 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image Captioning via Generative Pretrained Transformers
Sep 28, 2022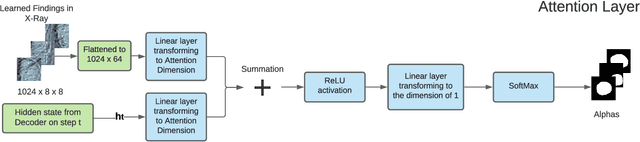
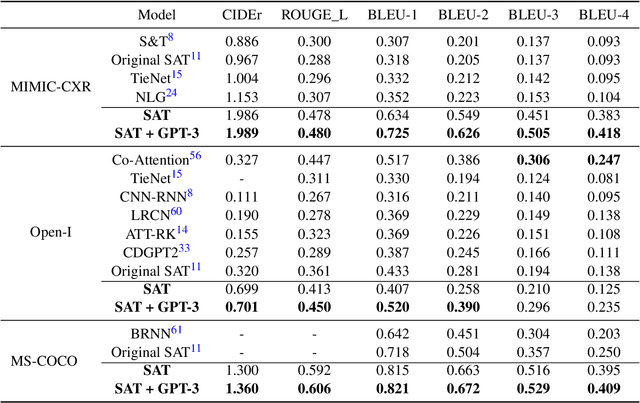
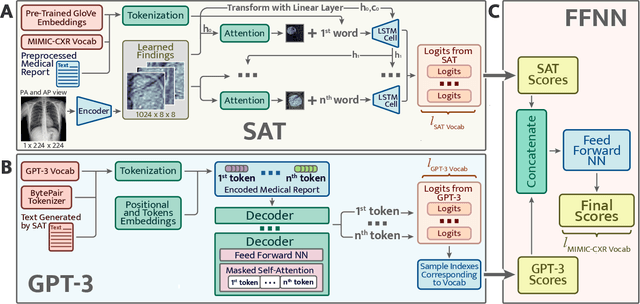
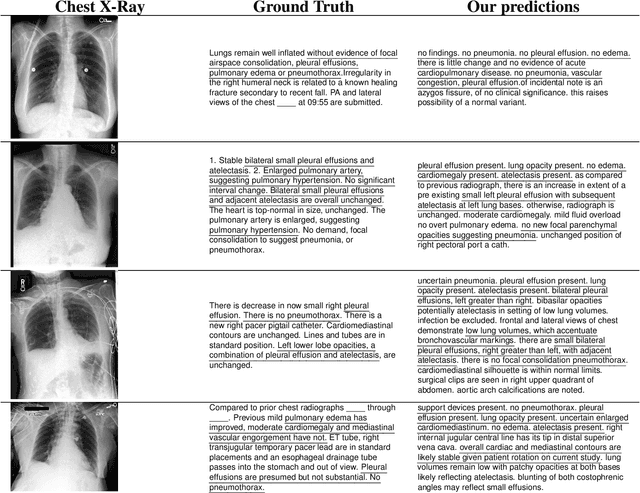
The automatic clinical caption generation problem is referred to as proposed model combining the analysis of frontal chest X-Ray scans with structured patient information from the radiology records. We combine two language models, the Show-Attend-Tell and the GPT-3, to generate comprehensive and descriptive radiology records. The proposed combination of these models generates a textual summary with the essential information about pathologies found, their location, and the 2D heatmaps localizing each pathology on the original X-Ray scans. The proposed model is tested on two medical datasets, the Open-I, MIMIC-CXR, and the general-purpose MS-COCO. The results measured with the natural language assessment metrics prove their efficient applicability to the chest X-Ray image captioning.
RuCLIP -- new models and experiments: a technical report
Feb 22, 2022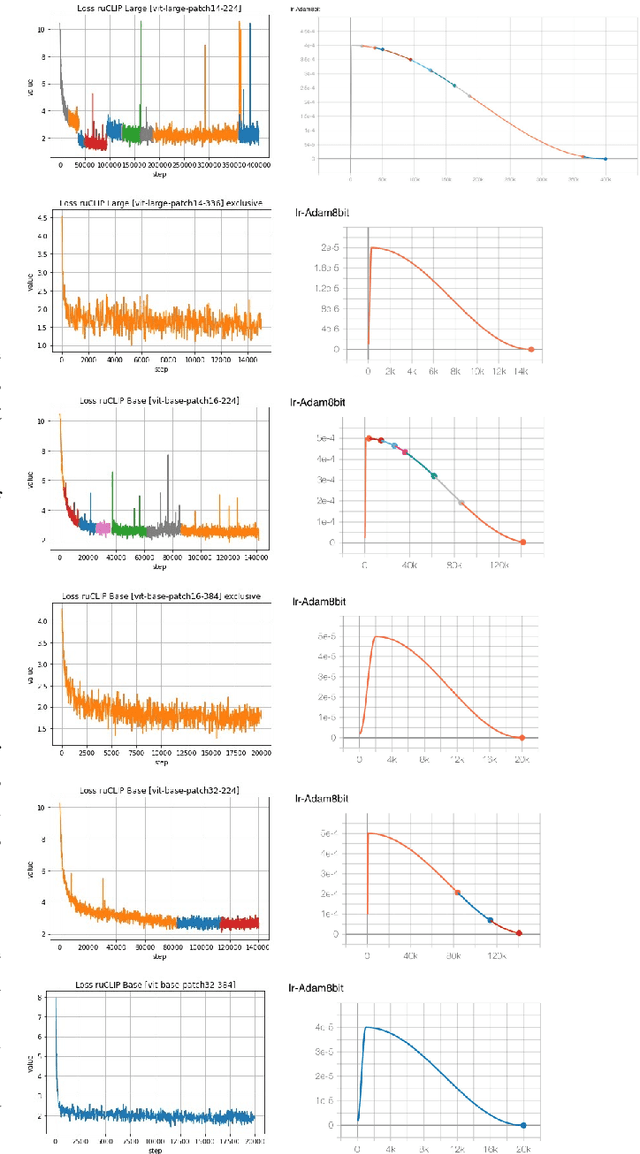
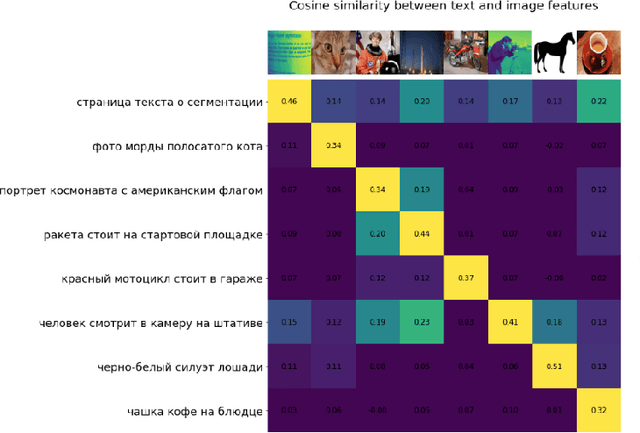
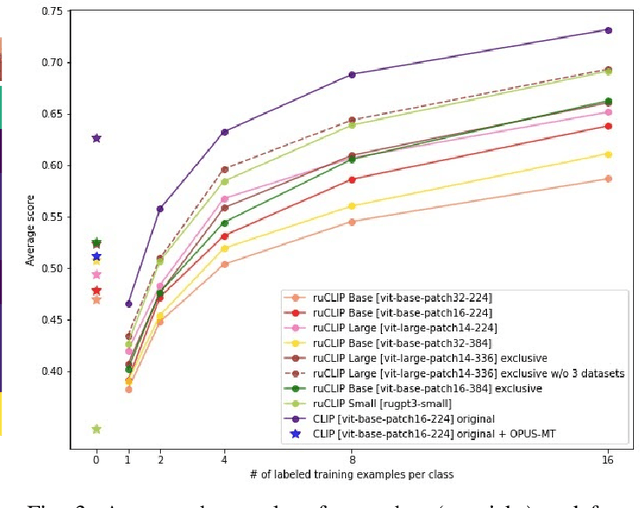
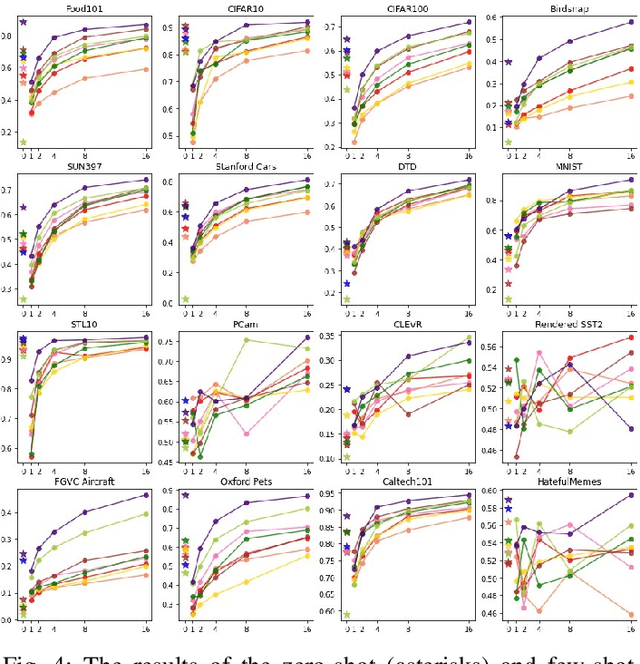
In the report we propose six new implementations of ruCLIP model trained on our 240M pairs. The accuracy results are compared with original CLIP model with Ru-En translation (OPUS-MT) on 16 datasets from different domains. Our best implementations outperform CLIP + OPUS-MT solution on most of the datasets in few-show and zero-shot tasks. In the report we briefly describe the implementations and concentrate on the conducted experiments. Inference execution time comparison is also presented in the report.
A new face swap method for image and video domains: a technical report
Feb 07, 2022



Deep fake technology became a hot field of research in the last few years. Researchers investigate sophisticated Generative Adversarial Networks (GAN), autoencoders, and other approaches to establish precise and robust algorithms for face swapping. Achieved results show that the deep fake unsupervised synthesis task has problems in terms of the visual quality of generated data. These problems usually lead to high fake detection accuracy when an expert analyzes them. The first problem is that existing image-to-image approaches do not consider video domain specificity and frame-by-frame processing leads to face jittering and other clearly visible distortions. Another problem is the generated data resolution, which is low for many existing methods due to high computational complexity. The third problem appears when the source face has larger proportions (like bigger cheeks), and after replacement it becomes visible on the face border. Our main goal was to develop such an approach that could solve these problems and outperform existing solutions on a number of clue metrics. We introduce a new face swap pipeline that is based on FaceShifter architecture and fixes the problems stated above. With a new eye loss function, super-resolution block, and Gaussian-based face mask generation leads to improvements in quality which is confirmed during evaluation.