 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphericalDreamer: Generating Navigable Immersive 3D Worlds with Panorama Fusion
May 19, 2026The generation of immersive and navigable 3D environments is increasingly prevalent with the growing adoption of virtual reality and 3D content. However, recent methods face a fundamental limitation: they cannot produce 3D worlds that simultaneously (i) are navigable over long-range spatial extents and (ii) cover the complete omnidirectional field of view ($360^\circ$ horizontally and $180^\circ$ vertically). To address this challenge, we introduce SphericalDreamer, a method for generating fully immersive and long-range 3D outdoor environments from textual prompts. Our approach is built on the generation of multiple panoramic images, which are subsequently lifted into 3D and fused together while maintaining visual and geometric consistency. SphericalDreamer produces highly detailed, fully immersive 3D environments, while substantially improving scale and navigability compared to prior approaches.
Scaled Inverse Graphics: Efficiently Learning Large Sets of 3D Scenes
Oct 31, 2024While the field of inverse graphics has been witnessing continuous growth, techniques devised thus far predominantly focus on learning individual scene representations. In contrast, learning large sets of scenes has been a considerable bottleneck in NeRF developments, as repeatedly applying inverse graphics on a sequence of scenes, though essential for various applications, remains largely prohibitive in terms of resource costs. We introduce a framework termed "scaled inverse graphics", aimed at efficiently learning large sets of scene representations, and propose a novel method to this end. It operates in two stages: (i) training a compression model on a subset of scenes, then (ii) training NeRF models on the resulting smaller representations, thereby reducing the optimization space per new scene. In practice, we compact the representation of scenes by learning NeRFs in a latent space to reduce the image resolution, and sharing information across scenes to reduce NeRF representation complexity. We experimentally show that our method presents both the lowest training time and memory footprint in scaled inverse graphics compared to other methods applied independently on each scene. Our codebase is publicly available as open-source. Our project page can be found at https://scaled-ig.github.io .
Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Oct 30, 2024



While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024



We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023



Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
STDepthFormer: Predicting Spatio-temporal Depth from Video with a Self-supervised Transformer Model
Mar 02, 2023In this paper, a self-supervised model that simultaneously predicts a sequence of future frames from video-input with a novel spatial-temporal attention (ST) network is proposed. The ST transformer network allows constraining both temporal consistency across future frames whilst constraining consistency across spatial objects in the image at different scales. This was not the case in prior works for depth prediction, which focused on predicting a single frame as output. The proposed model leverages prior scene knowledge such as object shape and texture similar to single-image depth inference methods, whilst also constraining the motion and geometry from a sequence of input images. Apart from the transformer architecture, one of the main contributions with respect to prior works lies in the objective function that enforces spatio-temporal consistency across a sequence of output frames rather than a single output frame. As will be shown, this results in more accurate and robust depth sequence forecasting. The model achieves highly accurate depth forecasting results that outperform existing baselines on the KITTI benchmark. Extensive ablation studies were performed to assess the effectiveness of the proposed techniques. One remarkable result of the proposed model is that it is implicitly capable of forecasting the motion of objects in the scene, rather than requiring complex models involving multi-object detection, segmentation and tracking.
Forecasting of depth and ego-motion with transformers and self-supervision
Jun 15, 2022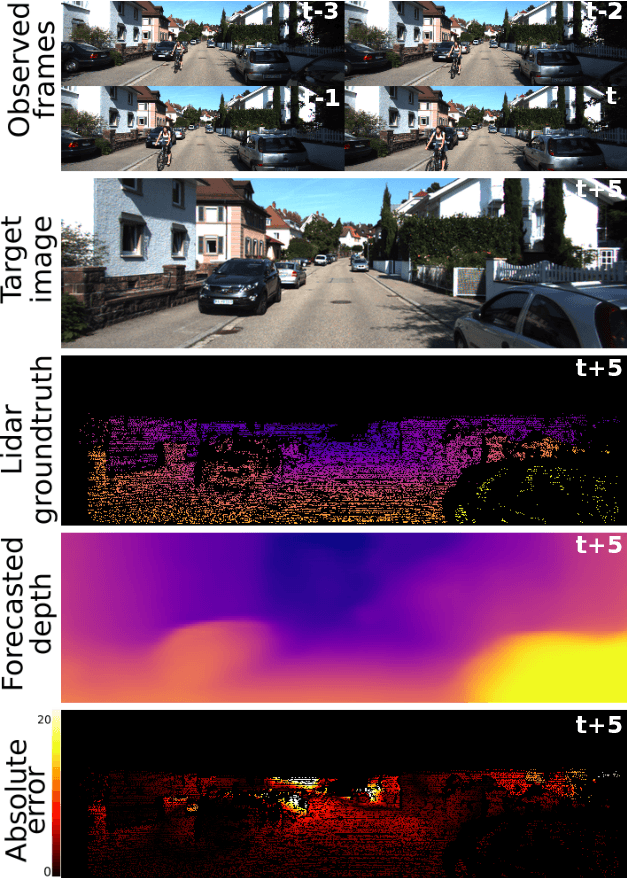
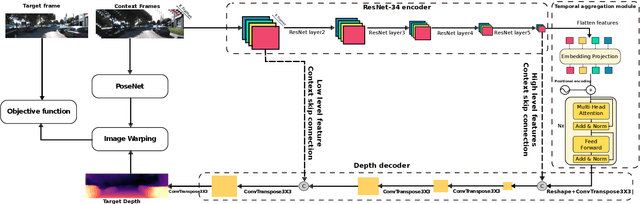
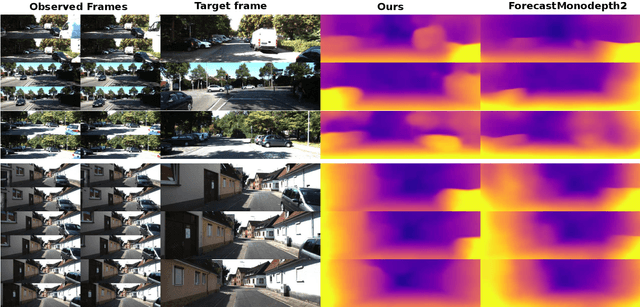
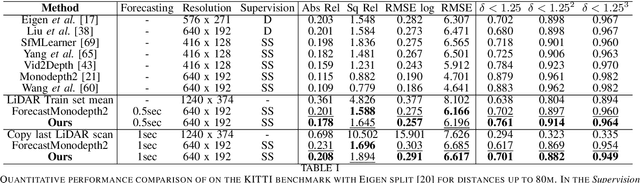
This paper addresses the problem of end-to-end self-supervised forecasting of depth and ego motion. Given a sequence of raw images, the aim is to forecast both the geometry and ego-motion using a self supervised photometric loss. The architecture is designed using both convolution and transformer modules. This leverages the benefits of both modules: Inductive bias of CNN, and the multi-head attention of transformers, thus enabling a rich spatio-temporal representation that enables accurate depth forecasting. Prior work attempts to solve this problem using multi-modal input/output with supervised ground-truth data which is not practical since a large annotated dataset is required. Alternatively to prior methods, this paper forecasts depth and ego motion using only self-supervised raw images as input. The approach performs significantly well on the KITTI dataset benchmark with several performance criteria being even comparable to prior non-forecasting self-supervised monocular depth inference methods.
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022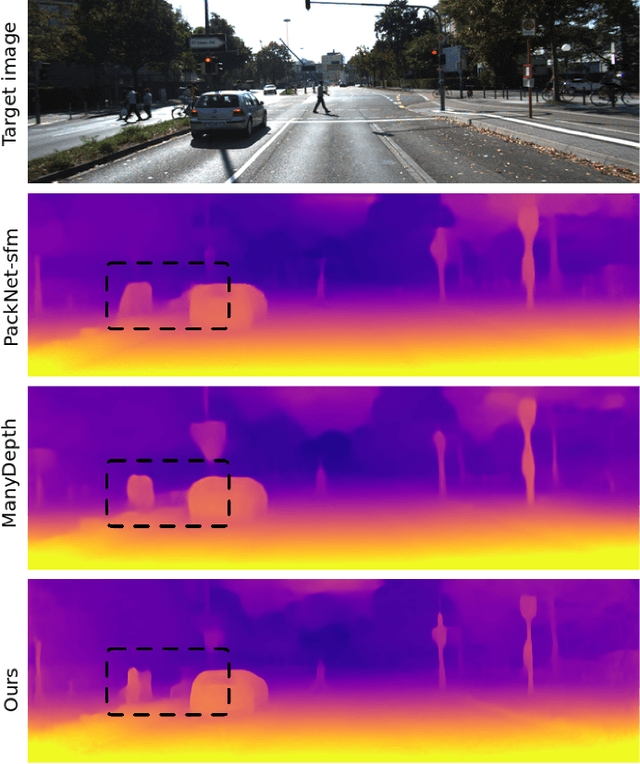
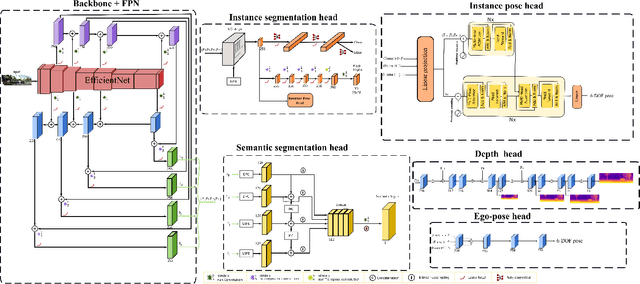
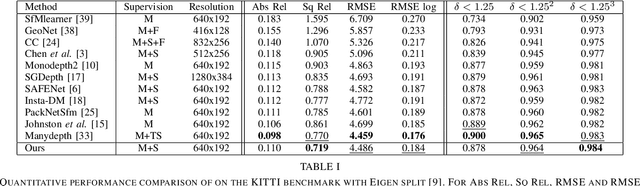
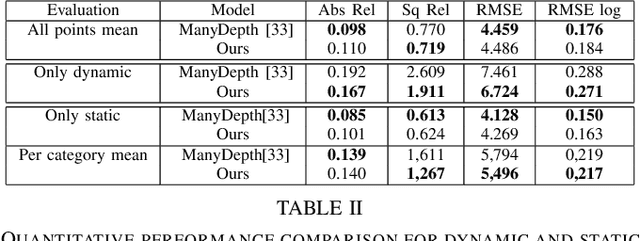
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.
Are conditional GANs explicitly conditional?
Jun 28, 2021
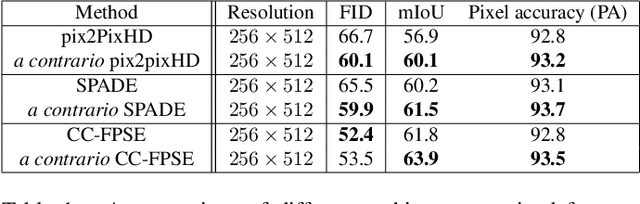
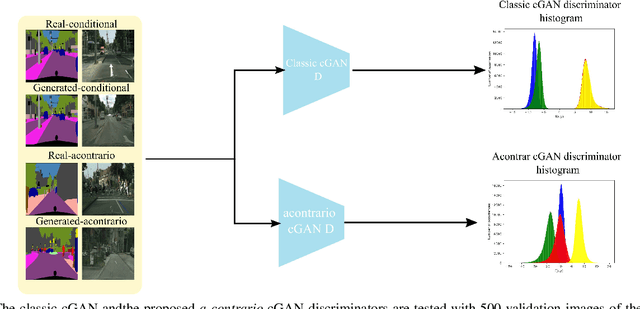

This paper proposes two important contributions for conditional Generative Adversarial Networks (cGANs) to improve the wide variety of applications that exploit this architecture. The first main contribution is an analysis of cGANs to show that they are not explicitly conditional. In particular, it will be shown that the discriminator and subsequently the cGAN does not automatically learn the conditionality between inputs. The second contribution is a new method, called acontrario, that explicitly models conditionality for both parts of the adversarial architecture via a novel acontrario loss that involves training the discriminator to learn unconditional (adverse) examples. This leads to a novel type of data augmentation approach for GANs (acontrario learning) which allows to restrict the search space of the generator to conditional outputs using adverse examples. Extensive experimentation is carried out to evaluate the conditionality of the discriminator by proposing a probability distribution analysis. Comparisons with the cGAN architecture for different applications show significant improvements in performance on well known datasets including, semantic image synthesis, image segmentation and monocular depth prediction using different metrics including Fr\'echet Inception Distance(FID), mean Intersection over Union (mIoU), Root Mean Square Error log (RMSE log) and Number of statistically-Different Bins (NDB)