 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Dual-branch Self-supervised Representation Learning Framework for Tumour Segmentation in Whole Slide Images
Mar 20, 2023
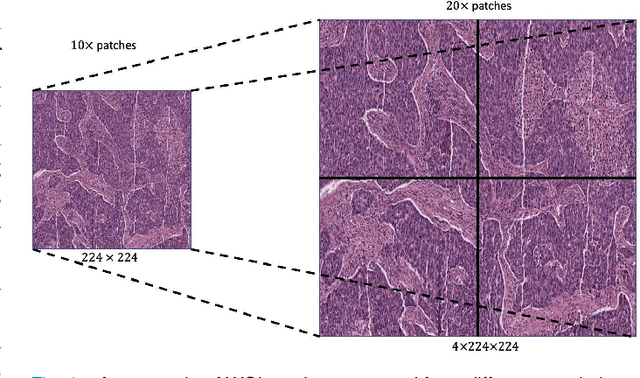
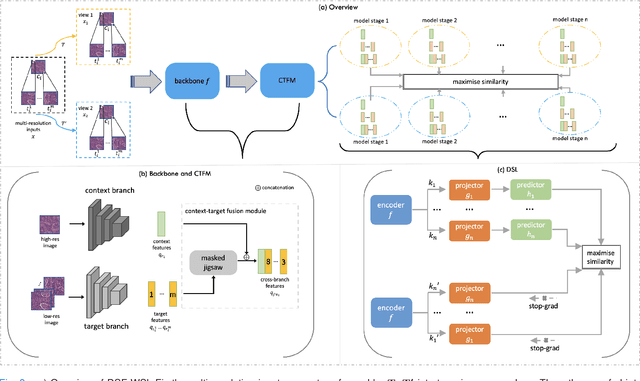
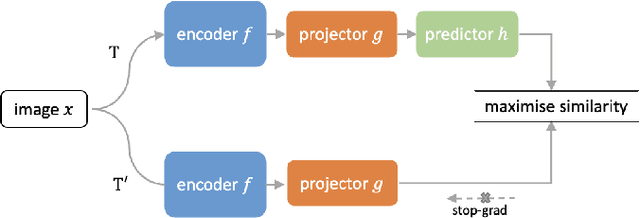
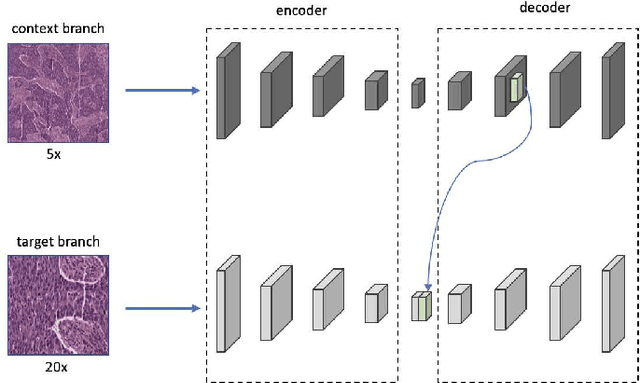
Supervised deep learning methods have achieved considerable success in medical image analysis, owing to the availability of large-scale and well-annotated datasets. However, creating such datasets for whole slide images (WSIs) in histopathology is a challenging task due to their gigapixel size. In recent years, self-supervised learning (SSL) has emerged as an alternative solution to reduce the annotation overheads in WSIs, as it does not require labels for training. These SSL approaches, however, are not designed for handling multi-resolution WSIs, which limits their performance in learning discriminative image features. In this paper, we propose a Dual-branch SSL Framework for WSI tumour segmentation (DSF-WSI) that can effectively learn image features from multi-resolution WSIs. Our DSF-WSI connected two branches and jointly learnt low and high resolution WSIs in a self-supervised manner. Moreover, we introduced a novel Context-Target Fusion Module (CTFM) and a masked jigsaw pretext task to align the learnt multi-resolution features. Furthermore, we designed a Dense SimSiam Learning (DSL) strategy to maximise the similarity of different views of WSIs, enabling the learnt representations to be more efficient and discriminative. We evaluated our method using two public datasets on breast and liver cancer segmentation tasks. The experiment results demonstrated that our DSF-WSI can effectively extract robust and efficient representations, which we validated through subsequent fine-tuning and semi-supervised settings. Our proposed method achieved better accuracy than other state-of-the-art approaches. Code is available at https://github.com/Dylan-H-Wang/dsf-wsi.
CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Nov 26, 2022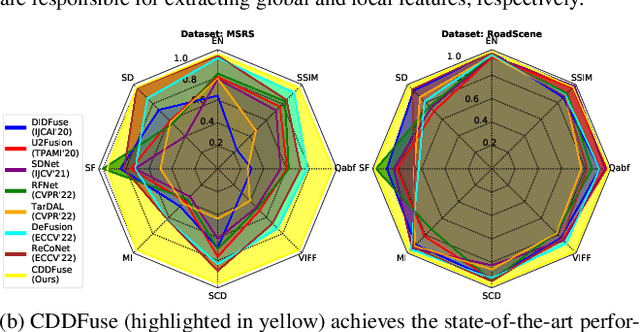
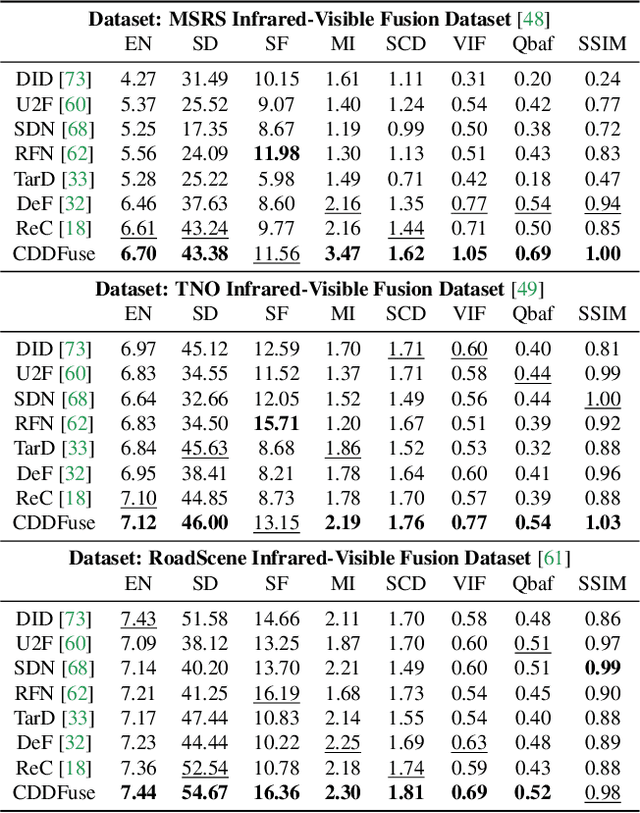
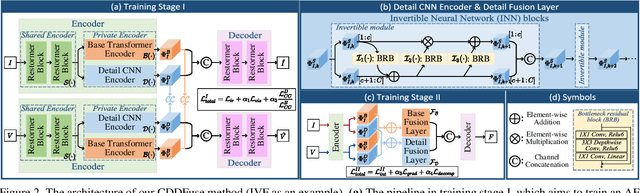
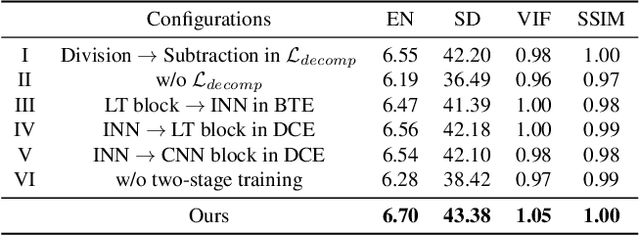
Multi-modality (MM) image fusion aims to render fused images that maintain the merits of different modalities, e.g., functional highlight and detailed textures. To tackle the challenge in modeling cross-modality features and decomposing desirable modality-specific and modality-shared features, we propose a novel Correlation-Driven feature Decomposition Fusion (CDDFuse) network for end-to-end MM feature decomposition and image fusion. In the first stage of the two-stage architectures, CDDFuse uses Restormer blocks to extract cross-modality shallow features. We then introduce a dual-branch Transformer-CNN feature extractor with Lite Transformer (LT) blocks leveraging long-range attention to handle low-frequency global features and Invertible Neural Networks (INN) blocks focusing on extracting high-frequency local information. Upon the embedded semantic information, the low-frequency features should be correlated while the high-frequency features should be uncorrelated. Thus, we propose a correlation-driven loss for better feature decomposition. In the second stage, the LT-based global fusion and INN-based local fusion layers output the fused image. Extensive experiments demonstrate that our CDDFuse achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. We also show that CDDFuse can boost the performance in downstream infrared-visible semantic segmentation and object detection in a unified benchmark.
Improving GAN Training via Feature Space Shrinkage
Mar 02, 2023
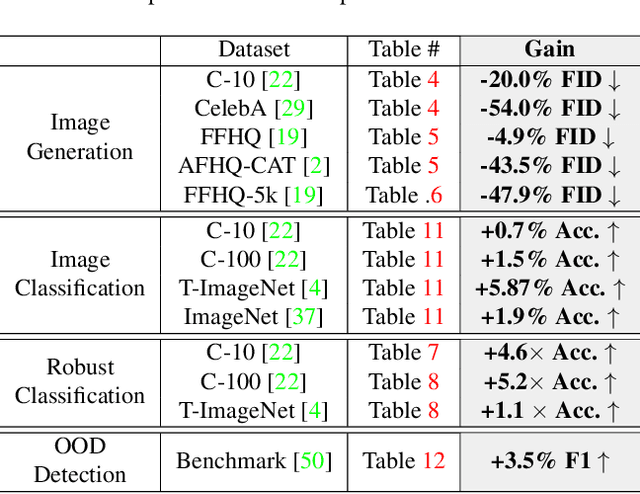
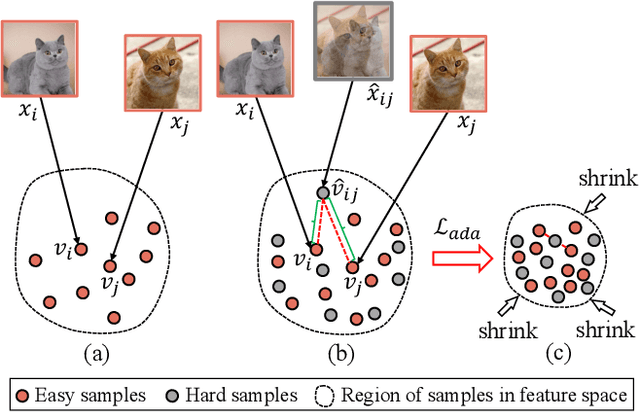

Due to the outstanding capability for data generation, Generative Adversarial Networks (GANs) have attracted considerable attention in unsupervised learning. However, training GANs is difficult, since the training distribution is dynamic for the discriminator, leading to unstable image representation. In this paper, we address the problem of training GANs from a novel perspective, \emph{i.e.,} robust image classification. Motivated by studies on robust image representation, we propose a simple yet effective module, namely AdaptiveMix, for GANs, which shrinks the regions of training data in the image representation space of the discriminator. Considering it is intractable to directly bound feature space, we propose to construct hard samples and narrow down the feature distance between hard and easy samples. The hard samples are constructed by mixing a pair of training images. We evaluate the effectiveness of our AdaptiveMix with widely-used and state-of-the-art GAN architectures. The evaluation results demonstrate that our AdaptiveMix can facilitate the training of GANs and effectively improve the image quality of generated samples. We also show that our AdaptiveMix can be further applied to image classification and Out-Of-Distribution (OOD) detection tasks, by equipping it with state-of-the-art methods. Extensive experiments on seven publicly available datasets show that our method effectively boosts the performance of baselines. The code is publicly available at https://github.com/WentianZhang-ML/AdaptiveMix.
Indescribable Multi-modal Spatial Evaluator
Mar 02, 2023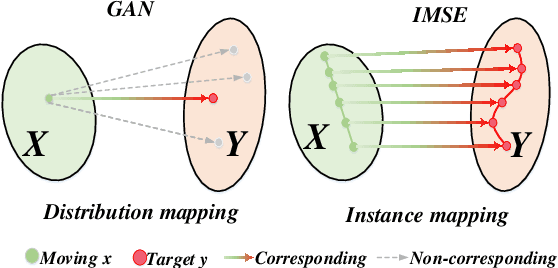

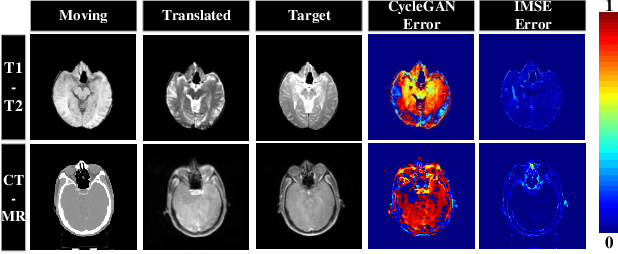
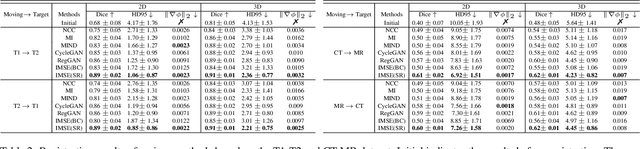
Multi-modal image registration spatially aligns two images with different distributions. One of its major challenges is that images acquired from different imaging machines have different imaging distributions, making it difficult to focus only on the spatial aspect of the images and ignore differences in distributions. In this study, we developed a self-supervised approach, Indescribable Multi-model Spatial Evaluator (IMSE), to address multi-modal image registration. IMSE creates an accurate multi-modal spatial evaluator to measure spatial differences between two images, and then optimizes registration by minimizing the error predicted of the evaluator. To optimize IMSE performance, we also proposed a new style enhancement method called Shuffle Remap which randomizes the image distribution into multiple segments, and then randomly disorders and remaps these segments, so that the distribution of the original image is changed. Shuffle Remap can help IMSE to predict the difference in spatial location from unseen target distributions. Our results show that IMSE outperformed the existing methods for registration using T1-T2 and CT-MRI datasets. IMSE also can be easily integrated into the traditional registration process, and can provide a convenient way to evaluate and visualize registration results. IMSE also has the potential to be used as a new paradigm for image-to-image translation. Our code is available at https://github.com/Kid-Liet/IMSE.
On the Importance of Contrastive Loss in Multimodal Learning
Apr 07, 2023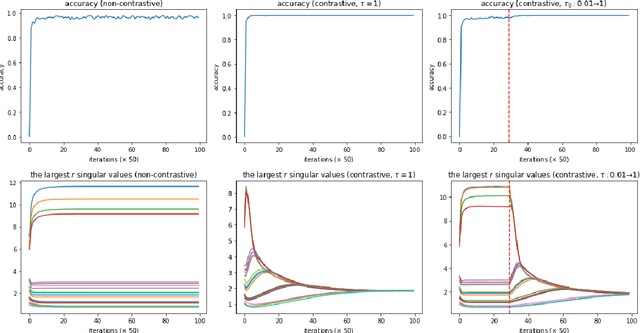
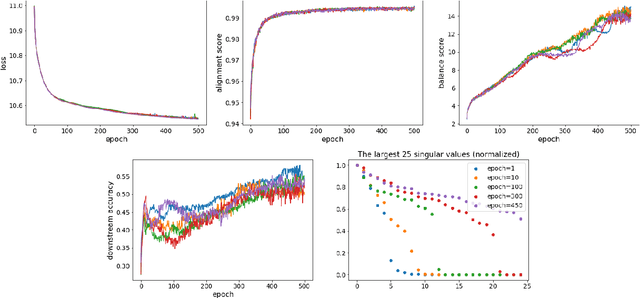
Recently, contrastive learning approaches (e.g., CLIP (Radford et al., 2021)) have received huge success in multimodal learning, where the model tries to minimize the distance between the representations of different views (e.g., image and its caption) of the same data point while keeping the representations of different data points away from each other. However, from a theoretical perspective, it is unclear how contrastive learning can learn the representations from different views efficiently, especially when the data is not isotropic. In this work, we analyze the training dynamics of a simple multimodal contrastive learning model and show that contrastive pairs are important for the model to efficiently balance the learned representations. In particular, we show that the positive pairs will drive the model to align the representations at the cost of increasing the condition number, while the negative pairs will reduce the condition number, keeping the learned representations balanced.
Renderable Neural Radiance Map for Visual Navigation
Mar 03, 2023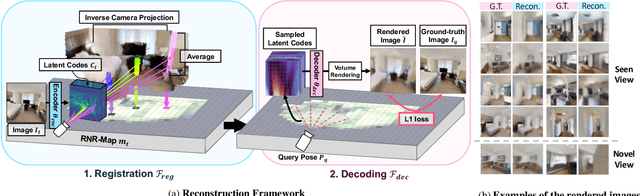
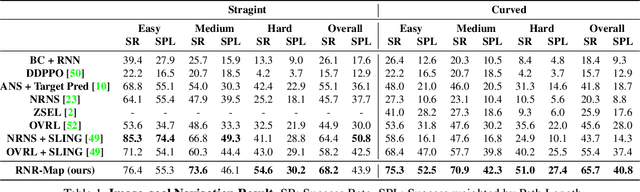
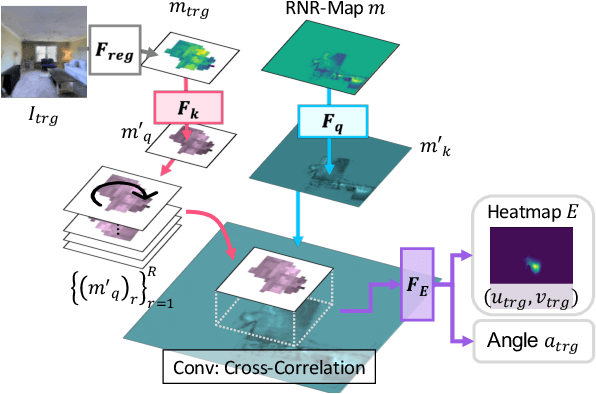
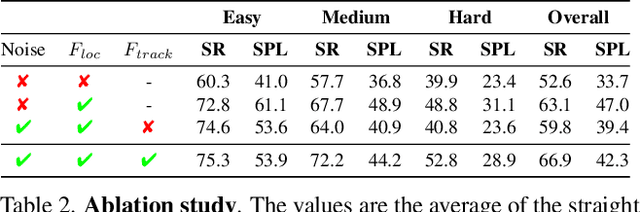
We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The navigation framework shows 65.7% success rate in curved scenarios of the NRNS dataset, which is an improvement of 18.6% over the current state-of-the-art.
OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering
Mar 26, 2023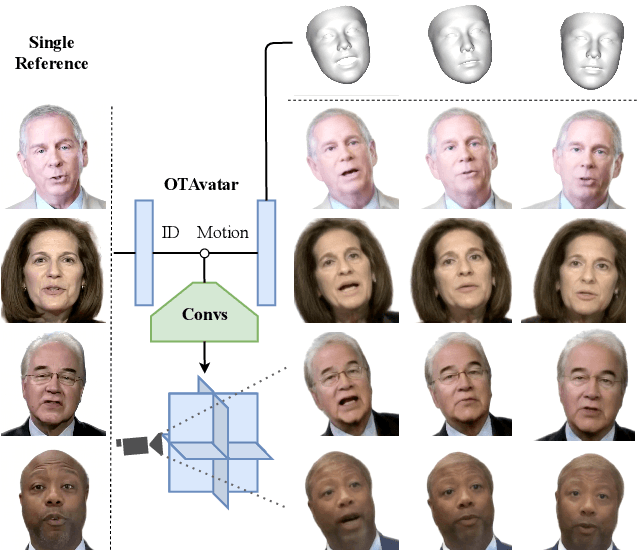

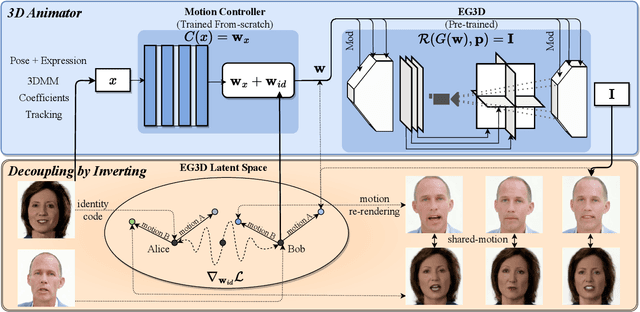

Controllability, generalizability and efficiency are the major objectives of constructing face avatars represented by neural implicit field. However, existing methods have not managed to accommodate the three requirements simultaneously. They either focus on static portraits, restricting the representation ability to a specific subject, or suffer from substantial computational cost, limiting their flexibility. In this paper, we propose One-shot Talking face Avatar (OTAvatar), which constructs face avatars by a generalized controllable tri-plane rendering solution so that each personalized avatar can be constructed from only one portrait as the reference. Specifically, OTAvatar first inverts a portrait image to a motion-free identity code. Second, the identity code and a motion code are utilized to modulate an efficient CNN to generate a tri-plane formulated volume, which encodes the subject in the desired motion. Finally, volume rendering is employed to generate an image in any view. The core of our solution is a novel decoupling-by-inverting strategy that disentangles identity and motion in the latent code via optimization-based inversion. Benefiting from the efficient tri-plane representation, we achieve controllable rendering of generalized face avatar at $35$ FPS on A100. Experiments show promising performance of cross-identity reenactment on subjects out of the training set and better 3D consistency.
Continual Learning for LiDAR Semantic Segmentation: Class-Incremental and Coarse-to-Fine strategies on Sparse Data
Apr 08, 2023

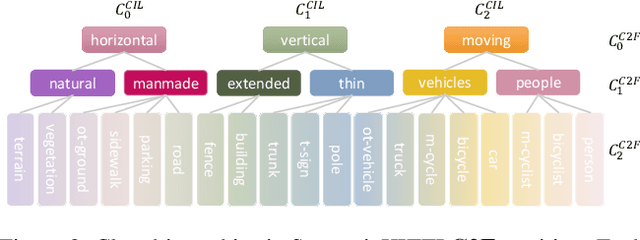
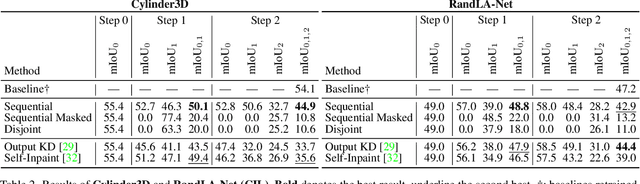
During the last few years, continual learning (CL) strategies for image classification and segmentation have been widely investigated designing innovative solutions to tackle catastrophic forgetting, like knowledge distillation and self-inpainting. However, the application of continual learning paradigms to point clouds is still unexplored and investigation is required, especially using architectures that capture the sparsity and uneven distribution of LiDAR data. The current paper analyzes the problem of class incremental learning applied to point cloud semantic segmentation, comparing approaches and state-of-the-art architectures. To the best of our knowledge, this is the first example of class-incremental continual learning for LiDAR point cloud semantic segmentation. Different CL strategies were adapted to LiDAR point clouds and tested, tackling both classic fine-tuning scenarios and the Coarse-to-Fine learning paradigm. The framework has been evaluated through two different architectures on SemanticKITTI, obtaining results in line with state-of-the-art CL strategies and standard offline learning.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023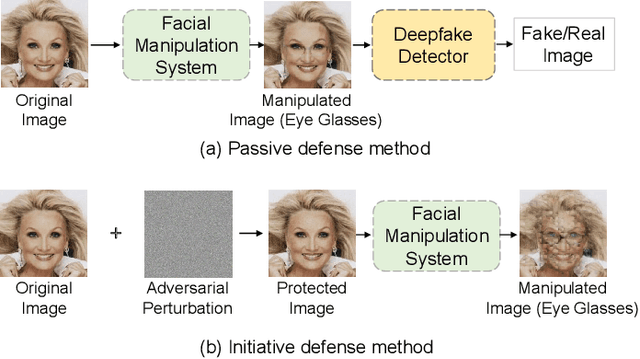
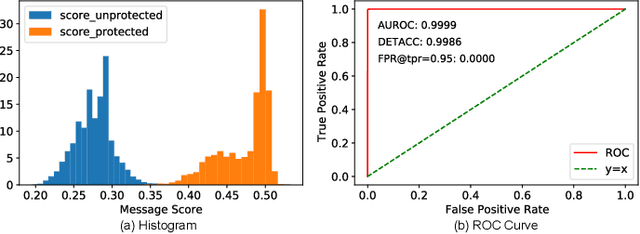


With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
Probabilistic Deep Metric Learning for Hyperspectral Image Classification
Nov 15, 2022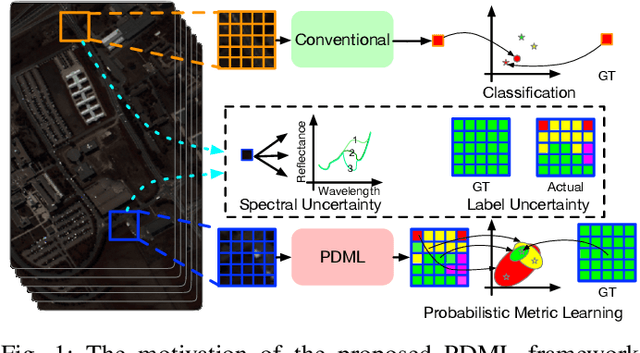
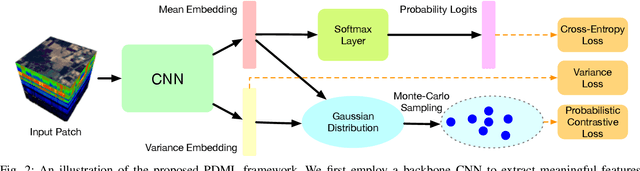
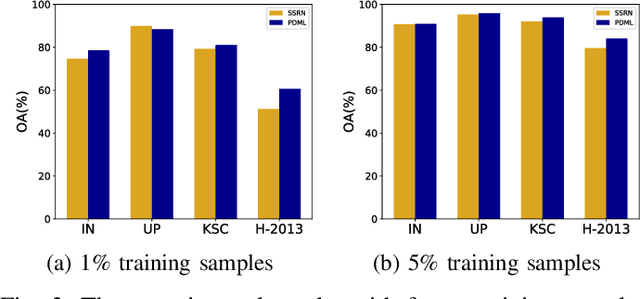
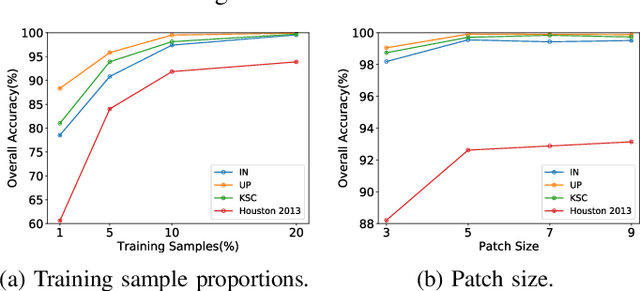
This paper proposes a probabilistic deep metric learning (PDML) framework for hyperspectral image classification, which aims to predict the category of each pixel for an image captured by hyperspectral sensors. The core problem for hyperspectral image classification is the spectral variability between intraclass materials and the spectral similarity between interclass materials, motivating the further incorporation of spatial information to differentiate a pixel based on its surrounding patch. However, different pixels and even the same pixel in one patch might not encode the same material due to the low spatial resolution of most hyperspectral sensors, leading to an inconsistent judgment of a specific pixel. To address this issue, we propose a probabilistic deep metric learning framework to model the categorical uncertainty of the spectral distribution of an observed pixel. We propose to learn a global probabilistic distribution for each pixel in the patch and a probabilistic metric to model the distance between distributions. We treat each pixel in a patch as a training sample, enabling us to exploit more information from the patch compared with conventional methods. Our framework can be readily applied to existing hyperspectral image classification methods with various network architectures and loss functions. Extensive experiments on four widely used datasets including IN, UP, KSC, and Houston 2013 datasets demonstrate that our framework improves the performance of existing methods and further achieves the state of the art. Code is available at: https://github.com/wzzheng/PDML.