 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating HDR Video from SDR Video
May 14, 2026The high dynamic range (HDR) video ecosystem is approaching maturity, but the problem of upconverting legacy standard dynamic range (SDR) videos persists without a convincing solution. We propose a framework for HDR video synthesis from casual SDR footage by leveraging large-scale generative video models. We introduce a Multi-Exposure Video Model (MEVM) that can predict exposure-bracketed linear SDR video sequences from a single nonlinear SDR video input. We further propose a learnable Video Merging Model (VMM) that merges the predicted exposure-bracketed video into a high-quality HDR sequence while preserving detail in both shadows and highlights. Extensive experiments, quantitative and qualitative evaluation, and a user study demonstrate that our approach enables robust HDR conversion for in-the-wild examples from casual consumer videos and even iconic films. Finally, our model can support HDR synthesis pipelines built upon existing SDR generative video models. Output HDR videos can be viewed on our supplementary webpage: sdr2hdrvideo.github.io
Deep chroma compression of tone-mapped images
Sep 24, 2024



Acquisition of high dynamic range (HDR) images is thriving due to the increasing use of smart devices and the demand for high-quality output. Extensive research has focused on developing methods for reducing the luminance range in HDR images using conventional and deep learning-based tone mapping operators to enable accurate reproduction on conventional 8 and 10-bit digital displays. However, these methods often fail to account for pixels that may lie outside the target display's gamut, resulting in visible chromatic distortions or color clipping artifacts. Previous studies suggested that a gamut management step ensures that all pixels remain within the target gamut. However, such approaches are computationally expensive and cannot be deployed on devices with limited computational resources. We propose a generative adversarial network for fast and reliable chroma compression of HDR tone-mapped images. We design a loss function that considers the hue property of generated images to improve color accuracy, and train the model on an extensive image dataset. Quantitative experiments demonstrate that the proposed model outperforms state-of-the-art image generation and enhancement networks in color accuracy, while a subjective study suggests that the generated images are on par or superior to those produced by conventional chroma compression methods in terms of visual quality. Additionally, the model achieves real-time performance, showing promising results for deployment on devices with limited computational resources.
HDRT: Infrared Capture for HDR Imaging
Jun 08, 2024
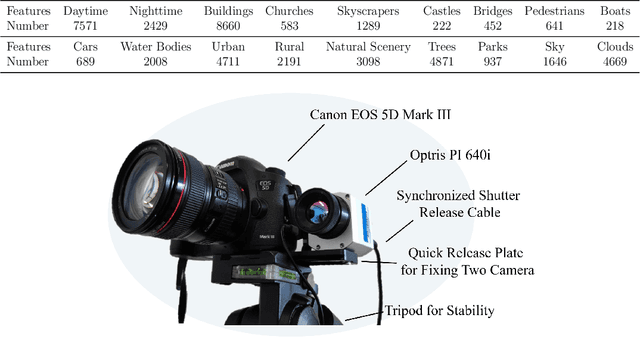
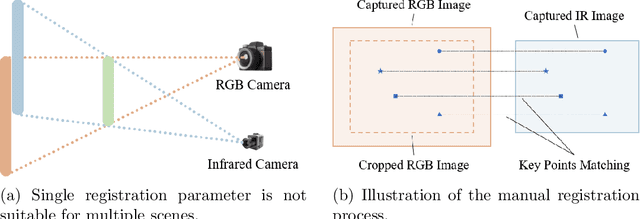
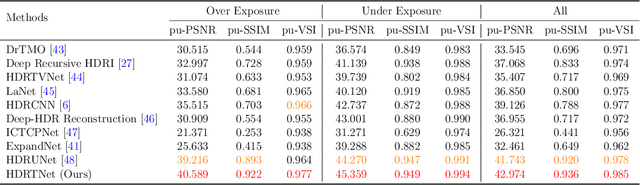
Capturing real world lighting is a long standing challenge in imaging and most practical methods acquire High Dynamic Range (HDR) images by either fusing multiple exposures, or boosting the dynamic range of Standard Dynamic Range (SDR) images. Multiple exposure capture is problematic as it requires longer capture times which can often lead to ghosting problems. The main alternative, inverse tone mapping is an ill-defined problem that is especially challenging as single captured exposures usually contain clipped and quantized values, and are therefore missing substantial amounts of content. To alleviate this, we propose a new approach, High Dynamic Range Thermal (HDRT), for HDR acquisition using a separate, commonly available, thermal infrared (IR) sensor. We propose a novel deep neural method (HDRTNet) which combines IR and SDR content to generate HDR images. HDRTNet learns to exploit IR features linked to the RGB image and the IR-specific parameters are subsequently used in a dual branch method that fuses features at shallow layers. This produces an HDR image that is significantly superior to that generated using naive fusion approaches. To validate our method, we have created the first HDR and thermal dataset, and performed extensive experiments comparing HDRTNet with the state-of-the-art. We show substantial quantitative and qualitative quality improvements on both over- and under-exposed images, showing that our approach is robust to capturing in multiple different lighting conditions.
Semantic Aware Diffusion Inverse Tone Mapping
May 24, 2024



The range of real-world scene luminance is larger than the capture capability of many digital camera sensors which leads to details being lost in captured images, most typically in bright regions. Inverse tone mapping attempts to boost these captured Standard Dynamic Range (SDR) images back to High Dynamic Range (HDR) by creating a mapping that linearizes the well exposed values from the SDR image, and provides a luminance boost to the clipped content. However, in most cases, the details in the clipped regions cannot be recovered or estimated. In this paper, we present a novel inverse tone mapping approach for mapping SDR images to HDR that generates lost details in clipped regions through a semantic-aware diffusion based inpainting approach. Our method proposes two major contributions - first, we propose to use a semantic graph to guide SDR diffusion based inpainting in masked regions in a saturated image. Second, drawing inspiration from traditional HDR imaging and bracketing methods, we propose a principled formulation to lift the SDR inpainted regions to HDR that is compatible with generative inpainting methods. Results show that our method demonstrates superior performance across different datasets on objective metrics, and subjective experiments show that the proposed method matches (and in most cases outperforms) state-of-art inverse tone mapping operators in terms of objective metrics and outperforms them for visual fidelity.
Re:Draw -- Context Aware Translation as a Controllable Method for Artistic Production
Jan 07, 2024



We introduce context-aware translation, a novel method that combines the benefits of inpainting and image-to-image translation, respecting simultaneously the original input and contextual relevance -- where existing methods fall short. By doing so, our method opens new avenues for the controllable use of AI within artistic creation, from animation to digital art. As an use case, we apply our method to redraw any hand-drawn animated character eyes based on any design specifications - eyes serve as a focal point that captures viewer attention and conveys a range of emotions, however, the labor-intensive nature of traditional animation often leads to compromises in the complexity and consistency of eye design. Furthermore, we remove the need for production data for training and introduce a new character recognition method that surpasses existing work by not requiring fine-tuning to specific productions. This proposed use case could help maintain consistency throughout production and unlock bolder and more detailed design choices without the production cost drawbacks. A user study shows context-aware translation is preferred over existing work 95.16% of the time.
Perceptual Quality Assessment of NeRF and Neural View Synthesis Methods for Front-Facing Views
Apr 02, 2023Neural view synthesis (NVS) is one of the most successful techniques for synthesizing free viewpoint videos, capable of achieving high fidelity from only a sparse set of captured images. This success has led to many variants of the techniques, each evaluated on a set of test views typically using image quality metrics such as PSNR, SSIM, or LPIPS. There has been a lack of research on how NVS methods perform with respect to perceived video quality. We present the first study on perceptual evaluation of NVS and NeRF variants. For this study, we collected two datasets of scenes captured in a controlled lab environment as well as in-the-wild. In contrast to existing datasets, these scenes come with reference video sequences, allowing us to test for temporal artifacts and subtle distortions that are easily overlooked when viewing only static images. We measured the quality of videos synthesized by several NVS methods in a well-controlled perceptual quality assessment experiment as well as with many existing state-of-the-art image/video quality metrics. We present a detailed analysis of the results and recommendations for dataset and metric selection for NVS evaluation.
Unsupervised HDR Imaging: What Can Be Learned from a Single 8-bit Video?
Feb 11, 2022



Recently, Deep Learning-based methods for inverse tone-mapping standard dynamic range (SDR) images to obtain high dynamic range (HDR) images have become very popular. These methods manage to fill over-exposed areas convincingly both in terms of details and dynamic range. Typically, these methods, to be effective, need to learn from large datasets and to transfer this knowledge to the network weights. In this work, we tackle this problem from a completely different perspective. What can we learn from a single SDR video? With the presented zero-shot approach, we show that, in many cases, a single SDR video is sufficient to be able to generate an HDR video of the same quality or better than other state-of-the-art methods.
DeepFlash: Turning a Flash Selfie into a Studio Portrait
Jan 14, 2019

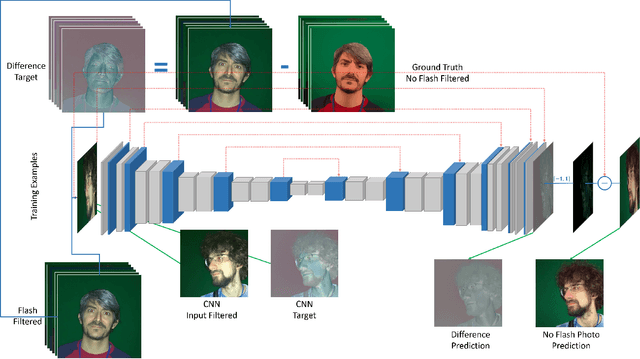

We present a method for turning a flash selfie taken with a smartphone into a photograph as if it was taken in a studio setting with uniform lighting. Our method uses a convolutional neural network trained on a set of pairs of photographs acquired in an ad-hoc acquisition campaign. Each pair consists of one photograph of a subject's face taken with the camera flash enabled and another one of the same subject in the same pose illuminated using a photographic studio-lighting setup. We show how our method can amend defects introduced by a close-up camera flash, such as specular highlights, shadows, skin shine, and flattened images.