 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SCANet: Self-Paced Semi-Curricular Attention Network for Non-Homogeneous Image Dehazing
Apr 17, 2023


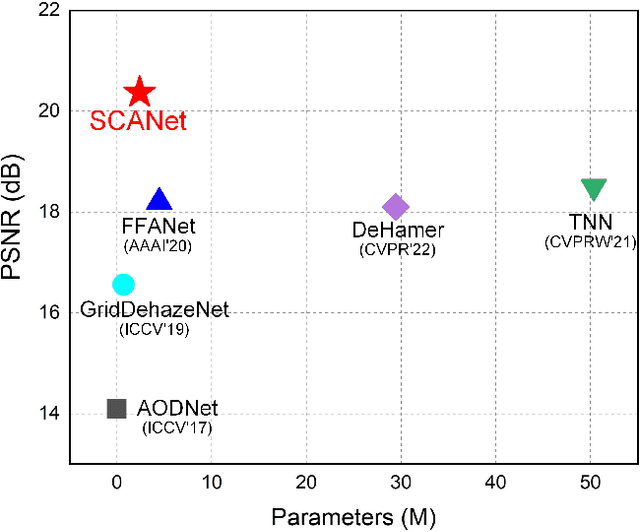
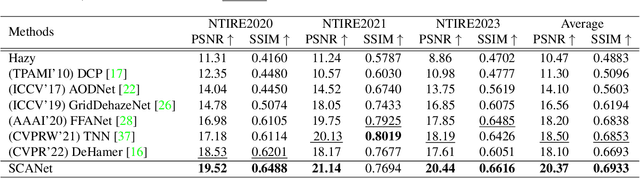
The presence of non-homogeneous haze can cause scene blurring, color distortion, low contrast, and other degradations that obscure texture details. Existing homogeneous dehazing methods struggle to handle the non-uniform distribution of haze in a robust manner. The crucial challenge of non-homogeneous dehazing is to effectively extract the non-uniform distribution features and reconstruct the details of hazy areas with high quality. In this paper, we propose a novel self-paced semi-curricular attention network, called SCANet, for non-homogeneous image dehazing that focuses on enhancing haze-occluded regions. Our approach consists of an attention generator network and a scene reconstruction network. We use the luminance differences of images to restrict the attention map and introduce a self-paced semi-curricular learning strategy to reduce learning ambiguity in the early stages of training. Extensive quantitative and qualitative experiments demonstrate that our SCANet outperforms many state-of-the-art methods. The code is publicly available at https://github.com/gy65896/SCANet.
ELEV-VISION: Automated Lowest Floor Elevation Estimation from Segmenting Street View Images
Jun 05, 2023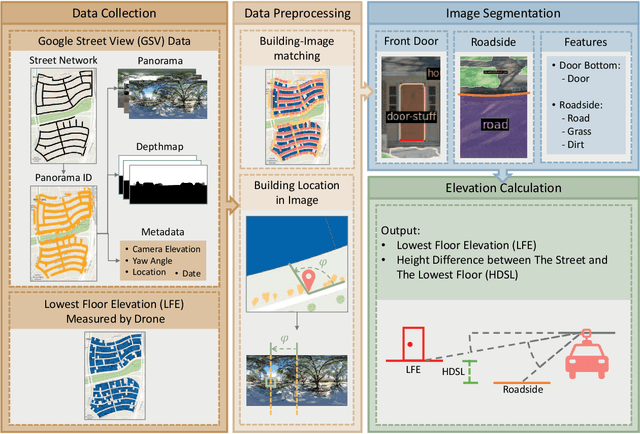

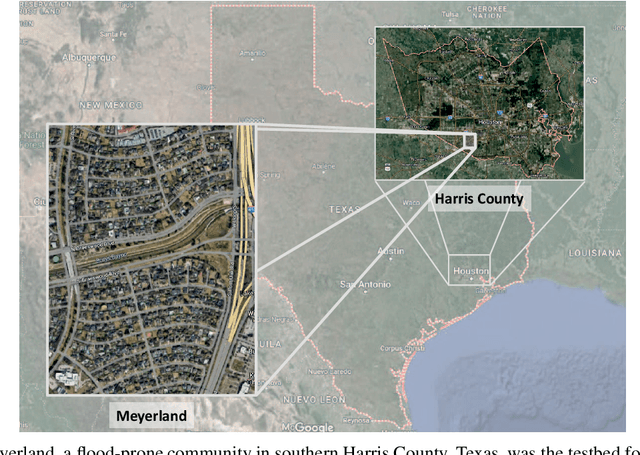

We propose an automated lowest floor elevation (LFE) estimation algorithm based on computer vision techniques to leverage the latent information in street view images. Flood depth-damage models use a combination of LFE and flood depth for determining flood risk and extent of damage to properties. We used image segmentation for detecting door bottoms and roadside edges from Google Street View images. The characteristic of equirectangular projection with constant spacing representation of horizontal and vertical angles allows extraction of the pitch angle from the camera to the door bottom. The depth from the camera to the door bottom was obtained from the depthmap paired with the Google Street View image. LFEs were calculated from the pitch angle and the depth. The testbed for application of the proposed method is Meyerland (Harris County, Texas). The results show that the proposed method achieved mean absolute error of 0.190 m (1.18 %) in estimating LFE. The height difference between the street and the lowest floor (HDSL) was estimated to provide information for flood damage estimation. The proposed automatic LFE estimation algorithm using Street View images and image segmentation provides a rapid and cost-effective method for LFE estimation compared with the surveys using total station theodolite and unmanned aerial systems. By obtaining more accurate and up-to-date LFE data using the proposed method, city planners, emergency planners and insurance companies could make a more precise estimation of flood damage.
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
Jun 07, 2023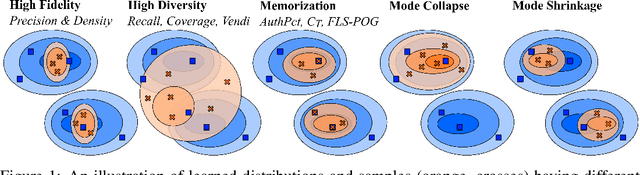

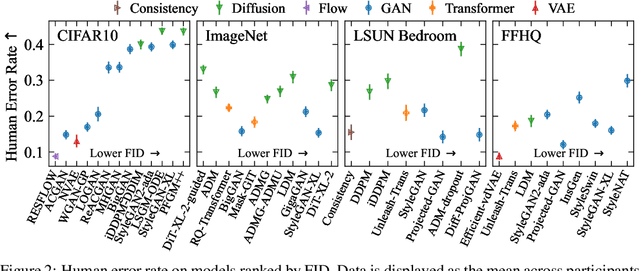
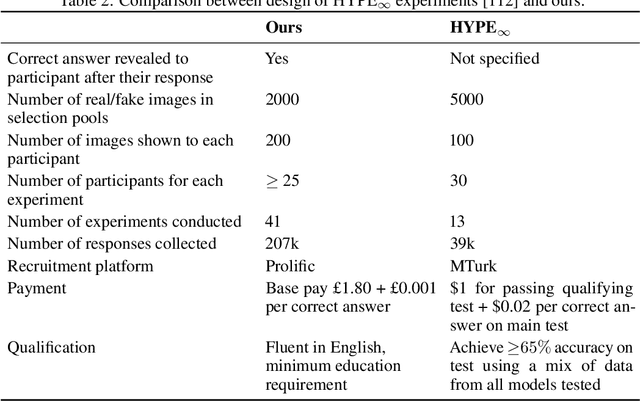
We systematically study a wide variety of image-based generative models spanning semantically-diverse datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best practices in psychophysics, we measure human perception of image realism for generated samples by conducting the largest experiment evaluating generative models to date, and find that no existing metric strongly correlates with human evaluations. Comparing to 16 modern metrics for evaluating the overall performance, fidelity, diversity, and memorization of generative models, we find that the state-of-the-art perceptual realism of diffusion models as judged by humans is not reflected in commonly reported metrics such as FID. This discrepancy is not explained by diversity in generated samples, though one cause is over-reliance on Inception-V3. We address these flaws through a study of alternative self-supervised feature extractors, find that the semantic information encoded by individual networks strongly depends on their training procedure, and show that DINOv2-ViT-L/14 allows for much richer evaluation of generative models. Next, we investigate data memorization, and find that generative models do memorize training examples on simple, smaller datasets like CIFAR10, but not necessarily on more complex datasets like ImageNet. However, our experiments show that current metrics do not properly detect memorization; none in the literature is able to separate memorization from other phenomena such as underfitting or mode shrinkage. To facilitate further development of generative models and their evaluation we release all generated image datasets, human evaluation data, and a modular library to compute 16 common metrics for 8 different encoders at https://github.com/layer6ai-labs/dgm-eval.
GPT4Image: Can Large Pre-trained Models Help Vision Models on Perception Tasks?
Jun 07, 2023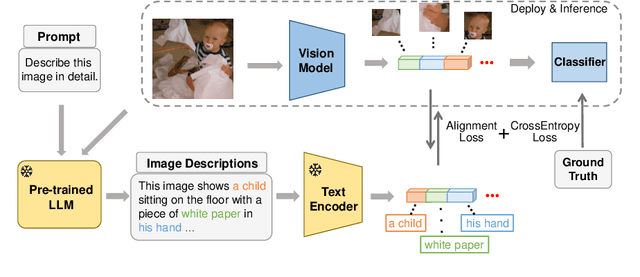
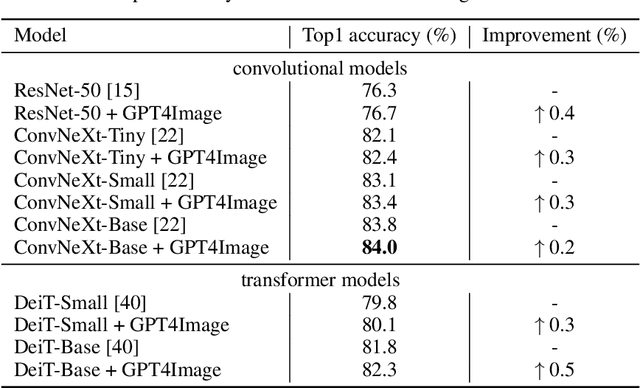

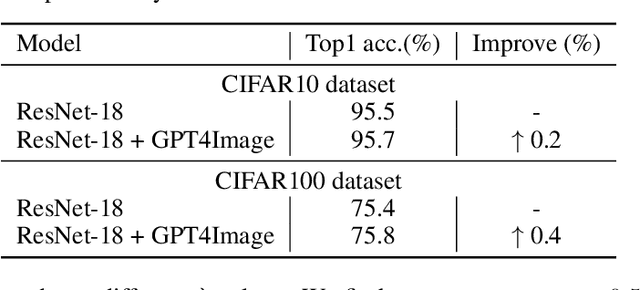
The recent upsurge in pre-trained large models (e.g. GPT-4) has swept across the entire deep learning community. Such powerful large language models (LLMs) demonstrate advanced generative ability and multimodal understanding capability, which quickly achieve new state-of-the-art performances on a variety of benchmarks. The pre-trained LLM usually plays the role as a universal AI model that can conduct various tasks, including context reasoning, article analysis and image content comprehension. However, considering the prohibitively high memory and computational cost for implementing such a large model, the conventional models (such as CNN and ViT), are still essential for many visual perception tasks. In this paper, we propose to enhance the representation ability of ordinary vision models for perception tasks (e.g. image classification) by taking advantage of large pre-trained models. We present a new learning paradigm in which the knowledge extracted from large pre-trained models are utilized to help models like CNN and ViT learn enhanced representations and achieve better performance. Firstly, we curate a high quality description set by prompting a multimodal LLM to generate descriptive text for all training images. Furthermore, we feed these detailed descriptions into a pre-trained encoder to extract text embeddings with rich semantic information that encodes the content of images. During training, text embeddings will serve as extra supervising signals and be aligned with image representations learned by vision models. The alignment process helps vision models learn better and achieve higher accuracy with the assistance of pre-trained LLMs. We conduct extensive experiments to verify that the proposed algorithm consistently improves the performance for various vision models with heterogeneous architectures.
SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions
Jun 08, 2023

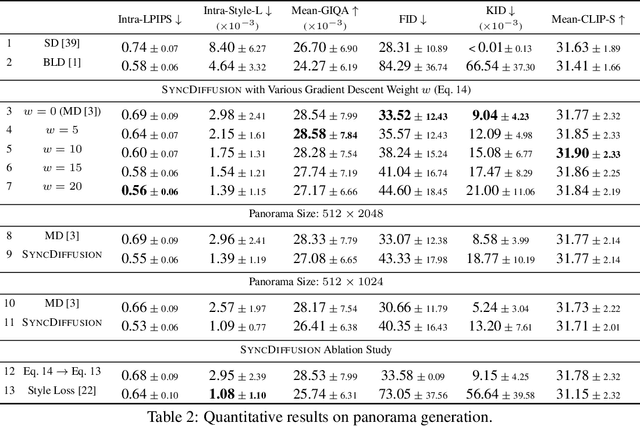

The remarkable capabilities of pretrained image diffusion models have been utilized not only for generating fixed-size images but also for creating panoramas. However, naive stitching of multiple images often results in visible seams. Recent techniques have attempted to address this issue by performing joint diffusions in multiple windows and averaging latent features in overlapping regions. However, these approaches, which focus on seamless montage generation, often yield incoherent outputs by blending different scenes within a single image. To overcome this limitation, we propose SyncDiffusion, a plug-and-play module that synchronizes multiple diffusions through gradient descent from a perceptual similarity loss. Specifically, we compute the gradient of the perceptual loss using the predicted denoised images at each denoising step, providing meaningful guidance for achieving coherent montages. Our experimental results demonstrate that our method produces significantly more coherent outputs compared to previous methods (66.35% vs. 33.65% in our user study) while still maintaining fidelity (as assessed by GIQA) and compatibility with the input prompt (as measured by CLIP score).
Social Biases through the Text-to-Image Generation Lens
Mar 30, 2023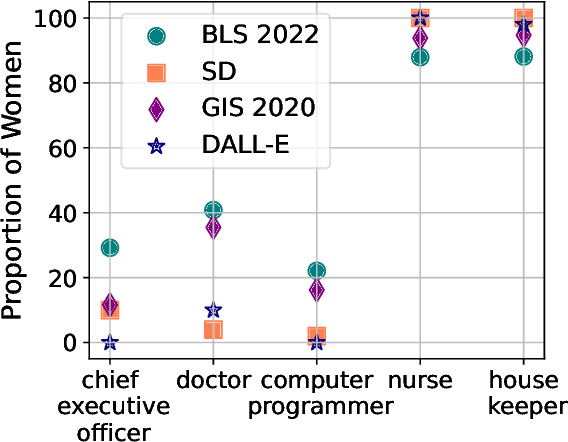
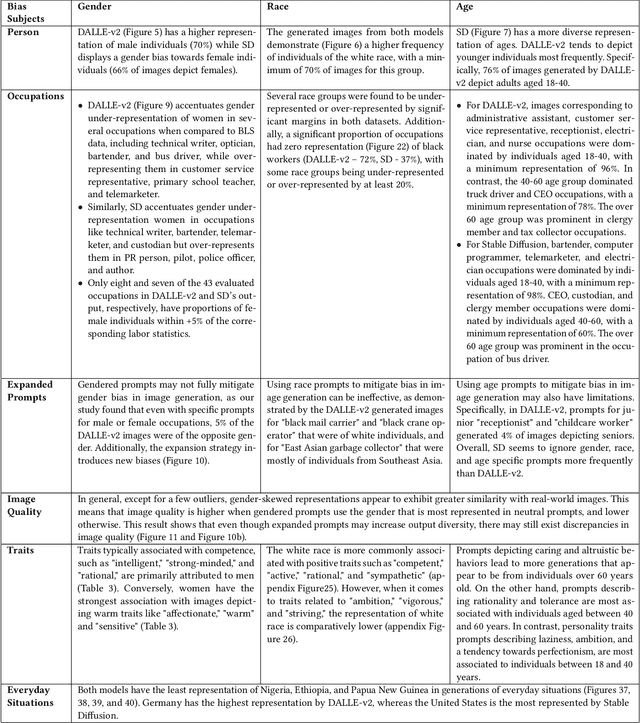

Text-to-Image (T2I) generation is enabling new applications that support creators, designers, and general end users of productivity software by generating illustrative content with high photorealism starting from a given descriptive text as a prompt. Such models are however trained on massive amounts of web data, which surfaces the peril of potential harmful biases that may leak in the generation process itself. In this paper, we take a multi-dimensional approach to studying and quantifying common social biases as reflected in the generated images, by focusing on how occupations, personality traits, and everyday situations are depicted across representations of (perceived) gender, age, race, and geographical location. Through an extensive set of both automated and human evaluation experiments we present findings for two popular T2I models: DALLE-v2 and Stable Diffusion. Our results reveal that there exist severe occupational biases of neutral prompts majorly excluding groups of people from results for both models. Such biases can get mitigated by increasing the amount of specification in the prompt itself, although the prompting mitigation will not address discrepancies in image quality or other usages of the model or its representations in other scenarios. Further, we observe personality traits being associated with only a limited set of people at the intersection of race, gender, and age. Finally, an analysis of geographical location representations on everyday situations (e.g., park, food, weddings) shows that for most situations, images generated through default location-neutral prompts are closer and more similar to images generated for locations of United States and Germany.
PanFlowNet: A Flow-Based Deep Network for Pan-sharpening
May 16, 2023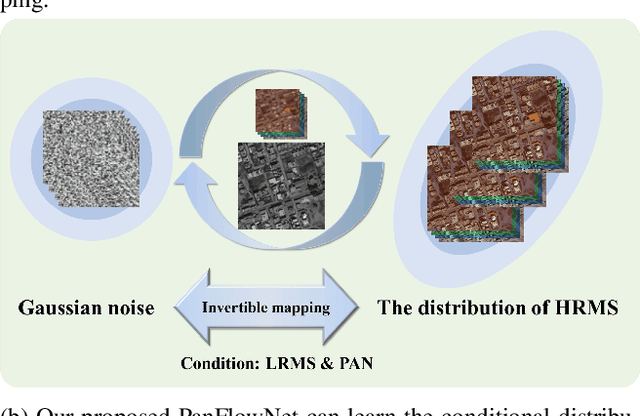
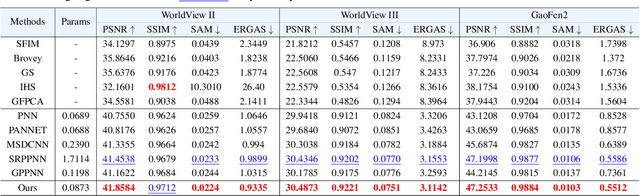
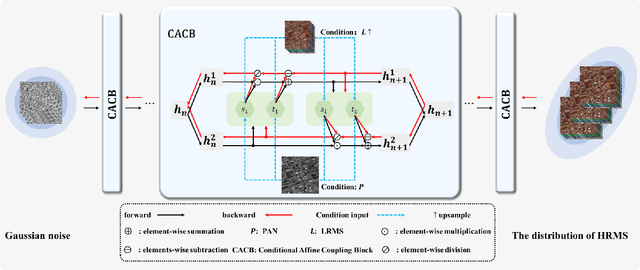
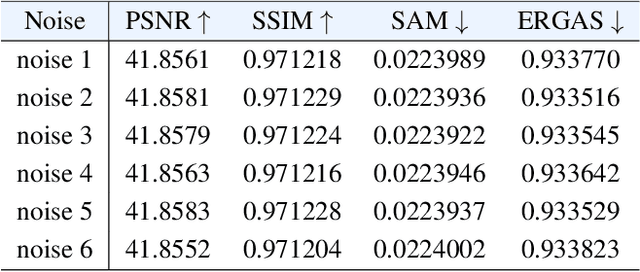
Pan-sharpening aims to generate a high-resolution multispectral (HRMS) image by integrating the spectral information of a low-resolution multispectral (LRMS) image with the texture details of a high-resolution panchromatic (PAN) image. It essentially inherits the ill-posed nature of the super-resolution (SR) task that diverse HRMS images can degrade into an LRMS image. However, existing deep learning-based methods recover only one HRMS image from the LRMS image and PAN image using a deterministic mapping, thus ignoring the diversity of the HRMS image. In this paper, to alleviate this ill-posed issue, we propose a flow-based pan-sharpening network (PanFlowNet) to directly learn the conditional distribution of HRMS image given LRMS image and PAN image instead of learning a deterministic mapping. Specifically, we first transform this unknown conditional distribution into a given Gaussian distribution by an invertible network, and the conditional distribution can thus be explicitly defined. Then, we design an invertible Conditional Affine Coupling Block (CACB) and further build the architecture of PanFlowNet by stacking a series of CACBs. Finally, the PanFlowNet is trained by maximizing the log-likelihood of the conditional distribution given a training set and can then be used to predict diverse HRMS images. The experimental results verify that the proposed PanFlowNet can generate various HRMS images given an LRMS image and a PAN image. Additionally, the experimental results on different kinds of satellite datasets also demonstrate the superiority of our PanFlowNet compared with other state-of-the-art methods both visually and quantitatively.
Investigation of the Challenges of Underwater-Visual-Monocular-SLAM
Jun 14, 2023In this paper, we present a comprehensive investigation of the challenges of Monocular Visual Simultaneous Localization and Mapping (vSLAM) methods for underwater robots. While significant progress has been made in state estimation methods that utilize visual data in the past decade, most evaluations have been limited to controlled indoor and urban environments, where impressive performance was demonstrated. However, these techniques have not been extensively tested in extremely challenging conditions, such as underwater scenarios where factors such as water and light conditions, robot path, and depth can greatly impact algorithm performance. Hence, our evaluation is conducted in real-world AUV scenarios as well as laboratory settings which provide precise external reference. A focus is laid on understanding the impact of environmental conditions, such as optical properties of the water and illumination scenarios, on the performance of monocular vSLAM methods. To this end, we first show that all methods perform very well in in-air settings and subsequently show the degradation of their performance in challenging underwater environments. The final goal of this study is to identify techniques that can improve accuracy and robustness of SLAM methods in such conditions. To achieve this goal, we investigate the potential of image enhancement techniques to improve the quality of input images used by the SLAM methods, specifically in low visibility and extreme lighting scenarios in scattering media. We present a first evaluation on calibration maneuvers and simple image restoration techniques to determine their ability to enable or enhance the performance of monocular SLAM methods in underwater environments.
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 25, 2023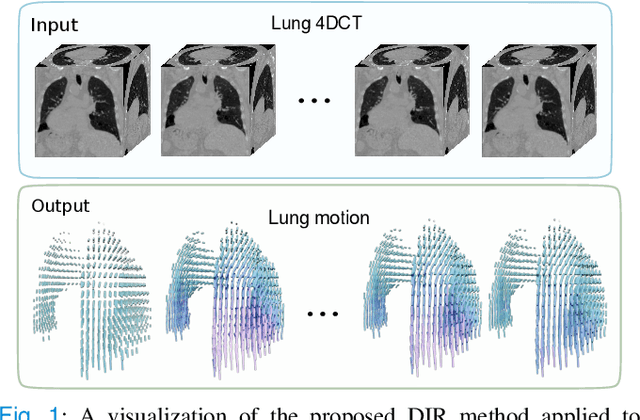
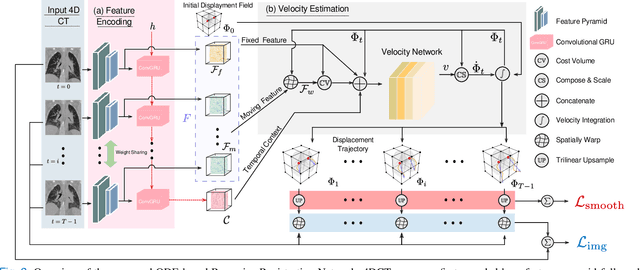
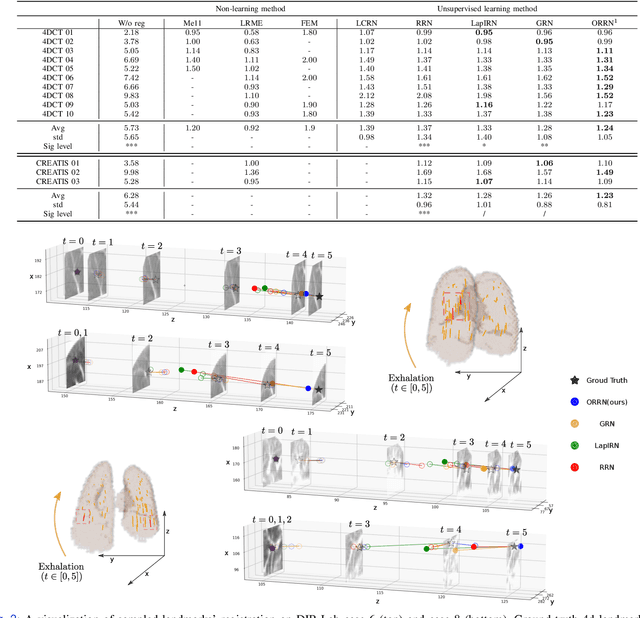
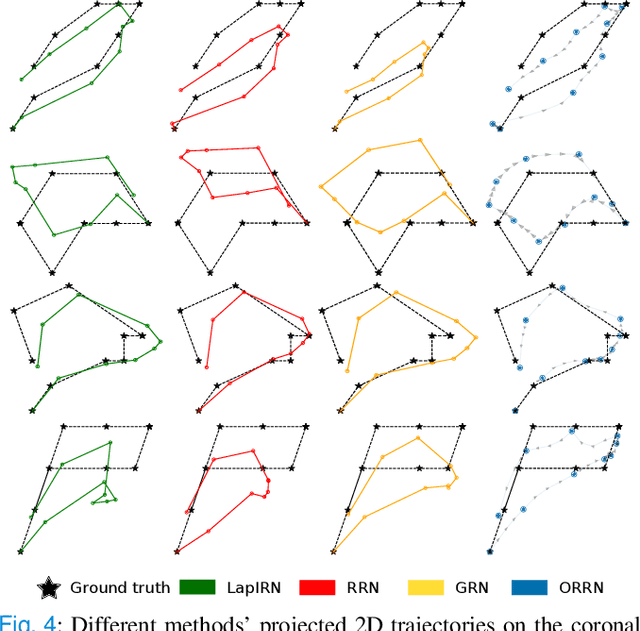
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
Mar 17, 2023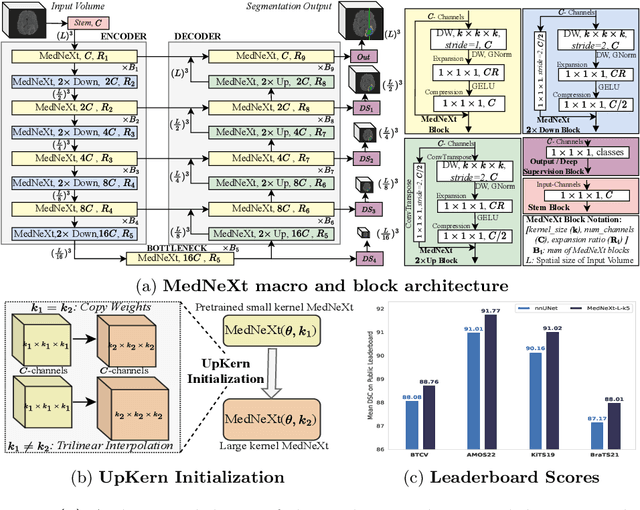

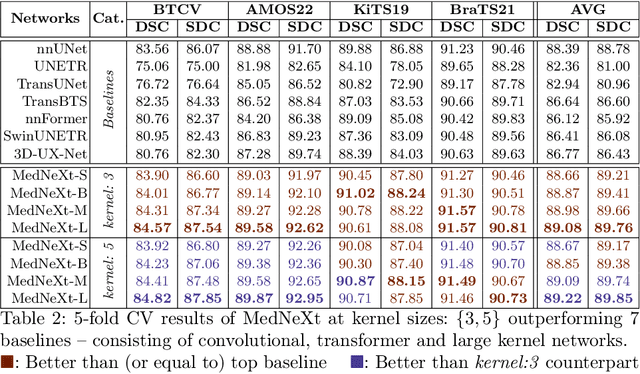
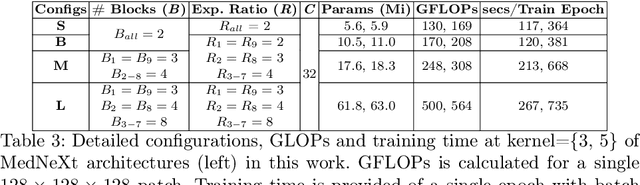
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convolutional networks, in contrast, have higher inductive biases and consequently, are easily trainable to high performance. Recently, the ConvNeXt architecture attempted to modernize the standard ConvNet by mirroring Transformer blocks. In this work, we improve upon this to design a modernized and scalable convolutional architecture customized to challenges of data-scarce medical settings. We introduce MedNeXt, a Transformer-inspired large kernel segmentation network which introduces - 1) A fully ConvNeXt 3D Encoder-Decoder Network for medical image segmentation, 2) Residual ConvNeXt up and downsampling blocks to preserve semantic richness across scales, 3) A novel technique to iteratively increase kernel sizes by upsampling small kernel networks, to prevent performance saturation on limited medical data, 4) Compound scaling at multiple levels (depth, width, kernel size) of MedNeXt. This leads to state-of-the-art performance on 4 tasks on CT and MRI modalities and varying dataset sizes, representing a modernized deep architecture for medical image segmentation.