 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Neural Divide-and-Conquer Reasoning Framework for Image Retrieval from Linguistically Complex Text
May 05, 2023
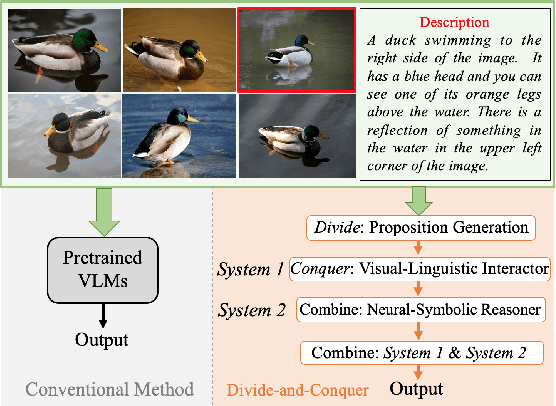
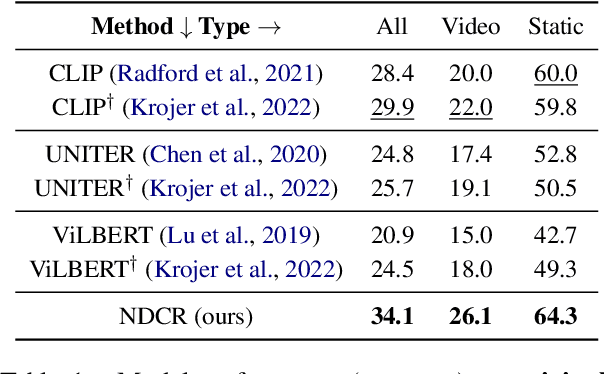

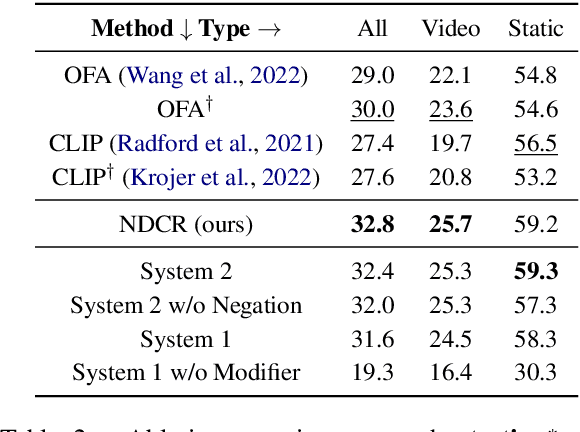
Pretrained Vision-Language Models (VLMs) have achieved remarkable performance in image retrieval from text. However, their performance drops drastically when confronted with linguistically complex texts that they struggle to comprehend. Inspired by the Divide-and-Conquer algorithm and dual-process theory, in this paper, we regard linguistically complex texts as compound proposition texts composed of multiple simple proposition sentences and propose an end-to-end Neural Divide-and-Conquer Reasoning framework, dubbed NDCR. It contains three main components: 1) Divide: a proposition generator divides the compound proposition text into simple proposition sentences and produces their corresponding representations, 2) Conquer: a pretrained VLMs-based visual-linguistic interactor achieves the interaction between decomposed proposition sentences and images, 3) Combine: a neural-symbolic reasoner combines the above reasoning states to obtain the final solution via a neural logic reasoning approach. According to the dual-process theory, the visual-linguistic interactor and neural-symbolic reasoner could be regarded as analogical reasoning System 1 and logical reasoning System 2. We conduct extensive experiments on a challenging image retrieval from contextual descriptions data set. Experimental results and analyses indicate NDCR significantly improves performance in the complex image-text reasoning problem. Code link: https://github.com/YunxinLi/NDCR.
COCO-O: A Benchmark for Object Detectors under Natural Distribution Shifts
Jul 24, 2023Practical object detection application can lose its effectiveness on image inputs with natural distribution shifts. This problem leads the research community to pay more attention on the robustness of detectors under Out-Of-Distribution (OOD) inputs. Existing works construct datasets to benchmark the detector's OOD robustness for a specific application scenario, e.g., Autonomous Driving. However, these datasets lack universality and are hard to benchmark general detectors built on common tasks such as COCO. To give a more comprehensive robustness assessment, we introduce COCO-O(ut-of-distribution), a test dataset based on COCO with 6 types of natural distribution shifts. COCO-O has a large distribution gap with training data and results in a significant 55.7% relative performance drop on a Faster R-CNN detector. We leverage COCO-O to conduct experiments on more than 100 modern object detectors to investigate if their improvements are credible or just over-fitting to the COCO test set. Unfortunately, most classic detectors in early years do not exhibit strong OOD generalization. We further study the robustness effect on recent breakthroughs of detector's architecture design, augmentation and pre-training techniques. Some empirical findings are revealed: 1) Compared with detection head or neck, backbone is the most important part for robustness; 2) An end-to-end detection transformer design brings no enhancement, and may even reduce robustness; 3) Large-scale foundation models have made a great leap on robust object detection. We hope our COCO-O could provide a rich testbed for robustness study of object detection. The dataset will be available at \url{https://github.com/alibaba/easyrobust/tree/main/benchmarks/coco_o}.
General-Purpose Multi-Modal OOD Detection Framework
Jul 24, 2023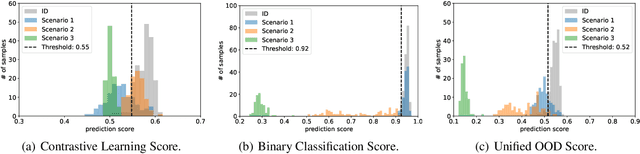

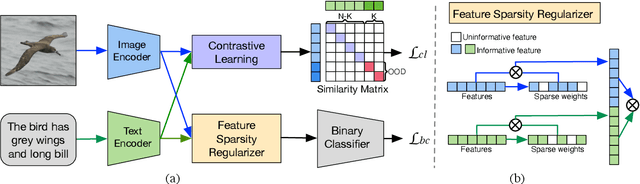

Out-of-distribution (OOD) detection identifies test samples that differ from the training data, which is critical to ensuring the safety and reliability of machine learning (ML) systems. While a plethora of methods have been developed to detect uni-modal OOD samples, only a few have focused on multi-modal OOD detection. Current contrastive learning-based methods primarily study multi-modal OOD detection in a scenario where both a given image and its corresponding textual description come from a new domain. However, real-world deployments of ML systems may face more anomaly scenarios caused by multiple factors like sensor faults, bad weather, and environmental changes. Hence, the goal of this work is to simultaneously detect from multiple different OOD scenarios in a fine-grained manner. To reach this goal, we propose a general-purpose weakly-supervised OOD detection framework, called WOOD, that combines a binary classifier and a contrastive learning component to reap the benefits of both. In order to better distinguish the latent representations of in-distribution (ID) and OOD samples, we adopt the Hinge loss to constrain their similarity. Furthermore, we develop a new scoring metric to integrate the prediction results from both the binary classifier and contrastive learning for identifying OOD samples. We evaluate the proposed WOOD model on multiple real-world datasets, and the experimental results demonstrate that the WOOD model outperforms the state-of-the-art methods for multi-modal OOD detection. Importantly, our approach is able to achieve high accuracy in OOD detection in three different OOD scenarios simultaneously. The source code will be made publicly available upon publication.
OPDN: Omnidirectional Position-aware Deformable Network for Omnidirectional Image Super-Resolution
Apr 26, 2023
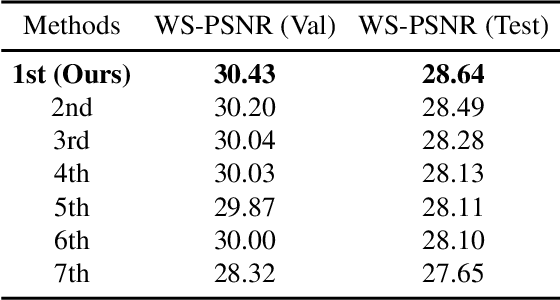

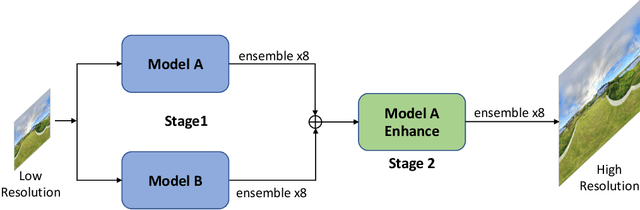
360{\deg} omnidirectional images have gained research attention due to their immersive and interactive experience, particularly in AR/VR applications. However, they suffer from lower angular resolution due to being captured by fisheye lenses with the same sensor size for capturing planar images. To solve the above issues, we propose a two-stage framework for 360{\deg} omnidirectional image superresolution. The first stage employs two branches: model A, which incorporates omnidirectional position-aware deformable blocks (OPDB) and Fourier upsampling, and model B, which adds a spatial frequency fusion module (SFF) to model A. Model A aims to enhance the feature extraction ability of 360{\deg} image positional information, while Model B further focuses on the high-frequency information of 360{\deg} images. The second stage performs same-resolution enhancement based on the structure of model A with a pixel unshuffle operation. In addition, we collected data from YouTube to improve the fitting ability of the transformer, and created pseudo low-resolution images using a degradation network. Our proposed method achieves superior performance and wins the NTIRE 2023 challenge of 360{\deg} omnidirectional image super-resolution.
Medical Image Deidentification, Cleaning and Compression Using Pylogik
Apr 20, 2023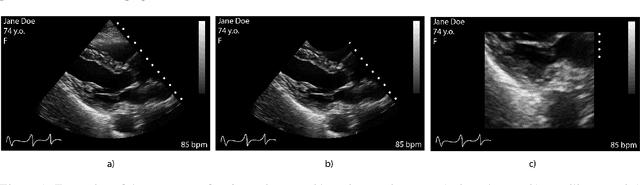

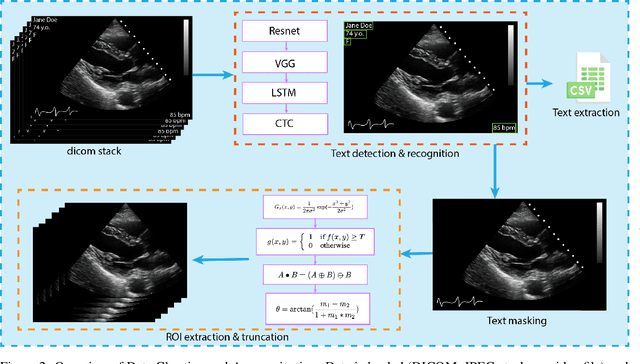
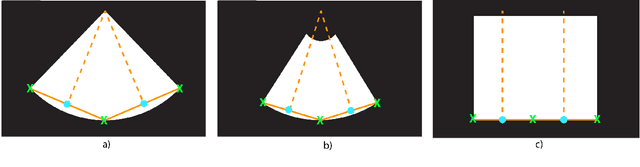
Leveraging medical record information in the era of big data and machine learning comes with the caveat that data must be cleaned and deidentified. Facilitating data sharing and harmonization for multi-center collaborations are particularly difficult when protected health information (PHI) is contained or embedded in image meta-data. We propose a novel library in the Python framework, called PyLogik, to help alleviate this issue for ultrasound images, which are particularly challenging because of the frequent inclusion of PHI directly on the images. PyLogik processes the image volumes through a series of text detection/extraction, filtering, thresholding, morphological and contour comparisons. This methodology deidentifies the images, reduces file sizes, and prepares image volumes for applications in deep learning and data sharing. To evaluate its effectiveness in the identification of regions of interest (ROI), a random sample of 50 cardiac ultrasounds (echocardiograms) were processed through PyLogik, and the outputs were compared with the manual segmentations by an expert user. The Dice coefficient of the two approaches achieved an average value of 0.976. Next, an investigation was conducted to ascertain the degree of information compression achieved using the algorithm. Resultant data was found to be on average approximately 72% smaller after processing by PyLogik. Our results suggest that PyLogik is a viable methodology for ultrasound data cleaning and deidentification, determining ROI, and file compression which will facilitate efficient storage, use, and dissemination of ultrasound data.
Patch-wise Features for Blur Image Classification
Apr 06, 2023
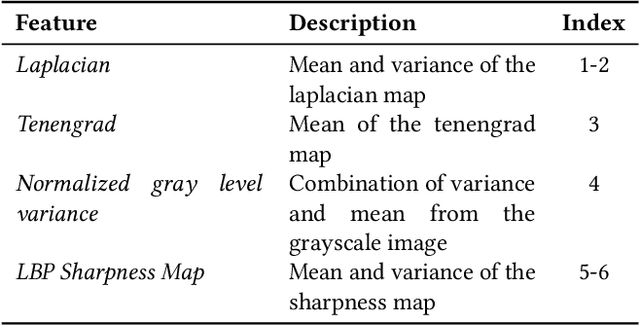

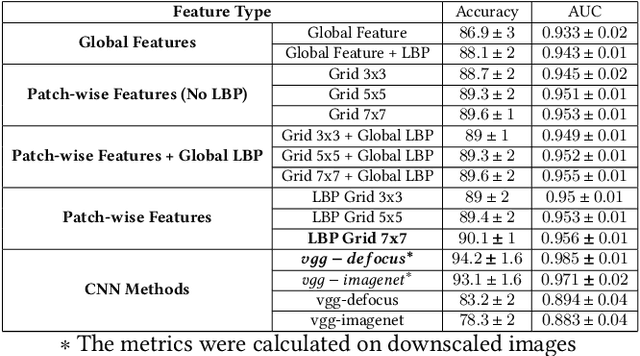
Images captured through smartphone cameras often suffer from degradation, blur being one of the major ones, posing a challenge in processing these images for downstream tasks. In this paper we propose low-compute lightweight patch-wise features for image quality assessment. Using our method we can discriminate between blur vs sharp image degradation. To this end, we train a decision-tree based XGBoost model on various intuitive image features like gray level variance, first and second order gradients, texture features like local binary patterns. Experiments conducted on an open dataset show that the proposed low compute method results in 90.1% mean accuracy on the validation set, which is comparable to the accuracy of a compute-intensive VGG16 network with 94% mean accuracy fine-tuned to this task. To demonstrate the generalizability of our proposed features and model we test the model on BHBID dataset and an internal dataset where we attain accuracy of 98% and 91%, respectively. The proposed method is 10x faster than the VGG16 based model on CPU and scales linearly to the input image size making it suitable to be implemented on low compute edge devices.
A Diffusion-based Method for Multi-turn Compositional Image Generation
Apr 05, 2023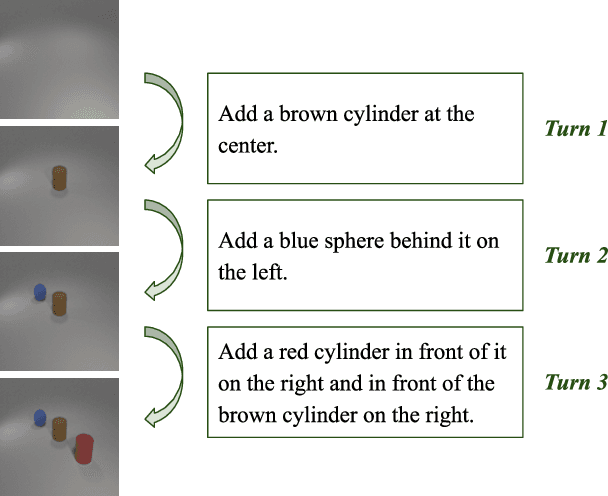
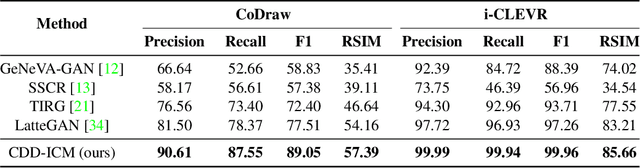
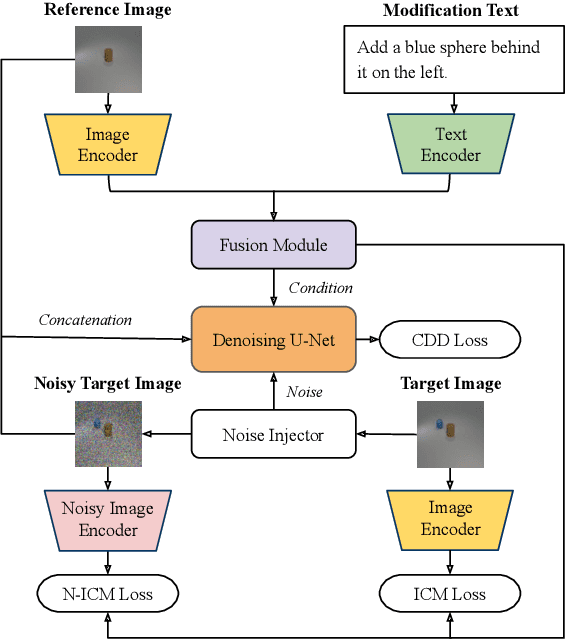
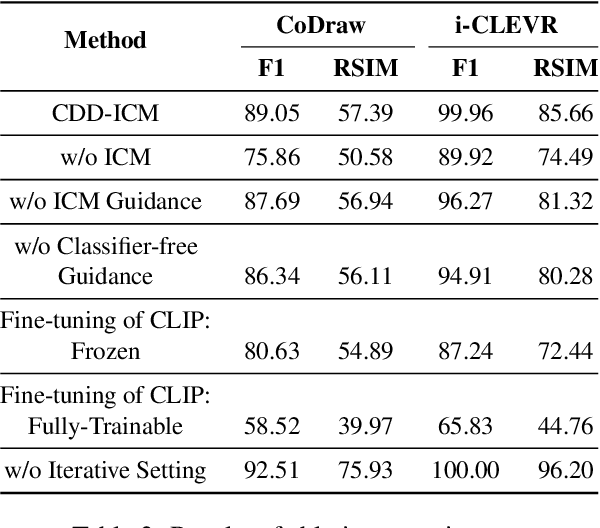
Multi-turn compositional image generation (M-CIG) is a challenging task that aims to iteratively manipulate a reference image given a modification text. While most of the existing methods for M-CIG are based on generative adversarial networks (GANs), recent advances in image generation have demonstrated the superiority of diffusion models over GANs. In this paper, we propose a diffusion-based method for M-CIG named conditional denoising diffusion with image compositional matching (CDD-ICM). We leverage CLIP as the backbone of image and text encoders, and incorporate a gated fusion mechanism, originally proposed for question answering, to compositionally fuse the reference image and the modification text at each turn of M-CIG. We introduce a conditioning scheme to generate the target image based on the fusion results. To prioritize the semantic quality of the generated target image, we learn an auxiliary image compositional match (ICM) objective, along with the conditional denoising diffusion (CDD) objective in a multi-task learning framework. Additionally, we also perform ICM guidance and classifier-free guidance to improve performance. Experimental results show that CDD-ICM achieves state-of-the-art results on two benchmark datasets for M-CIG, i.e., CoDraw and i-CLEVR.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 19, 2023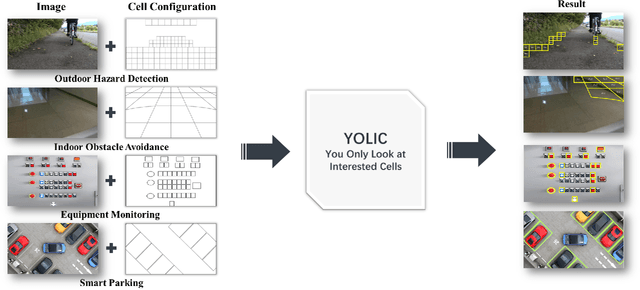
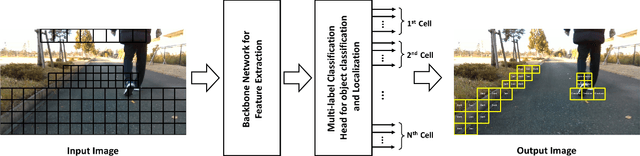


In the realm of Tiny AI, we introduce "You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell, effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets, demonstrating that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
Backdoor Attack against Object Detection with Clean Annotation
Jul 19, 2023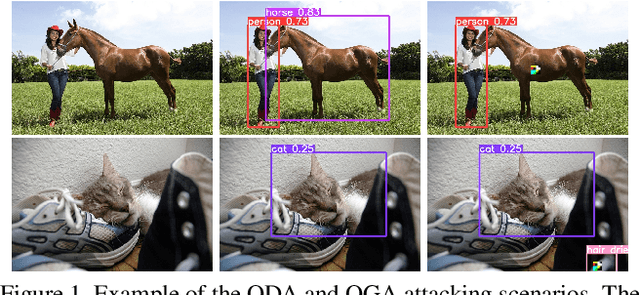
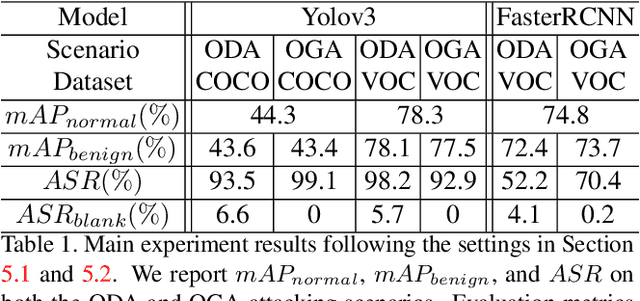
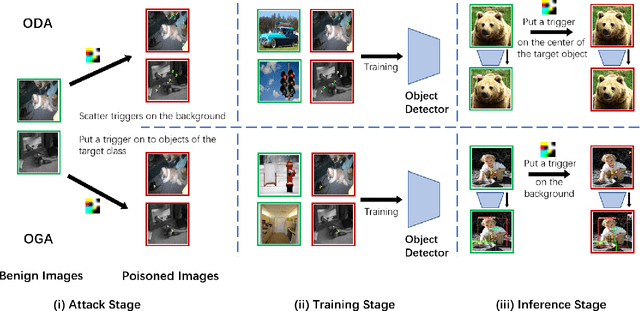
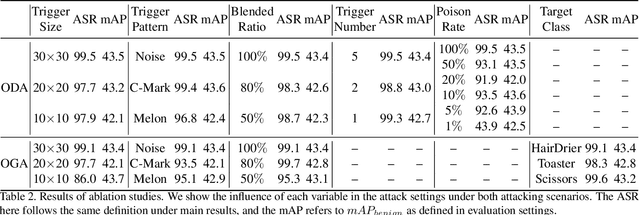
Deep neural networks (DNNs) have shown unprecedented success in object detection tasks. However, it was also discovered that DNNs are vulnerable to multiple kinds of attacks, including Backdoor Attacks. Through the attack, the attacker manages to embed a hidden backdoor into the DNN such that the model behaves normally on benign data samples, but makes attacker-specified judgments given the occurrence of a predefined trigger. Although numerous backdoor attacks have been experimented on image classification, backdoor attacks on object detection tasks have not been properly investigated and explored. As object detection has been adopted as an important module in multiple security-sensitive applications such as autonomous driving, backdoor attacks on object detection could pose even more severe threats. Inspired by the inherent property of deep learning-based object detectors, we propose a simple yet effective backdoor attack method against object detection without modifying the ground truth annotations, specifically focusing on the object disappearance attack and object generation attack. Extensive experiments and ablation studies prove the effectiveness of our attack on two benchmark object detection datasets, PASCAL VOC07+12 and MSCOCO, on which we achieve an attack success rate of more than 92% with a poison rate of only 5%.
Lazy Visual Localization via Motion Averaging
Jul 19, 2023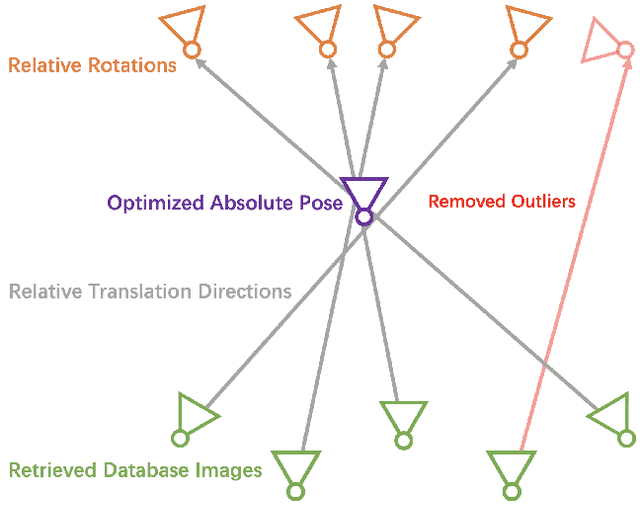
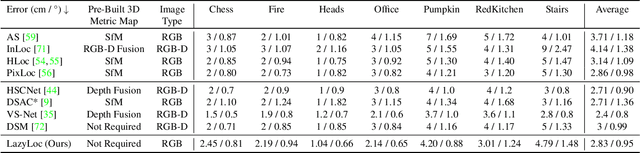
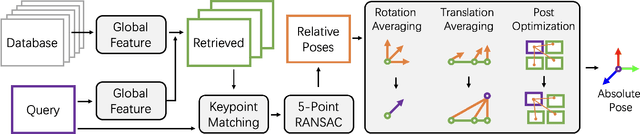
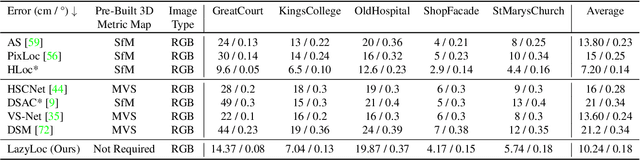
Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.