 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging Off-the-shelf Diffusion Model for Multi-attribute Fashion Image Manipulation
Oct 12, 2022

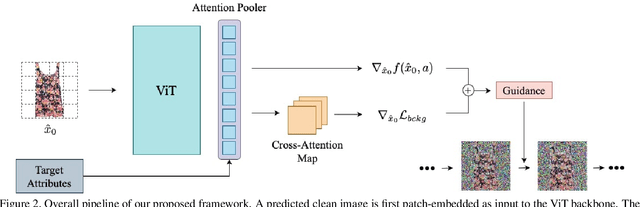
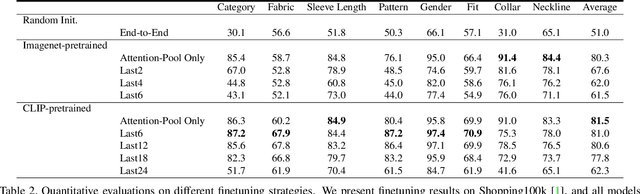
Fashion attribute editing is a task that aims to convert the semantic attributes of a given fashion image while preserving the irrelevant regions. Previous works typically employ conditional GANs where the generator explicitly learns the target attributes and directly execute the conversion. These approaches, however, are neither scalable nor generic as they operate only with few limited attributes and a separate generator is required for each dataset or attribute set. Inspired by the recent advancement of diffusion models, we explore the classifier-guided diffusion that leverages the off-the-shelf diffusion model pretrained on general visual semantics such as Imagenet. In order to achieve a generic editing pipeline, we pose this as multi-attribute image manipulation task, where the attribute ranges from item category, fabric, pattern to collar and neckline. We empirically show that conventional methods fail in our challenging setting, and study efficient adaptation scheme that involves recently introduced attention-pooling technique to obtain a multi-attribute classifier guidance. Based on this, we present a mask-free fashion attribute editing framework that leverages the classifier logits and the cross-attention map for manipulation. We empirically demonstrate that our framework achieves convincing sample quality and attribute alignments.
Learning Open-vocabulary Semantic Segmentation Models From Natural Language Supervision
Jan 22, 2023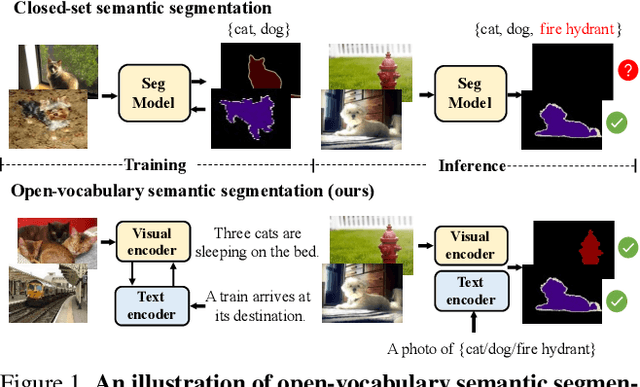
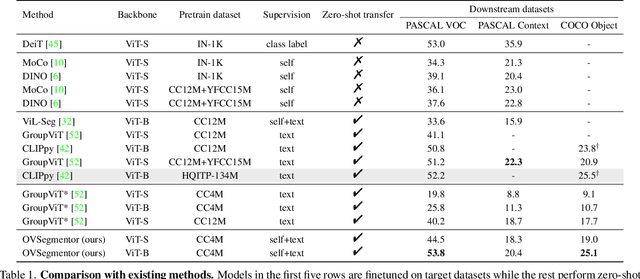
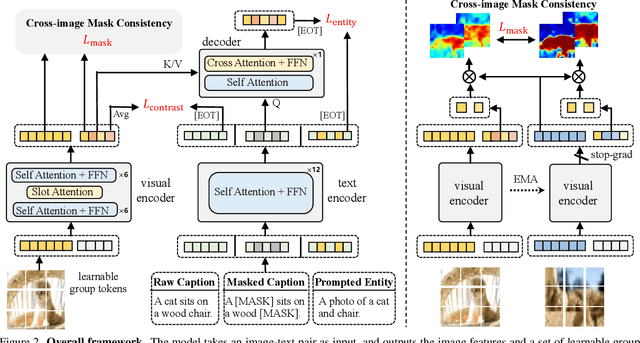
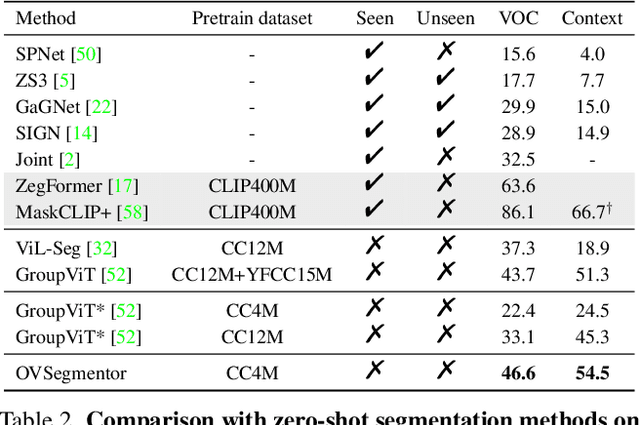
In this paper, we consider the problem of open-vocabulary semantic segmentation (OVS), which aims to segment objects of arbitrary classes instead of pre-defined, closed-set categories. The main contributions are as follows: First, we propose a transformer-based model for OVS, termed as OVSegmentor, which only exploits web-crawled image-text pairs for pre-training without using any mask annotations. OVSegmentor assembles the image pixels into a set of learnable group tokens via a slot-attention based binding module, and aligns the group tokens to the corresponding caption embedding. Second, we propose two proxy tasks for training, namely masked entity completion and cross-image mask consistency. The former aims to infer all masked entities in the caption given the group tokens, that enables the model to learn fine-grained alignment between visual groups and text entities. The latter enforces consistent mask predictions between images that contain shared entities, which encourages the model to learn visual invariance. Third, we construct CC4M dataset for pre-training by filtering CC12M with frequently appeared entities, which significantly improves training efficiency. Fourth, we perform zero-shot transfer on three benchmark datasets, PASCAL VOC 2012, PASCAL Context, and COCO Object. Our model achieves superior segmentation results over the state-of-the-art method by using only 3\% data (4M vs 134M) for pre-training. Code and pre-trained models will be released for future research.
A Survey of Fairness in Medical Image Analysis: Concepts, Algorithms, Evaluations, and Challenges
Sep 27, 2022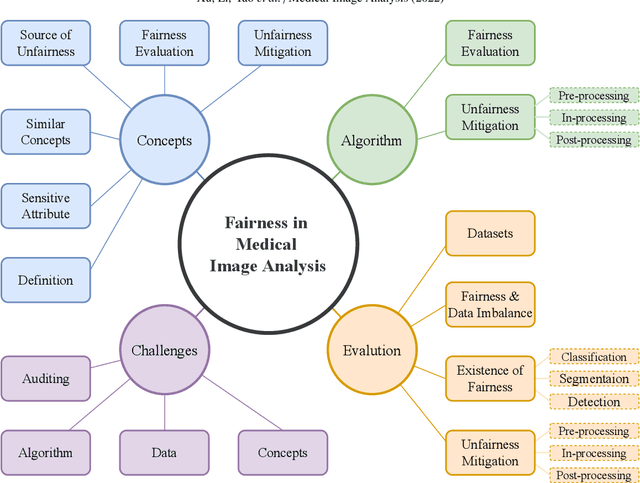

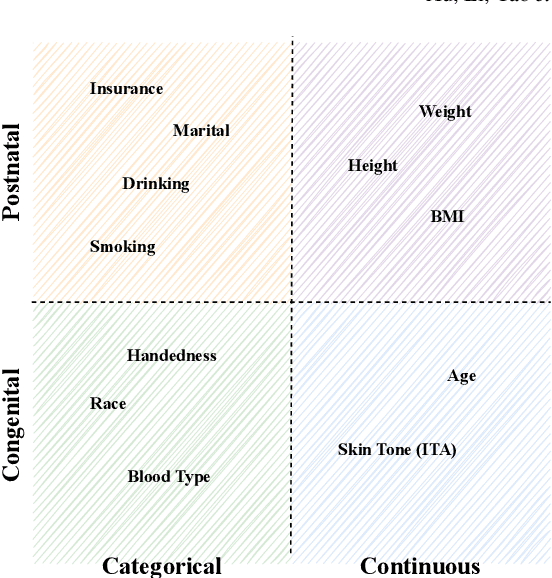
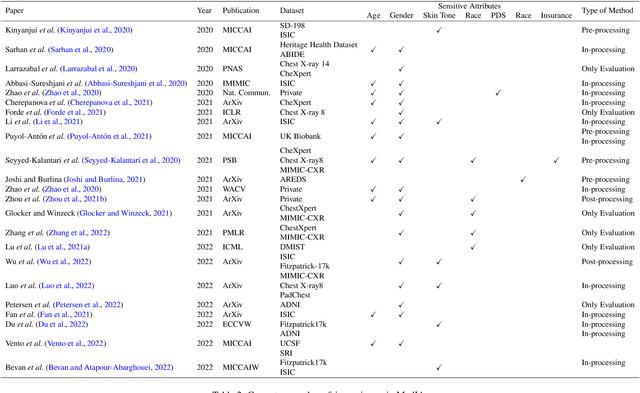
Fairness, a criterion focuses on evaluating algorithm performance on different demographic groups, has gained attention in natural language processing, recommendation system and facial recognition. Since there are plenty of demographic attributes in medical image samples, it is important to understand the concepts of fairness, be acquainted with unfairness mitigation techniques, evaluate fairness degree of an algorithm and recognize challenges in fairness issues in medical image analysis (MedIA). In this paper, we first give a comprehensive and precise definition of fairness, following by introducing currently used techniques in fairness issues in MedIA. After that, we list public medical image datasets that contain demographic attributes for facilitating the fairness research and summarize current algorithms concerning fairness in MedIA. To help achieve a better understanding of fairness, and call attention to fairness related issues in MedIA, experiments are conducted comparing the difference between fairness and data imbalance, verifying the existence of unfairness in various MedIA tasks, especially in classification, segmentation and detection, and evaluating the effectiveness of unfairness mitigation algorithms. Finally, we conclude with opportunities and challenges in fairness in MedIA.
OppLoD: the Opponency based Looming Detector, Model Extension of Looming Sensitivity from LGMD to LPLC2
Feb 10, 2023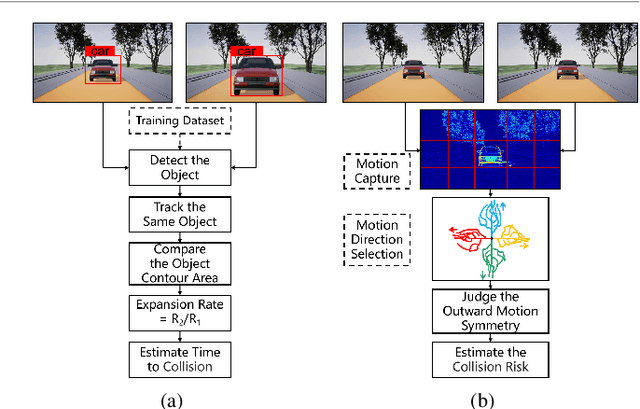
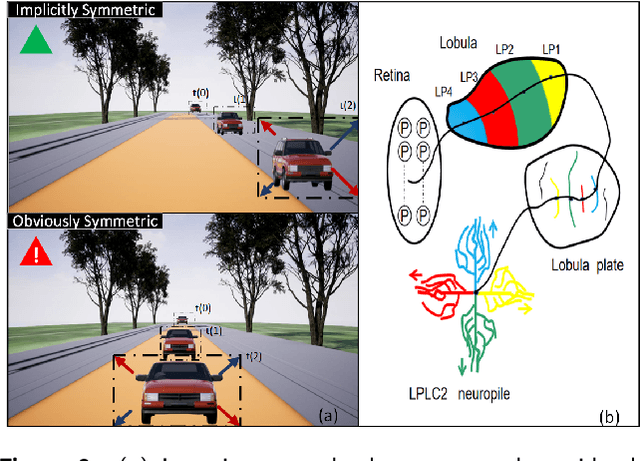
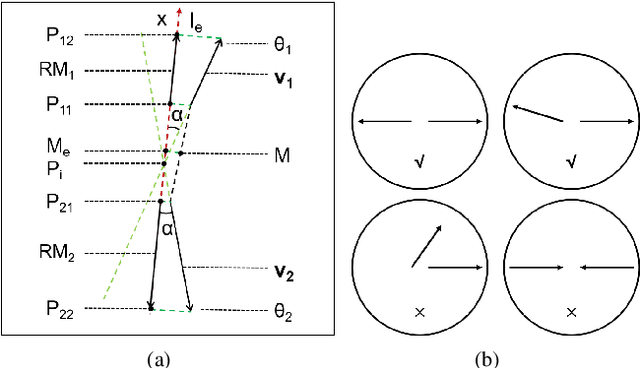
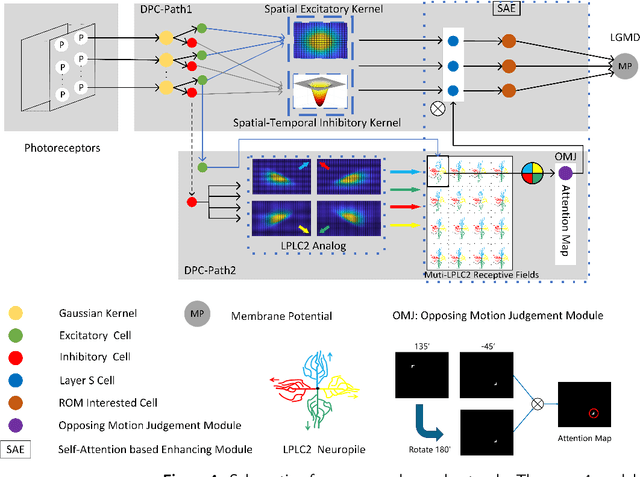
Looming detection plays an important role in insect collision prevention systems. As a vital capability evolutionary survival, it has been extensively studied in neuroscience and is attracting increasing research interest in robotics due to its close relationship with collision detection and navigation. Visual cues such as angular size, angular velocity, and expansion have been widely studied for looming detection by means of optic flow or elementary neural computing research. However, a critical visual motion cue has been long neglected because it is so easy to be confused with expansion, that is radial-opponent-motion (ROM). Recent research on the discovery of LPLC2, a ROM-sensitive neuron in Drosophila, has revealed its ultra-selectivity because it only responds to stimuli with focal, outward movement. This characteristic of ROM-sensitivity is consistent with the demand for collision detection because it is strongly associated with danger looming that is moving towards the center of the observer. Thus, we hope to extend the well-studied neural model of the lobula giant movement detector (LGMD) with ROM-sensibility in order to enhance robustness and accuracy at the same time. In this paper, we investigate the potential to extend an image velocity-based looming detector, the lobula giant movement detector (LGMD), with ROM-sensibility. To achieve this, we propose the mathematical definition of ROM and its main property, the radial motion opponency (RMO). Then, a synaptic neuropile that analogizes the synaptic processing of LPLC2 is proposed in the form of lateral inhibition and attention. Thus, our proposed model is the first to perform both image velocity selectivity and ROM sensitivity. Systematic experiments are conducted to exhibit the huge potential of the proposed bio-inspired looming detector.
DASH: Visual Analytics for Debiasing Image Classification via User-Driven Synthetic Data Augmentation
Sep 14, 2022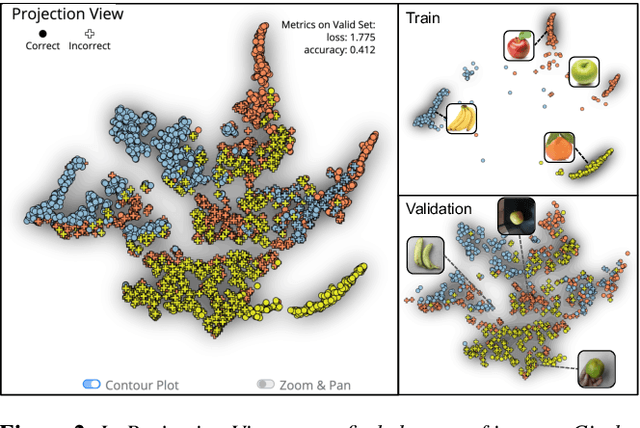
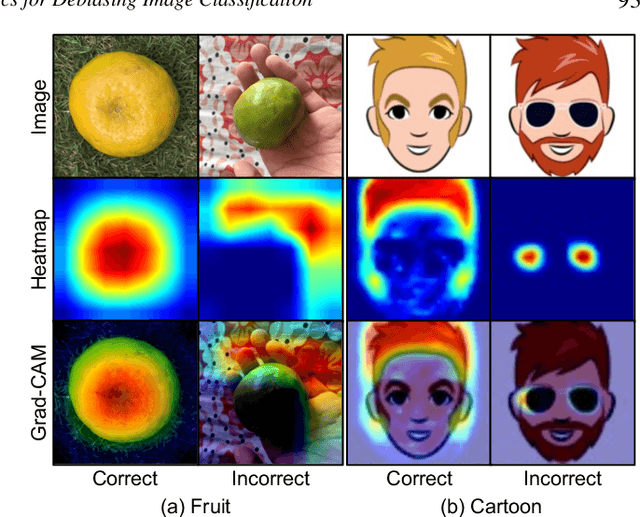
Image classification models often learn to predict a class based on irrelevant co-occurrences between input features and an output class in training data. We call the unwanted correlations "data biases," and the visual features causing data biases "bias factors." It is challenging to identify and mitigate biases automatically without human intervention. Therefore, we conducted a design study to find a human-in-the-loop solution. First, we identified user tasks that capture the bias mitigation process for image classification models with three experts. Then, to support the tasks, we developed a visual analytics system called DASH that allows users to visually identify bias factors, to iteratively generate synthetic images using a state-of-the-art image-to-image translation model, and to supervise the model training process for improving the classification accuracy. Our quantitative evaluation and qualitative study with ten participants demonstrate the usefulness of DASH and provide lessons for future work.
Medical Image Captioning via Generative Pretrained Transformers
Sep 28, 2022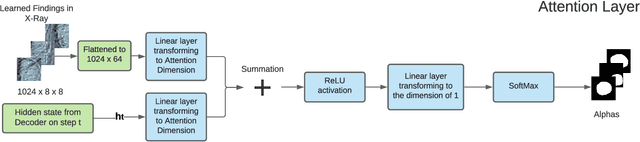
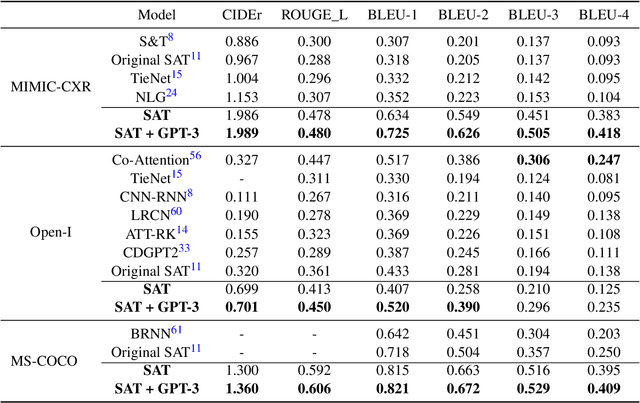
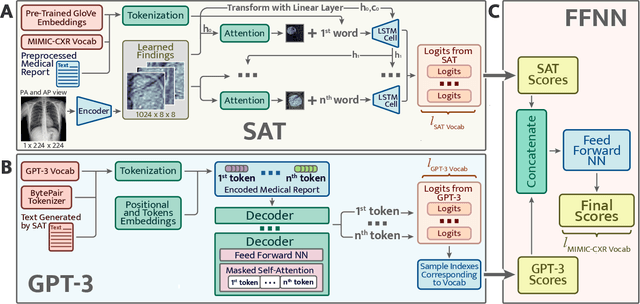
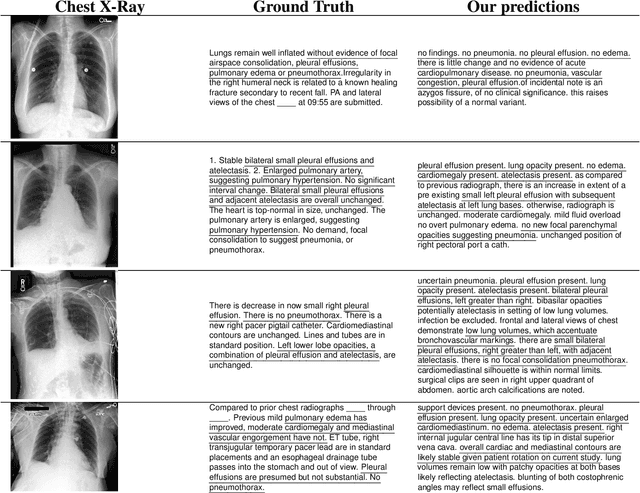
The automatic clinical caption generation problem is referred to as proposed model combining the analysis of frontal chest X-Ray scans with structured patient information from the radiology records. We combine two language models, the Show-Attend-Tell and the GPT-3, to generate comprehensive and descriptive radiology records. The proposed combination of these models generates a textual summary with the essential information about pathologies found, their location, and the 2D heatmaps localizing each pathology on the original X-Ray scans. The proposed model is tested on two medical datasets, the Open-I, MIMIC-CXR, and the general-purpose MS-COCO. The results measured with the natural language assessment metrics prove their efficient applicability to the chest X-Ray image captioning.
Zero3D: Semantic-Driven Multi-Category 3D Shape Generation
Feb 13, 2023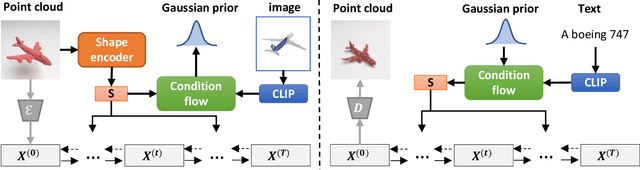
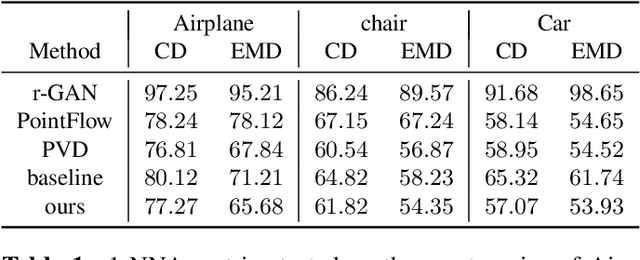
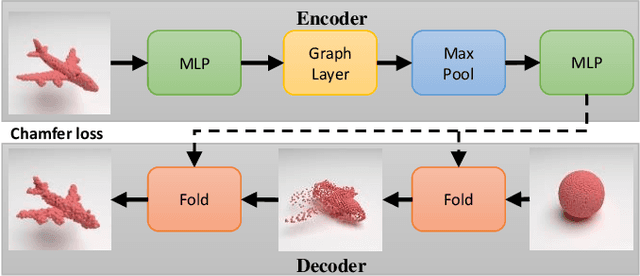
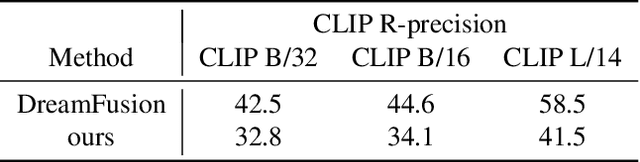
Semantic-driven 3D shape generation aims to generate 3D objects conditioned on text. Previous works face problems with single-category generation, low-frequency 3D details, and requiring a large number of paired datasets for training. To tackle these challenges, we propose a multi-category conditional diffusion model. Specifically, 1) to alleviate the problem of lack of large-scale paired data, we bridge the text, 2D image and 3D shape based on the pre-trained CLIP model, and 2) to obtain the multi-category 3D shape feature, we apply the conditional flow model to generate 3D shape vector conditioned on CLIP embedding. 3) to generate multi-category 3D shape, we employ the hidden-layer diffusion model conditioned on the multi-category shape vector, which greatly reduces the training time and memory consumption.
Histopathological Image Classification based on Self-Supervised Vision Transformer and Weak Labels
Oct 17, 2022Whole Slide Image (WSI) analysis is a powerful method to facilitate the diagnosis of cancer in tissue samples. Automating this diagnosis poses various issues, most notably caused by the immense image resolution and limited annotations. WSIs commonly exhibit resolutions of 100Kx100K pixels. Annotating cancerous areas in WSIs on the pixel level is prohibitively labor-intensive and requires a high level of expert knowledge. Multiple instance learning (MIL) alleviates the need for expensive pixel-level annotations. In MIL, learning is performed on slide-level labels, in which a pathologist provides information about whether a slide includes cancerous tissue. Here, we propose Self-ViT-MIL, a novel approach for classifying and localizing cancerous areas based on slide-level annotations, eliminating the need for pixel-wise annotated training data. Self-ViT- MIL is pre-trained in a self-supervised setting to learn rich feature representation without relying on any labels. The recent Vision Transformer (ViT) architecture builds the feature extractor of Self-ViT-MIL. For localizing cancerous regions, a MIL aggregator with global attention is utilized. To the best of our knowledge, Self-ViT- MIL is the first approach to introduce self-supervised ViTs in MIL-based WSI analysis tasks. We showcase the effectiveness of our approach on the common Camelyon16 dataset. Self-ViT-MIL surpasses existing state-of-the-art MIL-based approaches in terms of accuracy and area under the curve (AUC).
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022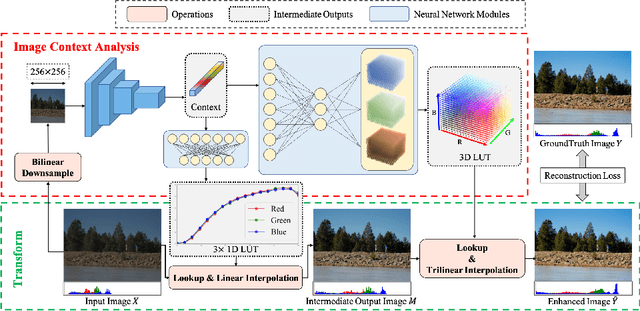
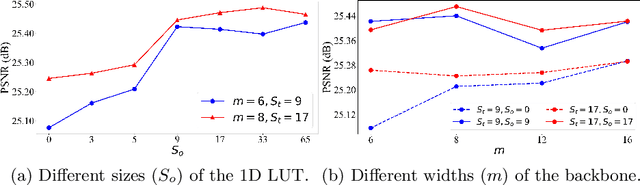
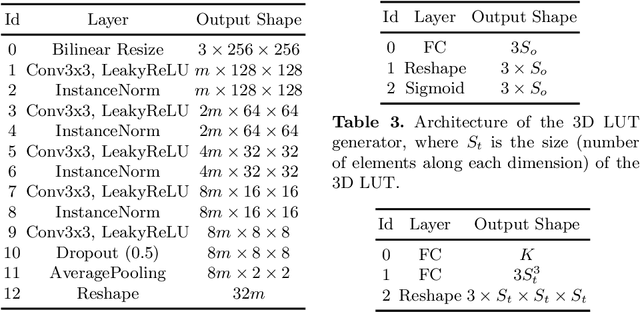
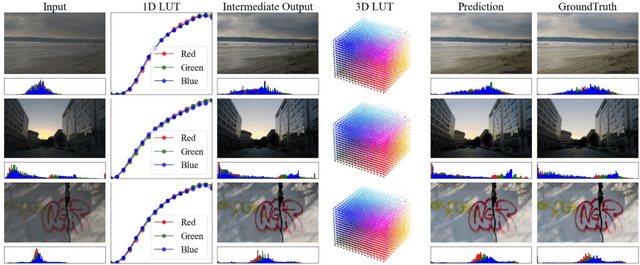
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
LC-NeRF: Local Controllable Face Generation in Neural Randiance Field
Feb 19, 2023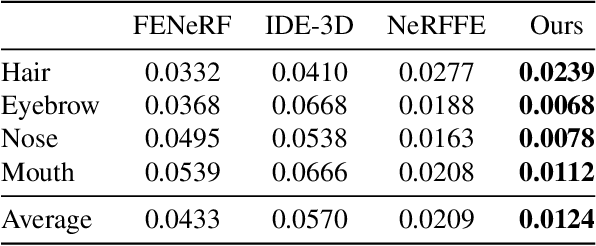
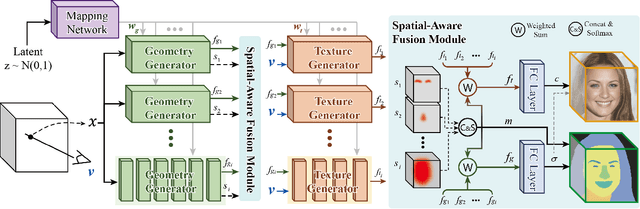
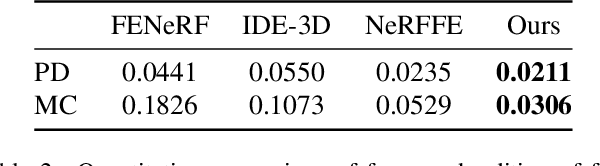

3D face generation has achieved high visual quality and 3D consistency thanks to the development of neural radiance fields (NeRF). Recently, to generate and edit 3D faces with NeRF representation, some methods are proposed and achieve good results in decoupling geometry and texture. The latent codes of these generative models affect the whole face, and hence modifications to these codes cause the entire face to change. However, users usually edit a local region when editing faces and do not want other regions to be affected. Since changes to the latent code affect global generation results, these methods do not allow for fine-grained control of local facial regions. To improve local controllability in NeRF-based face editing, we propose LC-NeRF, which is composed of a Local Region Generators Module and a Spatial-Aware Fusion Module, allowing for local geometry and texture control of local facial regions. Qualitative and quantitative evaluations show that our method provides better local editing than state-of-the-art face editing methods. Our method also performs well in downstream tasks, such as text-driven facial image editing.