 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the "Impracticality" of RAG: Proposing a Real-World Benchmark and Multi-Dimensional Diagnostic Framework
Apr 03, 2026Performance evaluation of Retrieval-Augmented Generation (RAG) systems within enterprise environments is governed by multi-dimensional and composite factors extending far beyond simple final accuracy checks. These factors include reasoning complexity, retrieval difficulty, the diverse structure of documents, and stringent requirements for operational explainability. Existing academic benchmarks fail to systematically diagnose these interlocking challenges, resulting in a critical gap where models achieving high performance scores fail to meet the expected reliability in practical deployment. To bridge this discrepancy, this research proposes a multi-dimensional diagnostic framework by defining a four-axis difficulty taxonomy and integrating it into an enterprise RAG benchmark to diagnose potential system weaknesses.
RAVU: Retrieval Augmented Video Understanding with Compositional Reasoning over Graph
May 06, 2025



Comprehending long videos remains a significant challenge for Large Multi-modal Models (LMMs). Current LMMs struggle to process even minutes to hours videos due to their lack of explicit memory and retrieval mechanisms. To address this limitation, we propose RAVU (Retrieval Augmented Video Understanding), a novel framework for video understanding enhanced by retrieval with compositional reasoning over a spatio-temporal graph. We construct a graph representation of the video, capturing both spatial and temporal relationships between entities. This graph serves as a long-term memory, allowing us to track objects and their actions across time. To answer complex queries, we decompose the queries into a sequence of reasoning steps and execute these steps on the graph, retrieving relevant key information. Our approach enables more accurate understanding of long videos, particularly for queries that require multi-hop reasoning and tracking objects across frames. Our approach demonstrate superior performances with limited retrieved frames (5-10) compared with other SOTA methods and baselines on two major video QA datasets, NExT-QA and EgoSchema.
Semantic Graph Consistency: Going Beyond Patches for Regularizing Self-Supervised Vision Transformers
Jun 18, 2024



Self-supervised learning (SSL) with vision transformers (ViTs) has proven effective for representation learning as demonstrated by the impressive performance on various downstream tasks. Despite these successes, existing ViT-based SSL architectures do not fully exploit the ViT backbone, particularly the patch tokens of the ViT. In this paper, we introduce a novel Semantic Graph Consistency (SGC) module to regularize ViT-based SSL methods and leverage patch tokens effectively. We reconceptualize images as graphs, with image patches as nodes and infuse relational inductive biases by explicit message passing using Graph Neural Networks into the SSL framework. Our SGC loss acts as a regularizer, leveraging the underexploited patch tokens of ViTs to construct a graph and enforcing consistency between graph features across multiple views of an image. Extensive experiments on various datasets including ImageNet, RESISC and Food-101 show that our approach significantly improves the quality of learned representations, resulting in a 5-10\% increase in performance when limited labeled data is used for linear evaluation. These experiments coupled with a comprehensive set of ablations demonstrate the promise of our approach in various settings.
GLoD: Composing Global Contexts and Local Details in Image Generation
Apr 23, 2024



Diffusion models have demonstrated their capability to synthesize high-quality and diverse images from textual prompts. However, simultaneous control over both global contexts (e.g., object layouts and interactions) and local details (e.g., colors and emotions) still remains a significant challenge. The models often fail to understand complex descriptions involving multiple objects and reflect specified visual attributes to wrong targets or ignore them. This paper presents Global-Local Diffusion (\textit{GLoD}), a novel framework which allows simultaneous control over the global contexts and the local details in text-to-image generation without requiring training or fine-tuning. It assigns multiple global and local prompts to corresponding layers and composes their noises to guide a denoising process using pre-trained diffusion models. Our framework enables complex global-local compositions, conditioning objects in the global prompt with the local prompts while preserving other unspecified identities. Our quantitative and qualitative evaluations demonstrate that GLoD effectively generates complex images that adhere to both user-provided object interactions and object details.
D3: Data Diversity Design for Systematic Generalization in Visual Question Answering
Sep 15, 2023



Systematic generalization is a crucial aspect of intelligence, which refers to the ability to generalize to novel tasks by combining known subtasks and concepts. One critical factor that has been shown to influence systematic generalization is the diversity of training data. However, diversity can be defined in various ways, as data have many factors of variation. A more granular understanding of how different aspects of data diversity affect systematic generalization is lacking. We present new evidence in the problem of Visual Question Answering (VQA) that reveals that the diversity of simple tasks (i.e. tasks formed by a few subtasks and concepts) plays a key role in achieving systematic generalization. This implies that it may not be essential to gather a large and varied number of complex tasks, which could be costly to obtain. We demonstrate that this result is independent of the similarity between the training and testing data and applies to well-known families of neural network architectures for VQA (i.e. monolithic architectures and neural module networks). Additionally, we observe that neural module networks leverage all forms of data diversity we evaluated, while monolithic architectures require more extensive amounts of data to do so. These findings provide a first step towards understanding the interactions between data diversity design, neural network architectures, and systematic generalization capabilities.
HICO-DET-SG and V-COCO-SG: New Data Splits to Evaluate Systematic Generalization in Human-Object Interaction Detection
May 17, 2023



Human-Object Interaction (HOI) detection is a task to predict interactions between humans and objects in an image. In real-world scenarios, HOI detection models are required systematic generalization, i.e., generalization to novel combinations of objects and interactions, because it is highly probable that the train data only cover a limited portion of all possible combinations. However, to our knowledge, no open benchmark or existing work evaluates the systematic generalization in HOI detection. To address this issue, we created two new sets of HOI detection data splits named HICO-DET-SG and V-COCO-SG based on HICO-DET and V-COCO datasets. We evaluated representative HOI detection models on the new data splits and observed large degradation in the test performances compared to those on the original datasets. This result shows that systematic generalization is a challenging goal in HOI detection. We hope our new data splits encourage more research toward this goal.
Detect Only What You Specify : Object Detection with Linguistic Target
Nov 18, 2022



Object detection is a computer vision task of predicting a set of bounding boxes and category labels for each object of interest in a given image. The category is related to a linguistic symbol such as 'dog' or 'person' and there should be relationships among them. However the object detector only learns to classify the categories and does not treat them as the linguistic symbols. Multi-modal models often use the pre-trained object detector to extract object features from the image, but the models are separated from the detector and the extracted visual features does not change with their linguistic input. We rethink the object detection as a vision-and-language reasoning task. We then propose targeted detection task, where detection targets are given by a natural language and the goal of the task is to detect only all the target objects in a given image. There are no detection if the target is not given. Commonly used modern object detectors have many hand-designed components like anchor and it is difficult to fuse the textual inputs into the complex pipeline. We thus propose Language-Targeted Detector (LTD) for the targeted detection based on a recently proposed Transformer-based detector. LTD is a encoder-decoder architecture and our conditional decoder allows the model to reason about the encoded image with the textual input as the linguistic context. We evaluate detection performances of LTD on COCO object detection dataset and also show that our model improves the detection results with the textual input grounding to the visual object.
Transformer Module Networks for Systematic Generalization in Visual Question Answering
Jan 27, 2022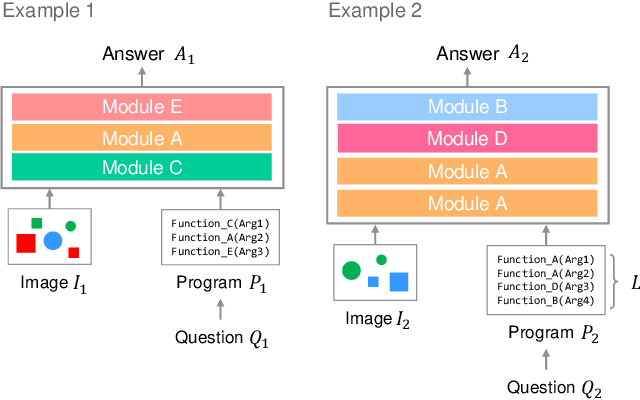
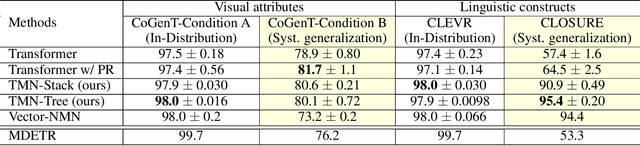
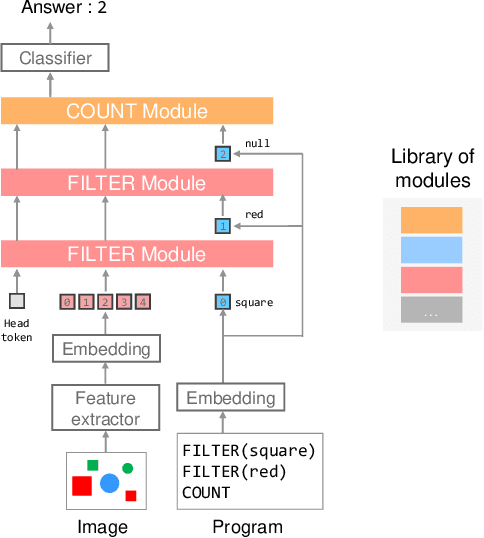

Transformer-based models achieve great performance on Visual Question Answering (VQA). However, when we evaluate them on systematic generalization, i.e., handling novel combinations of known concepts, their performance degrades. Neural Module Networks (NMNs) are a promising approach for systematic generalization that consists on composing modules, i.e., neural networks that tackle a sub-task. Inspired by Transformers and NMNs, we propose Transformer Module Network (TMN), a novel Transformer-based model for VQA that dynamically composes modules into a question-specific Transformer network. TMNs achieve state-of-the-art systematic generalization performance in three VQA datasets, namely, CLEVR-CoGenT, CLOSURE and GQA-SGL, in some cases improving more than 30% over standard Transformers.