 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAM on Medical Images: A Comprehensive Study on Three Prompt Modes
Apr 28, 2023
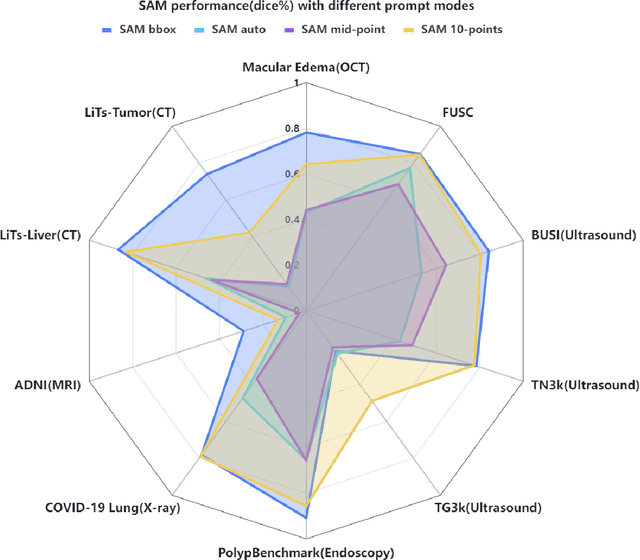
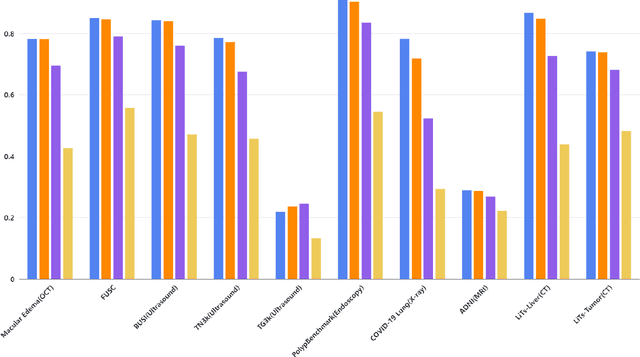
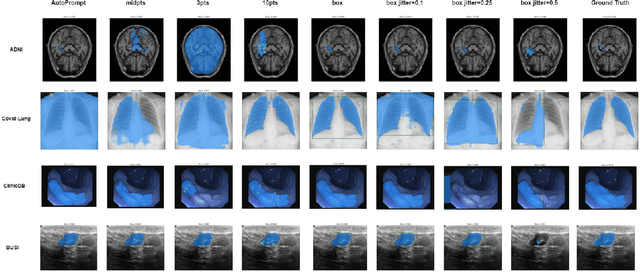

The Segment Anything Model (SAM) made an eye-catching debut recently and inspired many researchers to explore its potential and limitation in terms of zero-shot generalization capability. As the first promptable foundation model for segmentation tasks, it was trained on a large dataset with an unprecedented number of images and annotations. This large-scale dataset and its promptable nature endow the model with strong zero-shot generalization. Although the SAM has shown competitive performance on several datasets, we still want to investigate its zero-shot generalization on medical images. As we know, the acquisition of medical image annotation usually requires a lot of effort from professional practitioners. Therefore, if there exists a foundation model that can give high-quality mask prediction simply based on a few point prompts, this model will undoubtedly become the game changer for medical image analysis. To evaluate whether SAM has the potential to become the foundation model for medical image segmentation tasks, we collected more than 12 public medical image datasets that cover various organs and modalities. We also explore what kind of prompt can lead to the best zero-shot performance with different modalities. Furthermore, we find that a pattern shows that the perturbation of the box size will significantly change the prediction accuracy. Finally, Extensive experiments show that the predicted mask quality varied a lot among different datasets. And providing proper prompts, such as bounding boxes, to the SAM will significantly increase its performance.
PPCR: Learning Pyramid Pixel Context Recalibration Module for Medical Image Classification
Mar 10, 2023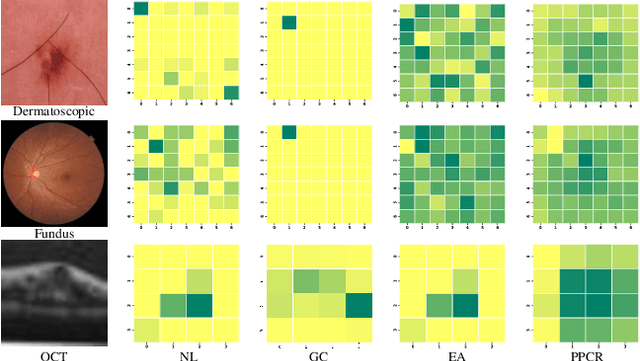
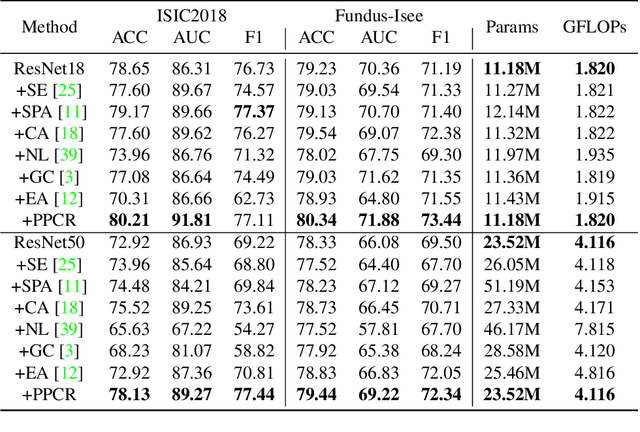
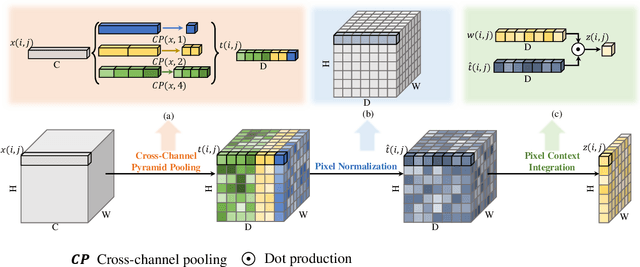
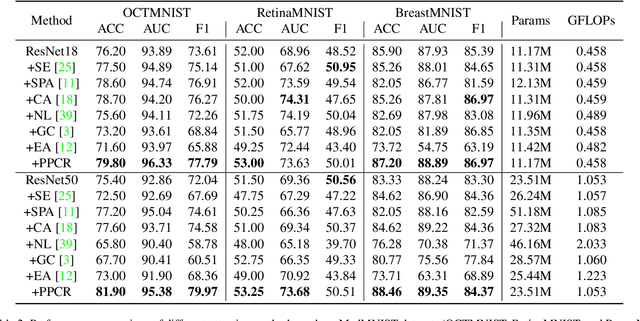
Spatial attention mechanism has been widely incorporated into deep convolutional neural networks (CNNs) via long-range dependency capturing, significantly lifting the performance in computer vision, but it may perform poorly in medical imaging. Unfortunately, existing efforts are often unaware that long-range dependency capturing has limitations in highlighting subtle lesion regions, neglecting to exploit the potential of multi-scale pixel context information to improve the representational capability of CNNs. In this paper, we propose a practical yet lightweight architectural unit, Pyramid Pixel Context Recalibration (PPCR) module, which exploits multi-scale pixel context information to recalibrate pixel position in a pixel-independent manner adaptively. PPCR first designs a cross-channel pyramid pooling to aggregate multi-scale pixel context information, then eliminates the inconsistency among them by the well-designed pixel normalization, and finally estimates per pixel attention weight via a pixel context integration. PPCR can be flexibly plugged into modern CNNs with negligible overhead. Extensive experiments on five medical image datasets and CIFAR benchmarks empirically demonstrate the superiority and generalization of PPCR over state-of-the-art attention methods. The in-depth analyses explain the inherent behavior of PPCR in the decision-making process, improving the interpretability of CNNs.
Structural Multiplane Image: Bridging Neural View Synthesis and 3D Reconstruction
Mar 10, 2023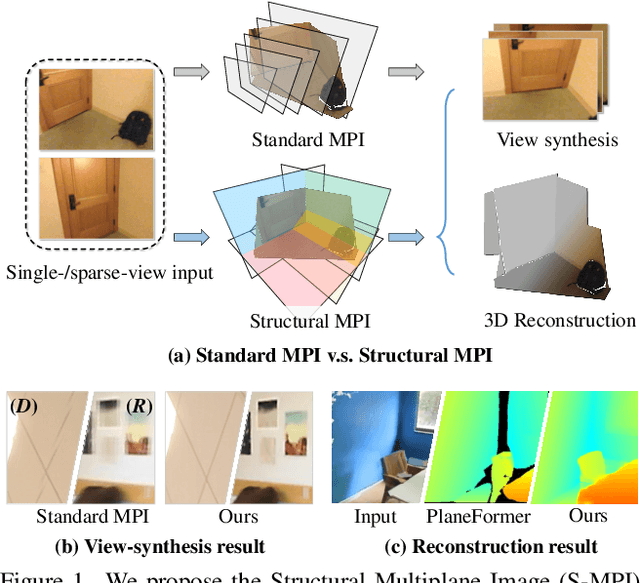
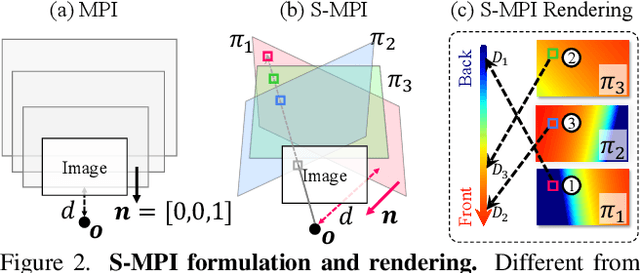
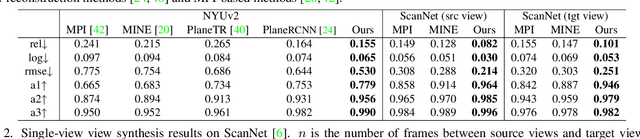
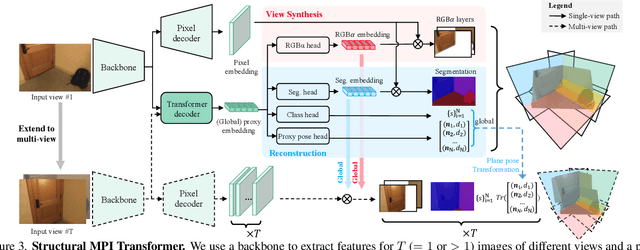
The Multiplane Image (MPI), containing a set of fronto-parallel RGBA layers, is an effective and efficient representation for view synthesis from sparse inputs. Yet, its fixed structure limits the performance, especially for surfaces imaged at oblique angles. We introduce the Structural MPI (S-MPI), where the plane structure approximates 3D scenes concisely. Conveying RGBA contexts with geometrically-faithful structures, the S-MPI directly bridges view synthesis and 3D reconstruction. It can not only overcome the critical limitations of MPI, i.e., discretization artifacts from sloped surfaces and abuse of redundant layers, and can also acquire planar 3D reconstruction. Despite the intuition and demand of applying S-MPI, great challenges are introduced, e.g., high-fidelity approximation for both RGBA layers and plane poses, multi-view consistency, non-planar regions modeling, and efficient rendering with intersected planes. Accordingly, we propose a transformer-based network based on a segmentation model. It predicts compact and expressive S-MPI layers with their corresponding masks, poses, and RGBA contexts. Non-planar regions are inclusively handled as a special case in our unified framework. Multi-view consistency is ensured by sharing global proxy embeddings, which encode plane-level features covering the complete 3D scenes with aligned coordinates. Intensive experiments show that our method outperforms both previous state-of-the-art MPI-based view synthesis methods and planar reconstruction methods.
Global Structure Knowledge-Guided Relation Extraction Method for Visually-Rich Document
May 23, 2023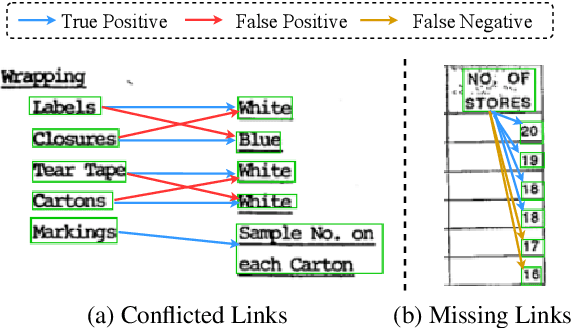
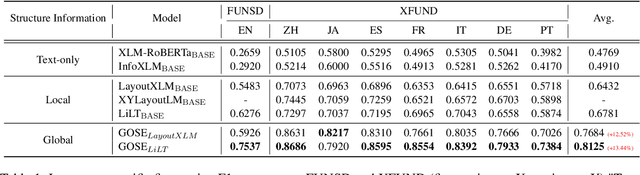
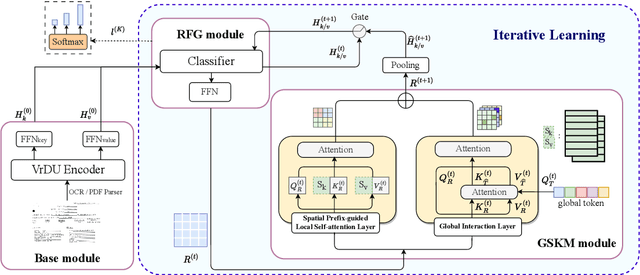
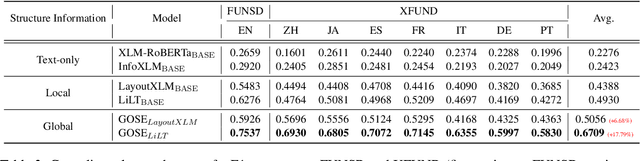
Visual relation extraction (VRE) aims to extract relations between entities from visuallyrich documents. Existing methods usually predict relations for each entity pair independently based on entity features but ignore the global structure information, i.e., dependencies between entity pairs. The absence of global structure information may make the model struggle to learn long-range relations and easily predict conflicted results. To alleviate such limitations, we propose a GlObal Structure knowledgeguided relation Extraction (GOSE) framework, which captures dependencies between entity pairs in an iterative manner. Given a scanned image of the document, GOSE firstly generates preliminary relation predictions on entity pairs. Secondly, it mines global structure knowledge based on prediction results of the previous iteration and further incorporates global structure knowledge into entity representations. This "generate-capture-incorporate" schema is performed multiple times so that entity representations and global structure knowledge can mutually reinforce each other. Extensive experiments show that GOSE not only outperforms previous methods on the standard fine-tuning setting but also shows promising superiority in cross-lingual learning; even yields stronger data-efficient performance in the low-resource setting.
Continual Learning with Strong Experience Replay
May 23, 2023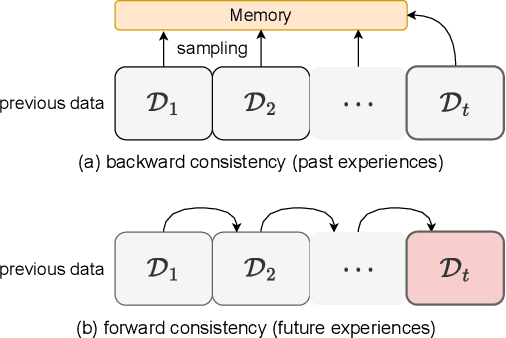
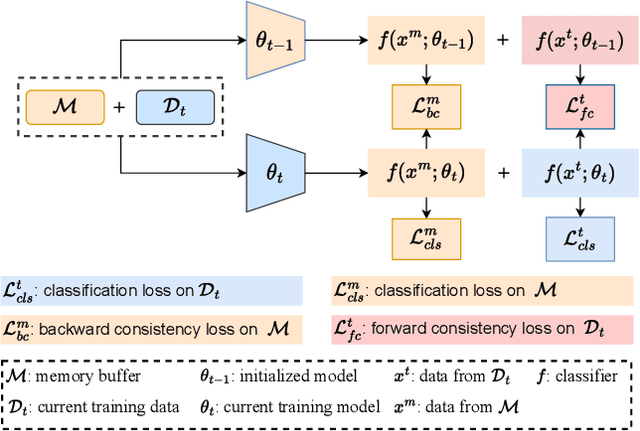
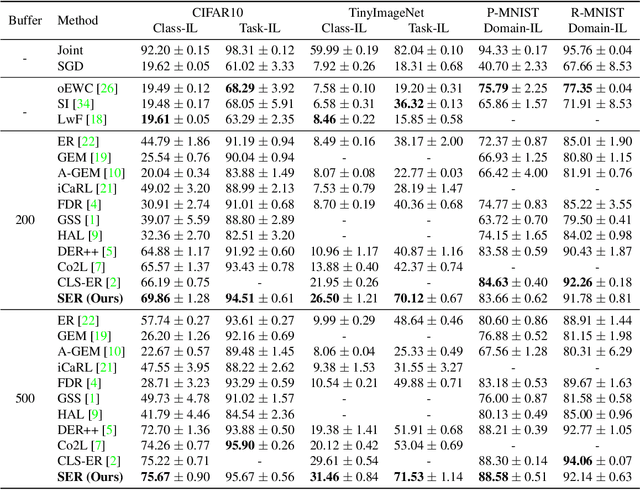
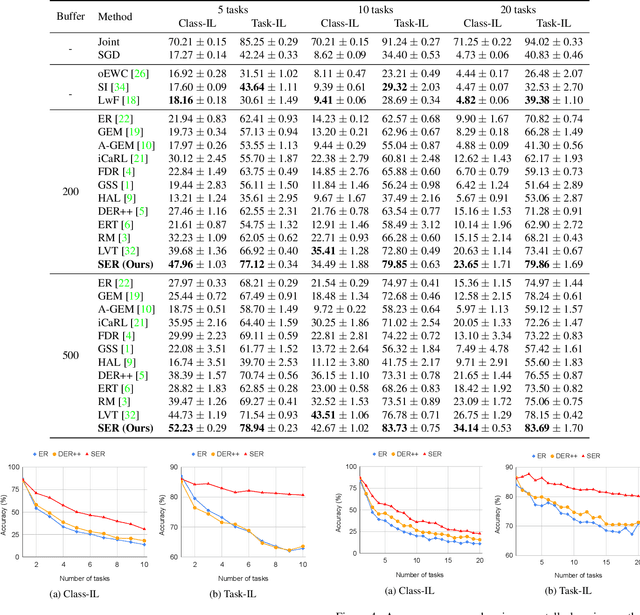
Continual Learning (CL) aims at incrementally learning new tasks without forgetting the knowledge acquired from old ones. Experience Replay (ER) is a simple and effective rehearsal-based strategy, which optimizes the model with current training data and a subset of old samples stored in a memory buffer. To further reduce forgetting, recent approaches extend ER with various techniques, such as model regularization and memory sampling. However, the prediction consistency between the new model and the old one on current training data has been seldom explored, resulting in less knowledge preserved when few previous samples are available. To address this issue, we propose a CL method with Strong Experience Replay (SER), which additionally utilizes future experiences mimicked on the current training data, besides distilling past experience from the memory buffer. In our method, the updated model will produce approximate outputs as its original ones, which can effectively preserve the acquired knowledge. Experimental results on multiple image classification datasets show that our SER method surpasses the state-of-the-art methods by a noticeable margin.
HeteroEdge: Addressing Asymmetry in Heterogeneous Collaborative Autonomous Systems
May 05, 2023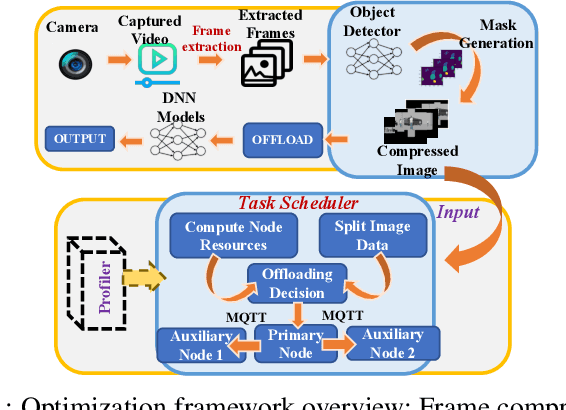

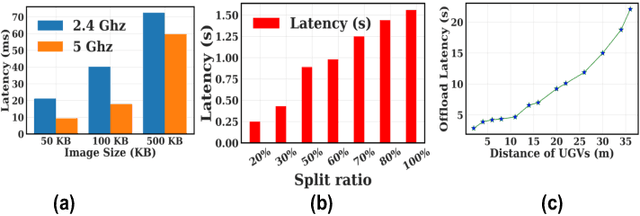

Gathering knowledge about surroundings and generating situational awareness for IoT devices is of utmost importance for systems developed for smart urban and uncontested environments. For example, a large-area surveillance system is typically equipped with multi-modal sensors such as cameras and LIDARs and is required to execute deep learning algorithms for action, face, behavior, and object recognition. However, these systems face power and memory constraints due to their ubiquitous nature, making it crucial to optimize data processing, deep learning algorithm input, and model inference communication. In this paper, we propose a self-adaptive optimization framework for a testbed comprising two Unmanned Ground Vehicles (UGVs) and two NVIDIA Jetson devices. This framework efficiently manages multiple tasks (storage, processing, computation, transmission, inference) on heterogeneous nodes concurrently. It involves compressing and masking input image frames, identifying similar frames, and profiling devices to obtain boundary conditions for optimization.. Finally, we propose and optimize a novel parameter split-ratio, which indicates the proportion of the data required to be offloaded to another device while considering the networking bandwidth, busy factor, memory (CPU, GPU, RAM), and power constraints of the devices in the testbed. Our evaluations captured while executing multiple tasks (e.g., PoseNet, SegNet, ImageNet, DetectNet, DepthNet) simultaneously, reveal that executing 70% (split-ratio=70%) of the data on the auxiliary node minimizes the offloading latency by approx. 33% (18.7 ms/image to 12.5 ms/image) and the total operation time by approx. 47% (69.32s to 36.43s) compared to the baseline configuration (executing on the primary node).
High-Fidelity Image Synthesis from Pulmonary Nodule Lesion Maps using Semantic Diffusion Model
May 02, 2023
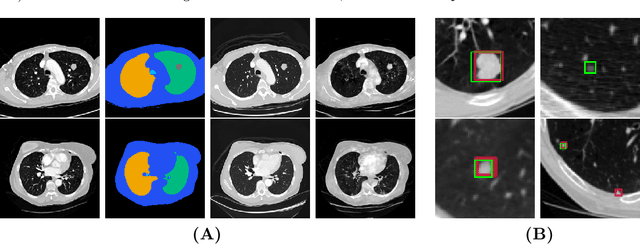
Lung cancer has been one of the leading causes of cancer-related deaths worldwide for years. With the emergence of deep learning, computer-assisted diagnosis (CAD) models based on learning algorithms can accelerate the nodule screening process, providing valuable assistance to radiologists in their daily clinical workflows. However, developing such robust and accurate models often requires large-scale and diverse medical datasets with high-quality annotations. Generating synthetic data provides a pathway for augmenting datasets at a larger scale. Therefore, in this paper, we explore the use of Semantic Diffusion Mod- els (SDM) to generate high-fidelity pulmonary CT images from segmentation maps. We utilize annotation information from the LUNA16 dataset to create paired CT images and masks, and assess the quality of the generated images using the Frechet Inception Distance (FID), as well as on two common clinical downstream tasks: nodule detection and nodule localization. Achieving improvements of 3.96% for detection accuracy and 8.50% for AP50 in nodule localization task, respectively, demonstrates the feasibility of the approach.
Progressive Scale-aware Network for Remote sensing Image Change Captioning
Mar 01, 2023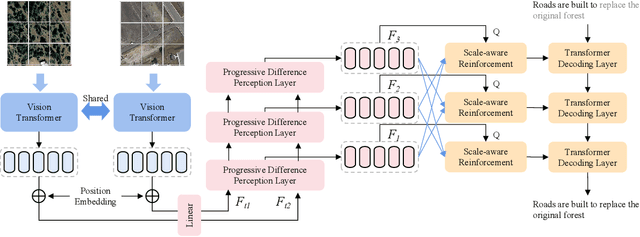
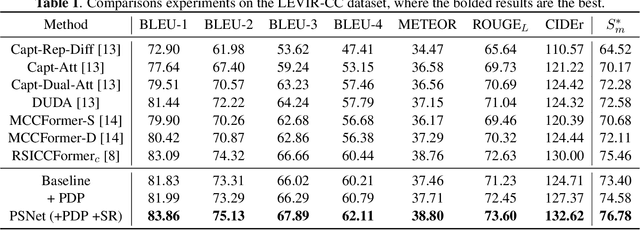
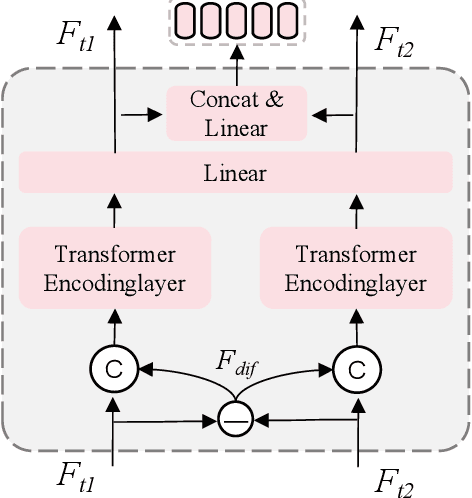
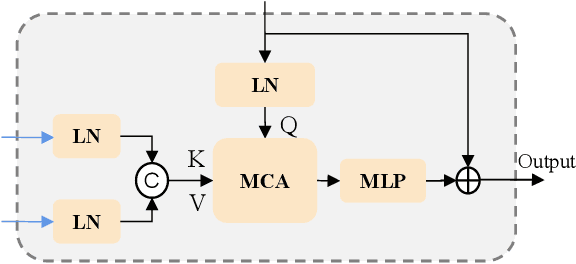
Remote sensing (RS) images contain numerous objects of different scales, which poses significant challenges for the RS image change captioning (RSICC) task to identify visual changes of interest in complex scenes and describe them via language. However, current methods still have some weaknesses in sufficiently extracting and utilizing multi-scale information. In this paper, we propose a progressive scale-aware network (PSNet) to address the problem. PSNet is a pure Transformer-based model. To sufficiently extract multi-scale visual features, multiple progressive difference perception (PDP) layers are stacked to progressively exploit the differencing features of bitemporal features. To sufficiently utilize the extracted multi-scale features for captioning, we propose a scale-aware reinforcement (SR) module and combine it with the Transformer decoding layer to progressively utilize the features from different PDP layers. Experiments show that the PDP layer and SR module are effective and our PSNet outperforms previous methods.
BIRD-PCC: Bi-directional Range Image-based Deep LiDAR Point Cloud Compression
Mar 09, 2023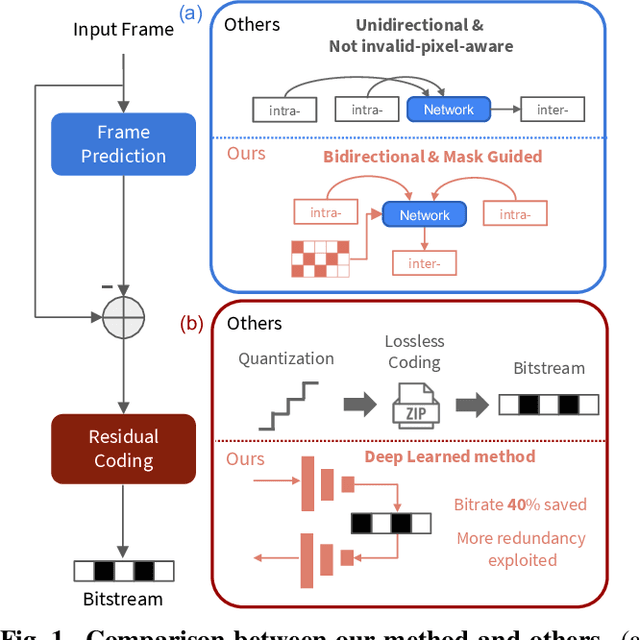
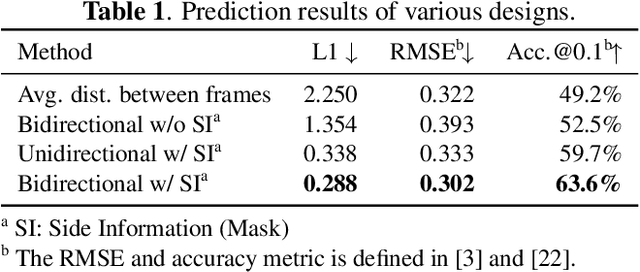
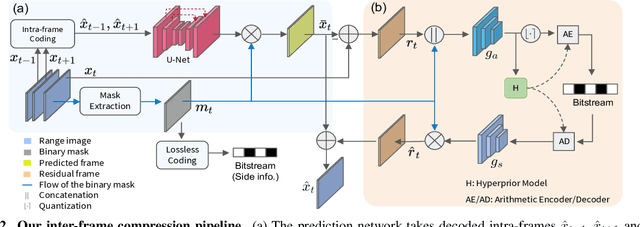
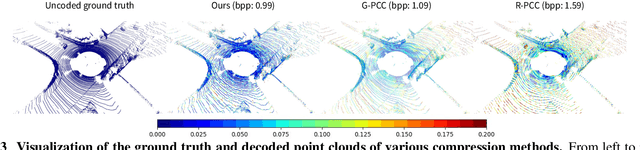
The large amount of data collected by LiDAR sensors brings the issue of LiDAR point cloud compression (PCC). Previous works on LiDAR PCC have used range image representations and followed the predictive coding paradigm to create a basic prototype of a coding framework. However, their prediction methods give an inaccurate result due to the negligence of invalid pixels in range images and the omission of future frames in the time step. Moreover, their handcrafted design of residual coding methods could not fully exploit spatial redundancy. To remedy this, we propose a coding framework BIRD-PCC. Our prediction module is aware of the coordinates of invalid pixels in range images and takes a bidirectional scheme. Also, we introduce a deep-learned residual coding module that can further exploit spatial redundancy within a residual frame. Experiments conducted on SemanticKITTI and KITTI-360 datasets show that BIRD-PCC outperforms other methods in most bitrate conditions and generalizes well to unseen environments.
Multistage Spatial Context Models for Learned Image Compression
Feb 18, 2023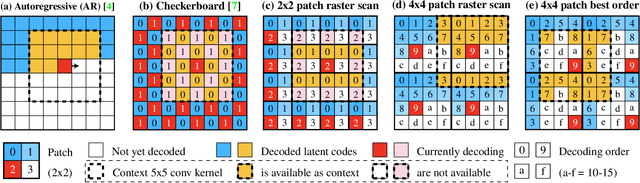

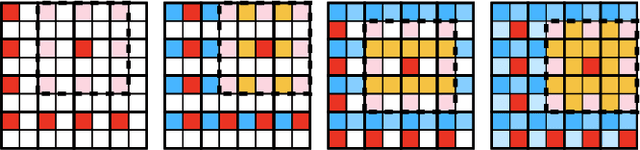
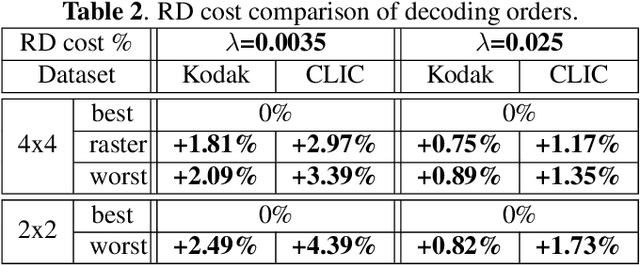
Recent state-of-the-art Learned Image Compression methods feature spatial context models, achieving great rate-distortion improvements over hyperprior methods. However, the autoregressive context model requires serial decoding, limiting runtime performance. The Checkerboard context model allows parallel decoding at a cost of reduced RD performance. We present a series of multistage spatial context models allowing both fast decoding and better RD performance. We split the latent space into square patches and decode serially within each patch while different patches are decoded in parallel. The proposed method features a comparable decoding speed to Checkerboard while reaching the RD performance of Autoregressive and even also outperforming Autoregressive. Inside each patch, the decoding order must be carefully decided as a bad order negatively impacts performance; therefore, we also propose a decoding order optimization algorithm.