 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretability of Machine Learning: Recent Advances and Future Prospects
Apr 30, 2023
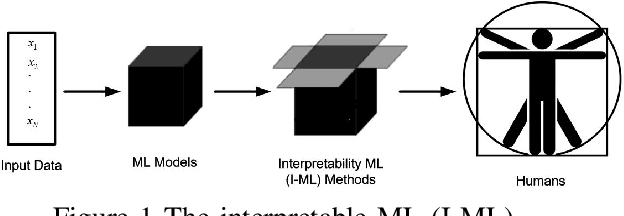
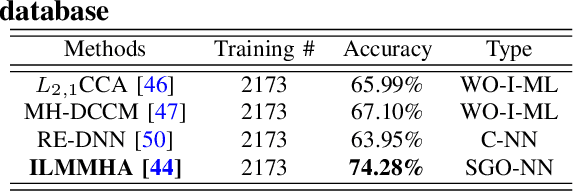
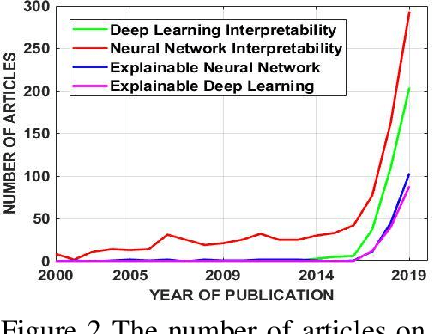
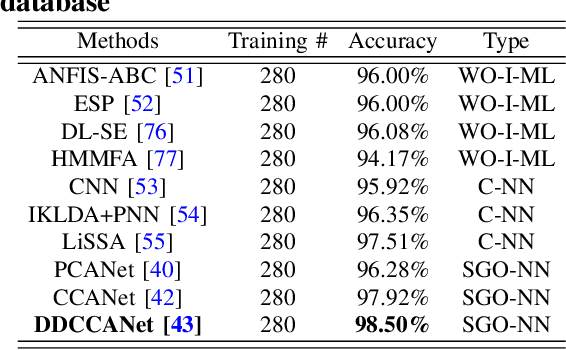
The proliferation of machine learning (ML) has drawn unprecedented interest in the study of various multimedia contents such as text, image, audio and video, among others. Consequently, understanding and learning ML-based representations have taken center stage in knowledge discovery in intelligent multimedia research and applications. Nevertheless, the black-box nature of contemporary ML, especially in deep neural networks (DNNs), has posed a primary challenge for ML-based representation learning. To address this black-box problem, the studies on interpretability of ML have attracted tremendous interests in recent years. This paper presents a survey on recent advances and future prospects on interpretability of ML, with several application examples pertinent to multimedia computing, including text-image cross-modal representation learning, face recognition, and the recognition of objects. It is evidently shown that the study of interpretability of ML promises an important research direction, one which is worth further investment in.
Prompt ChatGPT In MNER: Improved multimodal named entity recognition method based on auxiliary refining knowledge from ChatGPT
May 20, 2023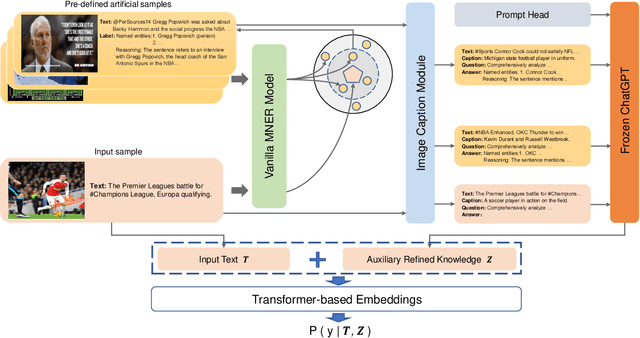
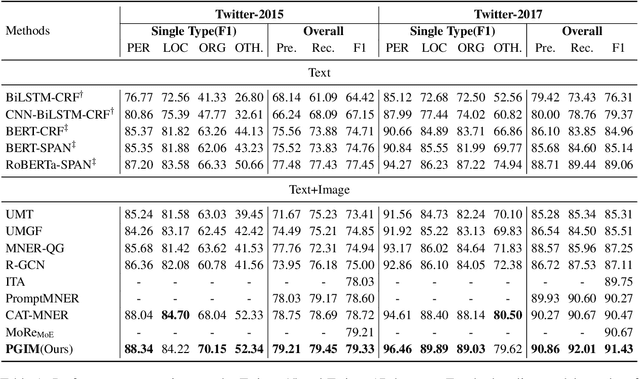
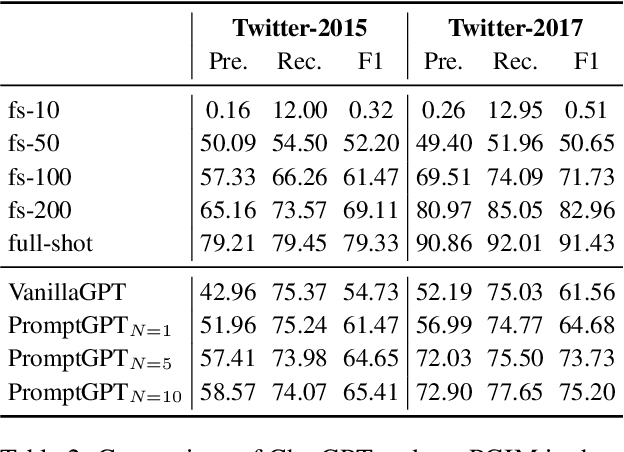
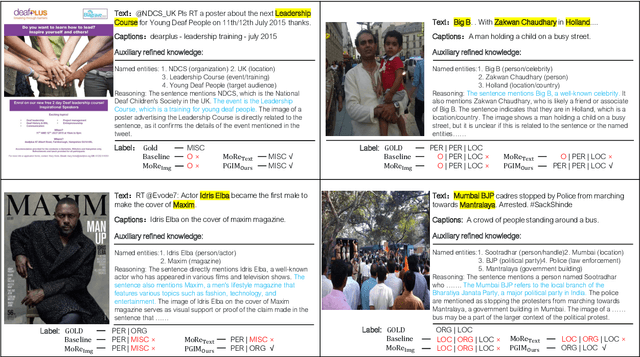
Multimodal Named Entity Recognition (MNER) on social media aims to enhance textual entity prediction by incorporating image-based clues. Existing research in this domain has primarily focused on maximizing the utilization of potentially relevant information in images or incorporating external knowledge from explicit knowledge bases (KBs). However, these methods either neglect the necessity of providing the model with relevant external knowledge, or the retrieved external knowledge suffers from high redundancy. To address these problems, we propose a conceptually simple two-stage framework called Prompt ChatGPT In MNER (PGIM) in this paper. We leverage ChatGPT as an implicit knowledge engine to acquire auxiliary refined knowledge, thereby bolstering the model's performance in MNER tasks. Specifically, we first utilize a Multimodal Similar Example Awareness module to select suitable examples from a small number of manually annotated samples. These examples are then integrated into a formatted prompt template tailored to the MNER task, guiding ChatGPT to generate auxiliary refined knowledge. Finally, the acquired knowledge is integrated with the raw text and inputted into the downstream model for further processing. Extensive experiments show that our PGIM significantly outperforms all existing state-of-the-art methods on two classic MNER datasets.
Learning Hand-Held Object Reconstruction from In-The-Wild Videos
May 04, 2023
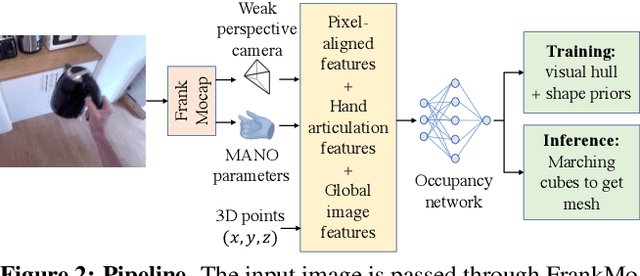

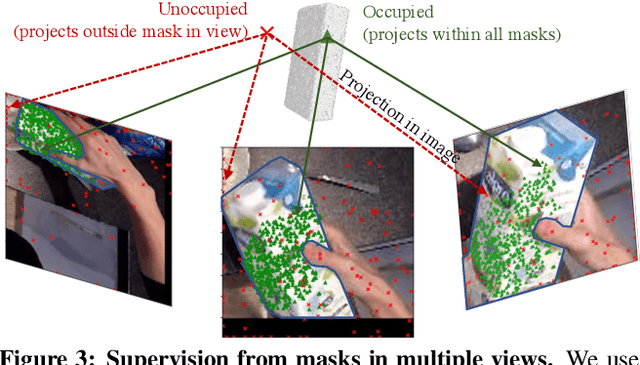
Prior works for reconstructing hand-held objects from a single image rely on direct 3D shape supervision which is challenging to gather in real world at scale. Consequently, these approaches do not generalize well when presented with novel objects in in-the-wild settings. While 3D supervision is a major bottleneck, there is an abundance of in-the-wild raw video data showing hand-object interactions. In this paper, we automatically extract 3D supervision (via multiview 2D supervision) from such raw video data to scale up the learning of models for hand-held object reconstruction. This requires tackling two key challenges: unknown camera pose and occlusion. For the former, we use hand pose (predicted from existing techniques, e.g. FrankMocap) as a proxy for object pose. For the latter, we learn data-driven 3D shape priors using synthetic objects from the ObMan dataset. We use these indirect 3D cues to train occupancy networks that predict the 3D shape of objects from a single RGB image. Our experiments on the MOW and HO3D datasets show the effectiveness of these supervisory signals at predicting the 3D shape for real-world hand-held objects without any direct real-world 3D supervision.
Transformer-based stereo-aware 3D object detection from binocular images
Apr 24, 2023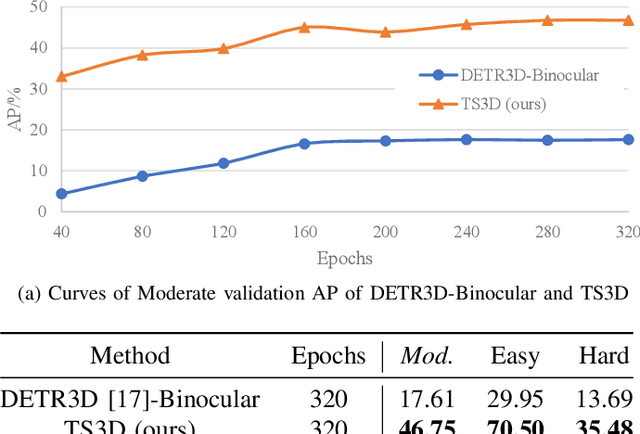
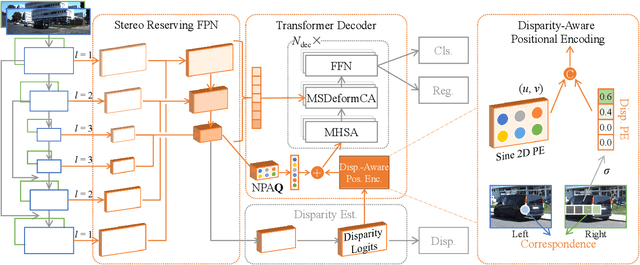
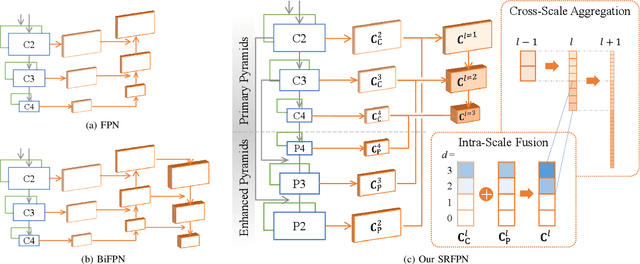

Vision Transformers have shown promising progress in various object detection tasks, including monocular 2D/3D detection and surround-view 3D detection. However, when used in essential and classic stereo 3D object detection, directly adopting those surround-view Transformers leads to slow convergence and significant precision drops. We argue that one of the causes of this defect is that the surround-view Transformers do not consider the stereo-specific image correspondence information. In a surround-view system, the overlapping areas are small, and thus correspondence is not a primary issue. In this paper, we explore the model design of vision Transformers in stereo 3D object detection, focusing particularly on extracting and encoding the task-specific image correspondence information. To achieve this goal, we present TS3D, a Transformer-based Stereo-aware 3D object detector. In the TS3D, a Disparity-Aware Positional Encoding (DAPE) model is proposed to embed the image correspondence information into stereo features. The correspondence is encoded as normalized disparity and is used in conjunction with sinusoidal 2D positional encoding to provide the location information of the 3D scene. To extract enriched multi-scale stereo features, we propose a Stereo Reserving Feature Pyramid Network (SRFPN). The SRFPN is designed to reserve the correspondence information while fusing intra-scale and aggregating cross-scale stereo features. Our proposed TS3D achieves a 41.29% Moderate Car detection average precision on the KITTI test set and takes 88 ms to detect objects from each binocular image pair. It is competitive with advanced counterparts in terms of both precision and inference speed.
Personalized and privacy-preserving federated heterogeneous medical image analysis with PPPML-HMI
Feb 20, 2023Heterogeneous data is endemic due to the use of diverse models and settings of devices by hospitals in the field of medical imaging. However, there are few open-source frameworks for federated heterogeneous medical image analysis with personalization and privacy protection simultaneously without the demand to modify the existing model structures or to share any private data. In this paper, we proposed PPPML-HMI, an open-source learning paradigm for personalized and privacy-preserving federated heterogeneous medical image analysis. To our best knowledge, personalization and privacy protection were achieved simultaneously for the first time under the federated scenario by integrating the PerFedAvg algorithm and designing our novel cyclic secure aggregation with the homomorphic encryption algorithm. To show the utility of PPPML-HMI, we applied it to a simulated classification task namely the classification of healthy people and patients from the RAD-ChestCT Dataset, and one real-world segmentation task namely the segmentation of lung infections from COVID-19 CT scans. For the real-world task, PPPML-HMI achieved $\sim$5\% higher Dice score on average compared to conventional FL under the heterogeneous scenario. Meanwhile, we applied the improved deep leakage from gradients to simulate adversarial attacks and showed the solid privacy-preserving capability of PPPML-HMI. By applying PPPML-HMI to both tasks with different neural networks, a varied number of users, and sample sizes, we further demonstrated the strong robustness of PPPML-HMI.
Batch Model Consolidation: A Multi-Task Model Consolidation Framework
May 25, 2023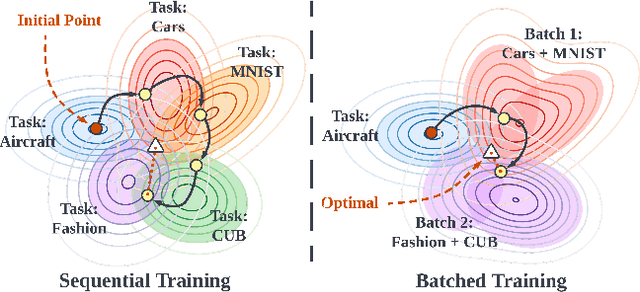
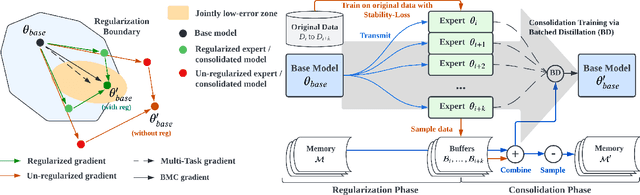
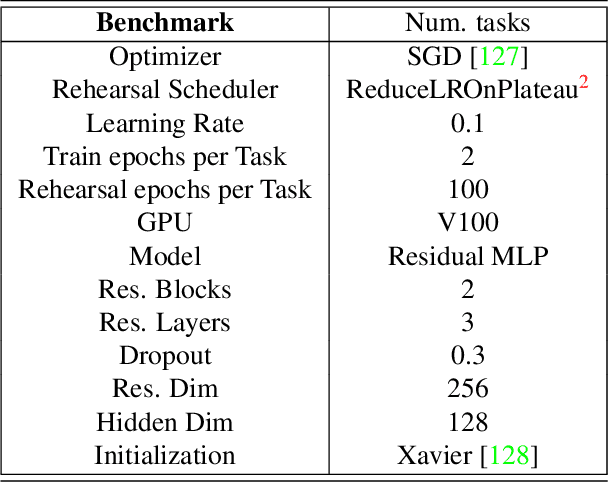
In Continual Learning (CL), a model is required to learn a stream of tasks sequentially without significant performance degradation on previously learned tasks. Current approaches fail for a long sequence of tasks from diverse domains and difficulties. Many of the existing CL approaches are difficult to apply in practice due to excessive memory cost or training time, or are tightly coupled to a single device. With the intuition derived from the widely applied mini-batch training, we propose Batch Model Consolidation ($\textbf{BMC}$) to support more realistic CL under conditions where multiple agents are exposed to a range of tasks. During a $\textit{regularization}$ phase, BMC trains multiple $\textit{expert models}$ in parallel on a set of disjoint tasks. Each expert maintains weight similarity to a $\textit{base model}$ through a $\textit{stability loss}$, and constructs a $\textit{buffer}$ from a fraction of the task's data. During the $\textit{consolidation}$ phase, we combine the learned knowledge on 'batches' of $\textit{expert models}$ using a $\textit{batched consolidation loss}$ in $\textit{memory}$ data that aggregates all buffers. We thoroughly evaluate each component of our method in an ablation study and demonstrate the effectiveness on standardized benchmark datasets Split-CIFAR-100, Tiny-ImageNet, and the Stream dataset composed of 71 image classification tasks from diverse domains and difficulties. Our method outperforms the next best CL approach by 70% and is the only approach that can maintain performance at the end of 71 tasks; Our benchmark can be accessed at https://github.com/fostiropoulos/stream_benchmark
Debiased Mapping for Full-Reference Image Quality Assessment
Feb 22, 2023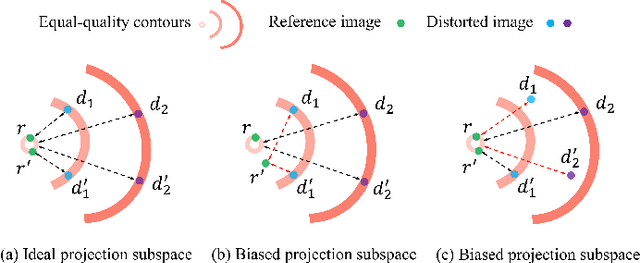
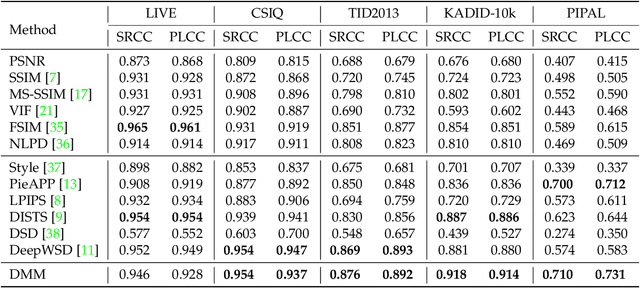


Mapping images to deep feature space for comparisons has been wildly adopted in recent learning-based full-reference image quality assessment (FR-IQA) models. Analogous to the classical classification task, the ideal mapping space for quality regression should possess both inter-class separability and intra-class compactness. The inter-class separability that focuses on the discrimination of images with different quality levels has been highly emphasized in existing models. However, the intra-class compactness that maintains small objective quality variance of images with the same or indistinguishable quality escapes the research attention, potentially leading to the perception-biased measures. In this paper, we reveal that such bias is mainly caused by the unsuitable subspace that the features are projected and compared in. To account for this, we develop the Debiased Mapping based quality Measure (DMM), which relies on the orthonormal bases of deep learning features formed by singular value decomposition (SVD). The SVD in deep learning feature domain, which overwhelmingly separates the quality variations with singular values and projection bases, facilitates the quality inference with dedicatedly designed distance measure. Experiments on different IQA databases demonstrate the mapping method is able to mitigate the perception bias efficiently, and the superior performance on quality prediction verifies the effectiveness of our method. The implementation will be publicly available.
Video4MRI: An Empirical Study on Brain Magnetic Resonance Image Analytics with CNN-based Video Classification Frameworks
Feb 24, 2023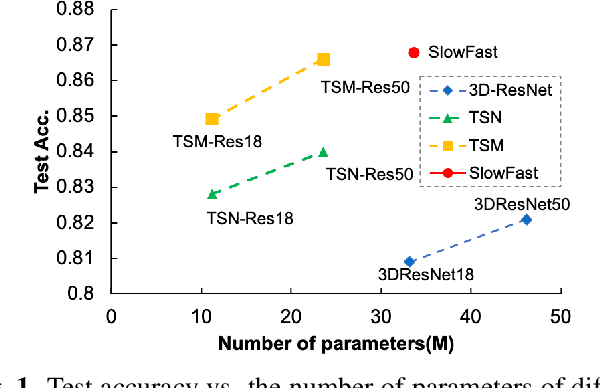

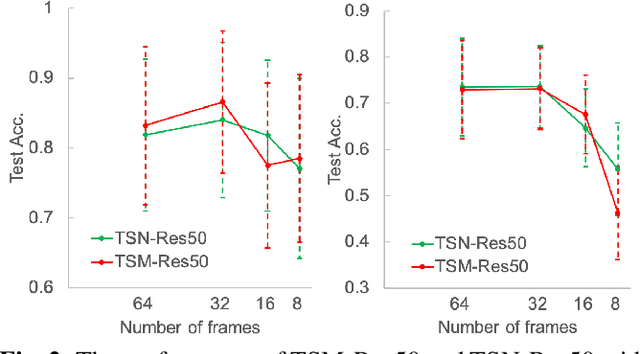

To address the problem of medical image recognition, computer vision techniques like convolutional neural networks (CNN) are frequently used. Recently, 3D CNN-based models dominate the field of magnetic resonance image (MRI) analytics. Due to the high similarity between MRI data and videos, we conduct extensive empirical studies on video recognition techniques for MRI classification to answer the questions: (1) can we directly use video recognition models for MRI classification, (2) which model is more appropriate for MRI, (3) are the common tricks like data augmentation in video recognition still useful for MRI classification? Our work suggests that advanced video techniques benefit MRI classification. In this paper, four datasets of Alzheimer's and Parkinson's disease recognition are utilized in experiments, together with three alternative video recognition models and data augmentation techniques that are frequently applied to video tasks. In terms of efficiency, the results reveal that the video framework performs better than 3D-CNN models by 5% - 11% with 50% - 66% less trainable parameters. This report pushes forward the potential fusion of 3D medical imaging and video understanding research.
Boundary-aware Supervoxel-level Iteratively Refined Interactive 3D Image Segmentation with Multi-agent Reinforcement Learning
Mar 19, 2023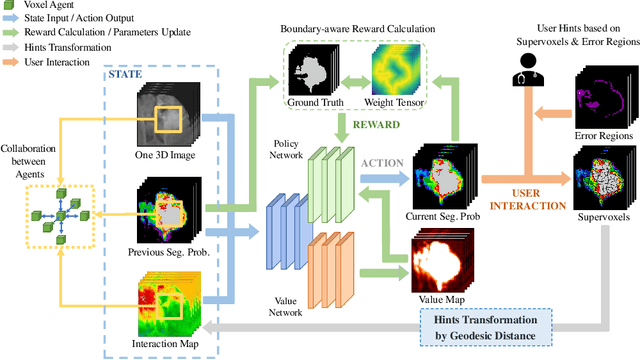
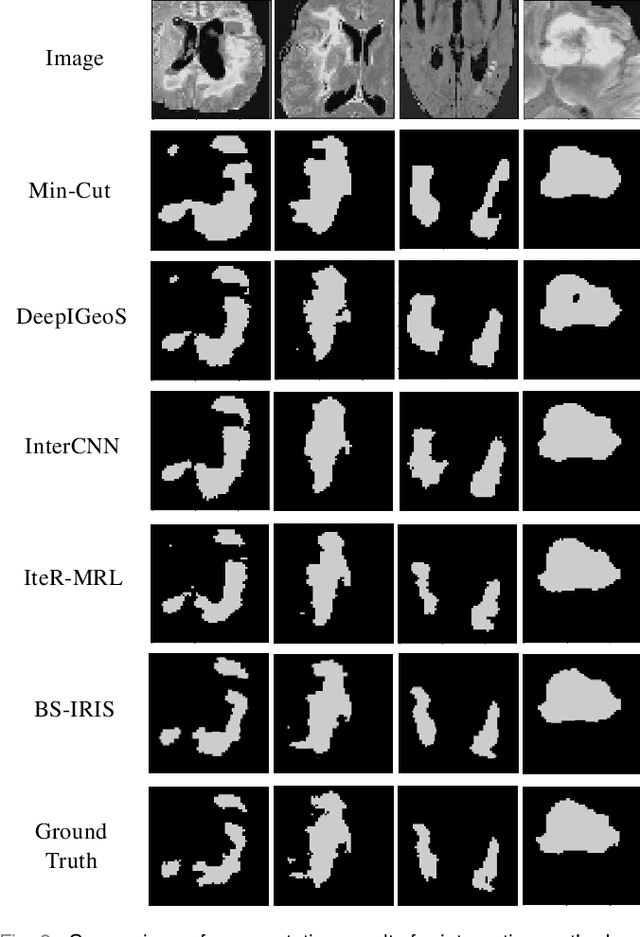
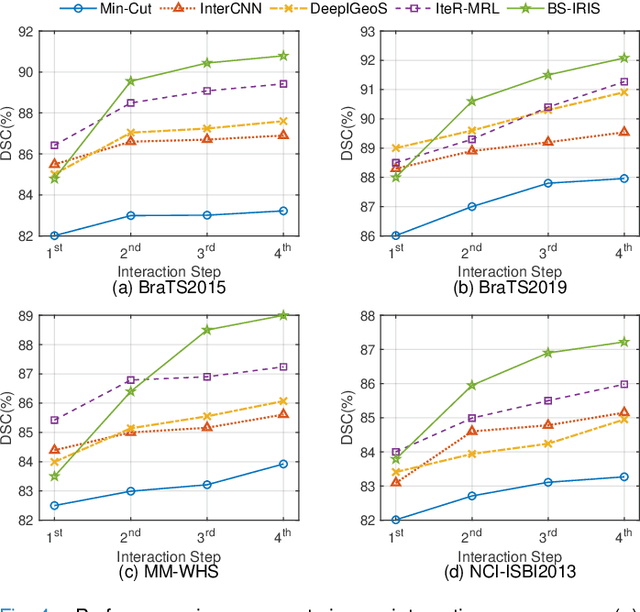
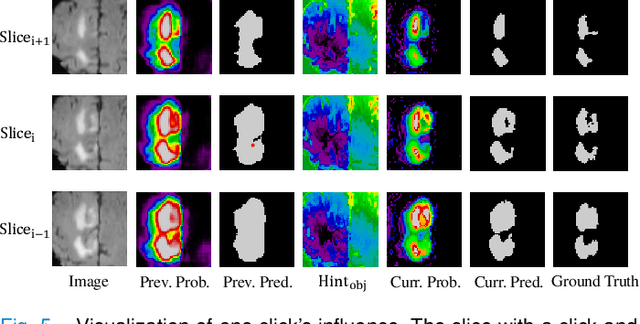
Interactive segmentation has recently been explored to effectively and efficiently harvest high-quality segmentation masks by iteratively incorporating user hints. While iterative in nature, most existing interactive segmentation methods tend to ignore the dynamics of successive interactions and take each interaction independently. We here propose to model iterative interactive image segmentation with a Markov decision process (MDP) and solve it with reinforcement learning (RL) where each voxel is treated as an agent. Considering the large exploration space for voxel-wise prediction and the dependence among neighboring voxels for the segmentation tasks, multi-agent reinforcement learning is adopted, where the voxel-level policy is shared among agents. Considering that boundary voxels are more important for segmentation, we further introduce a boundary-aware reward, which consists of a global reward in the form of relative cross-entropy gain, to update the policy in a constrained direction, and a boundary reward in the form of relative weight, to emphasize the correctness of boundary predictions. To combine the advantages of different types of interactions, i.e., simple and efficient for point-clicking, and stable and robust for scribbles, we propose a supervoxel-clicking based interaction design. Experimental results on four benchmark datasets have shown that the proposed method significantly outperforms the state-of-the-arts, with the advantage of fewer interactions, higher accuracy, and enhanced robustness.
* Accepted by IEEE Transactions on Medical Imaging
DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
Apr 10, 2023

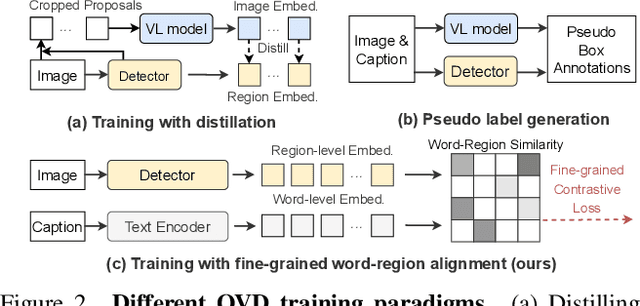
This paper presents DetCLIPv2, an efficient and scalable training framework that incorporates large-scale image-text pairs to achieve open-vocabulary object detection (OVD). Unlike previous OVD frameworks that typically rely on a pre-trained vision-language model (e.g., CLIP) or exploit image-text pairs via a pseudo labeling process, DetCLIPv2 directly learns the fine-grained word-region alignment from massive image-text pairs in an end-to-end manner. To accomplish this, we employ a maximum word-region similarity between region proposals and textual words to guide the contrastive objective. To enable the model to gain localization capability while learning broad concepts, DetCLIPv2 is trained with a hybrid supervision from detection, grounding and image-text pair data under a unified data formulation. By jointly training with an alternating scheme and adopting low-resolution input for image-text pairs, DetCLIPv2 exploits image-text pair data efficiently and effectively: DetCLIPv2 utilizes 13X more image-text pairs than DetCLIP with a similar training time and improves performance. With 13M image-text pairs for pre-training, DetCLIPv2 demonstrates superior open-vocabulary detection performance, e.g., DetCLIPv2 with Swin-T backbone achieves 40.4% zero-shot AP on the LVIS benchmark, which outperforms previous works GLIP/GLIPv2/DetCLIP by 14.4/11.4/4.5% AP, respectively, and even beats its fully-supervised counterpart by a large margin.