 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Semantic Segmentation
Mar 20, 2023
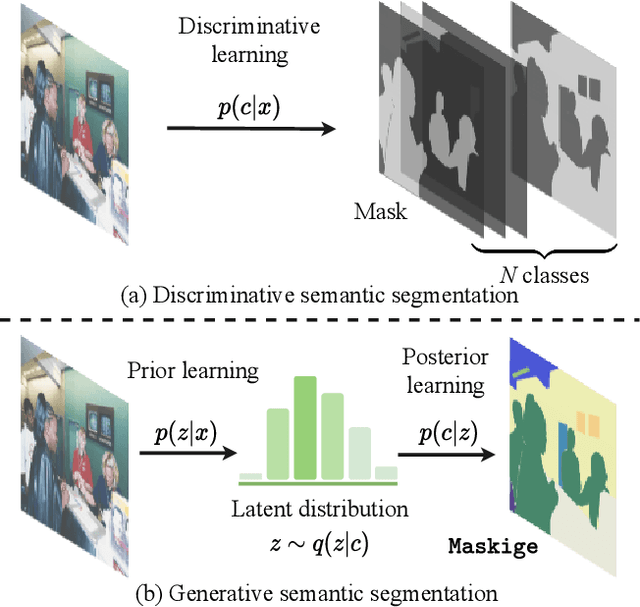
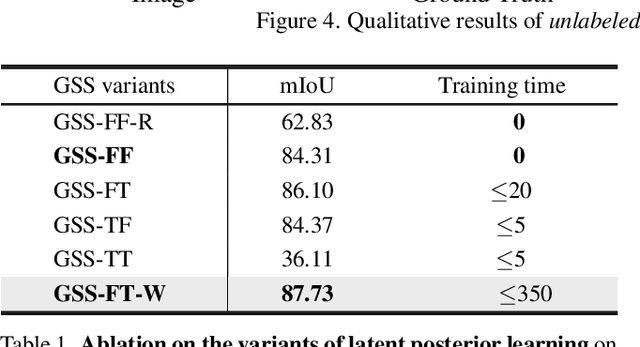
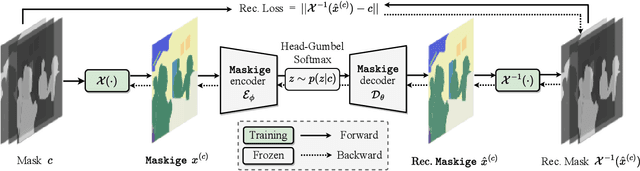
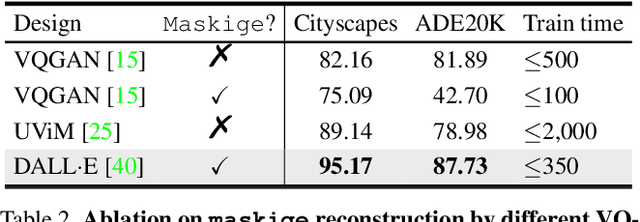
We present Generative Semantic Segmentation (GSS), a generative learning approach for semantic segmentation. Uniquely, we cast semantic segmentation as an image-conditioned mask generation problem. This is achieved by replacing the conventional per-pixel discriminative learning with a latent prior learning process. Specifically, we model the variational posterior distribution of latent variables given the segmentation mask. To that end, the segmentation mask is expressed with a special type of image (dubbed as maskige). This posterior distribution allows to generate segmentation masks unconditionally. To achieve semantic segmentation on a given image, we further introduce a conditioning network. It is optimized by minimizing the divergence between the posterior distribution of maskige (i.e., segmentation masks) and the latent prior distribution of input training images. Extensive experiments on standard benchmarks show that our GSS can perform competitively to prior art alternatives in the standard semantic segmentation setting, whilst achieving a new state of the art in the more challenging cross-domain setting.
Neural Implicit Vision-Language Feature Fields
Mar 20, 2023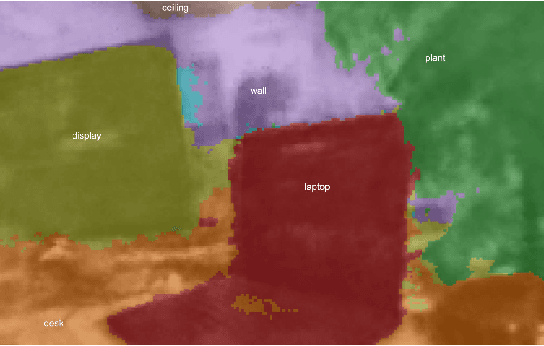


Recently, groundbreaking results have been presented on open-vocabulary semantic image segmentation. Such methods segment each pixel in an image into arbitrary categories provided at run-time in the form of text prompts, as opposed to a fixed set of classes defined at training time. In this work, we present a zero-shot volumetric open-vocabulary semantic scene segmentation method. Our method builds on the insight that we can fuse image features from a vision-language model into a neural implicit representation. We show that the resulting feature field can be segmented into different classes by assigning points to natural language text prompts. The implicit volumetric representation enables us to segment the scene both in 3D and 2D by rendering feature maps from any given viewpoint of the scene. We show that our method works on noisy real-world data and can run in real-time on live sensor data dynamically adjusting to text prompts. We also present quantitative comparisons on the ScanNet dataset.
Collaborative Diffusion for Multi-Modal Face Generation and Editing
Apr 20, 2023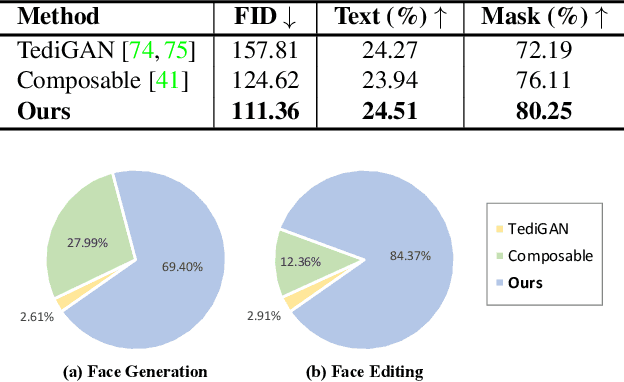
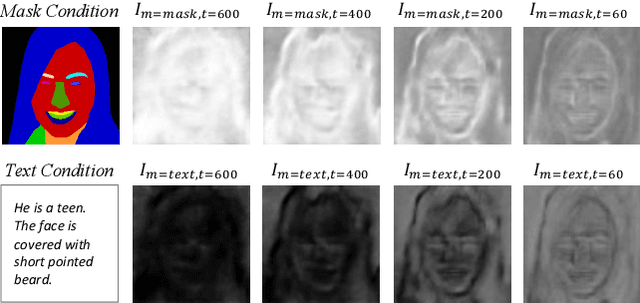
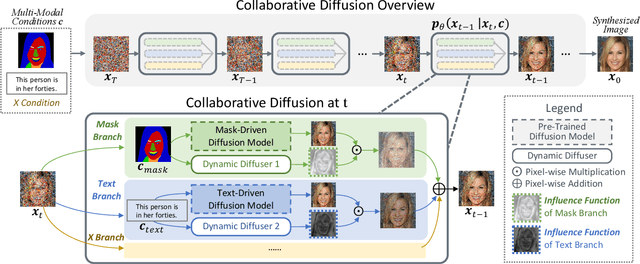
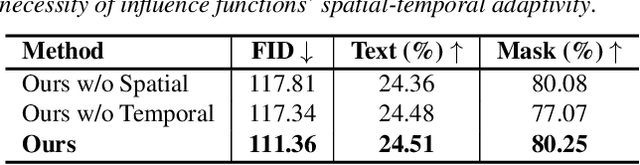
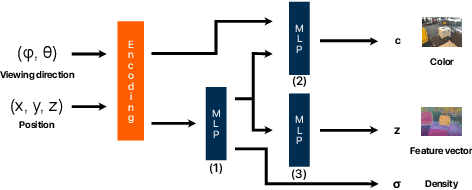
Diffusion models arise as a powerful generative tool recently. Despite the great progress, existing diffusion models mainly focus on uni-modal control, i.e., the diffusion process is driven by only one modality of condition. To further unleash the users' creativity, it is desirable for the model to be controllable by multiple modalities simultaneously, e.g., generating and editing faces by describing the age (text-driven) while drawing the face shape (mask-driven). In this work, we present Collaborative Diffusion, where pre-trained uni-modal diffusion models collaborate to achieve multi-modal face generation and editing without re-training. Our key insight is that diffusion models driven by different modalities are inherently complementary regarding the latent denoising steps, where bilateral connections can be established upon. Specifically, we propose dynamic diffuser, a meta-network that adaptively hallucinates multi-modal denoising steps by predicting the spatial-temporal influence functions for each pre-trained uni-modal model. Collaborative Diffusion not only collaborates generation capabilities from uni-modal diffusion models, but also integrates multiple uni-modal manipulations to perform multi-modal editing. Extensive qualitative and quantitative experiments demonstrate the superiority of our framework in both image quality and condition consistency.
High-Fidelity and Freely Controllable Talking Head Video Generation
Apr 20, 2023
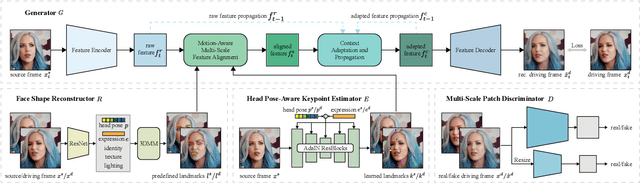
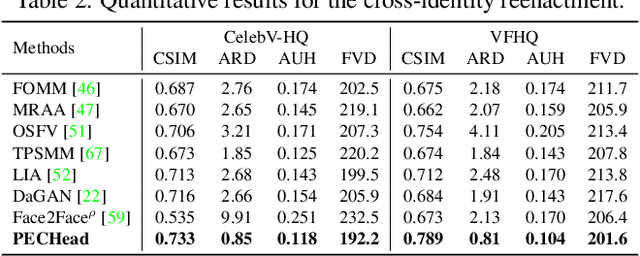
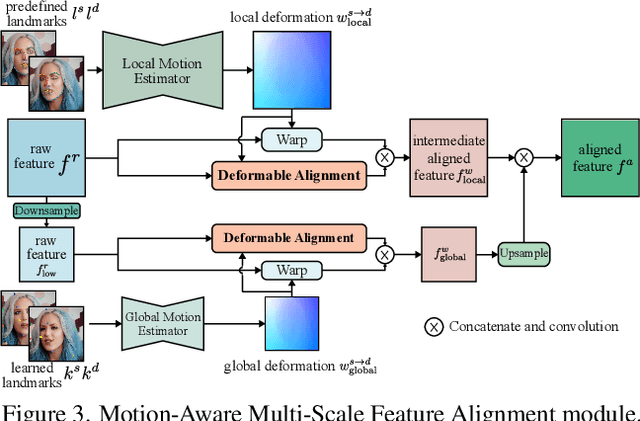
Talking head generation is to generate video based on a given source identity and target motion. However, current methods face several challenges that limit the quality and controllability of the generated videos. First, the generated face often has unexpected deformation and severe distortions. Second, the driving image does not explicitly disentangle movement-relevant information, such as poses and expressions, which restricts the manipulation of different attributes during generation. Third, the generated videos tend to have flickering artifacts due to the inconsistency of the extracted landmarks between adjacent frames. In this paper, we propose a novel model that produces high-fidelity talking head videos with free control over head pose and expression. Our method leverages both self-supervised learned landmarks and 3D face model-based landmarks to model the motion. We also introduce a novel motion-aware multi-scale feature alignment module to effectively transfer the motion without face distortion. Furthermore, we enhance the smoothness of the synthesized talking head videos with a feature context adaptation and propagation module. We evaluate our model on challenging datasets and demonstrate its state-of-the-art performance. More information is available at https://yuegao.me/PECHead.
LISA: Localized Image Stylization with Audio via Implicit Neural Representation
Nov 21, 2022
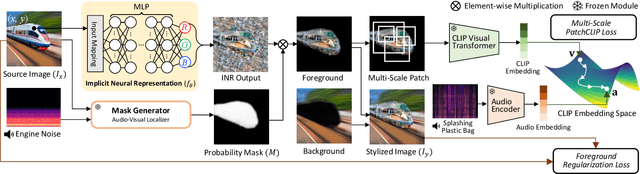
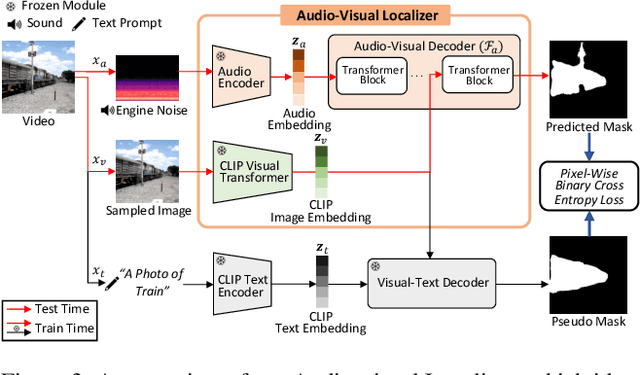
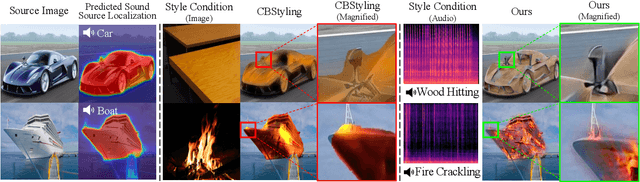
We present a novel framework, Localized Image Stylization with Audio (LISA) which performs audio-driven localized image stylization. Sound often provides information about the specific context of the scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. In this work, we propose a framework that a user provides an audio input to localize the sound source in the input image and another for locally stylizing the target object or scene. LISA first produces a delicate localization map with an audio-visual localization network by leveraging CLIP embedding space. We then utilize implicit neural representation (INR) along with the predicted localization map to stylize the target object or scene based on sound information. The proposed INR can manipulate the localized pixel values to be semantically consistent with the provided audio input. Through a series of experiments, we show that the proposed framework outperforms the other audio-guided stylization methods. Moreover, LISA constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.
IDLL: Inverse Depth Line based Visual Localization in Challenging Environments
Apr 23, 2023
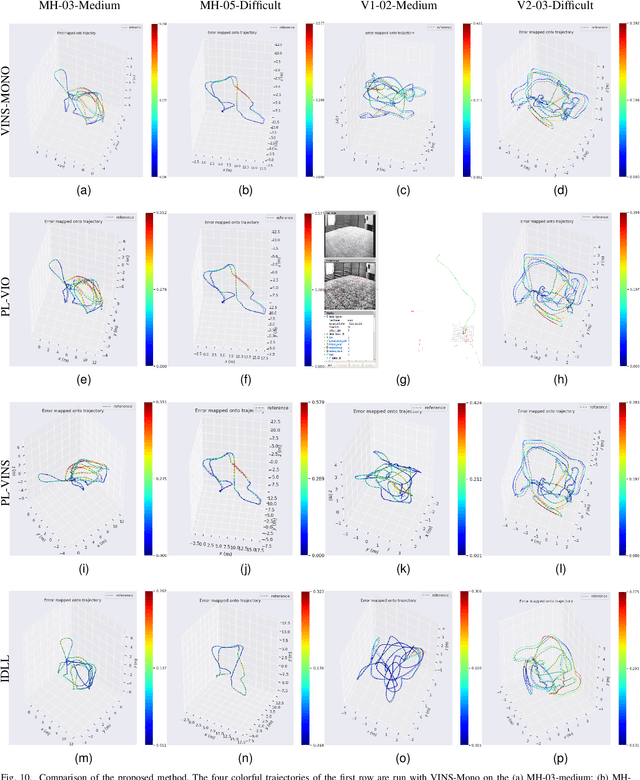
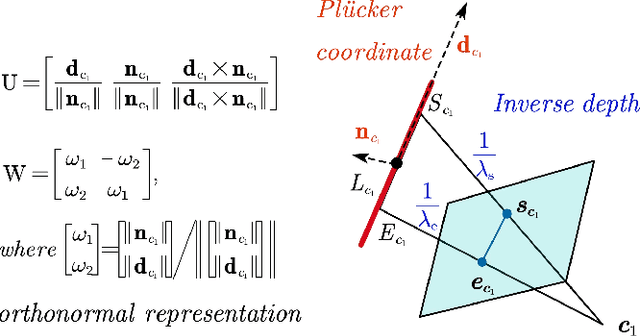
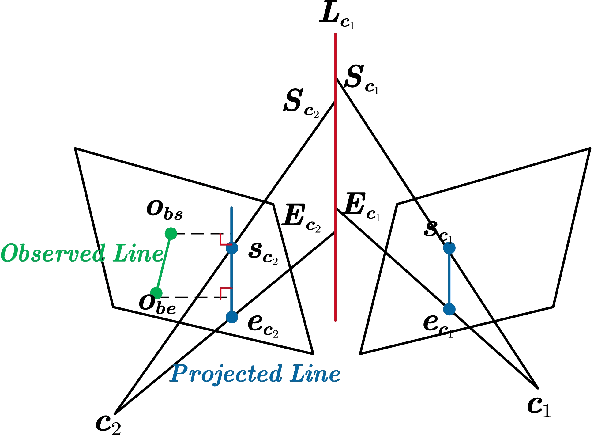
Precise and real-time localization of unmanned aerial vehicles (UAVs) or robots in GNSS denied indoor environments are critically important for various logistics and surveillance applications. Vision-based simultaneously locating and mapping (VSLAM) are key solutions but suffer location drifts in texture-less, man-made indoor environments. Line features are rich in man-made environments which can be exploited to improve the localization robustness, but existing point-line based VSLAM methods still lack accuracy and efficiency for the representation of lines introducing unnecessary degrees of freedoms. In this paper, we propose Inverse Depth Line Localization(IDLL), which models each extracted line feature using two inverse depth variables exploiting the fact that the projected pixel coordinates on the image plane are rather accurate, which partially restrict the lines. This freedom-reduced representation of lines enables easier line determination and faster convergence of bundle adjustment in each step, therefore achieves more accurate and more efficient frame-to-frame registration and frame-to-map registration using both point and line visual features. We redesign the whole front-end and back-end modules of VSLAM using this line model. IDLL is extensively evaluated in multiple perceptually-challenging datasets. The results show it is more accurate, robust, and needs lower computational overhead than the current state-of-the-art of feature-based VSLAM methods.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023
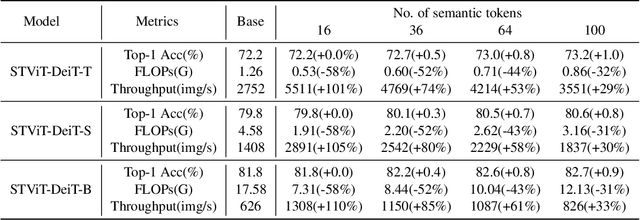
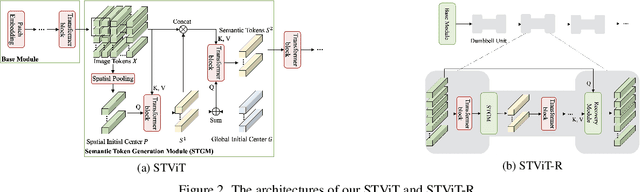
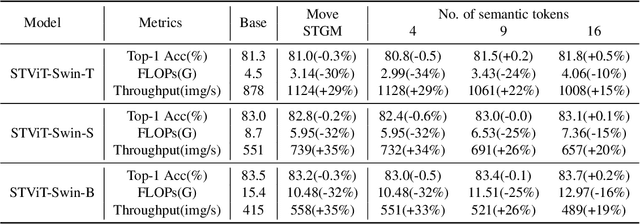
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
Learning Dynamic Style Kernels for Artistic Style Transfer
Apr 02, 2023
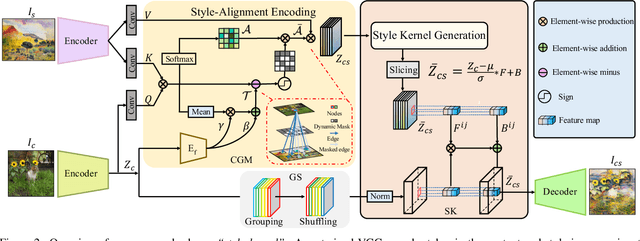


Arbitrary style transfer has been demonstrated to be efficient in artistic image generation. Previous methods either globally modulate the content feature ignoring local details, or overly focus on the local structure details leading to style leakage. In contrast to the literature, we propose a new scheme \textit{``style kernel"} that learns {\em spatially adaptive kernels} for per-pixel stylization, where the convolutional kernels are dynamically generated from the global style-content aligned feature and then the learned kernels are applied to modulate the content feature at each spatial position. This new scheme allows flexible both global and local interactions between the content and style features such that the wanted styles can be easily transferred to the content image while at the same time the content structure can be easily preserved. To further enhance the flexibility of our style transfer method, we propose a Style Alignment Encoding (SAE) module complemented with a Content-based Gating Modulation (CGM) module for learning the dynamic style kernels in focusing regions. Extensive experiments strongly demonstrate that our proposed method outperforms state-of-the-art methods and exhibits superior performance in terms of visual quality and efficiency.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023
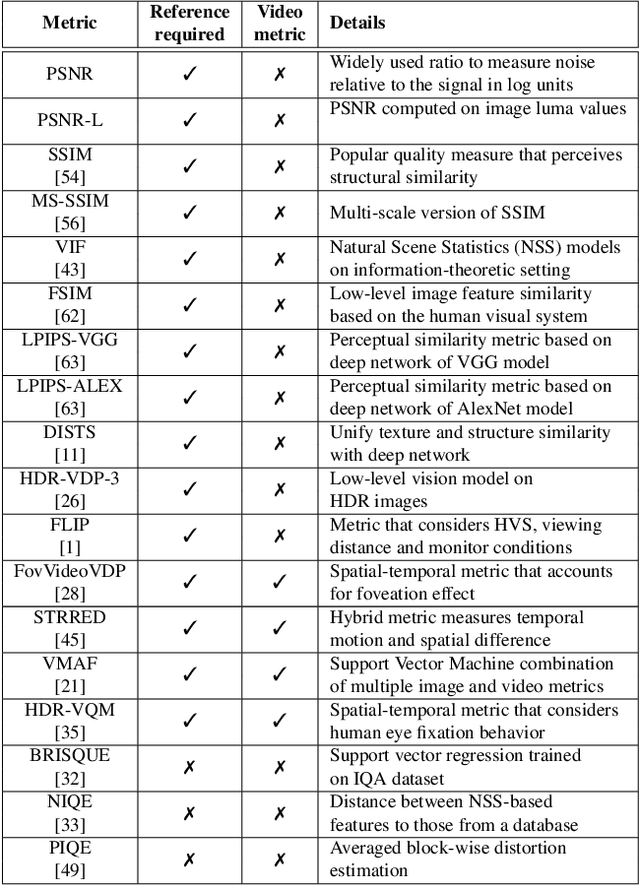
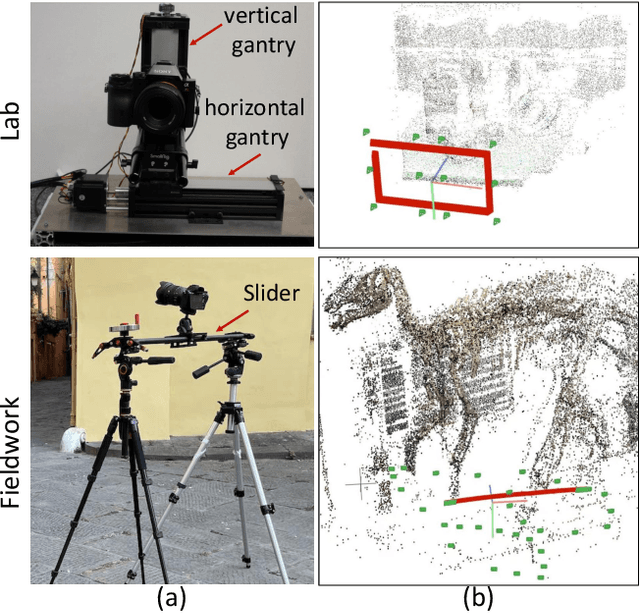

Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
Reconstructing the Image Scanning Microscopy Dataset: an Inverse Problem
Nov 22, 2022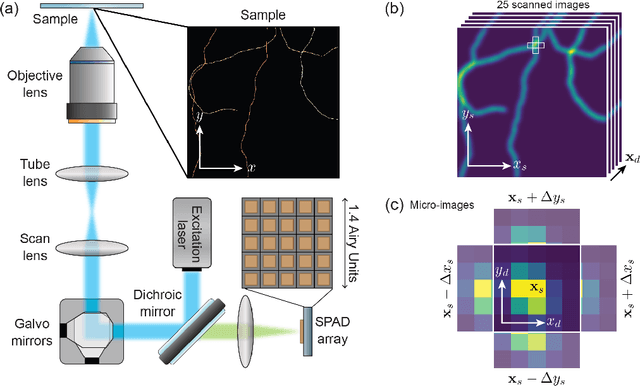
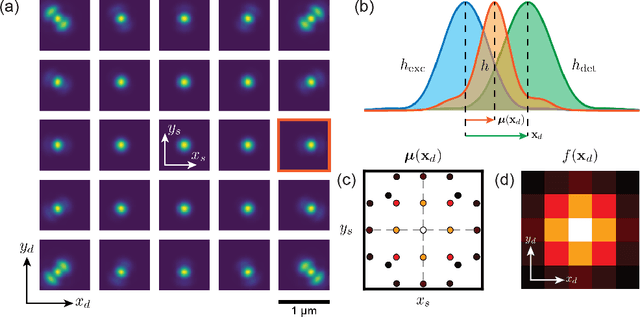
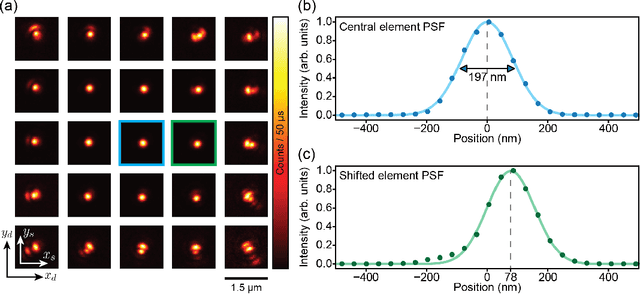
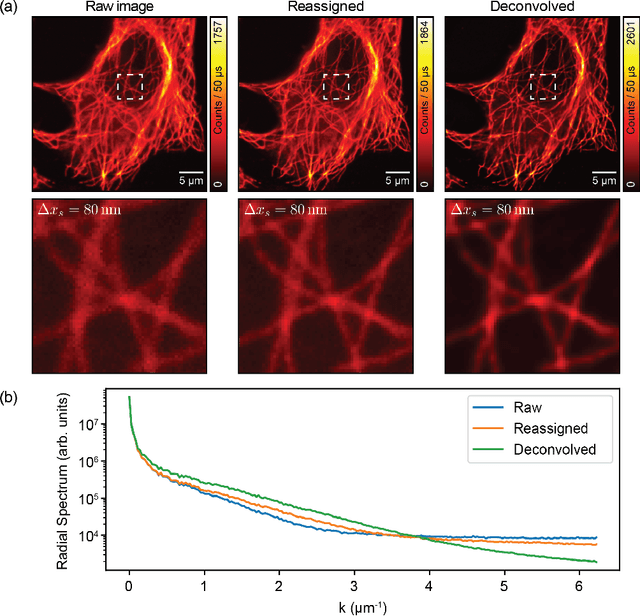
Confocal laser-scanning microscopy (CLSM) is one of the most popular optical architectures for fluorescence imaging. In CLSM, a focused laser beam excites the fluorescence emission from a specific specimen position. Some actuators scan the probed region across the sample and a photodetector collects a single intensity value for each scan point, building a two-dimensional image pixel-by-pixel. Recently, new fast single-photon array detectors have allowed the recording of a full bi-dimensional image of the probed region for each scan point, transforming CLSM into image scanning microscopy (ISM). This latter offers significant improvements over traditional imaging but requires an optimal processing tool to extract a super-resolved image from the four-dimensional dataset. Here we describe the image formation process in ISM from a statistical point of view, and we use the Bayesian framework to formulate a multi-image deconvolution problem. Notably, the single-photon detector suffers exclusively from the photon shot noise, enabling the development of an effective likelihood model. We derive an iterative likelihood maximization algorithm and test it on experimental and simulated data. Furthermore, we demonstrate that the ISM dataset is redundant, enabling the possibility of obtaining reconstruction sampled at twice the scanning step. Our results prove that in ISM, under appropriate conditions, the Nyquist-Shannon sampling criterium is effectively relaxed. This finding can be exploited to speed up the acquisition process by a factor of four, further improving the versatility of ISM systems.