 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Learning of Random Hierarchy Models and Hierarchical Shallow-to-Deep Chaining
Jan 27, 2026The empirical success of deep learning is often attributed to deep networks' ability to exploit hierarchical structure in data, constructing increasingly complex features across layers. Yet despite substantial progress in deep learning theory, most optimization results sill focus on networks with only two or three layers, leaving the theoretical understanding of hierarchical learning in genuinely deep models limited. This leads to a natural question: can we prove that deep networks, trained by gradient-based methods, can efficiently exploit hierarchical structure? In this work, we consider Random Hierarchy Models -- a hierarchical context-free grammar introduced by arXiv:2307.02129 and conjectured to separate deep and shallow networks. We prove that, under mild conditions, a deep convolutional network can be efficiently trained to learn this function class. Our proof builds on a general observation: if intermediate layers can receive clean signal from the labels and the relevant features are weakly identifiable, then layerwise training each individual layer suffices to hierarchically learn the target function.
Emergence and scaling laws in SGD learning of shallow neural networks
Apr 28, 2025We study the complexity of online stochastic gradient descent (SGD) for learning a two-layer neural network with $P$ neurons on isotropic Gaussian data: $f_*(\boldsymbol{x}) = \sum_{p=1}^P a_p\cdot \sigma(\langle\boldsymbol{x},\boldsymbol{v}_p^*\rangle)$, $\boldsymbol{x} \sim \mathcal{N}(0,\boldsymbol{I}_d)$, where the activation $\sigma:\mathbb{R}\to\mathbb{R}$ is an even function with information exponent $k_*>2$ (defined as the lowest degree in the Hermite expansion), $\{\boldsymbol{v}^*_p\}_{p\in[P]}\subset \mathbb{R}^d$ are orthonormal signal directions, and the non-negative second-layer coefficients satisfy $\sum_{p} a_p^2=1$. We focus on the challenging ``extensive-width'' regime $P\gg 1$ and permit diverging condition number in the second-layer, covering as a special case the power-law scaling $a_p\asymp p^{-\beta}$ where $\beta\in\mathbb{R}_{\ge 0}$. We provide a precise analysis of SGD dynamics for the training of a student two-layer network to minimize the mean squared error (MSE) objective, and explicitly identify sharp transition times to recover each signal direction. In the power-law setting, we characterize scaling law exponents for the MSE loss with respect to the number of training samples and SGD steps, as well as the number of parameters in the student neural network. Our analysis entails that while the learning of individual teacher neurons exhibits abrupt transitions, the juxtaposition of $P\gg 1$ emergent learning curves at different timescales leads to a smooth scaling law in the cumulative objective.
Learning and Transferring Sparse Contextual Bigrams with Linear Transformers
Oct 30, 2024



Transformers have excelled in natural language modeling and one reason behind this success is their exceptional ability to combine contextual informal and global knowledge. However, the theoretical basis remains unclear. In this paper, first we introduce the Sparse Contextual Bigram (SCB), a natural extension of the classical bigram model, where the next token's generation depends on a sparse set of earlier positions determined by the last token. We then analyze the training dynamics and sample complexity of learning SCB using a one-layer linear transformer with a gradient-based algorithm. We show that when trained from scratch, the training process can be split into an initial sample-intensive stage where the correlation is boosted from zero to a nontrivial value, followed by a more sample-efficient stage of further improvement. Additionally, we prove that, provided a nontrivial correlation between the downstream and pretraining tasks, finetuning from a pretrained model allows us to bypass the initial sample-intensive stage. We also empirically demonstrate that our algorithm can outperform SGD in this setting and discuss its relationship with the usual softmax-based transformers.
Learning Orthogonal Multi-Index Models: A Fine-Grained Information Exponent Analysis
Oct 13, 2024
The information exponent (Ben Arous et al. [2021]) -- which is equivalent to the lowest degree in the Hermite expansion of the link function for Gaussian single-index models -- has played an important role in predicting the sample complexity of online stochastic gradient descent (SGD) in various learning tasks. In this work, we demonstrate that, for multi-index models, focusing solely on the lowest degree can miss key structural details of the model and result in suboptimal rates. Specifically, we consider the task of learning target functions of form $f_*(\mathbf{x}) = \sum_{k=1}^{P} \phi(\mathbf{v}_k^* \cdot \mathbf{x})$, where $P \ll d$, the ground-truth directions $\{ \mathbf{v}_k^* \}_{k=1}^P$ are orthonormal, and only the second and $2L$-th Hermite coefficients of the link function $\phi$ can be nonzero. Based on the theory of information exponent, when the lowest degree is $2L$, recovering the directions requires $d^{2L-1}\mathrm{poly}(P)$ samples, and when the lowest degree is $2$, only the relevant subspace (not the exact directions) can be recovered due to the rotational invariance of the second-order terms. In contrast, we show that by considering both second- and higher-order terms, we can first learn the relevant space via the second-order terms, and then the exact directions using the higher-order terms, and the overall sample and complexity of online SGD is $d \mathrm{poly}(P)$.
On the Importance of Contrastive Loss in Multimodal Learning
Apr 07, 2023

Recently, contrastive learning approaches (e.g., CLIP (Radford et al., 2021)) have received huge success in multimodal learning, where the model tries to minimize the distance between the representations of different views (e.g., image and its caption) of the same data point while keeping the representations of different data points away from each other. However, from a theoretical perspective, it is unclear how contrastive learning can learn the representations from different views efficiently, especially when the data is not isotropic. In this work, we analyze the training dynamics of a simple multimodal contrastive learning model and show that contrastive pairs are important for the model to efficiently balance the learned representations. In particular, we show that the positive pairs will drive the model to align the representations at the cost of increasing the condition number, while the negative pairs will reduce the condition number, keeping the learned representations balanced.
Depth Separation with Multilayer Mean-Field Networks
Apr 03, 2023

Depth separation -- why a deeper network is more powerful than a shallower one -- has been a major problem in deep learning theory. Previous results often focus on representation power. For example, arXiv:1904.06984 constructed a function that is easy to approximate using a 3-layer network but not approximable by any 2-layer network. In this paper, we show that this separation is in fact algorithmic: one can learn the function constructed by arXiv:1904.06984 using an overparameterized network with polynomially many neurons efficiently. Our result relies on a new way of extending the mean-field limit to multilayer networks, and a decomposition of loss that factors out the error introduced by the discretization of infinite-width mean-field networks.
Understanding Deflation Process in Over-parametrized Tensor Decomposition
Jun 11, 2021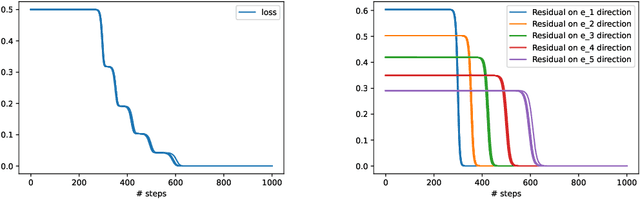
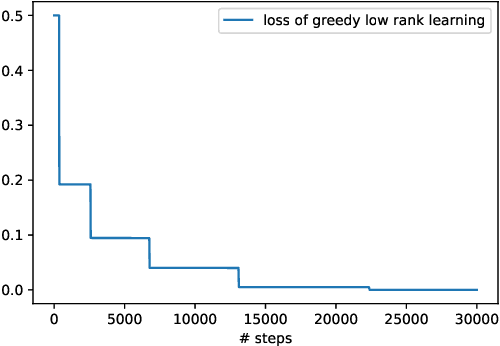

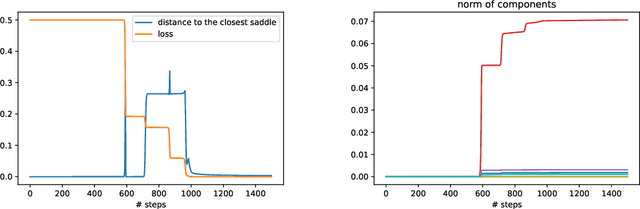
In this paper we study the training dynamics for gradient flow on over-parametrized tensor decomposition problems. Empirically, such training process often first fits larger components and then discovers smaller components, which is similar to a tensor deflation process that is commonly used in tensor decomposition algorithms. We prove that for orthogonally decomposable tensor, a slightly modified version of gradient flow would follow a tensor deflation process and recover all the tensor components. Our proof suggests that for orthogonal tensors, gradient flow dynamics works similarly as greedy low-rank learning in the matrix setting, which is a first step towards understanding the implicit regularization effect of over-parametrized models for low-rank tensors.