 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out-of-Distribution Detection with Reconstruction Error and Typicality-based Penalty
Dec 24, 2022
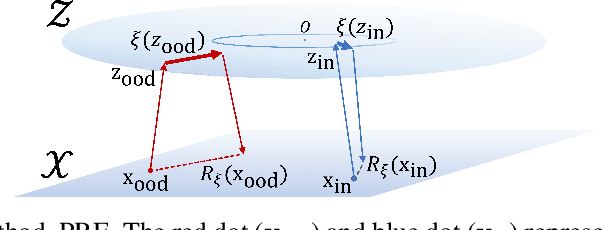
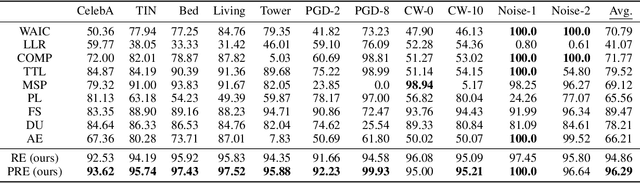
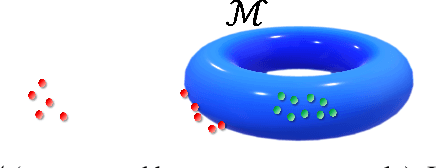
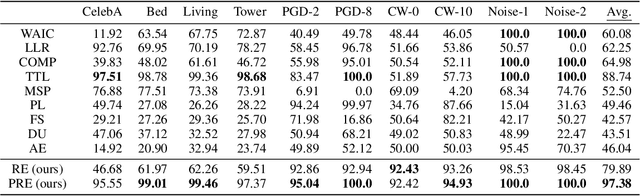
The task of out-of-distribution (OOD) detection is vital to realize safe and reliable operation for real-world applications. After the failure of likelihood-based detection in high dimensions had been shown, approaches based on the \emph{typical set} have been attracting attention; however, they still have not achieved satisfactory performance. Beginning by presenting the failure case of the typicality-based approach, we propose a new reconstruction error-based approach that employs normalizing flow (NF). We further introduce a typicality-based penalty, and by incorporating it into the reconstruction error in NF, we propose a new OOD detection method, penalized reconstruction error (PRE). Because the PRE detects test inputs that lie off the in-distribution manifold, it effectively detects adversarial examples as well as OOD examples. We show the effectiveness of our method through the evaluation using natural image datasets, CIFAR-10, TinyImageNet, and ILSVRC2012.
FeatureBooster: Boosting Feature Descriptors with a Lightweight Neural Network
Nov 28, 2022
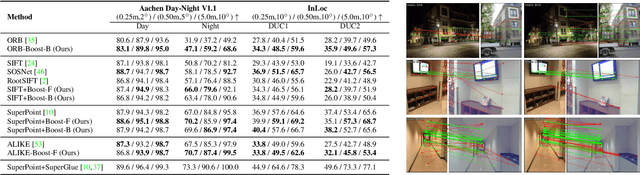
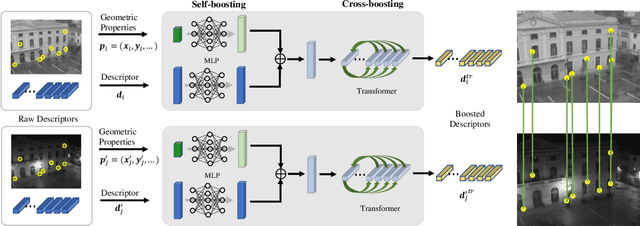
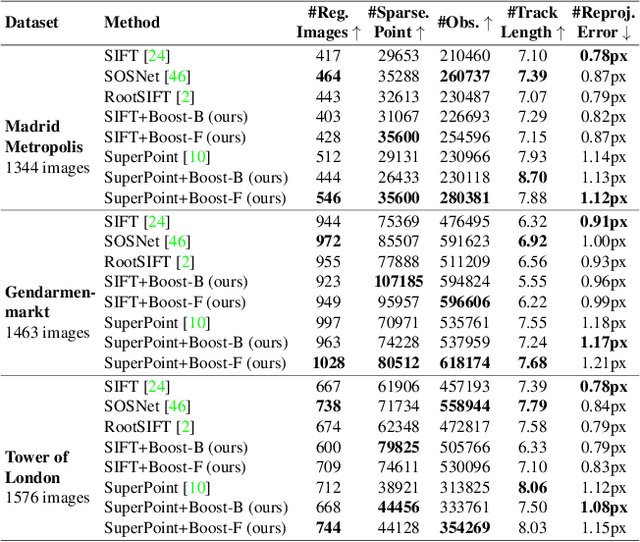
We introduce a lightweight network to improve descriptors of keypoints within the same image. The network takes the original descriptors and the geometric properties of keypoints as the input, and uses an MLP-based self-boosting stage and a Transformer-based cross-boosting stage to enhance the descriptors. The enhanced descriptors can be either real-valued or binary ones. We use the proposed network to boost both hand-crafted (ORB, SIFT) and the state-of-the-art learning-based descriptors (SuperPoint, ALIKE) and evaluate them on image matching, visual localization, and structure-from-motion tasks. The results show that our method significantly improves the performance of each task, particularly in challenging cases such as large illumination changes or repetitive patterns. Our method requires only 3.2ms on desktop GPU and 27ms on embedded GPU to process 2000 features, which is fast enough to be applied to a practical system.
Meta-DETR: Image-Level Few-Shot Detection with Inter-Class Correlation Exploitation
Jul 30, 2022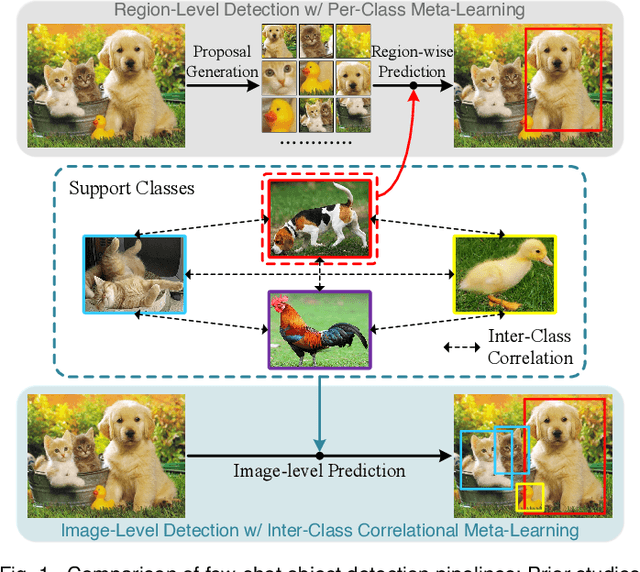
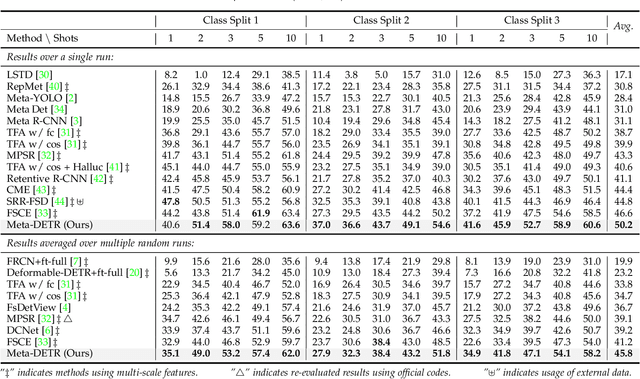
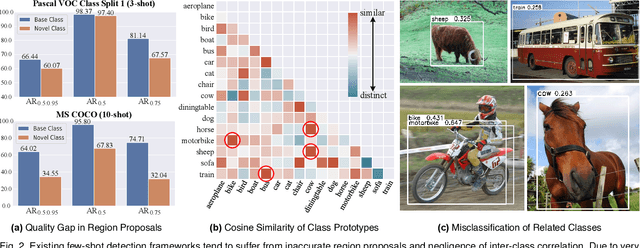
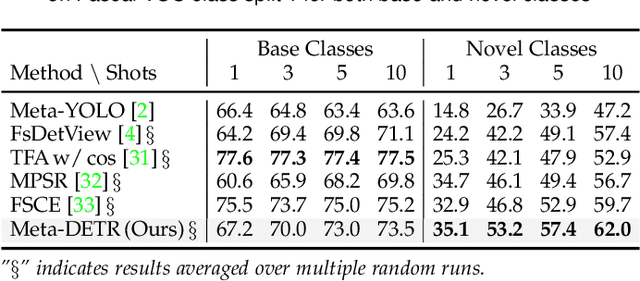
Few-shot object detection has been extensively investigated by incorporating meta-learning into region-based detection frameworks. Despite its success, the said paradigm is still constrained by several factors, such as (i) low-quality region proposals for novel classes and (ii) negligence of the inter-class correlation among different classes. Such limitations hinder the generalization of base-class knowledge for the detection of novel-class objects. In this work, we design Meta-DETR, which (i) is the first image-level few-shot detector, and (ii) introduces a novel inter-class correlational meta-learning strategy to capture and leverage the correlation among different classes for robust and accurate few-shot object detection. Meta-DETR works entirely at image level without any region proposals, which circumvents the constraint of inaccurate proposals in prevalent few-shot detection frameworks. In addition, the introduced correlational meta-learning enables Meta-DETR to simultaneously attend to multiple support classes within a single feedforward, which allows to capture the inter-class correlation among different classes, thus significantly reducing the misclassification over similar classes and enhancing knowledge generalization to novel classes. Experiments over multiple few-shot object detection benchmarks show that the proposed Meta-DETR outperforms state-of-the-art methods by large margins. The implementation codes are available at https://github.com/ZhangGongjie/Meta-DETR.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022

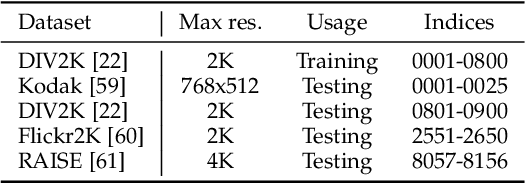
Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.
Learning to Model Multimodal Semantic Alignment for Story Visualization
Nov 14, 2022
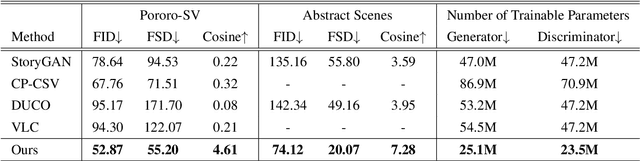

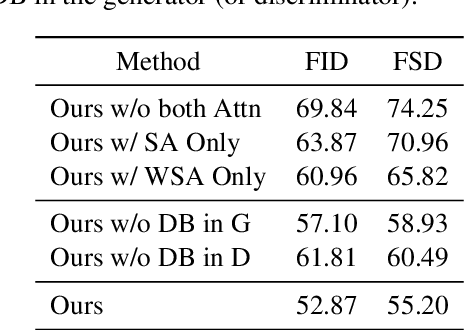
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story, where the images should be realistic and keep global consistency across dynamic scenes and characters. Current works face the problem of semantic misalignment because of their fixed architecture and diversity of input modalities. To address this problem, we explore the semantic alignment between text and image representations by learning to match their semantic levels in the GAN-based generative model. More specifically, we introduce dynamic interactions according to learning to dynamically explore various semantic depths and fuse the different-modal information at a matched semantic level, which thus relieves the text-image semantic misalignment problem. Extensive experiments on different datasets demonstrate the improvements of our approach, neither using segmentation masks nor auxiliary captioning networks, on image quality and story consistency, compared with state-of-the-art methods.
Rethinking Label Smoothing on Multi-hop Question Answering
Dec 19, 2022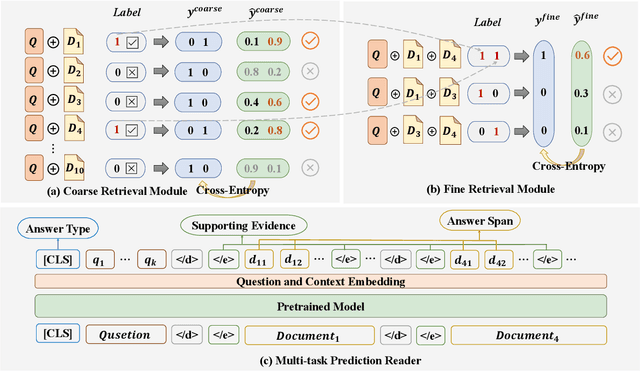
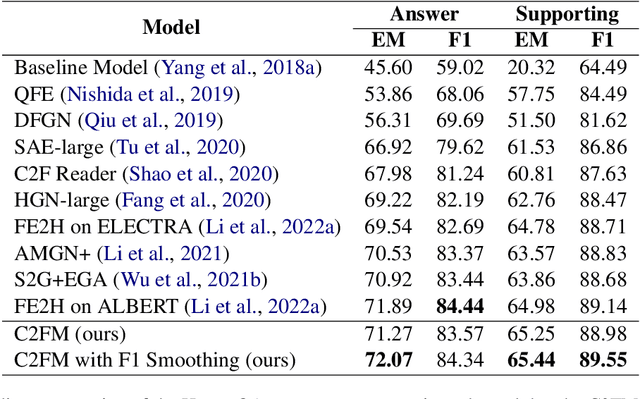
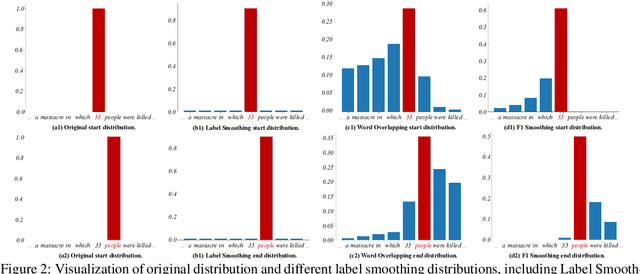
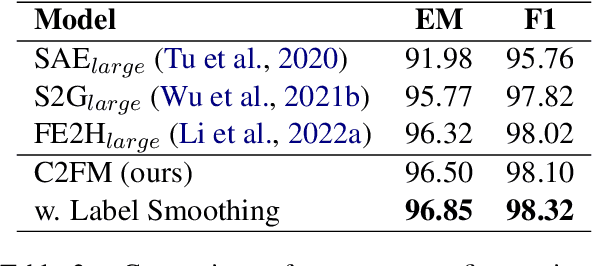
Label smoothing is a regularization technique widely used in supervised learning to improve the generalization of models on various tasks, such as image classification and machine translation. However, the effectiveness of label smoothing in multi-hop question answering (MHQA) has yet to be well studied. In this paper, we systematically analyze the role of label smoothing on various modules of MHQA and propose F1 smoothing, a novel label smoothing technique specifically designed for machine reading comprehension (MRC) tasks. We evaluate our method on the HotpotQA dataset and demonstrate its superiority over several strong baselines, including models that utilize complex attention mechanisms. Our results suggest that label smoothing can be effective in MHQA, but the choice of smoothing strategy can significantly affect performance.
MLC at HECKTOR 2022: The Effect and Importance of Training Data when Analyzing Cases of Head and Neck Tumors using Machine Learning
Nov 30, 2022
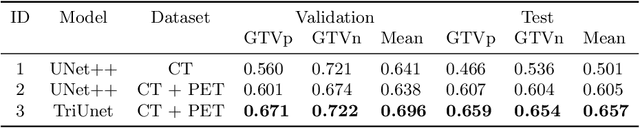
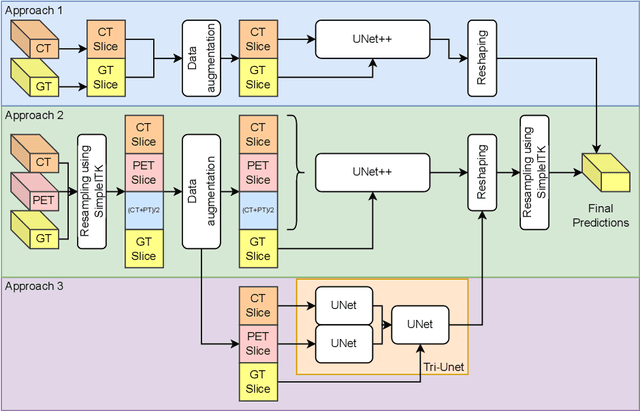

Head and neck cancers are the fifth most common cancer worldwide, and recently, analysis of Positron Emission Tomography (PET) and Computed Tomography (CT) images has been proposed to identify patients with a prognosis. Even though the results look promising, more research is needed to further validate and improve the results. This paper presents the work done by team MLC for the 2022 version of the HECKTOR grand challenge held at MICCAI 2022. For Task 1, the automatic segmentation task, our approach was, in contrast to earlier solutions using 3D segmentation, to keep it as simple as possible using a 2D model, analyzing every slice as a standalone image. In addition, we were interested in understanding how different modalities influence the results. We proposed two approaches; one using only the CT scans to make predictions and another using a combination of the CT and PET scans. For Task 2, the prediction of recurrence-free survival, we first proposed two approaches, one where we only use patient data and one where we combined the patient data with segmentations from the image model. For the prediction of the first two approaches, we used Random Forest. In our third approach, we combined patient data and image data using XGBoost. Low kidney function might worsen cancer prognosis. In this approach, we therefore estimated the kidney function of the patients and included it as a feature. Overall, we conclude that our simple methods were not able to compete with the highest-ranking submissions, but we still obtained reasonably good scores. We also got interesting insights into how the combination of different modalities can influence the segmentation and predictions.
Knowledge Distillation based Degradation Estimation for Blind Super-Resolution
Nov 30, 2022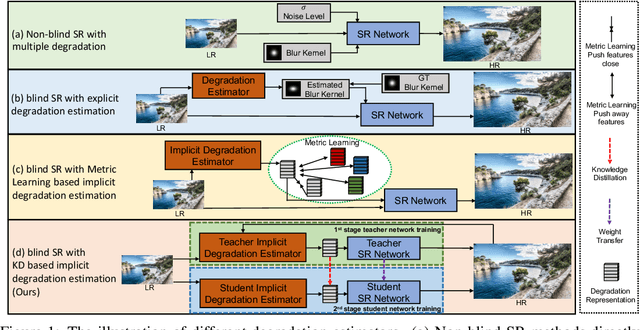
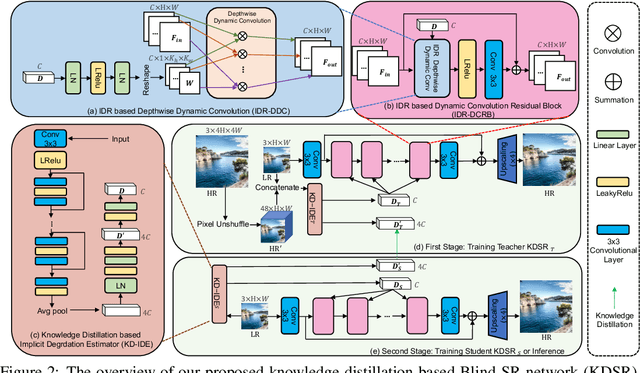
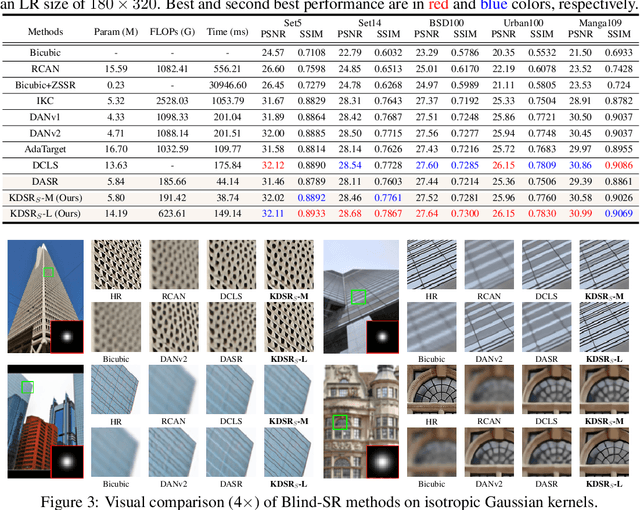
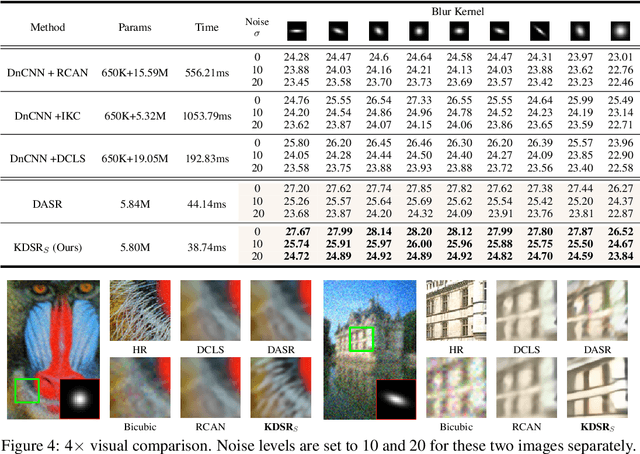
Blind image super-resolution (Blind-SR) aims to recover a high-resolution (HR) image from its corresponding low-resolution (LR) input image with unknown degradations. Most of the existing works design an explicit degradation estimator for each degradation to guide SR. However, it is infeasible to provide concrete labels of multiple degradation combinations (\eg, blur, noise, jpeg compression) to supervise the degradation estimator training. In addition, these special designs for certain degradation, such as blur, impedes the models from being generalized to handle different degradations. To this end, it is necessary to design an implicit degradation estimator that can extract discriminative degradation representation for all degradations without relying on the supervision of degradation ground-truth. In this paper, we propose a Knowledge Distillation based Blind-SR network (KDSR). It consists of a knowledge distillation based implicit degradation estimator network (KD-IDE) and an efficient SR network. To learn the KDSR model, we first train a teacher network: KD-IDE$_{T}$. It takes paired HR and LR patches as inputs and is optimized with the SR network jointly. Then, we further train a student network KD-IDE$_{S}$, which only takes LR images as input and learns to extract the same implicit degradation representation (IDR) as KD-IDE$_{T}$. In addition, to fully use extracted IDR, we design a simple, strong, and efficient IDR based dynamic convolution residual block (IDR-DCRB) to build an SR network. We conduct extensive experiments under classic and real-world degradation settings. The results show that KDSR achieves SOTA performance and can generalize to various degradation processes. The source codes and pre-trained models will be released.
Semantic Interleaving Global Channel Attention for Multilabel Remote Sensing Image Classification
Aug 04, 2022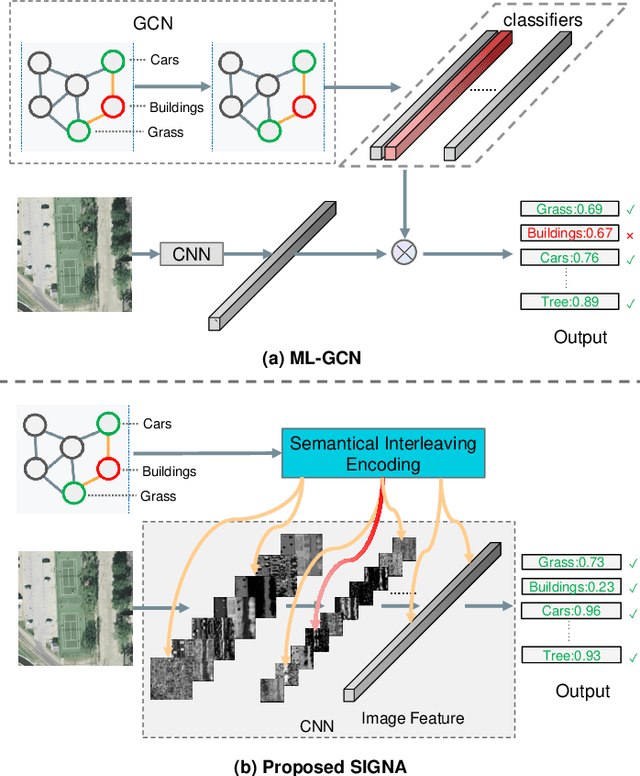
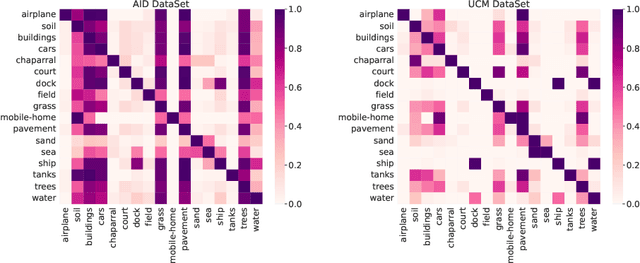
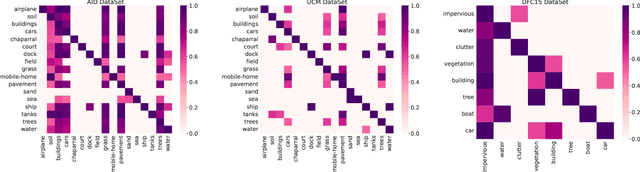
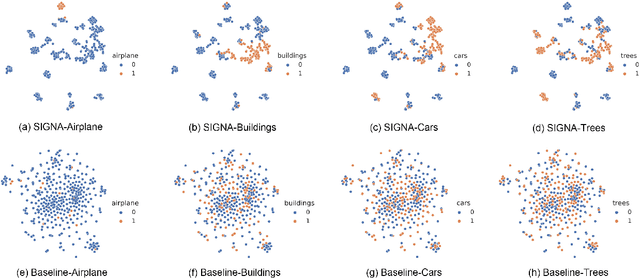
Multi-Label Remote Sensing Image Classification (MLRSIC) has received increasing research interest. Taking the cooccurrence relationship of multiple labels as additional information helps to improve the performance of this task. Current methods focus on using it to constrain the final feature output of a Convolutional Neural Network (CNN). On the one hand, these methods do not make full use of label correlation to form feature representation. On the other hand, they increase the label noise sensitivity of the system, resulting in poor robustness. In this paper, a novel method called Semantic Interleaving Global Channel Attention (SIGNA) is proposed for MLRSIC. First, the label co-occurrence graph is obtained according to the statistical information of the data set. The label co-occurrence graph is used as the input of the Graph Neural Network (GNN) to generate optimal feature representations. Then, the semantic features and visual features are interleaved, to guide the feature expression of the image from the original feature space to the semantic feature space with embedded label relations. SIGNA triggers global attention of feature maps channels in a new semantic feature space to extract more important visual features. Multihead SIGNA based feature adaptive weighting networks are proposed to act on any layer of CNN in a plug-and-play manner. For remote sensing images, better classification performance can be achieved by inserting CNN into the shallow layer. We conduct extensive experimental comparisons on three data sets: UCM data set, AID data set, and DFC15 data set. Experimental results demonstrate that the proposed SIGNA achieves superior classification performance compared to state-of-the-art (SOTA) methods. It is worth mentioning that the codes of this paper will be open to the community for reproducibility research. Our codes are available at https://github.com/kyle-one/SIGNA.
Detect Only What You Specify : Object Detection with Linguistic Target
Nov 18, 2022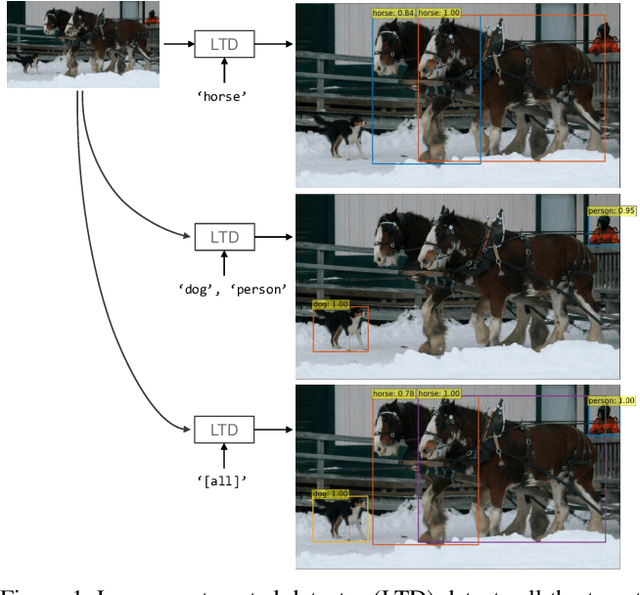
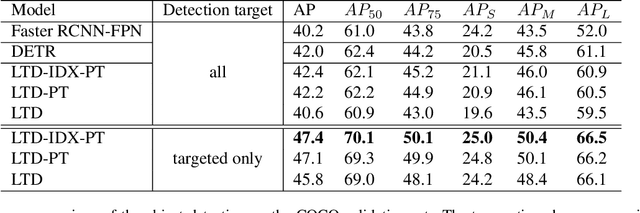
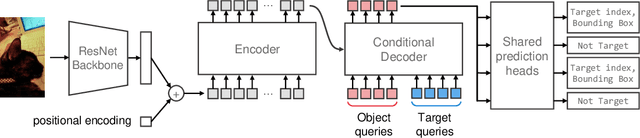

Object detection is a computer vision task of predicting a set of bounding boxes and category labels for each object of interest in a given image. The category is related to a linguistic symbol such as 'dog' or 'person' and there should be relationships among them. However the object detector only learns to classify the categories and does not treat them as the linguistic symbols. Multi-modal models often use the pre-trained object detector to extract object features from the image, but the models are separated from the detector and the extracted visual features does not change with their linguistic input. We rethink the object detection as a vision-and-language reasoning task. We then propose targeted detection task, where detection targets are given by a natural language and the goal of the task is to detect only all the target objects in a given image. There are no detection if the target is not given. Commonly used modern object detectors have many hand-designed components like anchor and it is difficult to fuse the textual inputs into the complex pipeline. We thus propose Language-Targeted Detector (LTD) for the targeted detection based on a recently proposed Transformer-based detector. LTD is a encoder-decoder architecture and our conditional decoder allows the model to reason about the encoded image with the textual input as the linguistic context. We evaluate detection performances of LTD on COCO object detection dataset and also show that our model improves the detection results with the textual input grounding to the visual object.