 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Features, Not Tokens: Energy-Based Fine-Tuning of Language Models
Mar 12, 2026Cross-entropy (CE) training provides dense and scalable supervision for language models, but it optimizes next-token prediction under teacher forcing rather than sequence-level behavior under model rollouts. We introduce a feature-matching objective for language-model fine-tuning that targets sequence-level statistics of the completion distribution, providing dense semantic feedback without requiring a task-specific verifier or preference model. To optimize this objective efficiently, we propose energy-based fine-tuning (EBFT), which uses strided block-parallel sampling to generate multiple rollouts from nested prefixes concurrently, batches feature extraction over these rollouts, and uses the resulting embeddings to perform an on-policy policy-gradient update. We present a theoretical perspective connecting EBFT to KL-regularized feature-matching and energy-based modeling. Empirically, across Q&A coding, unstructured coding, and translation, EBFT matches RLVR and outperforms SFT on downstream accuracy while achieving a lower validation cross-entropy than both methods.
SCALAR: Learning and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding
Mar 10, 2026LM-based agents excel when given high-level action APIs but struggle to ground language into low-level control. Prior work has LLMs generate skills or reward functions for RL, but these one-shot approaches lack feedback to correct specification errors. We introduce SCALAR, a bidirectional framework coupling LLM planning with RL through a learned skill library. The LLM proposes skills with preconditions and effects; RL trains policies for each skill and feeds back execution results to iteratively refine specifications, improving robustness to initial errors. Pivotal Trajectory Analysis corrects LLM priors by analyzing RL trajectories; Frontier Checkpointing optionally saves environment states at skill boundaries to improve sample efficiency. On Craftax, SCALAR achieves 88.2% diamond collection, a 1.9x improvement over the best baseline, and reaches the Gnomish Mines 9.1% of the time where prior methods fail entirely.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Mobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mar 26, 2025



Rapid advancements in large language models (LLMs) have increased interest in deploying them on mobile devices for on-device AI applications. Mobile users interact differently with LLMs compared to desktop users, creating unique expectations and data biases. Current benchmark datasets primarily target at server and desktop environments, and there is a notable lack of extensive datasets specifically designed for mobile contexts. Additionally, mobile devices face strict limitations in storage and computing resources, constraining model size and capabilities, thus requiring optimized efficiency and prioritized knowledge. To address these challenges, we introduce Mobile-MMLU, a large-scale benchmark dataset tailored for mobile intelligence. It consists of 16,186 questions across 80 mobile-related fields, designed to evaluate LLM performance in realistic mobile scenarios. A challenging subset, Mobile-MMLU-Pro, provides advanced evaluation similar in size to MMLU-Pro but significantly more difficult than our standard full set. Both benchmarks use multiple-choice, order-invariant questions focused on practical mobile interactions, such as recipe suggestions, travel planning, and essential daily tasks. The dataset emphasizes critical mobile-specific metrics like inference latency, energy consumption, memory usage, and response quality, offering comprehensive insights into model performance under mobile constraints. Moreover, it prioritizes privacy and adaptability, assessing models' ability to perform on-device processing, maintain user privacy, and adapt to personalized usage patterns. Mobile-MMLU family offers a standardized framework for developing and comparing mobile-optimized LLMs, enabling advancements in productivity and decision-making within mobile computing environments. Our code and data are available at: https://github.com/VILA-Lab/Mobile-MMLU.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Phi-4 Technical Report
Dec 12, 2024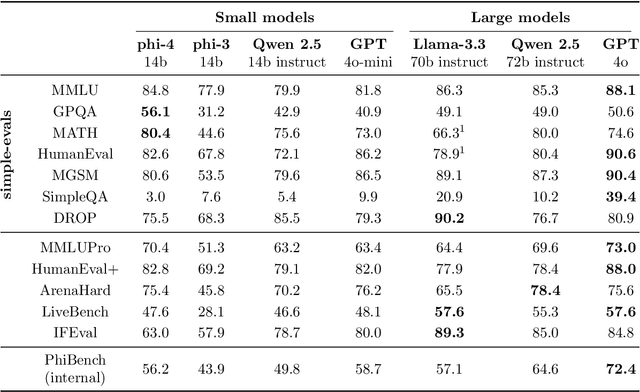
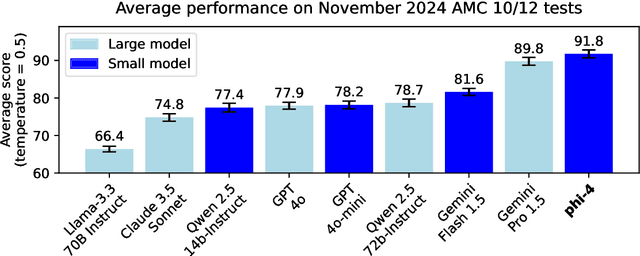

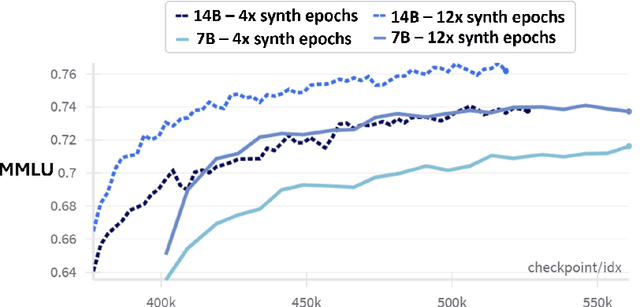
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Mixture of Parrots: Experts improve memorization more than reasoning
Oct 24, 2024



The Mixture-of-Experts (MoE) architecture enables a significant increase in the total number of model parameters with minimal computational overhead. However, it is not clear what performance tradeoffs, if any, exist between MoEs and standard dense transformers. In this paper, we show that as we increase the number of experts (while fixing the number of active parameters), the memorization performance consistently increases while the reasoning capabilities saturate. We begin by analyzing the theoretical limitations of MoEs at reasoning. We prove that there exist graph problems that cannot be solved by any number of experts of a certain width; however, the same task can be easily solved by a dense model with a slightly larger width. On the other hand, we find that on memory-intensive tasks, MoEs can effectively leverage a small number of active parameters with a large number of experts to memorize the data. We empirically validate these findings on synthetic graph problems and memory-intensive closed book retrieval tasks. Lastly, we pre-train a series of MoEs and dense transformers and evaluate them on commonly used benchmarks in math and natural language. We find that increasing the number of experts helps solve knowledge-intensive tasks, but fails to yield the same benefits for reasoning tasks.
LoRA Soups: Merging LoRAs for Practical Skill Composition Tasks
Oct 16, 2024



Low-Rank Adaptation (LoRA) is a popular technique for parameter-efficient fine-tuning of Large Language Models (LLMs). We study how different LoRA modules can be merged to achieve skill composition -- testing the performance of the merged model on a target task that involves combining multiple skills, each skill coming from a single LoRA. This setup is favorable when it is difficult to obtain training data for the target task and when it can be decomposed into multiple skills. First, we identify practically occurring use-cases that can be studied under the realm of skill composition, e.g. solving hard math-word problems with code, creating a bot to answer questions on proprietary manuals or about domain-specialized corpora. Our main contribution is to show that concatenation of LoRAs (CAT), which optimally averages LoRAs that were individually trained on different skills, outperforms existing model- and data- merging techniques; for instance on math-word problems, CAT beats these methods by an average of 43% and 12% respectively. Thus, this paper advocates model merging as an efficient way to solve compositional tasks and underscores CAT as a simple, compute-friendly and effective procedure. To our knowledge, this is the first work demonstrating the superiority of model merging over data mixing for binary skill composition tasks.
Adversarial Training Can Provably Improve Robustness: Theoretical Analysis of Feature Learning Process Under Structured Data
Oct 11, 2024



Adversarial training is a widely-applied approach to training deep neural networks to be robust against adversarial perturbation. However, although adversarial training has achieved empirical success in practice, it still remains unclear why adversarial examples exist and how adversarial training methods improve model robustness. In this paper, we provide a theoretical understanding of adversarial examples and adversarial training algorithms from the perspective of feature learning theory. Specifically, we focus on a multiple classification setting, where the structured data can be composed of two types of features: the robust features, which are resistant to perturbation but sparse, and the non-robust features, which are susceptible to perturbation but dense. We train a two-layer smoothed ReLU convolutional neural network to learn our structured data. First, we prove that by using standard training (gradient descent over the empirical risk), the network learner primarily learns the non-robust feature rather than the robust feature, which thereby leads to the adversarial examples that are generated by perturbations aligned with negative non-robust feature directions. Then, we consider the gradient-based adversarial training algorithm, which runs gradient ascent to find adversarial examples and runs gradient descent over the empirical risk at adversarial examples to update models. We show that the adversarial training method can provably strengthen the robust feature learning and suppress the non-robust feature learning to improve the network robustness. Finally, we also empirically validate our theoretical findings with experiments on real-image datasets, including MNIST, CIFAR10 and SVHN.
Beyond Parameter Count: Implicit Bias in Soft Mixture of Experts
Sep 02, 2024



The traditional viewpoint on Sparse Mixture of Experts (MoE) models is that instead of training a single large expert, which is computationally expensive, we can train many small experts. The hope is that if the total parameter count of the small experts equals that of the singular large expert, then we retain the representation power of the large expert while gaining computational tractability and promoting expert specialization. The recently introduced Soft MoE replaces the Sparse MoE's discrete routing mechanism with a differentiable gating function that smoothly mixes tokens. While this smooth gating function successfully mitigates the various training instabilities associated with Sparse MoE, it is unclear whether it induces implicit biases that affect Soft MoE's representation power or potential for expert specialization. We prove that Soft MoE with a single arbitrarily powerful expert cannot represent simple convex functions. This justifies that Soft MoE's success cannot be explained by the traditional viewpoint of many small experts collectively mimicking the representation power of a single large expert, and that multiple experts are actually necessary to achieve good representation power (even for a fixed total parameter count). Continuing along this line of investigation, we introduce a notion of expert specialization for Soft MoE, and while varying the number of experts yet fixing the total parameter count, we consider the following (computationally intractable) task. Given any input, how can we discover the expert subset that is specialized to predict this input's label? We empirically show that when there are many small experts, the architecture is implicitly biased in a fashion that allows us to efficiently approximate the specialized expert subset. Our method can be easily implemented to potentially reduce computation during inference.