 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Prior Feature and Attention Enhanced Image Inpainting
Aug 03, 2022


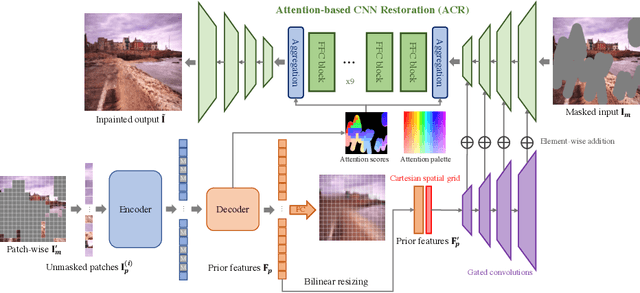

Many recent inpainting works have achieved impressive results by leveraging Deep Neural Networks (DNNs) to model various prior information for image restoration. Unfortunately, the performance of these methods is largely limited by the representation ability of vanilla Convolutional Neural Networks (CNNs) backbones.On the other hand, Vision Transformers (ViT) with self-supervised pre-training have shown great potential for many visual recognition and object detection tasks. A natural question is whether the inpainting task can be greatly benefited from the ViT backbone? However, it is nontrivial to directly replace the new backbones in inpainting networks, as the inpainting is an inverse problem fundamentally different from the recognition tasks. To this end, this paper incorporates the pre-training based Masked AutoEncoder (MAE) into the inpainting model, which enjoys richer informative priors to enhance the inpainting process. Moreover, we propose to use attention priors from MAE to make the inpainting model learn more long-distance dependencies between masked and unmasked regions. Sufficient ablations have been discussed about the inpainting and the self-supervised pre-training models in this paper. Besides, experiments on both Places2 and FFHQ demonstrate the effectiveness of our proposed model. Codes and pre-trained models are released in https://github.com/ewrfcas/MAE-FAR.
Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification
Nov 21, 2022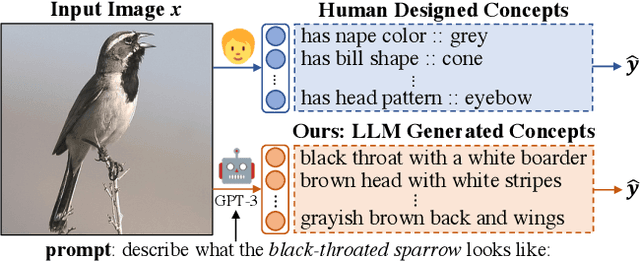

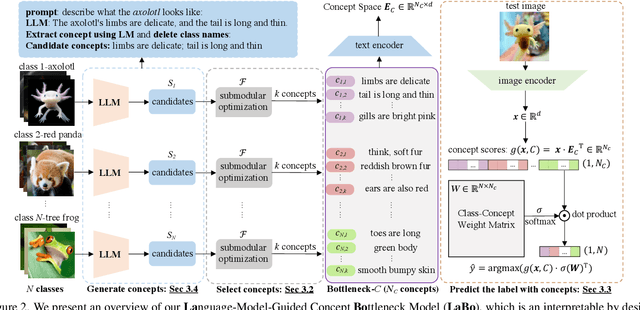

Concept Bottleneck Models (CBM) are inherently interpretable models that factor model decisions into human-readable concepts. They allow people to easily understand why a model is failing, a critical feature for high-stakes applications. CBMs require manually specified concepts and often under-perform their black box counterparts, preventing their broad adoption. We address these shortcomings and are first to show how to construct high-performance CBMs without manual specification of similar accuracy to black box models. Our approach, Language Guided Bottlenecks (LaBo), leverages a language model, GPT-3, to define a large space of possible bottlenecks. Given a problem domain, LaBo uses GPT-3 to produce factual sentences about categories to form candidate concepts. LaBo efficiently searches possible bottlenecks through a novel submodular utility that promotes the selection of discriminative and diverse information. Ultimately, GPT-3's sentential concepts can be aligned to images using CLIP, to form a bottleneck layer. Experiments demonstrate that LaBo is a highly effective prior for concepts important to visual recognition. In the evaluation with 11 diverse datasets, LaBo bottlenecks excel at few-shot classification: they are 11.7% more accurate than black box linear probes at 1 shot and comparable with more data. Overall, LaBo demonstrates that inherently interpretable models can be widely applied at similar, or better, performance than black box approaches.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning
May 28, 2022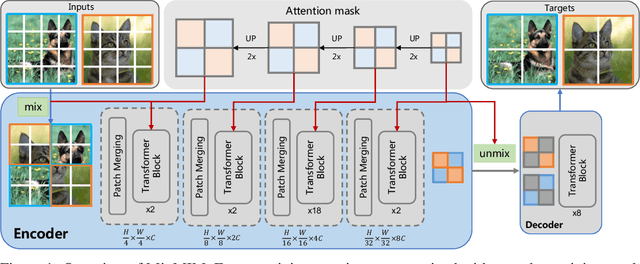

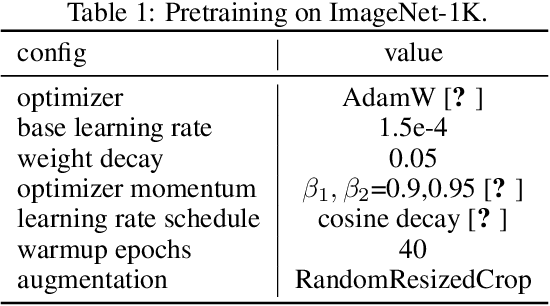
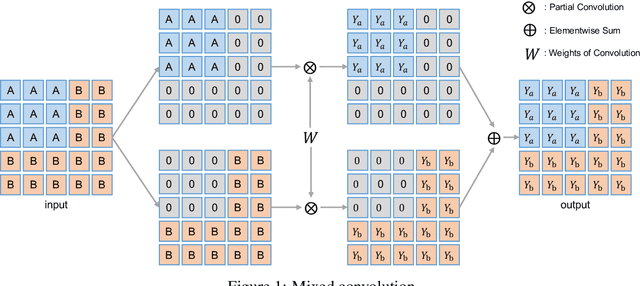
In this study, we propose Mixed and Masked Image Modeling (MixMIM), a simple but efficient MIM method that is applicable to various hierarchical Vision Transformers. Existing MIM methods replace a random subset of input tokens with a special MASK symbol and aim at reconstructing original image tokens from the corrupted image. However, we find that using the MASK symbol greatly slows down the training and causes training-finetuning inconsistency, due to the large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens of one image with visible tokens of another image, i.e., creating a mixed image. We then conduct dual reconstruction to reconstruct the original two images from the mixed input, which significantly improves efficiency. While MixMIM can be applied to various architectures, this paper explores a simpler but stronger hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical results demonstrate that MixMIM can learn high-quality visual representations efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1 accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for neural networks with comparable model sizes (e.g., ViT-B) among MIM methods. Besides, its transferring performances on the other 6 datasets show MixMIM has better FLOPs / performance tradeoff than previous MIM methods. Code is available at https://github.com/Sense-X/MixMIM.
Exemplar Learning for Medical Image Segmentation
Apr 03, 2022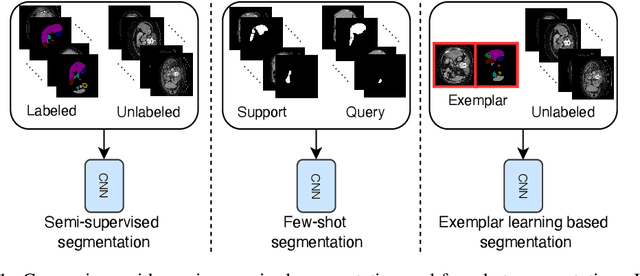

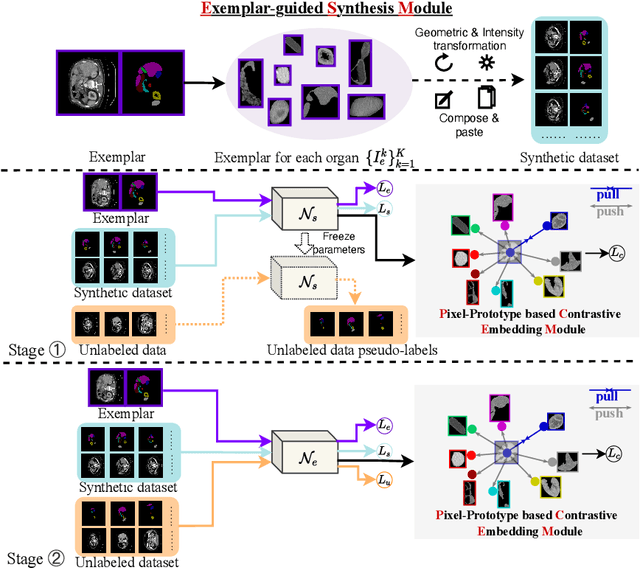
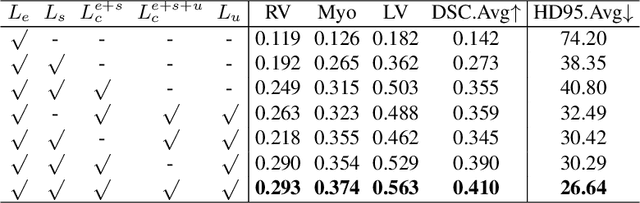
Medical image annotation typically requires expert knowledge and hence incurs time-consuming and expensive data annotation costs. To reduce this burden, we propose a novel learning scenario, Exemplar Learning (EL), to explore automated learning processes for medical image segmentation from a single annotated image example. This innovative learning task is particularly suitable for medical image segmentation, where all categories of organs can be presented in one single image for annotation all at once. To address this challenging EL task, we propose an Exemplar Learning-based Synthesis Net (ELSNet) framework for medical image segmentation that enables innovative exemplar-based data synthesis, pixel-prototype based contrastive embedding learning, and pseudo-label based exploitation of the unlabeled data. Specifically, ELSNet introduces two new modules for image segmentation: an exemplar-guided synthesis module, which enriches and diversifies the training set by synthesizing annotated samples from the given exemplar, and a pixel-prototype based contrastive embedding module, which enhances the discriminative capacity of the base segmentation model via contrastive self-supervised learning. Moreover, we deploy a two-stage process for segmentation model training, which exploits the unlabeled data with predicted pseudo segmentation labels. To evaluate this new learning framework, we conduct extensive experiments on several organ segmentation datasets and present an in-depth analysis. The empirical results show that the proposed exemplar learning framework produces effective segmentation results.
Super-resolution image display using diffractive decoders
Jun 15, 2022
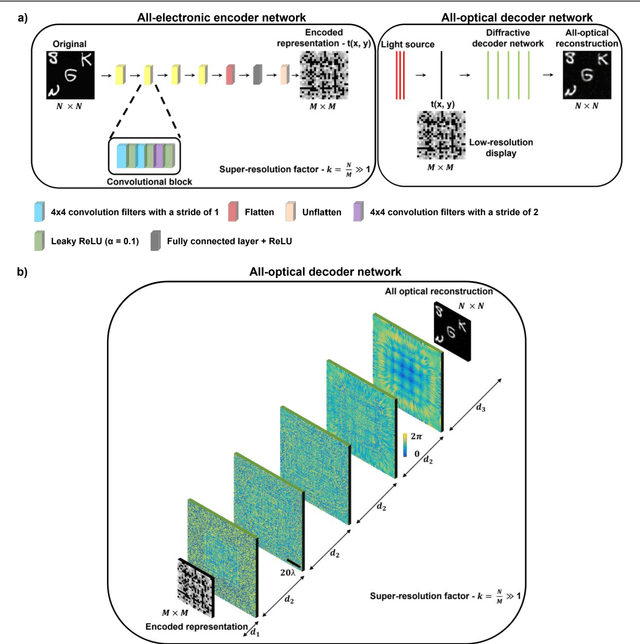
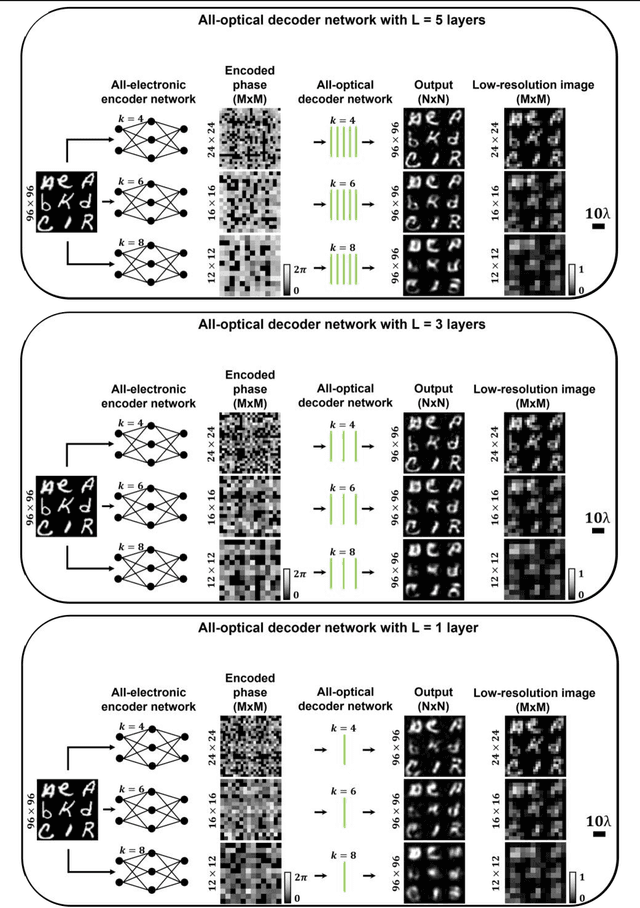
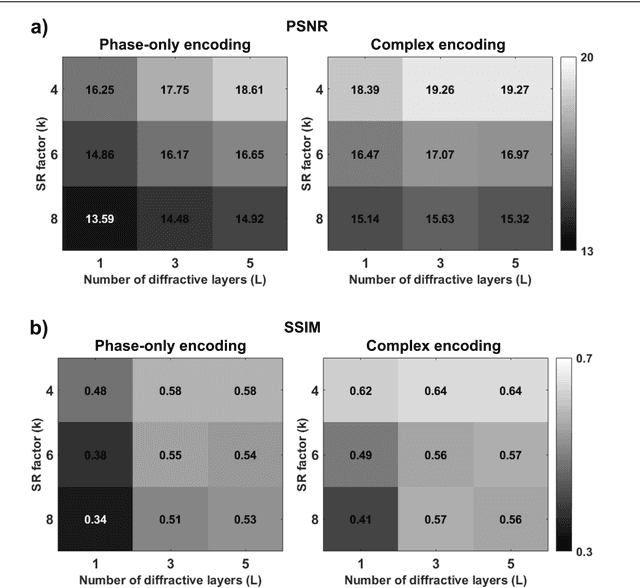
High-resolution synthesis/projection of images over a large field-of-view (FOV) is hindered by the restricted space-bandwidth-product (SBP) of wavefront modulators. We report a deep learning-enabled diffractive display design that is based on a jointly-trained pair of an electronic encoder and a diffractive optical decoder to synthesize/project super-resolved images using low-resolution wavefront modulators. The digital encoder, composed of a trained convolutional neural network (CNN), rapidly pre-processes the high-resolution images of interest so that their spatial information is encoded into low-resolution (LR) modulation patterns, projected via a low SBP wavefront modulator. The diffractive decoder processes this LR encoded information using thin transmissive layers that are structured using deep learning to all-optically synthesize and project super-resolved images at its output FOV. Our results indicate that this diffractive image display can achieve a super-resolution factor of ~4, demonstrating a ~16-fold increase in SBP. We also experimentally validate the success of this diffractive super-resolution display using 3D-printed diffractive decoders that operate at the THz spectrum. This diffractive image decoder can be scaled to operate at visible wavelengths and inspire the design of large FOV and high-resolution displays that are compact, low-power, and computationally efficient.
Towards Efficient Single Image Dehazing and Desnowing
Apr 19, 2022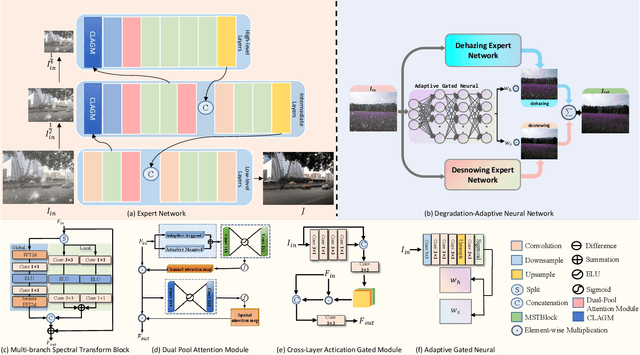
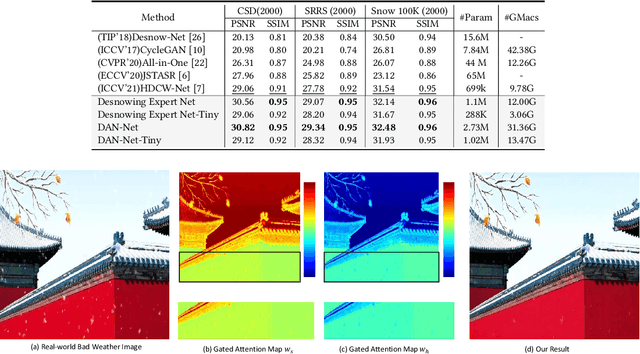

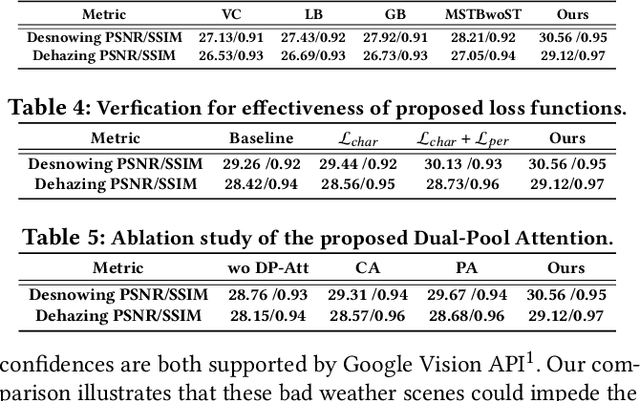
Removing adverse weather conditions like rain, fog, and snow from images is a challenging problem. Although the current recovery algorithms targeting a specific condition have made impressive progress, it is not flexible enough to deal with various degradation types. We propose an efficient and compact image restoration network named DAN-Net (Degradation-Adaptive Neural Network) to address this problem, which consists of multiple compact expert networks with one adaptive gated neural. A single expert network efficiently addresses specific degradation in nasty winter scenes relying on the compact architecture and three novel components. Based on the Mixture of Experts strategy, DAN-Net captures degradation information from each input image to adaptively modulate the outputs of task-specific expert networks to remove various adverse winter weather conditions. Specifically, it adopts a lightweight Adaptive Gated Neural Network to estimate gated attention maps of the input image, while different task-specific experts with the same topology are jointly dispatched to process the degraded image. Such novel image restoration pipeline handles different types of severe weather scenes effectively and efficiently. It also enjoys the benefit of coordinate boosting in which the whole network outperforms each expert trained without coordination. Extensive experiments demonstrate that the presented manner outperforms the state-of-the-art single-task methods on image quality and has better inference efficiency. Furthermore, we have collected the first real-world winter scenes dataset to evaluate winter image restoration methods, which contains various hazy and snowy images snapped in winter. Both the dataset and source code will be publicly available.
DiffusionSDF: Conditional Generative Modeling of Signed Distance Functions
Nov 24, 2022
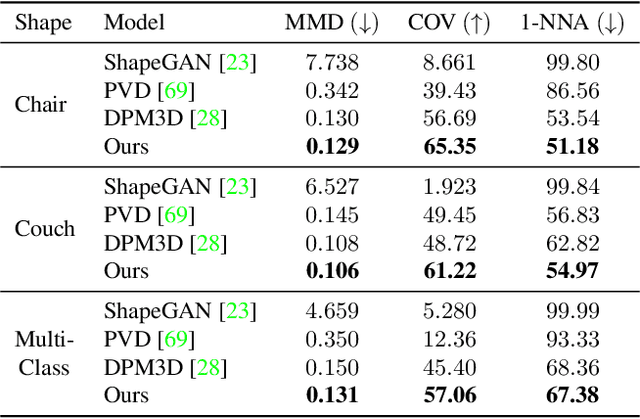
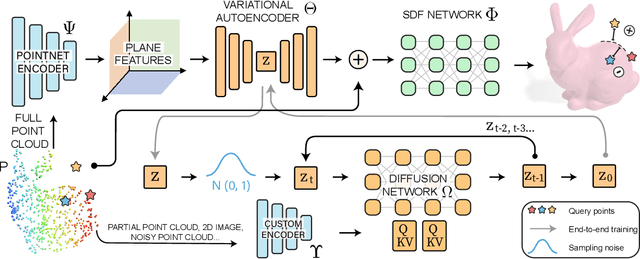
Probabilistic diffusion models have achieved state-of-the-art results for image synthesis, inpainting, and text-to-image tasks. However, they are still in the early stages of generating complex 3D shapes. This work proposes DiffusionSDF, a generative model for shape completion, single-view reconstruction, and reconstruction of real-scanned point clouds. We use neural signed distance functions (SDFs) as our 3D representation to parameterize the geometry of various signals (e.g., point clouds, 2D images) through neural networks. Neural SDFs are implicit functions and diffusing them amounts to learning the reversal of their neural network weights, which we solve using a custom modulation module. Extensive experiments show that our method is capable of both realistic unconditional generation and conditional generation from partial inputs. This work expands the domain of diffusion models from learning 2D, explicit representations, to 3D, implicit representations.
Image Gradient Decomposition for Parallel and Memory-Efficient Ptychographic Reconstruction
May 12, 2022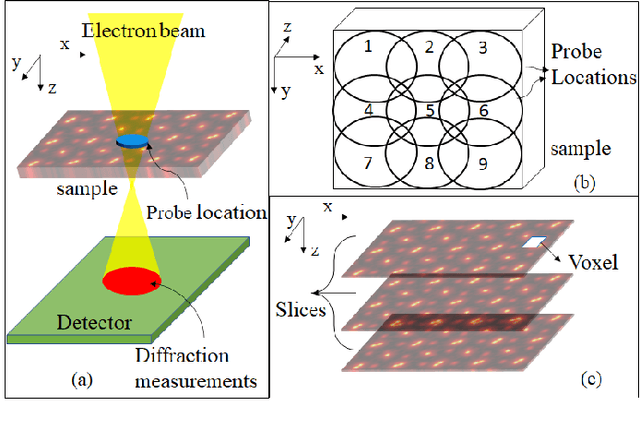
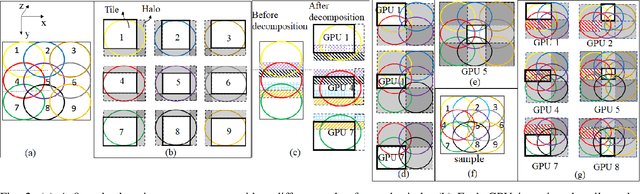
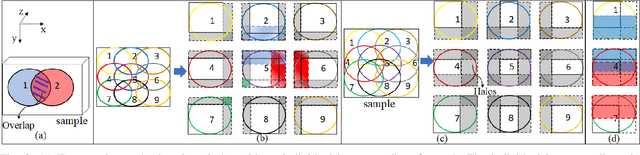
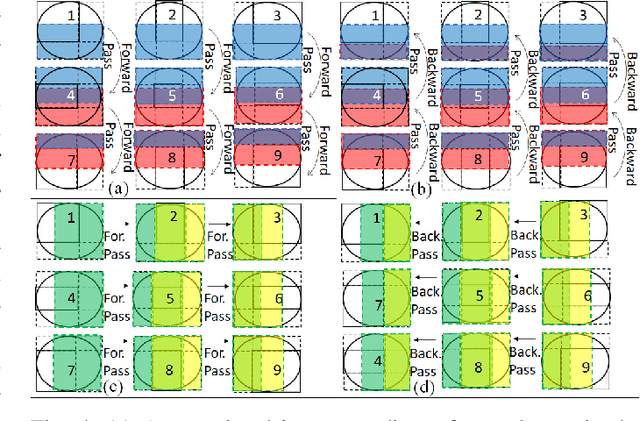
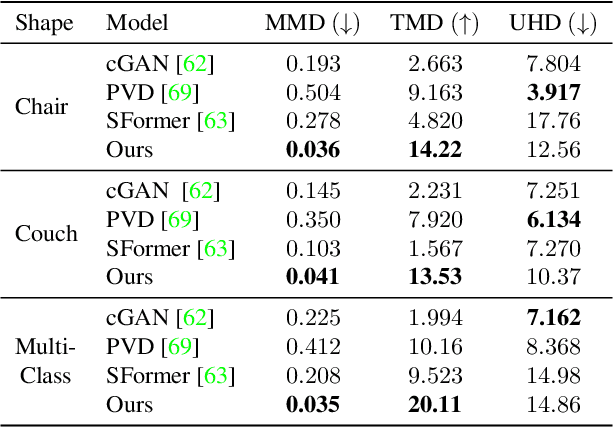
Ptychography is a popular microscopic imaging modality for many scientific discoveries and sets the record for highest image resolution. Unfortunately, the high image resolution for ptychographic reconstruction requires significant amount of memory and computations, forcing many applications to compromise their image resolution in exchange for a smaller memory footprint and a shorter reconstruction time. In this paper, we propose a novel image gradient decomposition method that significantly reduces the memory footprint for ptychographic reconstruction by tessellating image gradients and diffraction measurements into tiles. In addition, we propose a parallel image gradient decomposition method that enables asynchronous point-to-point communications and parallel pipelining with minimal overhead on a large number of GPUs. Our experiments on a Titanate material dataset (PbTiO3) with 16632 probe locations show that our Gradient Decomposition algorithm reduces memory footprint by 51 times. In addition, it achieves time-to-solution within 2.2 minutes by scaling to 4158 GPUs with a super-linear speedup at 364% efficiency. This performance is 2.7 times more memory efficient, 9 times more scalable and 86 times faster than the state-of-the-art algorithm.
ImLoveNet: Misaligned Image-supported Registration Network for Low-overlap Point Cloud Pairs
Jul 02, 2022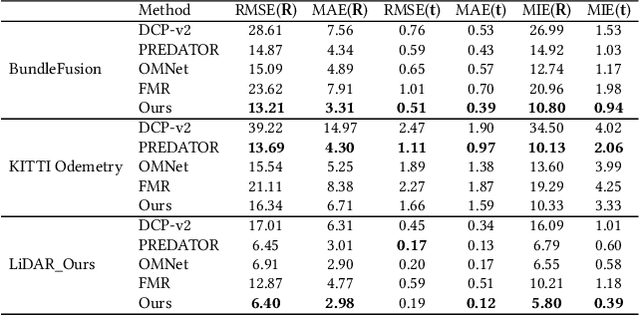
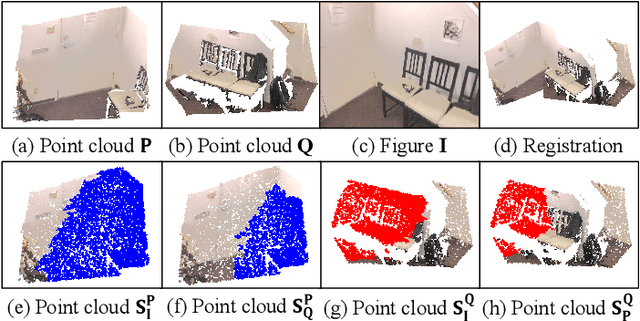
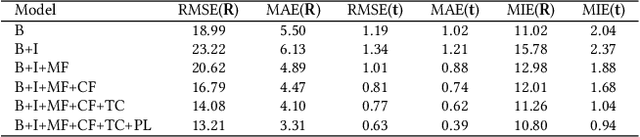
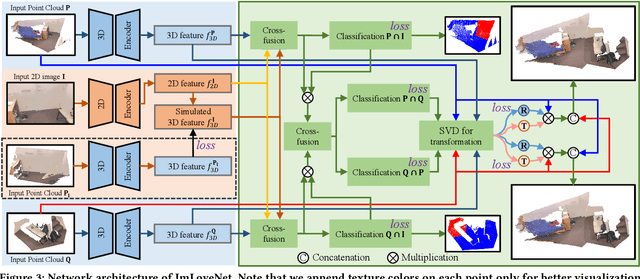
Low-overlap regions between paired point clouds make the captured features very low-confidence, leading cutting edge models to point cloud registration with poor quality. Beyond the traditional wisdom, we raise an intriguing question: Is it possible to exploit an intermediate yet misaligned image between two low-overlap point clouds to enhance the performance of cutting-edge registration models? To answer it, we propose a misaligned image supported registration network for low-overlap point cloud pairs, dubbed ImLoveNet. ImLoveNet first learns triple deep features across different modalities and then exports these features to a two-stage classifier, for progressively obtaining the high-confidence overlap region between the two point clouds. Therefore, soft correspondences are well established on the predicted overlap region, resulting in accurate rigid transformations for registration. ImLoveNet is simple to implement yet effective, since 1) the misaligned image provides clearer overlap information for the two low-overlap point clouds to better locate overlap parts; 2) it contains certain geometry knowledge to extract better deep features; and 3) it does not require the extrinsic parameters of the imaging device with respect to the reference frame of the 3D point cloud. Extensive qualitative and quantitative evaluations on different kinds of benchmarks demonstrate the effectiveness and superiority of our ImLoveNet over state-of-the-art approaches.