 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA: Feature Gradient Enhanced Affine-Flow Matching for SAR-Optical Registration
Nov 17, 2025



Achieving pixel-level registration between SAR and optical images remains a challenging task due to their fundamentally different imaging mechanisms and visual characteristics. Although deep learning has achieved great success in many cross-modal tasks, its performance on SAR-Optical registration tasks is still unsatisfactory. Gradient-based information has traditionally played a crucial role in handcrafted descriptors by highlighting structural differences. However, such gradient cues have not been effectively leveraged in deep learning frameworks for SAR-Optical image matching. To address this gap, we propose SOMA, a dense registration framework that integrates structural gradient priors into deep features and refines alignment through a hybrid matching strategy. Specifically, we introduce the Feature Gradient Enhancer (FGE), which embeds multi-scale, multi-directional gradient filters into the feature space using attention and reconstruction mechanisms to boost feature distinctiveness. Furthermore, we propose the Global-Local Affine-Flow Matcher (GLAM), which combines affine transformation and flow-based refinement within a coarse-to-fine architecture to ensure both structural consistency and local accuracy. Experimental results demonstrate that SOMA significantly improves registration precision, increasing the CMR@1px by 12.29% on the SEN1-2 dataset and 18.50% on the GFGE_SO dataset. In addition, SOMA exhibits strong robustness and generalizes well across diverse scenes and resolutions.
Adaptive Spatial Augmentation for Semi-supervised Semantic Segmentation
May 29, 2025



In semi-supervised semantic segmentation (SSSS), data augmentation plays a crucial role in the weak-to-strong consistency regularization framework, as it enhances diversity and improves model generalization. Recent strong augmentation methods have primarily focused on intensity-based perturbations, which have minimal impact on the semantic masks. In contrast, spatial augmentations like translation and rotation have long been acknowledged for their effectiveness in supervised semantic segmentation tasks, but they are often ignored in SSSS. In this work, we demonstrate that spatial augmentation can also contribute to model training in SSSS, despite generating inconsistent masks between the weak and strong augmentations. Furthermore, recognizing the variability among images, we propose an adaptive augmentation strategy that dynamically adjusts the augmentation for each instance based on entropy. Extensive experiments show that our proposed Adaptive Spatial Augmentation (\textbf{ASAug}) can be integrated as a pluggable module, consistently improving the performance of existing methods and achieving state-of-the-art results on benchmark datasets such as PASCAL VOC 2012, Cityscapes, and COCO.
RGB-T Object Detection via Group Shuffled Multi-receptive Attention and Multi-modal Supervision
May 29, 2024



Multispectral object detection, utilizing both visible (RGB) and thermal infrared (T) modals, has garnered significant attention for its robust performance across diverse weather and lighting conditions. However, effectively exploiting the complementarity between RGB-T modals while maintaining efficiency remains a critical challenge. In this paper, a very simple Group Shuffled Multi-receptive Attention (GSMA) module is proposed to extract and combine multi-scale RGB and thermal features. Then, the extracted multi-modal features are directly integrated with a multi-level path aggregation neck, which significantly improves the fusion effect and efficiency. Meanwhile, multi-modal object detection often adopts union annotations for both modals. This kind of supervision is not sufficient and unfair, since objects observed in one modal may not be seen in the other modal. To solve this issue, Multi-modal Supervision (MS) is proposed to sufficiently supervise RGB-T object detection. Comprehensive experiments on two challenging benchmarks, KAIST and DroneVehicle, demonstrate the proposed model achieves the state-of-the-art accuracy while maintaining competitive efficiency.
DDF: A Novel Dual-Domain Image Fusion Strategy for Remote Sensing Image Semantic Segmentation with Unsupervised Domain Adaptation
Mar 05, 2024



Semantic segmentation of remote sensing images is a challenging and hot issue due to the large amount of unlabeled data. Unsupervised domain adaptation (UDA) has proven to be advantageous in incorporating unclassified information from the target domain. However, independently fine-tuning UDA models on the source and target domains has a limited effect on the outcome. This paper proposes a hybrid training strategy as well as a novel dual-domain image fusion strategy that effectively utilizes the original image, transformation image, and intermediate domain information. Moreover, to enhance the precision of pseudo-labels, we present a pseudo-label region-specific weight strategy. The efficacy of our approach is substantiated by extensive benchmark experiments and ablation studies conducted on the ISPRS Vaihingen and Potsdam datasets.
Hand-Centric Motion Refinement for 3D Hand-Object Interaction via Hierarchical Spatial-Temporal Modeling
Jan 29, 2024Hands are the main medium when people interact with the world. Generating proper 3D motion for hand-object interaction is vital for applications such as virtual reality and robotics. Although grasp tracking or object manipulation synthesis can produce coarse hand motion, this kind of motion is inevitably noisy and full of jitter. To address this problem, we propose a data-driven method for coarse motion refinement. First, we design a hand-centric representation to describe the dynamic spatial-temporal relation between hands and objects. Compared to the object-centric representation, our hand-centric representation is straightforward and does not require an ambiguous projection process that converts object-based prediction into hand motion. Second, to capture the dynamic clues of hand-object interaction, we propose a new architecture that models the spatial and temporal structure in a hierarchical manner. Extensive experiments demonstrate that our method outperforms previous methods by a noticeable margin.
Prior-Free Continual Learning with Unlabeled Data in the Wild
Oct 16, 2023



Continual Learning (CL) aims to incrementally update a trained model on new tasks without forgetting the acquired knowledge of old ones. Existing CL methods usually reduce forgetting with task priors, \ie using task identity or a subset of previously seen samples for model training. However, these methods would be infeasible when such priors are unknown in real-world applications. To address this fundamental but seldom-studied problem, we propose a Prior-Free Continual Learning (PFCL) method, which learns new tasks without knowing the task identity or any previous data. First, based on a fixed single-head architecture, we eliminate the need for task identity to select the task-specific output head. Second, we employ a regularization-based strategy for consistent predictions between the new and old models, avoiding revisiting previous samples. However, using this strategy alone often performs poorly in class-incremental scenarios, particularly for a long sequence of tasks. By analyzing the effectiveness and limitations of conventional regularization-based methods, we propose enhancing model consistency with an auxiliary unlabeled dataset additionally. Moreover, since some auxiliary data may degrade the performance, we further develop a reliable sample selection strategy to obtain consistent performance improvement. Extensive experiments on multiple image classification benchmark datasets show that our PFCL method significantly mitigates forgetting in all three learning scenarios. Furthermore, when compared to the most recent rehearsal-based methods that replay a limited number of previous samples, PFCL achieves competitive accuracy. Our code is available at: https://github.com/visiontao/pfcl
Continual Learning with Strong Experience Replay
May 23, 2023



Continual Learning (CL) aims at incrementally learning new tasks without forgetting the knowledge acquired from old ones. Experience Replay (ER) is a simple and effective rehearsal-based strategy, which optimizes the model with current training data and a subset of old samples stored in a memory buffer. To further reduce forgetting, recent approaches extend ER with various techniques, such as model regularization and memory sampling. However, the prediction consistency between the new model and the old one on current training data has been seldom explored, resulting in less knowledge preserved when few previous samples are available. To address this issue, we propose a CL method with Strong Experience Replay (SER), which additionally utilizes future experiences mimicked on the current training data, besides distilling past experience from the memory buffer. In our method, the updated model will produce approximate outputs as its original ones, which can effectively preserve the acquired knowledge. Experimental results on multiple image classification datasets show that our SER method surpasses the state-of-the-art methods by a noticeable margin.
Temporal Action Localization with Multi-temporal Scales
Aug 16, 2022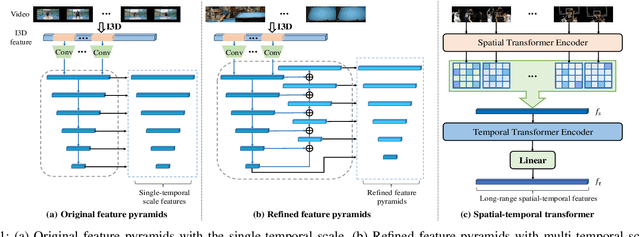
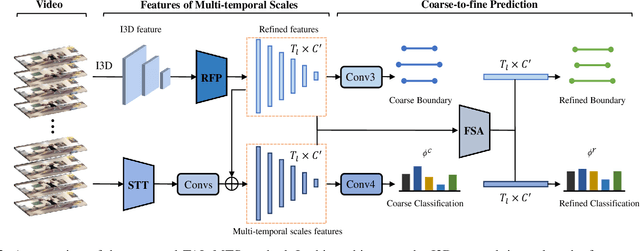
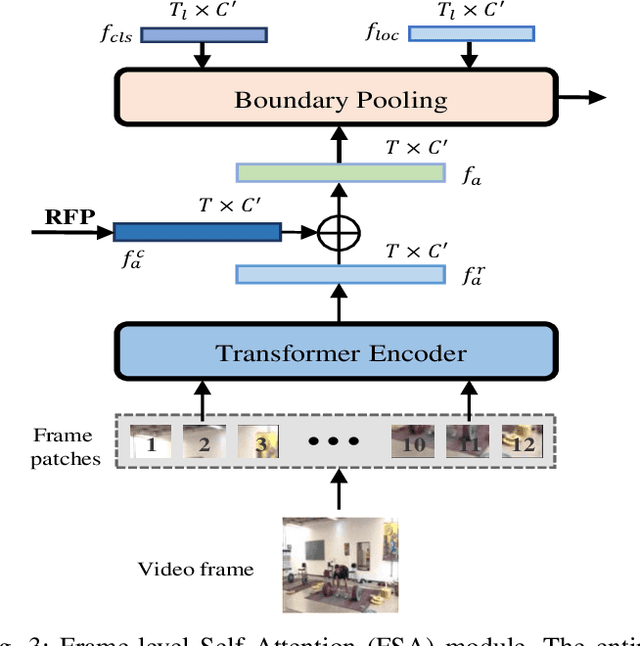
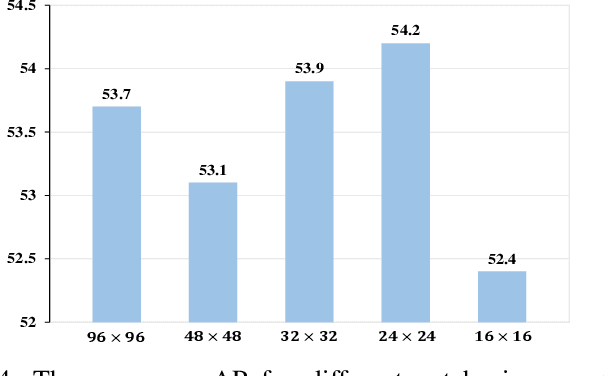
Temporal action localization plays an important role in video analysis, which aims to localize and classify actions in untrimmed videos. The previous methods often predict actions on a feature space of a single-temporal scale. However, the temporal features of a low-level scale lack enough semantics for action classification while a high-level scale cannot provide rich details of the action boundaries. To address this issue, we propose to predict actions on a feature space of multi-temporal scales. Specifically, we use refined feature pyramids of different scales to pass semantics from high-level scales to low-level scales. Besides, to establish the long temporal scale of the entire video, we use a spatial-temporal transformer encoder to capture the long-range dependencies of video frames. Then the refined features with long-range dependencies are fed into a classifier for the coarse action prediction. Finally, to further improve the prediction accuracy, we propose to use a frame-level self attention module to refine the classification and boundaries of each action instance. Extensive experiments show that the proposed method can outperform state-of-the-art approaches on the THUMOS14 dataset and achieves comparable performance on the ActivityNet1.3 dataset. Compared with A2Net (TIP20, Avg\{0.3:0.7\}), Sub-Action (CSVT2022, Avg\{0.1:0.5\}), and AFSD (CVPR21, Avg\{0.3:0.7\}) on the THUMOS14 dataset, the proposed method can achieve improvements of 12.6\%, 17.4\% and 2.2\%, respectively
Effective Abstract Reasoning with Dual-Contrast Network
May 27, 2022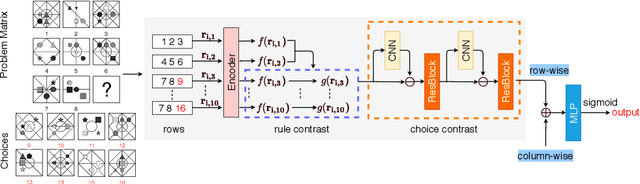
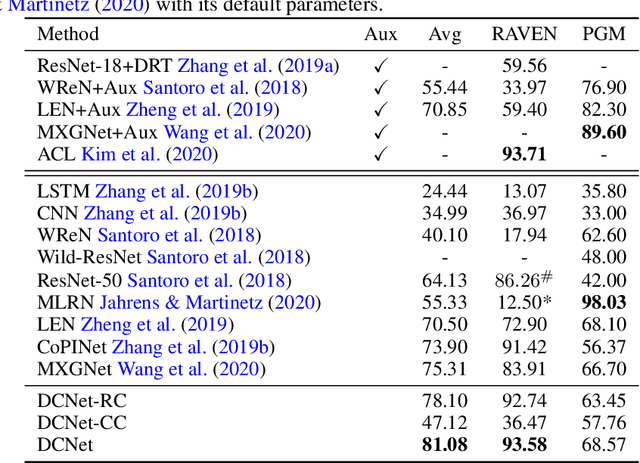
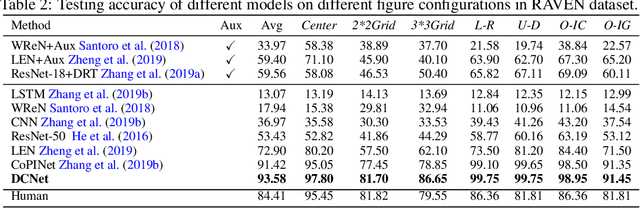
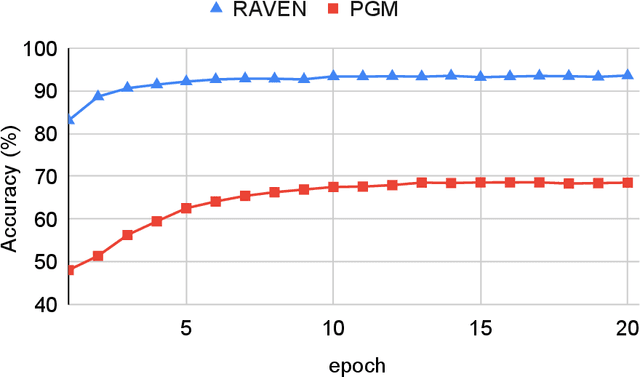
As a step towards improving the abstract reasoning capability of machines, we aim to solve Raven's Progressive Matrices (RPM) with neural networks, since solving RPM puzzles is highly correlated with human intelligence. Unlike previous methods that use auxiliary annotations or assume hidden rules to produce appropriate feature representation, we only use the ground truth answer of each question for model learning, aiming for an intelligent agent to have a strong learning capability with a small amount of supervision. Based on the RPM problem formulation, the correct answer filled into the missing entry of the third row/column has to best satisfy the same rules shared between the first two rows/columns. Thus we design a simple yet effective Dual-Contrast Network (DCNet) to exploit the inherent structure of RPM puzzles. Specifically, a rule contrast module is designed to compare the latent rules between the filled row/column and the first two rows/columns; a choice contrast module is designed to increase the relative differences between candidate choices. Experimental results on the RAVEN and PGM datasets show that DCNet outperforms the state-of-the-art methods by a large margin of 5.77%. Further experiments on few training samples and model generalization also show the effectiveness of DCNet. Code is available at https://github.com/visiontao/dcnet.
Unsupervised Abstract Reasoning for Raven's Problem Matrices
Sep 21, 2021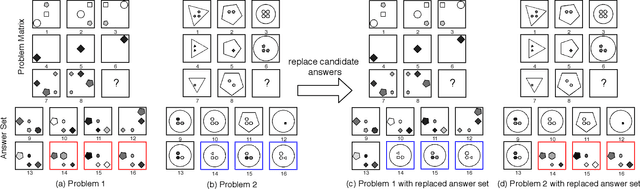
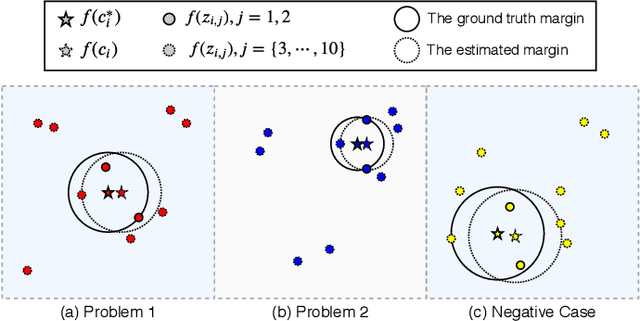
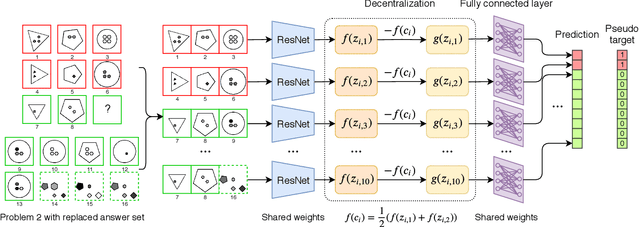
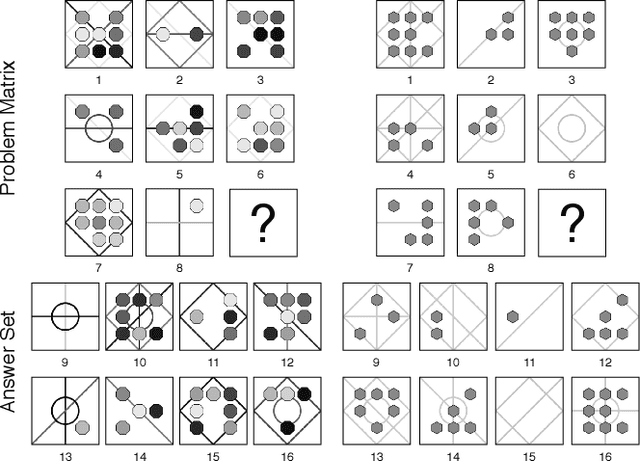
Raven's Progressive Matrices (RPM) is highly correlated with human intelligence, and it has been widely used to measure the abstract reasoning ability of humans. In this paper, to study the abstract reasoning capability of deep neural networks, we propose the first unsupervised learning method for solving RPM problems. Since the ground truth labels are not allowed, we design a pseudo target based on the prior constraints of the RPM formulation to approximate the ground truth label, which effectively converts the unsupervised learning strategy into a supervised one. However, the correct answer is wrongly labelled by the pseudo target, and thus the noisy contrast will lead to inaccurate model training. To alleviate this issue, we propose to improve the model performance with negative answers. Moreover, we develop a decentralization method to adapt the feature representation to different RPM problems. Extensive experiments on three datasets demonstrate that our method even outperforms some of the supervised approaches. Our code is available at https://github.com/visiontao/ncd.