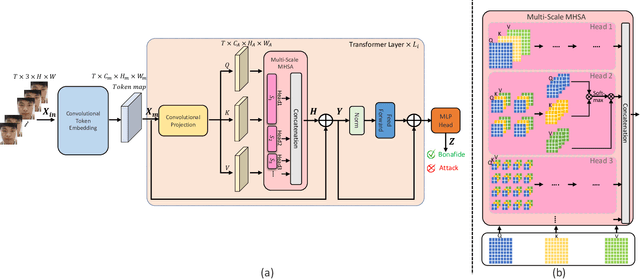
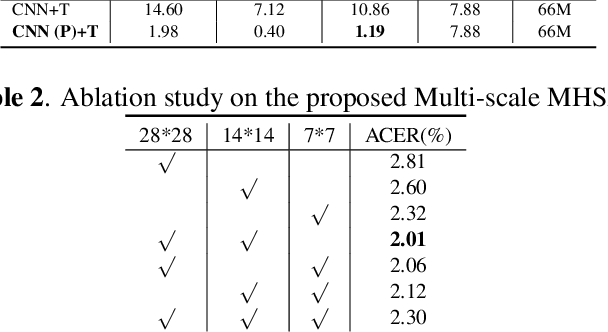
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.
CoDo: Contrastive Learning with Downstream Background Invariance for Detection
May 10, 2022
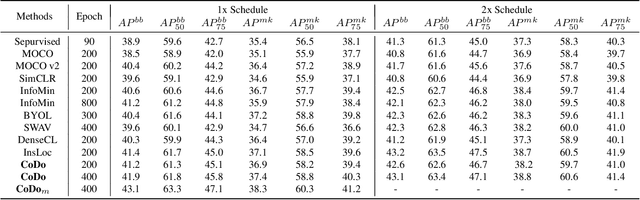
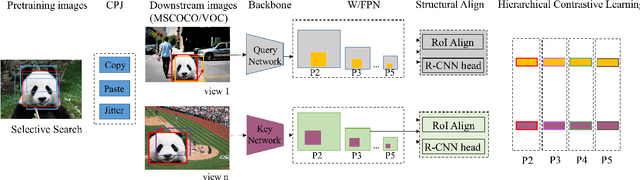

The prior self-supervised learning researches mainly select image-level instance discrimination as pretext task. It achieves a fantastic classification performance that is comparable to supervised learning methods. However, with degraded transfer performance on downstream tasks such as object detection. To bridge the performance gap, we propose a novel object-level self-supervised learning method, called Contrastive learning with Downstream background invariance (CoDo). The pretext task is converted to focus on instance location modeling for various backgrounds, especially for downstream datasets. The ability of background invariance is considered vital for object detection. Firstly, a data augmentation strategy is proposed to paste the instances onto background images, and then jitter the bounding box to involve background information. Secondly, we implement architecture alignment between our pretraining network and the mainstream detection pipelines. Thirdly, hierarchical and multi views contrastive learning is designed to improve performance of visual representation learning. Experiments on MSCOCO demonstrate that the proposed CoDo with common backbones, ResNet50-FPN, yields strong transfer learning results for object detection.
RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Apr 08, 2021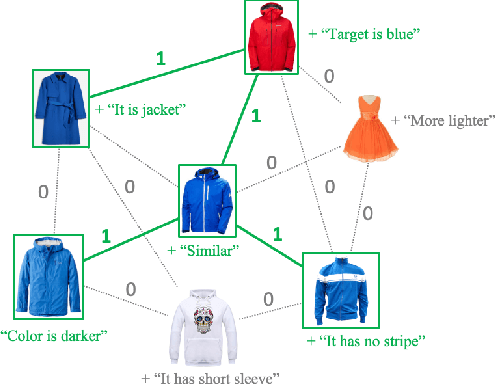
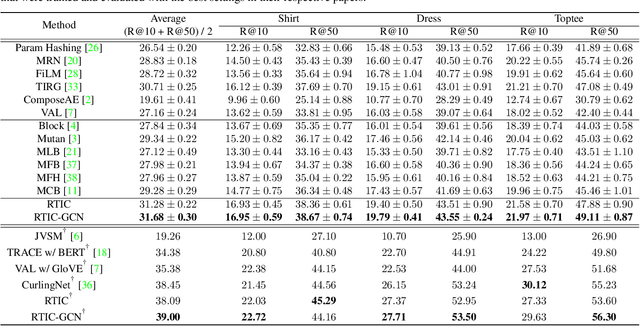
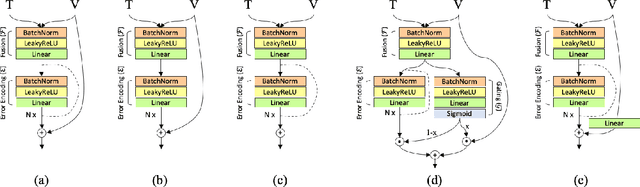
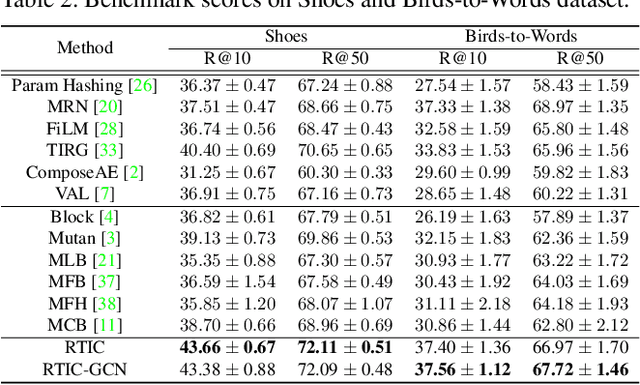
In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022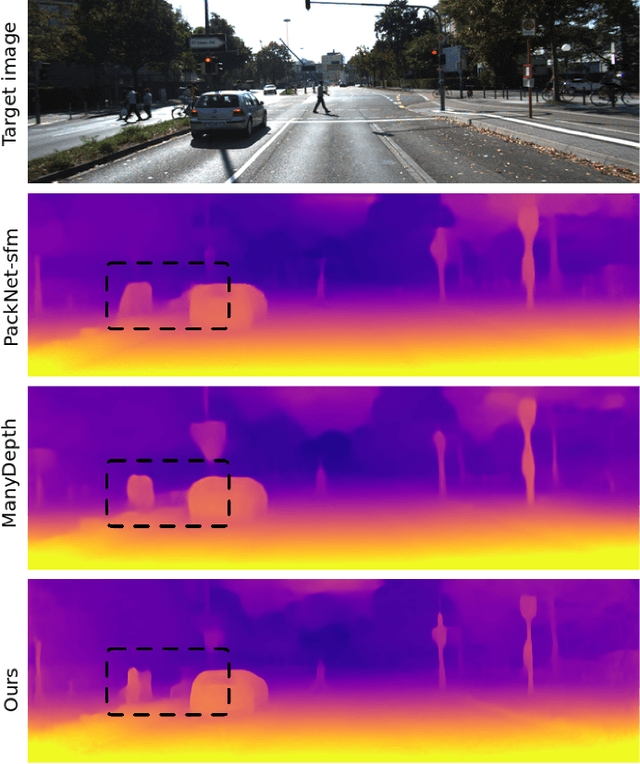
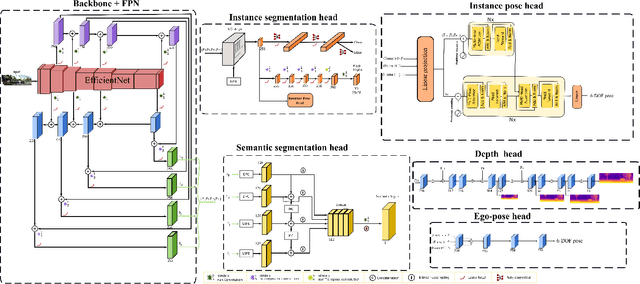
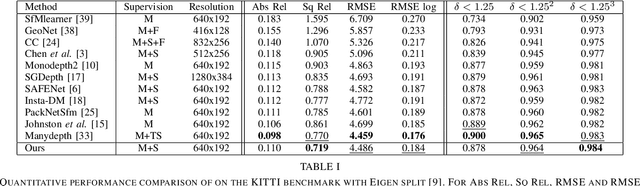
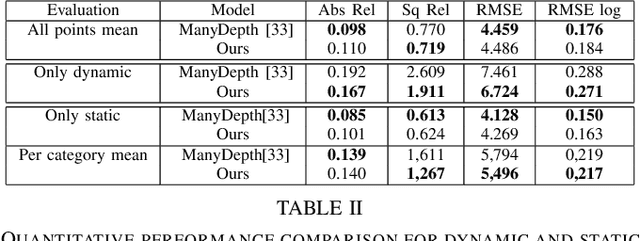
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.