 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
Apr 02, 2025



Embodied agents operating in real-world environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent must fetch a specific object instance given an ambiguous instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To solve this problem, we propose a novel approach that fine-tunes multimodal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines, including GPT-4o, and supervised fine-tuned MLLMs, on our task. Our results demonstrate that our RL-finetuned MLLM outperforms all baselines by a significant margin ($19.1$-$40.3\%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024



We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation
Apr 09, 2024



The Embodied AI community has made significant strides in visual navigation tasks, exploring targets from 3D coordinates, objects, language descriptions, and images. However, these navigation models often handle only a single input modality as the target. With the progress achieved so far, it is time to move towards universal navigation models capable of handling various goal types, enabling more effective user interaction with robots. To facilitate this goal, we propose GOAT-Bench, a benchmark for the universal navigation task referred to as GO to AnyThing (GOAT). In this task, the agent is directed to navigate to a sequence of targets specified by the category name, language description, or image in an open-vocabulary fashion. We benchmark monolithic RL and modular methods on the GOAT task, analyzing their performance across modalities, the role of explicit and implicit scene memories, their robustness to noise in goal specifications, and the impact of memory in lifelong scenarios.
Diffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning
Feb 27, 2024



A common failure mode for policies trained with imitation is compounding execution errors at test time. When the learned policy encounters states that were not present in the expert demonstrations, the policy fails, leading to degenerate behavior. The Dataset Aggregation, or DAgger approach to this problem simply collects more data to cover these failure states. However, in practice, this is often prohibitively expensive. In this work, we propose Diffusion Meets DAgger (DMD), a method to reap the benefits of DAgger without the cost for eye-in-hand imitation learning problems. Instead of collecting new samples to cover out-of-distribution states, DMD uses recent advances in diffusion models to create these samples with diffusion models. This leads to robust performance from few demonstrations. In experiments conducted for non-prehensile pushing on a Franka Research 3, we show that DMD can achieve a success rate of 80% with as few as 8 expert demonstrations, where naive behavior cloning reaches only 20%. DMD also outperform competing NeRF-based augmentation schemes by 50%.
3D Hand Pose Estimation in Egocentric Images in the Wild
Dec 11, 2023



We present WildHands, a method for 3D hand pose estimation in egocentric images in the wild. This is challenging due to (a) lack of 3D hand pose annotations for images in the wild, and (b) a form of perspective distortion-induced shape ambiguity that arises in the analysis of crops around hands. For the former, we use auxiliary supervision on in-the-wild data in the form of segmentation masks & grasp labels in addition to 3D supervision available in lab datasets. For the latter, we provide spatial cues about the location of the hand crop in the camera's field of view. Our approach achieves the best 3D hand pose on the ARCTIC leaderboard and outperforms FrankMocap, a popular and robust approach for estimating hand pose in the wild, by 45.3% when evaluated on 2D hand pose on our EPIC-HandKps dataset.
GOAT: GO to Any Thing
Nov 10, 2023



In deployment scenarios such as homes and warehouses, mobile robots are expected to autonomously navigate for extended periods, seamlessly executing tasks articulated in terms that are intuitively understandable by human operators. We present GO To Any Thing (GOAT), a universal navigation system capable of tackling these requirements with three key features: a) Multimodal: it can tackle goals specified via category labels, target images, and language descriptions, b) Lifelong: it benefits from its past experience in the same environment, and c) Platform Agnostic: it can be quickly deployed on robots with different embodiments. GOAT is made possible through a modular system design and a continually augmented instance-aware semantic memory that keeps track of the appearance of objects from different viewpoints in addition to category-level semantics. This enables GOAT to distinguish between different instances of the same category to enable navigation to targets specified by images and language descriptions. In experimental comparisons spanning over 90 hours in 9 different homes consisting of 675 goals selected across 200+ different object instances, we find GOAT achieves an overall success rate of 83%, surpassing previous methods and ablations by 32% (absolute improvement). GOAT improves with experience in the environment, from a 60% success rate at the first goal to a 90% success after exploration. In addition, we demonstrate that GOAT can readily be applied to downstream tasks such as pick and place and social navigation.
Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos
May 25, 2023



The analysis and use of egocentric videos for robotic tasks is made challenging by occlusion due to the hand and the visual mismatch between the human hand and a robot end-effector. In this sense, the human hand presents a nuisance. However, often hands also provide a valuable signal, e.g. the hand pose may suggest what kind of object is being held. In this work, we propose to extract a factored representation of the scene that separates the agent (human hand) and the environment. This alleviates both occlusion and mismatch while preserving the signal, thereby easing the design of models for downstream robotics tasks. At the heart of this factorization is our proposed Video Inpainting via Diffusion Model (VIDM) that leverages both a prior on real-world images (through a large-scale pre-trained diffusion model) and the appearance of the object in earlier frames of the video (through attention). Our experiments demonstrate the effectiveness of VIDM at improving inpainting quality on egocentric videos and the power of our factored representation for numerous tasks: object detection, 3D reconstruction of manipulated objects, and learning of reward functions, policies, and affordances from videos.
Learning Hand-Held Object Reconstruction from In-The-Wild Videos
May 04, 2023Prior works for reconstructing hand-held objects from a single image rely on direct 3D shape supervision which is challenging to gather in real world at scale. Consequently, these approaches do not generalize well when presented with novel objects in in-the-wild settings. While 3D supervision is a major bottleneck, there is an abundance of in-the-wild raw video data showing hand-object interactions. In this paper, we automatically extract 3D supervision (via multiview 2D supervision) from such raw video data to scale up the learning of models for hand-held object reconstruction. This requires tackling two key challenges: unknown camera pose and occlusion. For the former, we use hand pose (predicted from existing techniques, e.g. FrankMocap) as a proxy for object pose. For the latter, we learn data-driven 3D shape priors using synthetic objects from the ObMan dataset. We use these indirect 3D cues to train occupancy networks that predict the 3D shape of objects from a single RGB image. Our experiments on the MOW and HO3D datasets show the effectiveness of these supervisory signals at predicting the 3D shape for real-world hand-held objects without any direct real-world 3D supervision.
One-shot Visual Imitation via Attributed Waypoints and Demonstration Augmentation
Feb 09, 2023



In this paper, we analyze the behavior of existing techniques and design new solutions for the problem of one-shot visual imitation. In this setting, an agent must solve a novel instance of a novel task given just a single visual demonstration. Our analysis reveals that current methods fall short because of three errors: the DAgger problem arising from purely offline training, last centimeter errors in interacting with objects, and mis-fitting to the task context rather than to the actual task. This motivates the design of our modular approach where we a) separate out task inference (what to do) from task execution (how to do it), and b) develop data augmentation and generation techniques to mitigate mis-fitting. The former allows us to leverage hand-crafted motor primitives for task execution which side-steps the DAgger problem and last centimeter errors, while the latter gets the model to focus on the task rather than the task context. Our model gets 100% and 48% success rates on two recent benchmarks, improving upon the current state-of-the-art by absolute 90% and 20% respectively.
Learning Value Functions from Undirected State-only Experience
Apr 26, 2022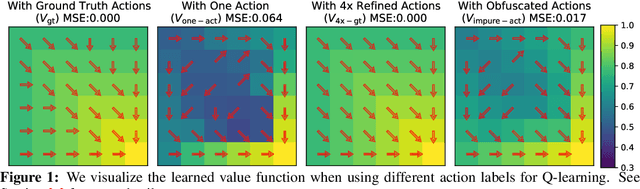



This paper tackles the problem of learning value functions from undirected state-only experience (state transitions without action labels i.e. (s,s',r) tuples). We first theoretically characterize the applicability of Q-learning in this setting. We show that tabular Q-learning in discrete Markov decision processes (MDPs) learns the same value function under any arbitrary refinement of the action space. This theoretical result motivates the design of Latent Action Q-learning or LAQ, an offline RL method that can learn effective value functions from state-only experience. Latent Action Q-learning (LAQ) learns value functions using Q-learning on discrete latent actions obtained through a latent-variable future prediction model. We show that LAQ can recover value functions that have high correlation with value functions learned using ground truth actions. Value functions learned using LAQ lead to sample efficient acquisition of goal-directed behavior, can be used with domain-specific low-level controllers, and facilitate transfer across embodiments. Our experiments in 5 environments ranging from 2D grid world to 3D visual navigation in realistic environments demonstrate the benefits of LAQ over simpler alternatives, imitation learning oracles, and competing methods.