 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Validation of a Responsible Artificial Intelligence-based System for the Referral of Diabetic Retinopathy Patients
Aug 17, 2025Diabetic Retinopathy (DR) is a leading cause of vision loss in working-age individuals. Early detection of DR can reduce the risk of vision loss by up to 95%, but a shortage of retinologists and challenges in timely examination complicate detection. Artificial Intelligence (AI) models using retinal fundus photographs (RFPs) offer a promising solution. However, adoption in clinical settings is hindered by low-quality data and biases that may lead AI systems to learn unintended features. To address these challenges, we developed RAIS-DR, a Responsible AI System for DR screening that incorporates ethical principles across the AI lifecycle. RAIS-DR integrates efficient convolutional models for preprocessing, quality assessment, and three specialized DR classification models. We evaluated RAIS-DR against the FDA-approved EyeArt system on a local dataset of 1,046 patients, unseen by both systems. RAIS-DR demonstrated significant improvements, with F1 scores increasing by 5-12%, accuracy by 6-19%, and specificity by 10-20%. Additionally, fairness metrics such as Disparate Impact and Equal Opportunity Difference indicated equitable performance across demographic subgroups, underscoring RAIS-DR's potential to reduce healthcare disparities. These results highlight RAIS-DR as a robust and ethically aligned solution for DR screening in clinical settings. The code, weights of RAIS-DR are available at https://gitlab.com/inteligencia-gubernamental-jalisco/jalisco-retinopathy with RAIL.
Explaining Autonomous Vehicles with Intention-aware Policy Graphs
May 13, 2025



The potential to improve road safety, reduce human driving error, and promote environmental sustainability have enabled the field of autonomous driving to progress rapidly over recent decades. The performance of autonomous vehicles has significantly improved thanks to advancements in Artificial Intelligence, particularly Deep Learning. Nevertheless, the opacity of their decision-making, rooted in the use of accurate yet complex AI models, has created barriers to their societal trust and regulatory acceptance, raising the need for explainability. We propose a post-hoc, model-agnostic solution to provide teleological explanations for the behaviour of an autonomous vehicle in urban environments. Building on Intention-aware Policy Graphs, our approach enables the extraction of interpretable and reliable explanations of vehicle behaviour in the nuScenes dataset from global and local perspectives. We demonstrate the potential of these explanations to assess whether the vehicle operates within acceptable legal boundaries and to identify possible vulnerabilities in autonomous driving datasets and models.
The Aloe Family Recipe for Open and Specialized Healthcare LLMs
May 07, 2025Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.
Intention-aware policy graphs: answering what, how, and why in opaque agents
Sep 27, 2024



Agents are a special kind of AI-based software in that they interact in complex environments and have increased potential for emergent behaviour. Explaining such emergent behaviour is key to deploying trustworthy AI, but the increasing complexity and opaque nature of many agent implementations makes this hard. In this work, we propose a Probabilistic Graphical Model along with a pipeline for designing such model -- by which the behaviour of an agent can be deliberated about -- and for computing a robust numerical value for the intentions the agent has at any moment. We contribute measurements that evaluate the interpretability and reliability of explanations provided, and enables explainability questions such as `what do you want to do now?' (e.g. deliver soup) `how do you plan to do it?' (e.g. returning a plan that considers its skills and the world), and `why would you take this action at this state?' (e.g. explaining how that furthers or hinders its own goals). This model can be constructed by taking partial observations of the agent's actions and world states, and we provide an iterative workflow for increasing the proposed measurements through better design and/or pointing out irrational agent behaviour.
The use of Synthetic Data to solve the scalability and data availability problems in Smart City Digital Twins
Jul 06, 2022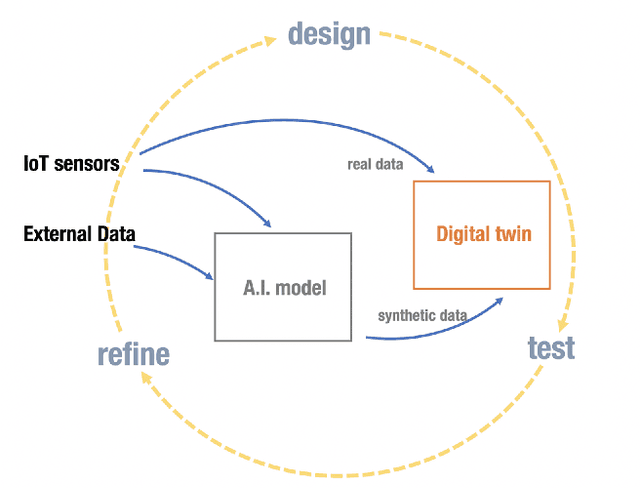
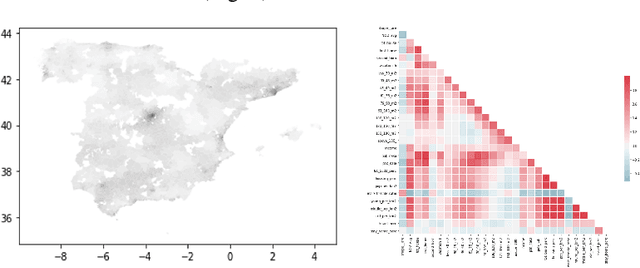


The A.I. disruption and the need to compete on innovation are impacting cities that have an increasing necessity to become innovation hotspots. However, without proven solutions, experimentation, often unsuccessful, is needed. But experimentation in cities has many undesirable effects not only for its citizens but also reputational if unsuccessful. Digital Twins, so popular in other areas, seem like a promising way to expand experimentation proposals but in simulated environments, translating only the half-baked ones, the ones with higher probability of success, to real environments and therefore minimizing risks. However, Digital Twins are data intensive and need highly localized data, making them difficult to scale, particularly to small cities, and with the high cost associated to data collection. We present an alternative based on synthetic data that given some conditions, quite common in Smart Cities, can solve these two problems together with a proof-of-concept based on NO2 pollution.
A trainable monogenic ConvNet layer robust in front of large contrast changes in image classification
Sep 14, 2021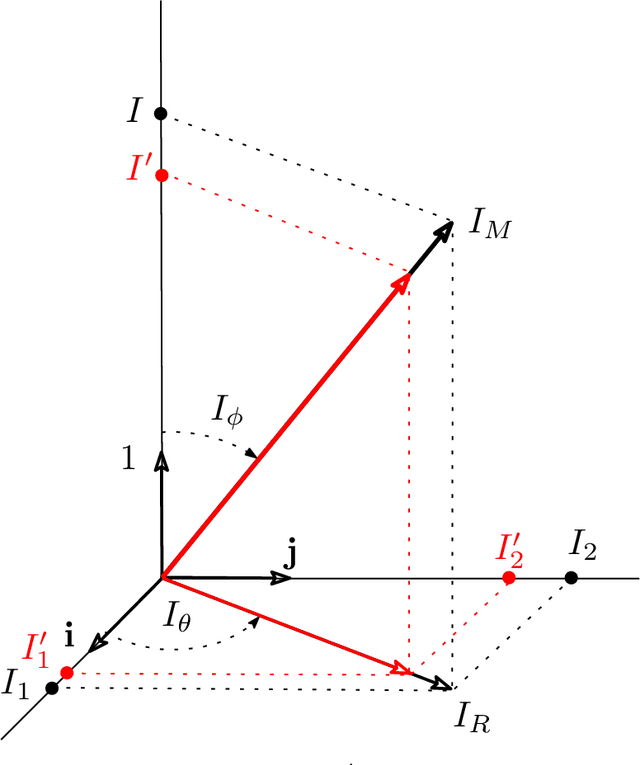
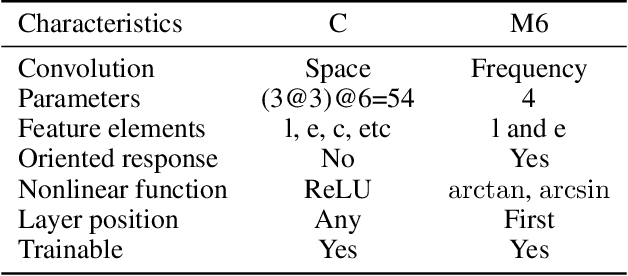

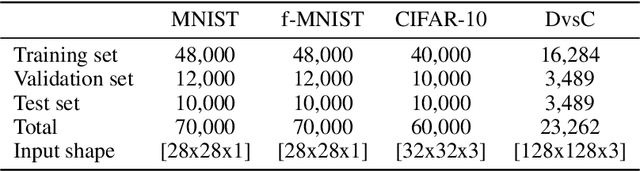
Convolutional Neural Networks (ConvNets) at present achieve remarkable performance in image classification tasks. However, current ConvNets cannot guarantee the capabilities of the mammalian visual systems such as invariance to contrast and illumination changes. Some ideas to overcome the illumination and contrast variations usually have to be tuned manually and tend to fail when tested with other types of data degradation. In this context, we present a new bio-inspired {entry} layer, M6, which detects low-level geometric features (lines, edges, and orientations) which are similar to patterns detected by the V1 visual cortex. This new trainable layer is capable of coping with image classification even with large contrast variations. The explanation for this behavior is the monogenic signal geometry, which represents each pixel value in a 3D space using quaternions, a fact that confers a degree of explainability to the networks. We compare M6 with a conventional convolutional layer (C) and a deterministic quaternion local phase layer (Q9). The experimental setup {is designed to evaluate the robustness} of our M6 enriched ConvNet model and includes three architectures, four datasets, three types of contrast degradation (including non-uniform haze degradations). The numerical results reveal that the models with M6 are the most robust in front of any kind of contrast variations. This amounts to a significant enhancement of the C models, which usually have reasonably good performance only when the same training and test degradation are used, except for the case of maximum degradation. Moreover, the Structural Similarity Index Measure (SSIM) is used to analyze and explain the robustness effect of the M6 feature maps under any kind of contrast degradations.
Random Forest as a Tumour Genetic Marker Extractor
Nov 26, 2019
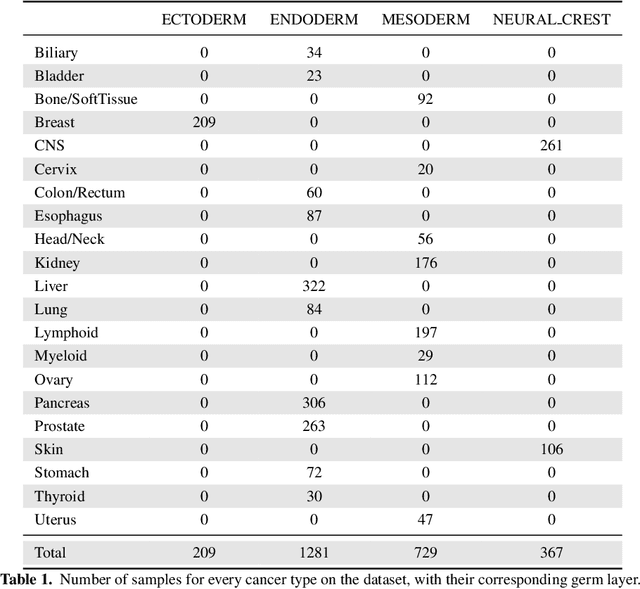
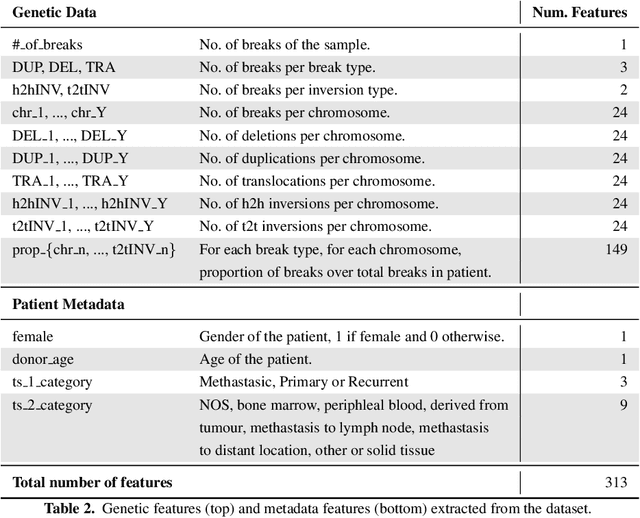

Finding tumour genetic markers is essential to biomedicine due to their relevance for cancer detection and therapy development. In this paper, we explore a recently released dataset of chromosome rearrangements in 2,586 cancer patients, where different sorts of alterations have been detected. Using a Random Forest classifier, we evaluate the relevance of several features (some directly available in the original data, some engineered by us) related to chromosome rearrangements. This evaluation results in a set of potential tumour genetic markers, some of which are validated in the bibliography, while others are potentially novel.
A Visual Distance for WordNet
Apr 27, 2018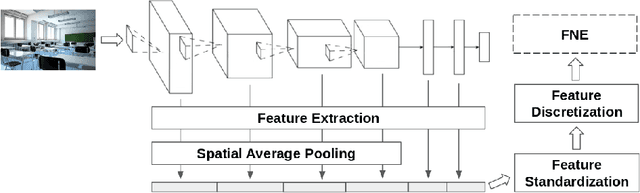
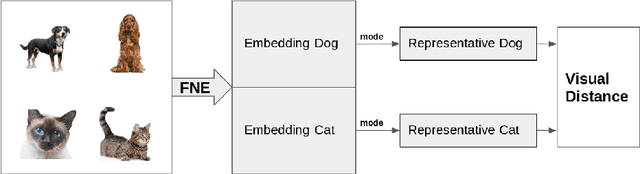
Measuring the distance between concepts is an important field of study of Natural Language Processing, as it can be used to improve tasks related to the interpretation of those same concepts. WordNet, which includes a wide variety of concepts associated with words (i.e., synsets), is often used as a source for computing those distances. In this paper, we explore a distance for WordNet synsets based on visual features, instead of lexical ones. For this purpose, we extract the graphic features generated within a deep convolutional neural networks trained with ImageNet and use those features to generate a representative of each synset. Based on those representatives, we define a distance measure of synsets, which complements the traditional lexical distances. Finally, we propose some experiments to evaluate its performance and compare it with the current state-of-the-art.
On the Behavior of Convolutional Nets for Feature Extraction
Jan 29, 2018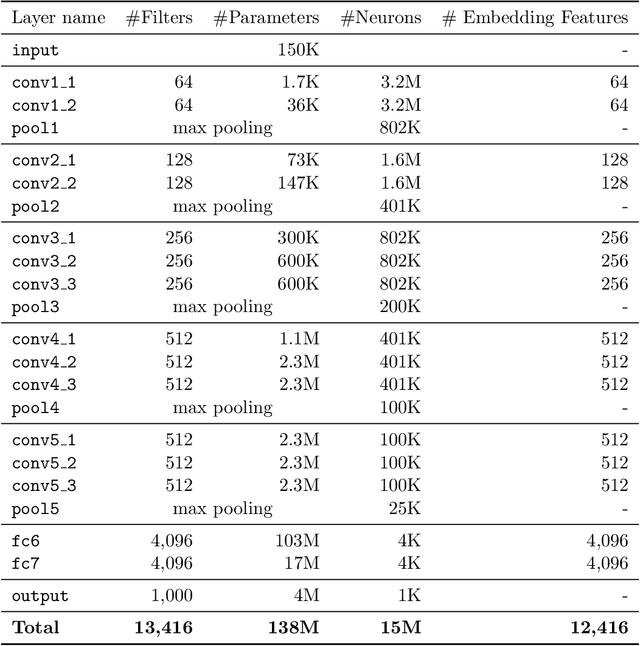
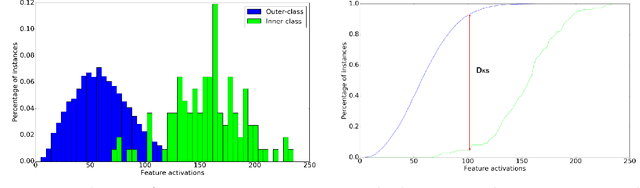

Deep neural networks are representation learning techniques. During training, a deep net is capable of generating a descriptive language of unprecedented size and detail in machine learning. Extracting the descriptive language coded within a trained CNN model (in the case of image data), and reusing it for other purposes is a field of interest, as it provides access to the visual descriptors previously learnt by the CNN after processing millions of images, without requiring an expensive training phase. Contributions to this field (commonly known as feature representation transfer or transfer learning) have been purely empirical so far, extracting all CNN features from a single layer close to the output and testing their performance by feeding them to a classifier. This approach has provided consistent results, although its relevance is limited to classification tasks. In a completely different approach, in this paper we statistically measure the discriminative power of every single feature found within a deep CNN, when used for characterizing every class of 11 datasets. We seek to provide new insights into the behavior of CNN features, particularly the ones from convolutional layers, as this can be relevant for their application to knowledge representation and reasoning. Our results confirm that low and middle level features may behave differently to high level features, but only under certain conditions. We find that all CNN features can be used for knowledge representation purposes both by their presence or by their absence, doubling the information a single CNN feature may provide. We also study how much noise these features may include, and propose a thresholding approach to discard most of it. All these insights have a direct application to the generation of CNN embedding spaces.
Building Graph Representations of Deep Vector Embeddings
Aug 09, 2017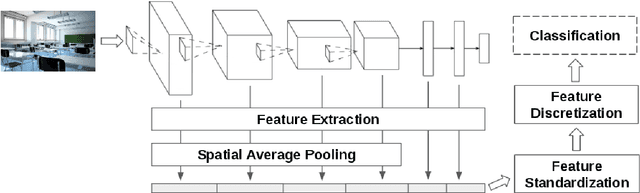
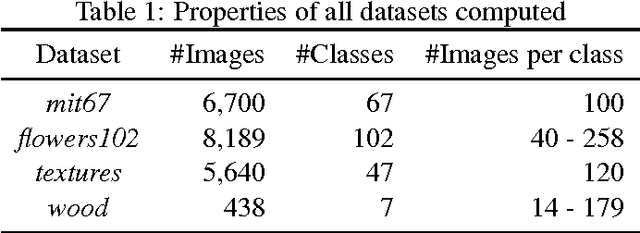
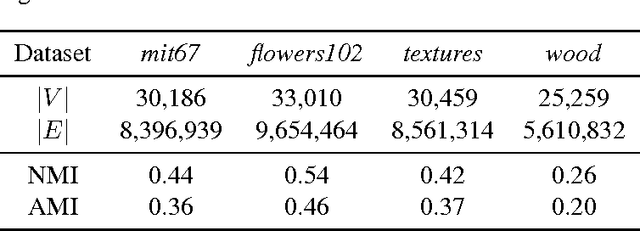
Patterns stored within pre-trained deep neural networks compose large and powerful descriptive languages that can be used for many different purposes. Typically, deep network representations are implemented within vector embedding spaces, which enables the use of traditional machine learning algorithms on top of them. In this short paper we propose the construction of a graph embedding space instead, introducing a methodology to transform the knowledge coded within a deep convolutional network into a topological space (i.e. a network). We outline how such graph can hold data instances, data features, relations between instances and features, and relations among features. Finally, we introduce some preliminary experiments to illustrate how the resultant graph embedding space can be exploited through graph analytics algorithms.