 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-Free Bistable Fluidic Gripper for Size-Selective and Stiffness-Adaptive Grasping
Nov 05, 2025Conventional fluid-driven soft grippers typically depend on external sources, which limit portability and long-term autonomy. This work introduces a self-contained soft gripper with fixed size that operates solely through internal liquid redistribution among three interconnected bistable snap-through chambers. When the top sensing chamber deforms upon contact, the displaced liquid triggers snap-through expansion of the grasping chambers, enabling stable and size-selective grasping without continuous energy input. The internal hydraulic feedback further allows passive adaptation of gripping pressure to object stiffness. This source-free and compact design opens new possibilities for lightweight, stiffness-adaptive fluid-driven manipulation in soft robotics, providing a feasible approach for targeted size-specific sampling and operation in underwater and field environments.
Learning IMU Bias with Diffusion Model
May 17, 2025Motion sensing and tracking with IMU data is essential for spatial intelligence, which however is challenging due to the presence of time-varying stochastic bias. IMU bias is affected by various factors such as temperature and vibration, making it highly complex and difficult to model analytically. Recent data-driven approaches using deep learning have shown promise in predicting bias from IMU readings. However, these methods often treat the task as a regression problem, overlooking the stochatic nature of bias. In contrast, we model bias, conditioned on IMU readings, as a probabilistic distribution and design a conditional diffusion model to approximate this distribution. Through this approach, we achieve improved performance and make predictions that align more closely with the known behavior of bias.
Language in a Bottle: Language Model Guided Concept Bottlenecks for Interpretable Image Classification
Nov 21, 2022



Concept Bottleneck Models (CBM) are inherently interpretable models that factor model decisions into human-readable concepts. They allow people to easily understand why a model is failing, a critical feature for high-stakes applications. CBMs require manually specified concepts and often under-perform their black box counterparts, preventing their broad adoption. We address these shortcomings and are first to show how to construct high-performance CBMs without manual specification of similar accuracy to black box models. Our approach, Language Guided Bottlenecks (LaBo), leverages a language model, GPT-3, to define a large space of possible bottlenecks. Given a problem domain, LaBo uses GPT-3 to produce factual sentences about categories to form candidate concepts. LaBo efficiently searches possible bottlenecks through a novel submodular utility that promotes the selection of discriminative and diverse information. Ultimately, GPT-3's sentential concepts can be aligned to images using CLIP, to form a bottleneck layer. Experiments demonstrate that LaBo is a highly effective prior for concepts important to visual recognition. In the evaluation with 11 diverse datasets, LaBo bottlenecks excel at few-shot classification: they are 11.7% more accurate than black box linear probes at 1 shot and comparable with more data. Overall, LaBo demonstrates that inherently interpretable models can be widely applied at similar, or better, performance than black box approaches.
Fine-Grained Egocentric Hand-Object Segmentation: Dataset, Model, and Applications
Aug 07, 2022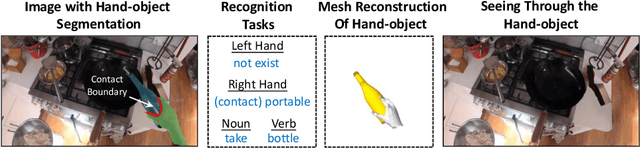
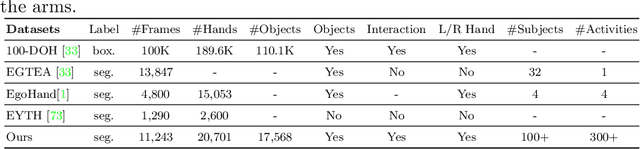
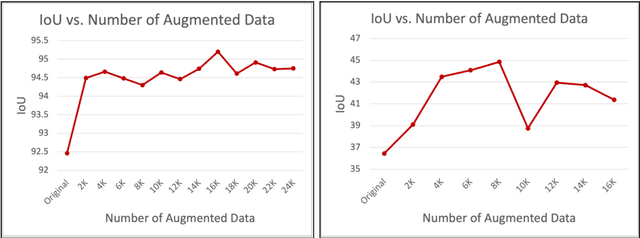

Egocentric videos offer fine-grained information for high-fidelity modeling of human behaviors. Hands and interacting objects are one crucial aspect of understanding a viewer's behaviors and intentions. We provide a labeled dataset consisting of 11,243 egocentric images with per-pixel segmentation labels of hands and objects being interacted with during a diverse array of daily activities. Our dataset is the first to label detailed hand-object contact boundaries. We introduce a context-aware compositional data augmentation technique to adapt to out-of-distribution YouTube egocentric video. We show that our robust hand-object segmentation model and dataset can serve as a foundational tool to boost or enable several downstream vision applications, including hand state classification, video activity recognition, 3D mesh reconstruction of hand-object interactions, and video inpainting of hand-object foregrounds in egocentric videos. Dataset and code are available at: https://github.com/owenzlz/EgoHOS