 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computer-aided Interpretable Features for Leaf Image Classification
Jun 15, 2021


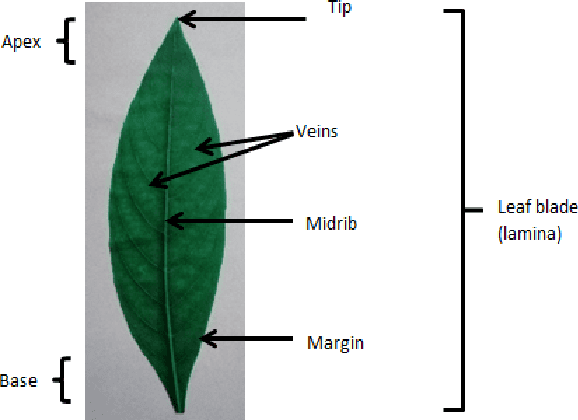
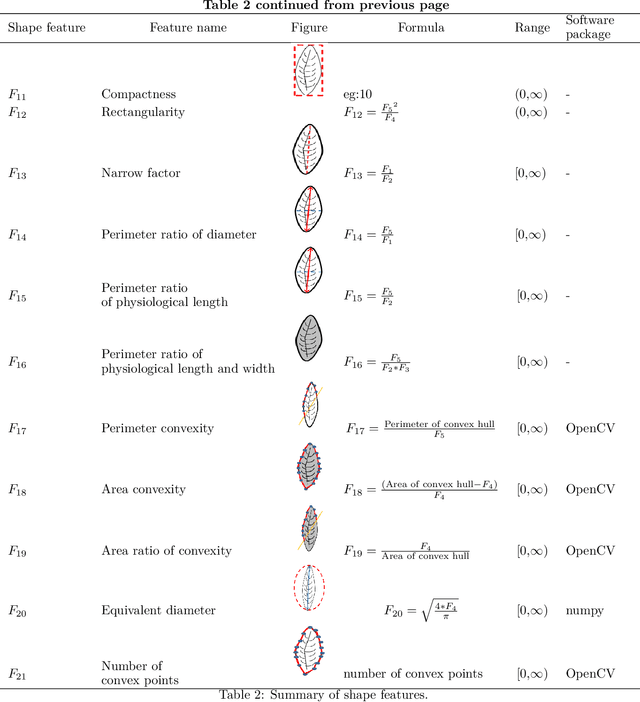
Plant species identification is time consuming, costly, and requires lots of efforts, and expertise knowledge. In recent, many researchers use deep learning methods to classify plants directly using plant images. While deep learning models have achieved a great success, the lack of interpretability limit their widespread application. To overcome this, we explore the use of interpretable, measurable and computer-aided features extracted from plant leaf images. Image processing is one of the most challenging, and crucial steps in feature-extraction. The purpose of image processing is to improve the leaf image by removing undesired distortion. The main image processing steps of our algorithm involves: i) Convert original image to RGB (Red-Green-Blue) image, ii) Gray scaling, iii) Gaussian smoothing, iv) Binary thresholding, v) Remove stalk, vi) Closing holes, and vii) Resize image. The next step after image processing is to extract features from plant leaf images. We introduced 52 computationally efficient features to classify plant species. These features are mainly classified into four groups as: i) shape-based features, ii) color-based features, iii) texture-based features, and iv) scagnostic features. Length, width, area, texture correlation, monotonicity and scagnostics are to name few of them. We explore the ability of features to discriminate the classes of interest under supervised learning and unsupervised learning settings. For that, supervised dimensionality reduction technique, Linear Discriminant Analysis (LDA), and unsupervised dimensionality reduction technique, Principal Component Analysis (PCA) are used to convert and visualize the images from digital-image space to feature space. The results show that the features are sufficient to discriminate the classes of interest under both supervised and unsupervised learning settings.
Image Inpainting via Conditional Texture and Structure Dual Generation
Aug 22, 2021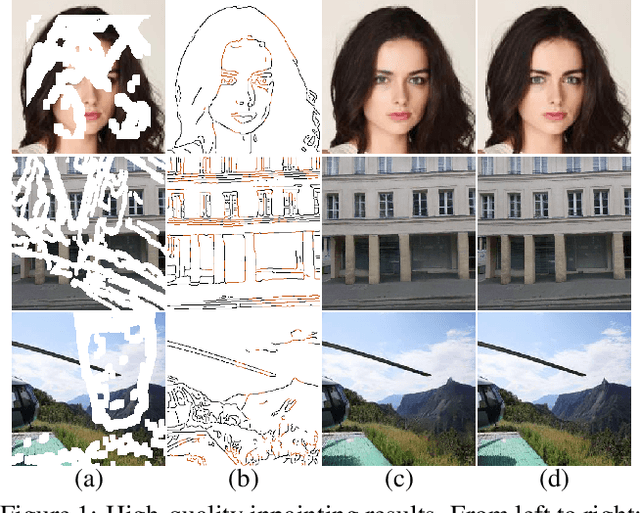
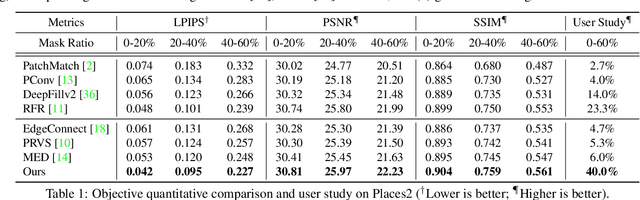
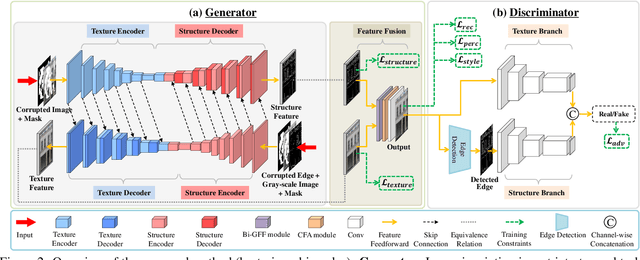
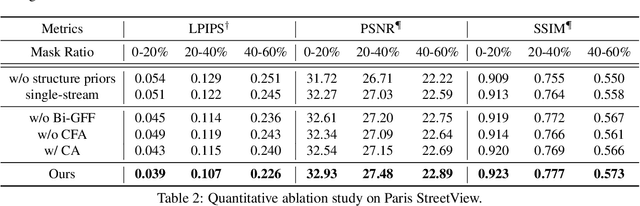
Deep generative approaches have recently made considerable progress in image inpainting by introducing structure priors. Due to the lack of proper interaction with image texture during structure reconstruction, however, current solutions are incompetent in handling the cases with large corruptions, and they generally suffer from distorted results. In this paper, we propose a novel two-stream network for image inpainting, which models the structure-constrained texture synthesis and texture-guided structure reconstruction in a coupled manner so that they better leverage each other for more plausible generation. Furthermore, to enhance the global consistency, a Bi-directional Gated Feature Fusion (Bi-GFF) module is designed to exchange and combine the structure and texture information and a Contextual Feature Aggregation (CFA) module is developed to refine the generated contents by region affinity learning and multi-scale feature aggregation. Qualitative and quantitative experiments on the CelebA, Paris StreetView and Places2 datasets demonstrate the superiority of the proposed method. Our code is available at https://github.com/Xiefan-Guo/CTSDG.
End-to-End 3D Hand Pose Estimation from Stereo Cameras
Jun 03, 2022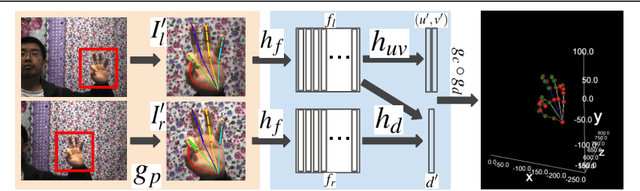
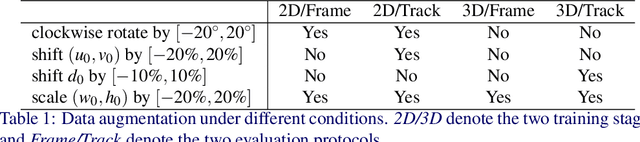

This work proposes an end-to-end approach to estimate full 3D hand pose from stereo cameras. Most existing methods of estimating hand pose from stereo cameras apply stereo matching to obtain depth map and use depth-based solution to estimate hand pose. In contrast, we propose to bypass the stereo matching and directly estimate the 3D hand pose from the stereo image pairs. The proposed neural network architecture extends from any keypoint predictor to estimate the sparse disparity of the hand joints. In order to effectively train the model, we propose a large scale synthetic dataset that is composed of stereo image pairs and ground truth 3D hand pose annotations. Experiments show that the proposed approach outperforms the existing methods based on the stereo depth.
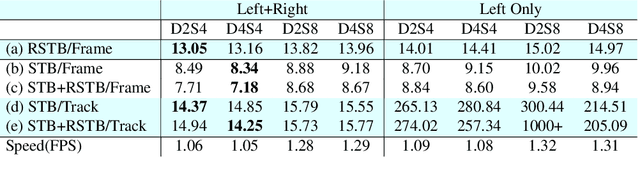
Learning to Predict 3D Lane Shape and Camera Pose from a Single Image via Geometry Constraints
Dec 31, 2021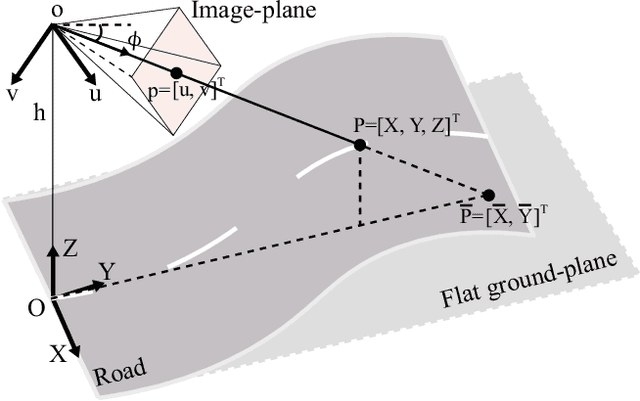
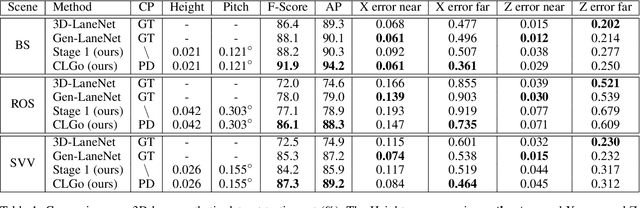
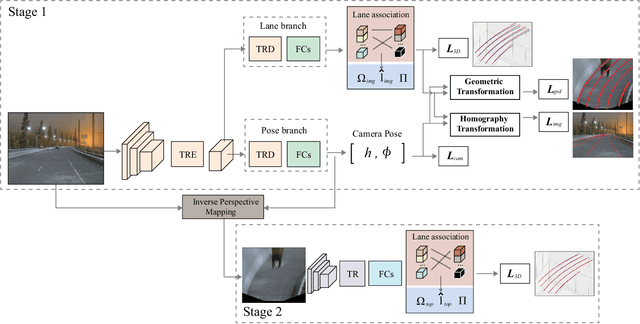
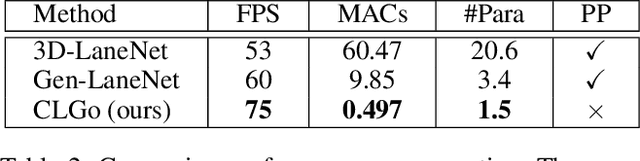
Detecting 3D lanes from the camera is a rising problem for autonomous vehicles. In this task, the correct camera pose is the key to generating accurate lanes, which can transform an image from perspective-view to the top-view. With this transformation, we can get rid of the perspective effects so that 3D lanes would look similar and can accurately be fitted by low-order polynomials. However, mainstream 3D lane detectors rely on perfect camera poses provided by other sensors, which is expensive and encounters multi-sensor calibration issues. To overcome this problem, we propose to predict 3D lanes by estimating camera pose from a single image with a two-stage framework. The first stage aims at the camera pose task from perspective-view images. To improve pose estimation, we introduce an auxiliary 3D lane task and geometry constraints to benefit from multi-task learning, which enhances consistencies between 3D and 2D, as well as compatibility in the above two tasks. The second stage targets the 3D lane task. It uses previously estimated pose to generate top-view images containing distance-invariant lane appearances for predicting accurate 3D lanes. Experiments demonstrate that, without ground truth camera pose, our method outperforms the state-of-the-art perfect-camera-pose-based methods and has the fewest parameters and computations. Codes are available at https://github.com/liuruijin17/CLGo.
Adversarially-Aware Robust Object Detector
Jul 22, 2022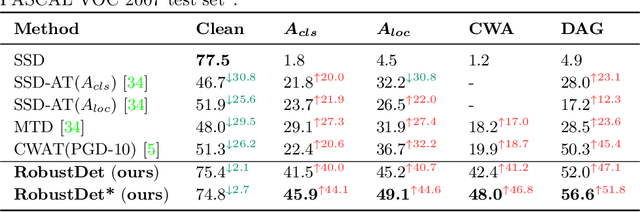
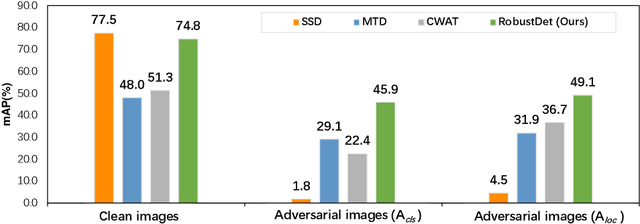
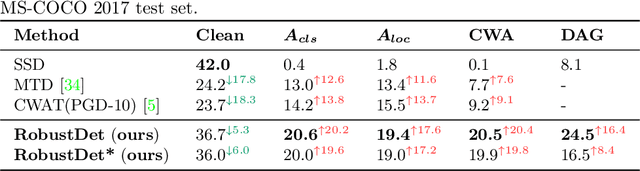
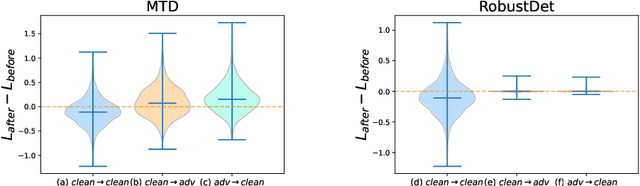
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022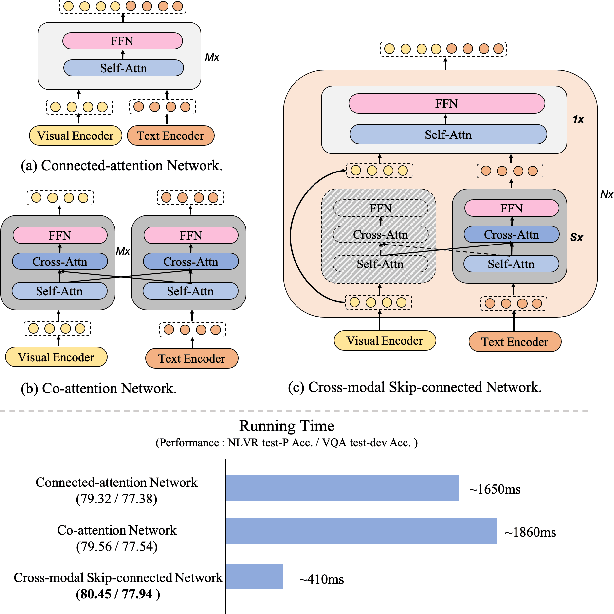
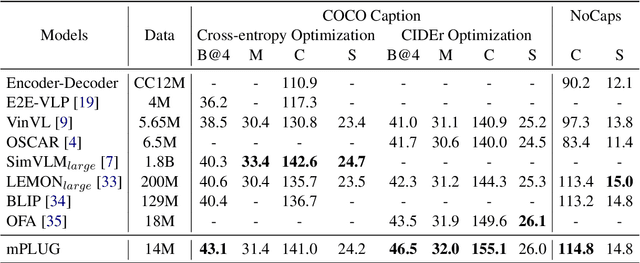
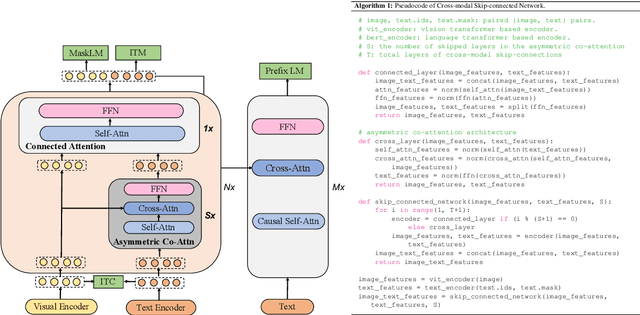
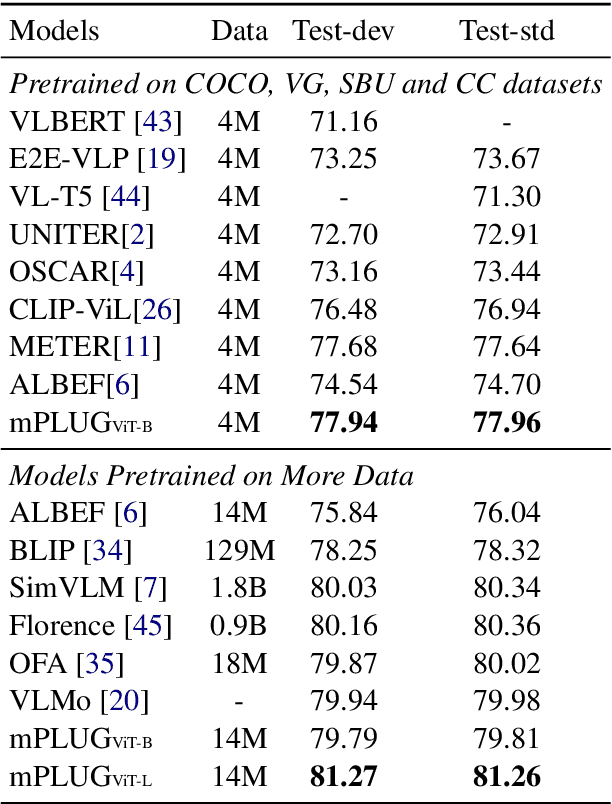
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Deep Image: A precious image based deep learning method for online malware detection in IoT Environment
Apr 04, 2022
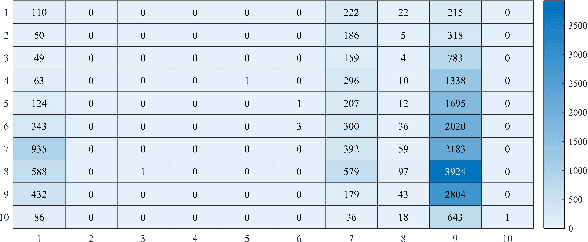
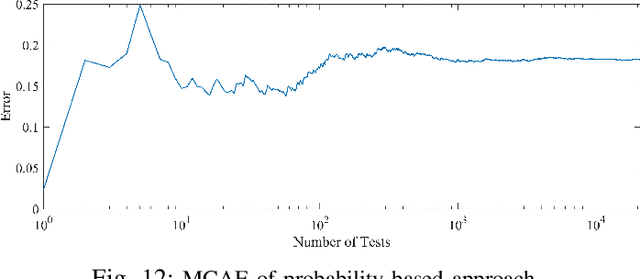
The volume of malware and the number of attacks in IoT devices are rising everyday, which encourages security professionals to continually enhance their malware analysis tools. Researchers in the field of cyber security have extensively explored the usage of sophisticated analytics and the efficiency of malware detection. With the introduction of new malware kinds and attack routes, security experts confront considerable challenges in developing efficient malware detection and analysis solutions. In this paper, a different view of malware analysis is considered and the risk level of each sample feature is computed, and based on that the risk level of that sample is calculated. In this way, a criterion is introduced that is used together with accuracy and FPR criteria for malware analysis in IoT environment. In this paper, three malware detection methods based on visualization techniques called the clustering approach, the probabilistic approach, and the deep learning approach are proposed. Then, in addition to the usual machine learning criteria namely accuracy and FPR, a proposed criterion based on the risk of samples has also been used for comparison, with the results showing that the deep learning approach performed better in detecting malware
Rethinking the Openness of CLIP
Jun 04, 2022Contrastive Language-Image Pre-training (CLIP) has demonstrated great potential in realizing open-vocabulary image classification in a matching style, because of its holistic use of natural language supervision that covers unconstrained real-world visual concepts. However, it is, in turn, also difficult to evaluate and analyze the openness of CLIP-like models, since they are in theory open to any vocabulary but the actual accuracy varies. To address the insufficiency of conventional studies on openness, we resort to an incremental view and define the extensibility, which essentially approximates the model's ability to deal with new visual concepts, by evaluating openness through vocabulary expansions. Our evaluation based on extensibility shows that CLIP-like models are hardly truly open and their performances degrade as the vocabulary expands to different degrees. Further analysis reveals that the over-estimation of openness is not because CLIP-like models fail to capture the general similarity of image and text features of novel visual concepts, but because of the confusion among competing text features, that is, they are not stable with respect to the vocabulary. In light of this, we propose to improve the openness of CLIP from the perspective of feature space by enforcing the distinguishability of text features. Our method retrieves relevant texts from the pre-training corpus to enhance prompts for inference, which boosts the extensibility and stability of CLIP even without fine-tuning.
PPT Fusion: Pyramid Patch Transformerfor a Case Study in Image Fusion
Jul 29, 2021

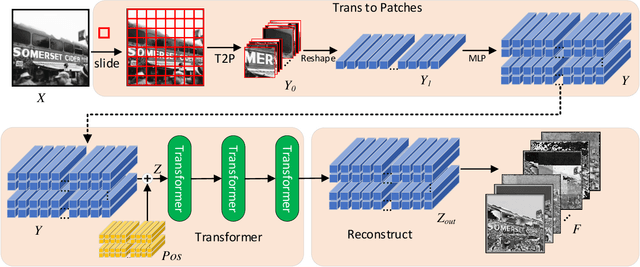
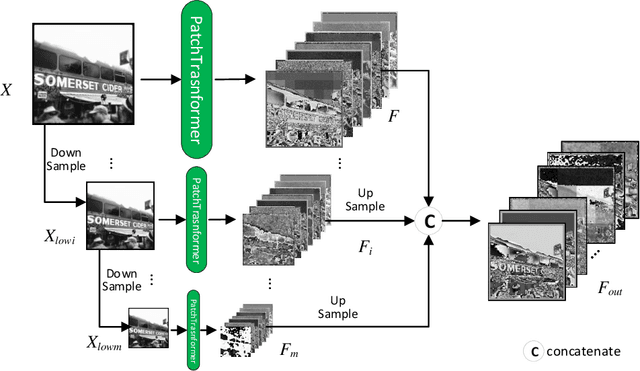
The Transformer architecture has achieved rapiddevelopment in recent years, outperforming the CNN archi-tectures in many computer vision tasks, such as the VisionTransformers (ViT) for image classification. However, existingvisual transformer models aim to extract semantic informationfor high-level tasks such as classification and detection, distortingthe spatial resolution of the input image, thus sacrificing thecapacity in reconstructing the input or generating high-resolutionimages. In this paper, therefore, we propose a Patch PyramidTransformer(PPT) to effectively address the above issues. Specif-ically, we first design a Patch Transformer to transform theimage into a sequence of patches, where transformer encodingis performed for each patch to extract local representations.In addition, we construct a Pyramid Transformer to effectivelyextract the non-local information from the entire image. Afterobtaining a set of multi-scale, multi-dimensional, and multi-anglefeatures of the original image, we design the image reconstructionnetwork to ensure that the features can be reconstructed intothe original input. To validate the effectiveness, we apply theproposed Patch Pyramid Transformer to the image fusion task.The experimental results demonstrate its superior performanceagainst the state-of-the-art fusion approaches, achieving the bestresults on several evaluation indicators. The underlying capacityof the PPT network is reflected by its universal power in featureextraction and image reconstruction, which can be directlyapplied to different image fusion tasks without redesigning orretraining the network.
Image Denoising in FPGA using Generic Risk Estimation
Nov 16, 2021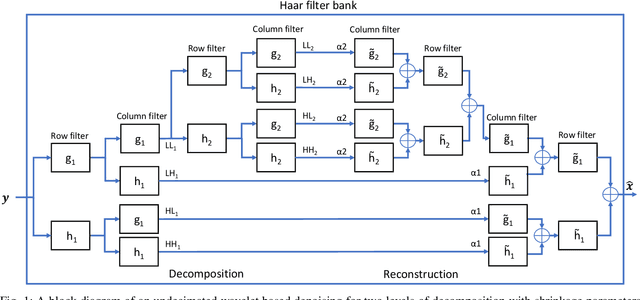
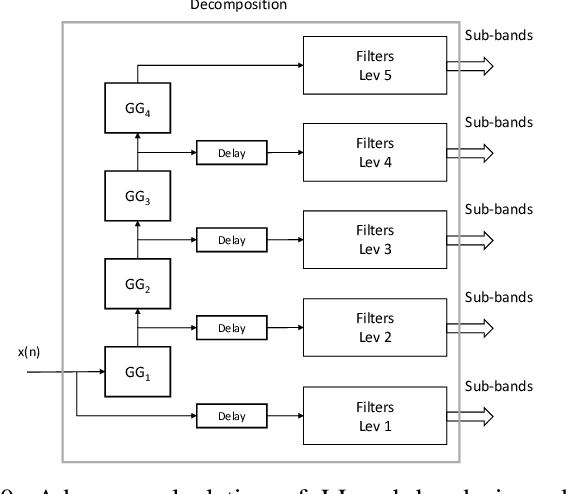
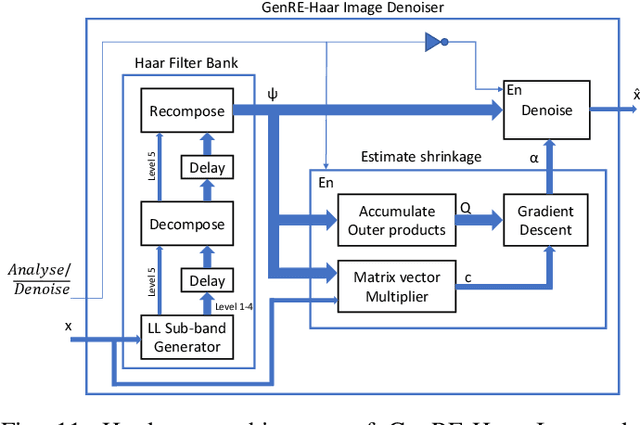

The generic risk estimator addresses the problem of denoising images corrupted by additive white noise without placing any restriction on the statistical distribution of the noise. In this paper, we discuss an efficient FPGA implementation of this algorithm. We use the undecimated Haar wavelet transform with shrinkage parameters for each sub-band as the denoising function. The computational complexity and memory requirement of the algorithm is first analyzed. To optimize the performance, a combination of convolution and recursion is employed to realize Haar filter bank and gradient descent algorithm is used to find the shrinkage parameters. A fully pipelined and parallel architecture is developed to achieve high throughput. The proposed design achieves an execution time of 3.5ms for an image of size 512x512. We also show that the recursive implementation of Haar wavelet is more expensive than the direct implementation in terms of hardware utilization.