 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Generation to Suppression: Towards Effective Irregular Glow Removal for Nighttime Visibility Enhancement
Jul 31, 2023
Most existing Low-Light Image Enhancement (LLIE) methods are primarily designed to improve brightness in dark regions, which suffer from severe degradation in nighttime images. However, these methods have limited exploration in another major visibility damage, the glow effects in real night scenes. Glow effects are inevitable in the presence of artificial light sources and cause further diffused blurring when directly enhanced. To settle this issue, we innovatively consider the glow suppression task as learning physical glow generation via multiple scattering estimation according to the Atmospheric Point Spread Function (APSF). In response to the challenges posed by uneven glow intensity and varying source shapes, an APSF-based Nighttime Imaging Model with Near-field Light Sources (NIM-NLS) is specifically derived to design a scalable Light-aware Blind Deconvolution Network (LBDN). The glow-suppressed result is then brightened via a Retinex-based Enhancement Module (REM). Remarkably, the proposed glow suppression method is based on zero-shot learning and does not rely on any paired or unpaired training data. Empirical evaluations demonstrate the effectiveness of the proposed method in both glow suppression and low-light enhancement tasks.
Pre-training Vision Transformers with Very Limited Synthesized Images
Jul 31, 2023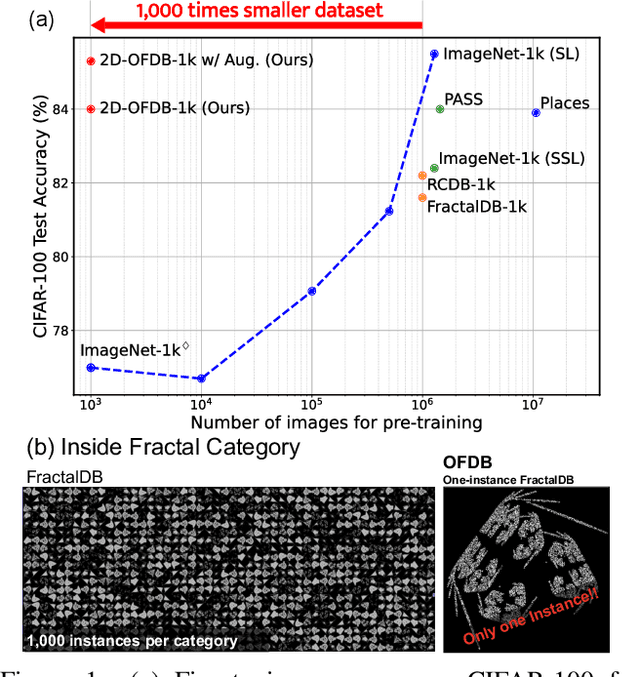
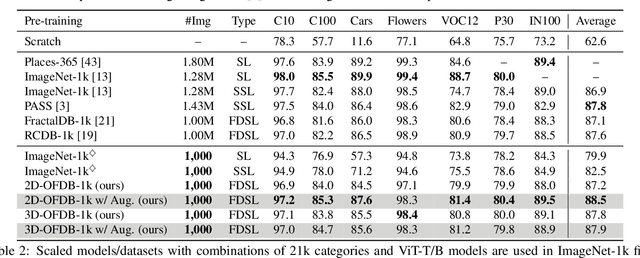
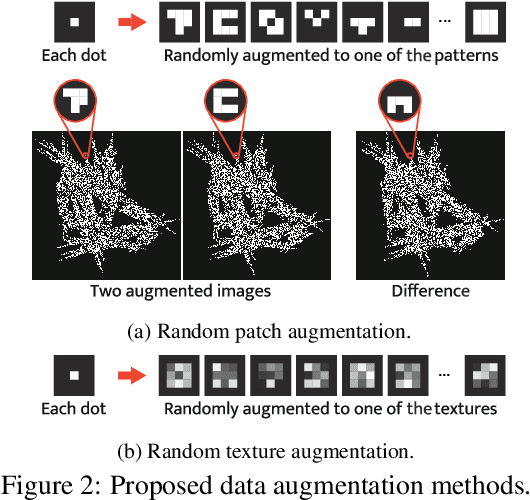
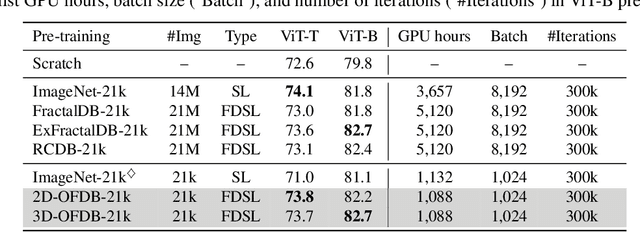
Formula-driven supervised learning (FDSL) is a pre-training method that relies on synthetic images generated from mathematical formulae such as fractals. Prior work on FDSL has shown that pre-training vision transformers on such synthetic datasets can yield competitive accuracy on a wide range of downstream tasks. These synthetic images are categorized according to the parameters in the mathematical formula that generate them. In the present work, we hypothesize that the process for generating different instances for the same category in FDSL, can be viewed as a form of data augmentation. We validate this hypothesis by replacing the instances with data augmentation, which means we only need a single image per category. Our experiments shows that this one-instance fractal database (OFDB) performs better than the original dataset where instances were explicitly generated. We further scale up OFDB to 21,000 categories and show that it matches, or even surpasses, the model pre-trained on ImageNet-21k in ImageNet-1k fine-tuning. The number of images in OFDB is 21k, whereas ImageNet-21k has 14M. This opens new possibilities for pre-training vision transformers with much smaller datasets.
Object-aware Gaze Target Detection
Jul 18, 2023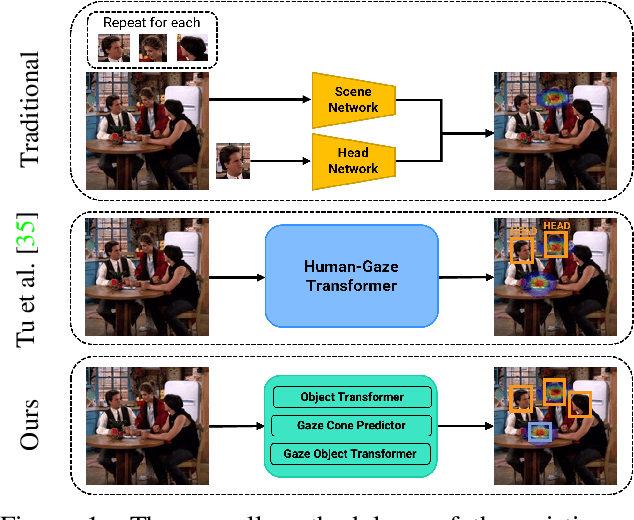
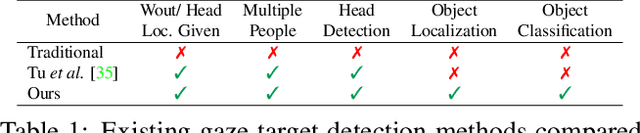
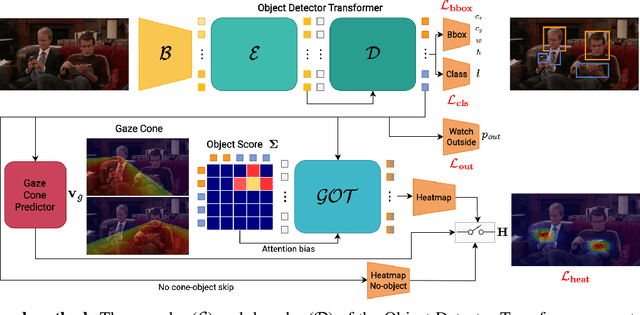
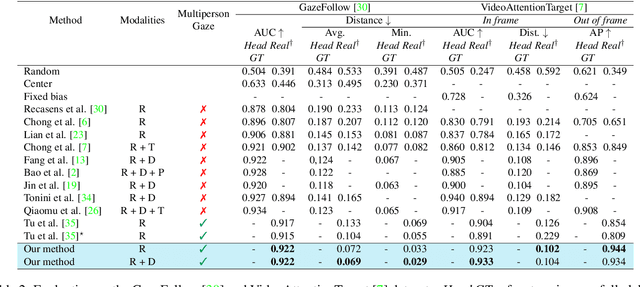
Gaze target detection aims to predict the image location where the person is looking and the probability that a gaze is out of the scene. Several works have tackled this task by regressing a gaze heatmap centered on the gaze location, however, they overlooked decoding the relationship between the people and the gazed objects. This paper proposes a Transformer-based architecture that automatically detects objects (including heads) in the scene to build associations between every head and the gazed-head/object, resulting in a comprehensive, explainable gaze analysis composed of: gaze target area, gaze pixel point, the class and the image location of the gazed-object. Upon evaluation of the in-the-wild benchmarks, our method achieves state-of-the-art results on all metrics (up to 2.91% gain in AUC, 50% reduction in gaze distance, and 9% gain in out-of-frame average precision) for gaze target detection and 11-13% improvement in average precision for the classification and the localization of the gazed-objects. The code of the proposed method is available https://github.com/francescotonini/object-aware-gaze-target-detection
A vision transformer-based framework for knowledge transfer from multi-modal to mono-modal lymphoma subtyping models
Aug 02, 2023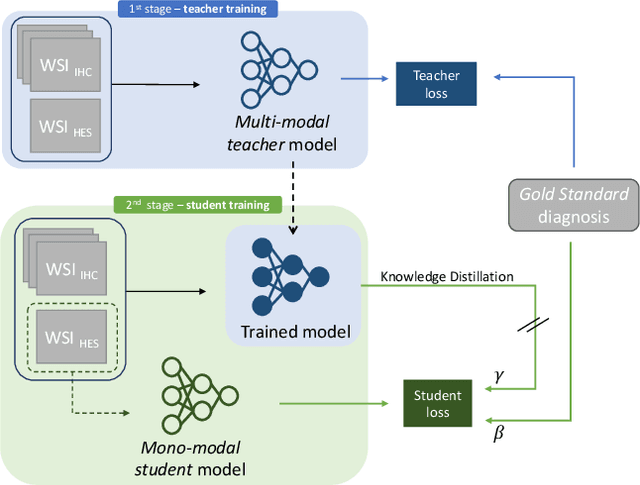
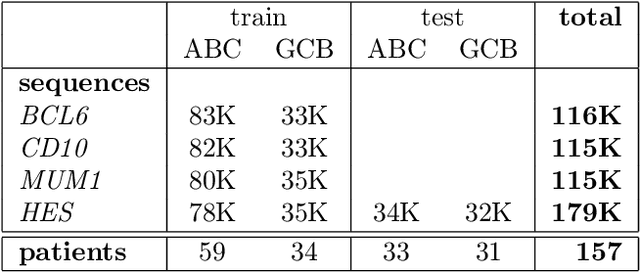


Determining lymphoma subtypes is a crucial step for better patients treatment targeting to potentially increase their survival chances. In this context, the existing gold standard diagnosis method, which is based on gene expression technology, is highly expensive and time-consuming making difficult its accessibility. Although alternative diagnosis methods based on IHC (immunohistochemistry) technologies exist (recommended by the WHO), they still suffer from similar limitations and are less accurate. WSI (Whole Slide Image) analysis by deep learning models showed promising new directions for cancer diagnosis that would be cheaper and faster than existing alternative methods. In this work, we propose a vision transformer-based framework for distinguishing DLBCL (Diffuse Large B-Cell Lymphoma) cancer subtypes from high-resolution WSIs. To this end, we propose a multi-modal architecture to train a classifier model from various WSI modalities. We then exploit this model through a knowledge distillation mechanism for efficiently driving the learning of a mono-modal classifier. Our experimental study conducted on a dataset of 157 patients shows the promising performance of our mono-modal classification model, outperforming six recent methods from the state-of-the-art dedicated for cancer classification. Moreover, the power-law curve, estimated on our experimental data, shows that our classification model requires a reasonable number of additional patients for its training to potentially reach identical diagnosis accuracy as IHC technologies.
Spectral normalized dual contrastive regularization for image-to-image translation
Apr 22, 2023
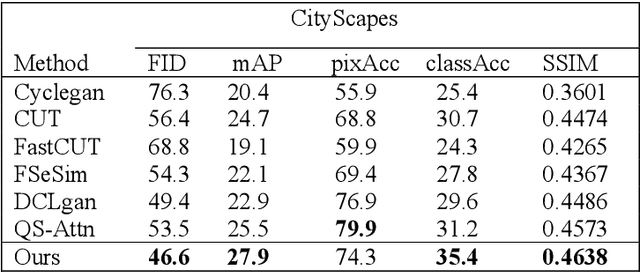


Existing image-to-image(I2I) translation methods achieve state-of-the-art performance by incorporating the patch-wise contrastive learning into Generative Adversarial Networks. However, patch-wise contrastive learning only focuses on the local content similarity but neglects the global structure constraint, which affects the quality of the generated images. In this paper, we propose a new unpaired I2I translation framework based on dual contrastive regularization and spectral normalization, namely SN-DCR. To maintain consistency of the global structure and texture, we design the dual contrastive regularization using different feature spaces respectively. In order to improve the global structure information of the generated images, we formulate a semantically contrastive loss to make the global semantic structure of the generated images similar to the real images from the target domain in the semantic feature space. We use Gram Matrices to extract the style of texture from images. Similarly, we design style contrastive loss to improve the global texture information of the generated images. Moreover, to enhance the stability of model, we employ the spectral normalized convolutional network in the design of our generator. We conduct the comprehensive experiments to evaluate the effectiveness of SN-DCR, and the results prove that our method achieves SOTA in multiple tasks.
Human-M3: A Multi-view Multi-modal Dataset for 3D Human Pose Estimation in Outdoor Scenes
Aug 01, 2023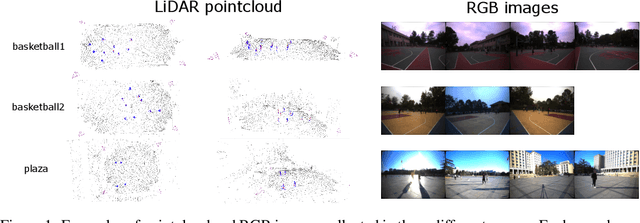


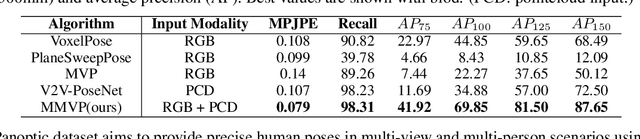
3D human pose estimation in outdoor environments has garnered increasing attention recently. However, prevalent 3D human pose datasets pertaining to outdoor scenes lack diversity, as they predominantly utilize only one type of modality (RGB image or pointcloud), and often feature only one individual within each scene. This limited scope of dataset infrastructure considerably hinders the variability of available data. In this article, we propose Human-M3, an outdoor multi-modal multi-view multi-person human pose database which includes not only multi-view RGB videos of outdoor scenes but also corresponding pointclouds. In order to obtain accurate human poses, we propose an algorithm based on multi-modal data input to generate ground truth annotation. This benefits from robust pointcloud detection and tracking, which solves the problem of inaccurate human localization and matching ambiguity that may exist in previous multi-view RGB videos in outdoor multi-person scenes, and generates reliable ground truth annotations. Evaluation of multiple different modalities algorithms has shown that this database is challenging and suitable for future research. Furthermore, we propose a 3D human pose estimation algorithm based on multi-modal data input, which demonstrates the advantages of multi-modal data input for 3D human pose estimation. Code and data will be released on https://github.com/soullessrobot/Human-M3-Dataset.
Understanding Activation Patterns in Artificial Neural Networks by Exploring Stochastic Processes
Aug 01, 2023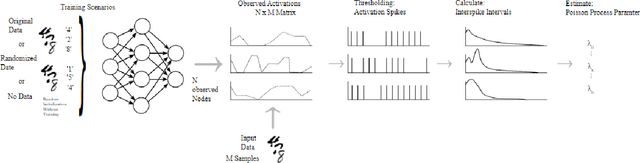
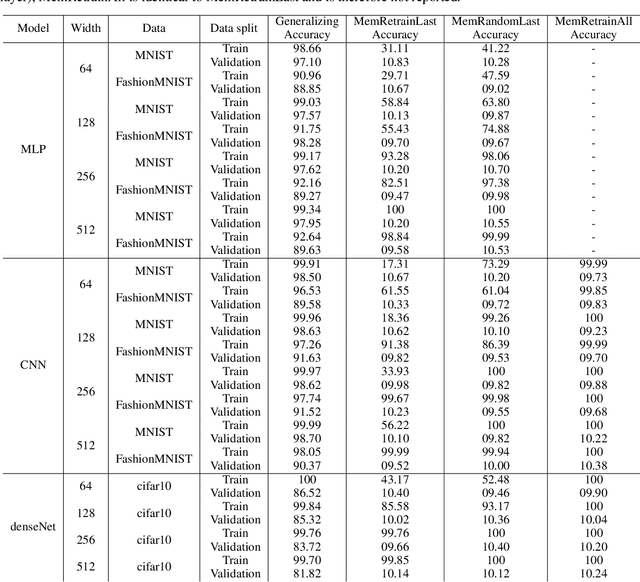
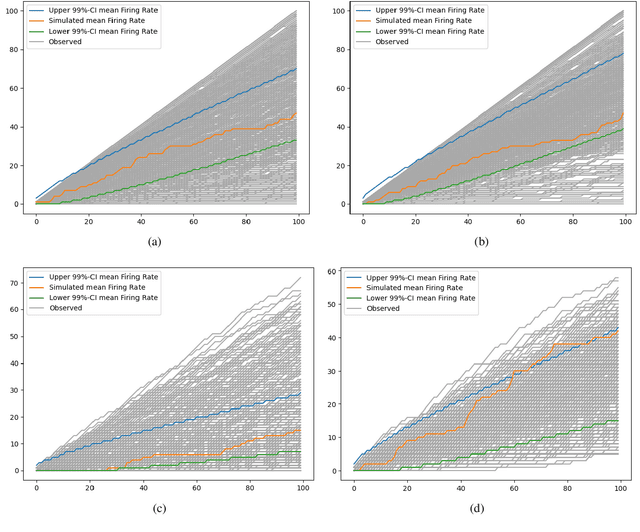
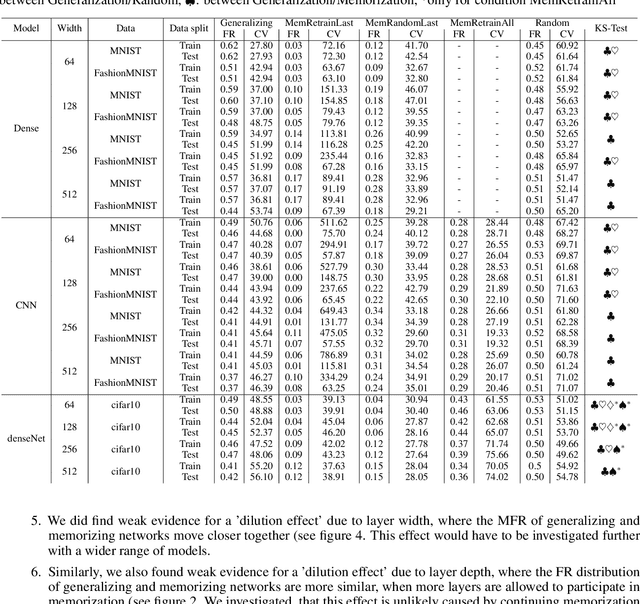
To gain a deeper understanding of the behavior and learning dynamics of (deep) artificial neural networks, it is valuable to employ mathematical abstractions and models. These tools provide a simplified perspective on network performance and facilitate systematic investigations through simulations. In this paper, we propose utilizing the framework of stochastic processes, which has been underutilized thus far. Our approach models activation patterns of thresholded nodes in (deep) artificial neural networks as stochastic processes. We focus solely on activation frequency, leveraging neuroscience techniques used for real neuron spike trains. During a classification task, we extract spiking activity and use an arrival process following the Poisson distribution. We examine observed data from various artificial neural networks in image recognition tasks, fitting the proposed model's assumptions. Through this, we derive parameters describing activation patterns in each network. Our analysis covers randomly initialized, generalizing, and memorizing networks, revealing consistent differences across architectures and training sets. Calculating Mean Firing Rate, Mean Fano Factor, and Variances, we find stable indicators of memorization during learning, providing valuable insights into network behavior. The proposed model shows promise in describing activation patterns and could serve as a general framework for future investigations. It has potential applications in theoretical simulations, pruning, and transfer learning.
NormKD: Normalized Logits for Knowledge Distillation
Aug 01, 2023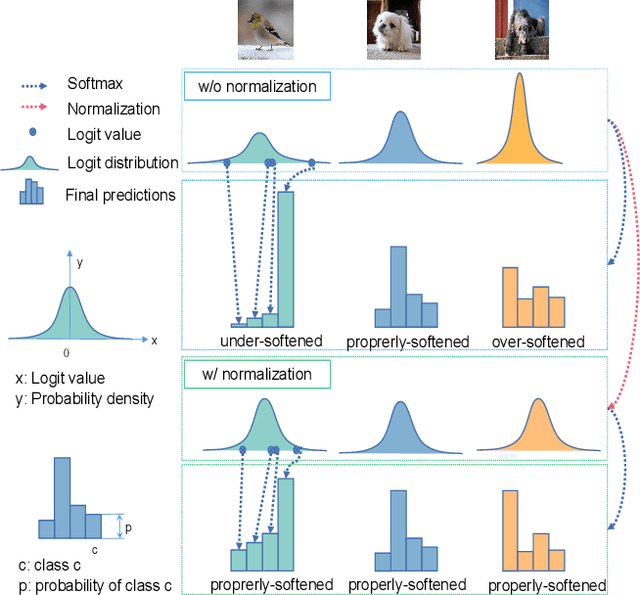
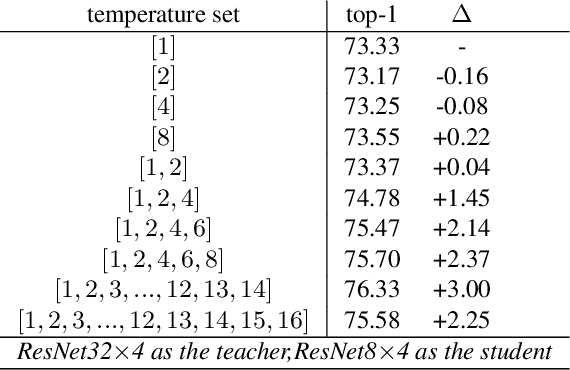
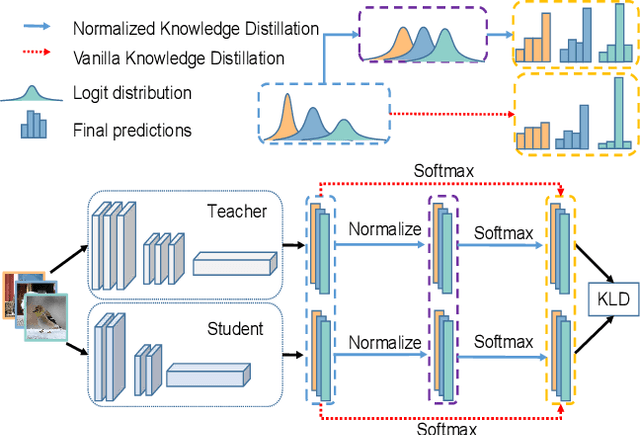
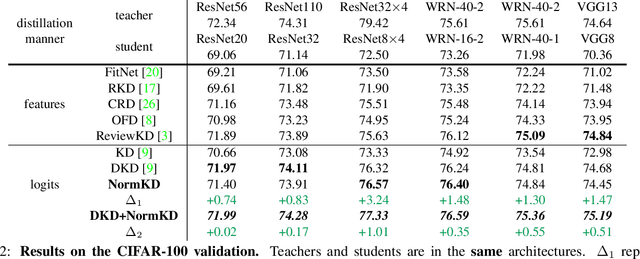
Logit based knowledge distillation gets less attention in recent years since feature based methods perform better in most cases. Nevertheless, we find it still has untapped potential when we re-investigate the temperature, which is a crucial hyper-parameter to soften the logit outputs. For most of the previous works, it was set as a fixed value for the entire distillation procedure. However, as the logits from different samples are distributed quite variously, it is not feasible to soften all of them to an equal degree by just a single temperature, which may make the previous work transfer the knowledge of each sample inadequately. In this paper, we restudy the hyper-parameter temperature and figure out its incapability to distill the knowledge from each sample sufficiently when it is a single value. To address this issue, we propose Normalized Knowledge Distillation (NormKD), with the purpose of customizing the temperature for each sample according to the characteristic of the sample's logit distribution. Compared to the vanilla KD, NormKD barely has extra computation or storage cost but performs significantly better on CIRAR-100 and ImageNet for image classification. Furthermore, NormKD can be easily applied to the other logit based methods and achieve better performance which can be closer to or even better than the feature based method.
Similarity Min-Max: Zero-Shot Day-Night Domain Adaptation
Jul 19, 2023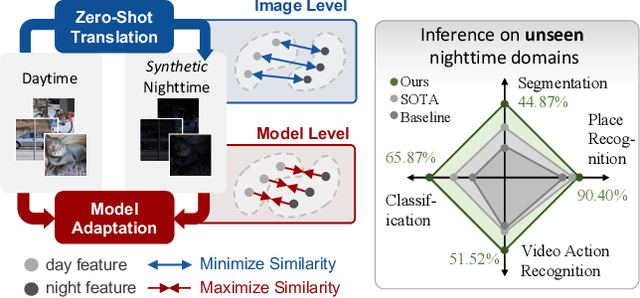
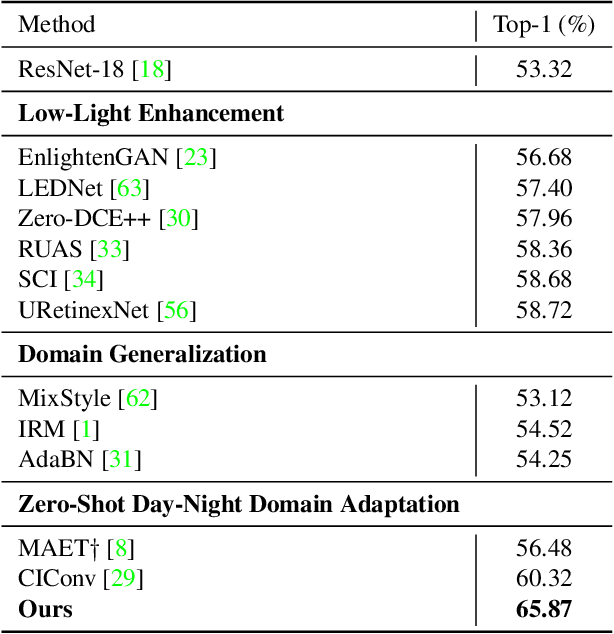
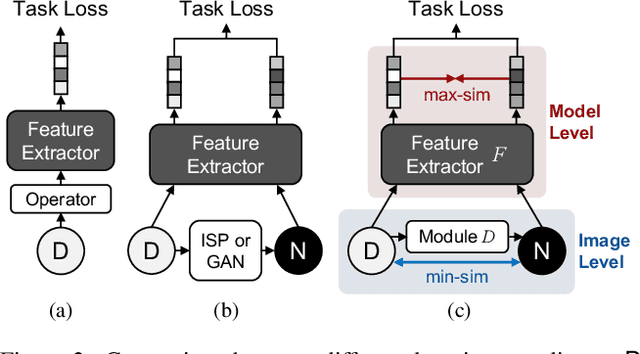
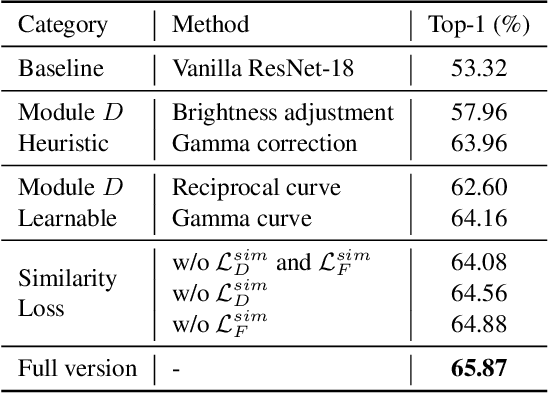
Low-light conditions not only hamper human visual experience but also degrade the model's performance on downstream vision tasks. While existing works make remarkable progress on day-night domain adaptation, they rely heavily on domain knowledge derived from the task-specific nighttime dataset. This paper challenges a more complicated scenario with border applicability, i.e., zero-shot day-night domain adaptation, which eliminates reliance on any nighttime data. Unlike prior zero-shot adaptation approaches emphasizing either image-level translation or model-level adaptation, we propose a similarity min-max paradigm that considers them under a unified framework. On the image level, we darken images towards minimum feature similarity to enlarge the domain gap. Then on the model level, we maximize the feature similarity between the darkened images and their normal-light counterparts for better model adaptation. To the best of our knowledge, this work represents the pioneering effort in jointly optimizing both aspects, resulting in a significant improvement of model generalizability. Extensive experiments demonstrate our method's effectiveness and broad applicability on various nighttime vision tasks, including classification, semantic segmentation, visual place recognition, and video action recognition. Code and pre-trained models are available at https://red-fairy.github.io/ZeroShotDayNightDA-Webpage/.
LXL: LiDAR Excluded Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
Jul 07, 2023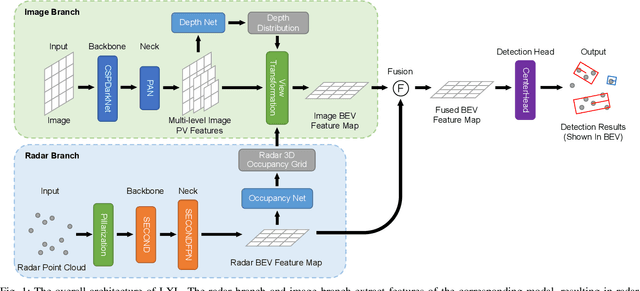
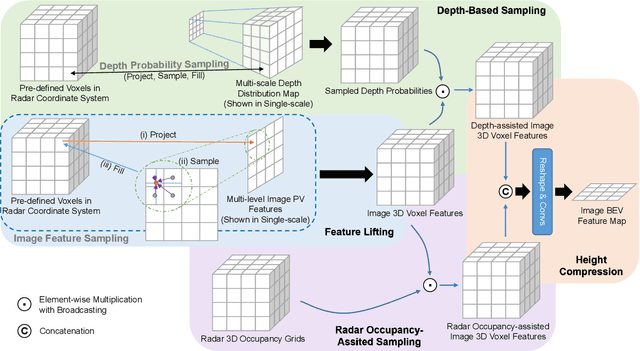
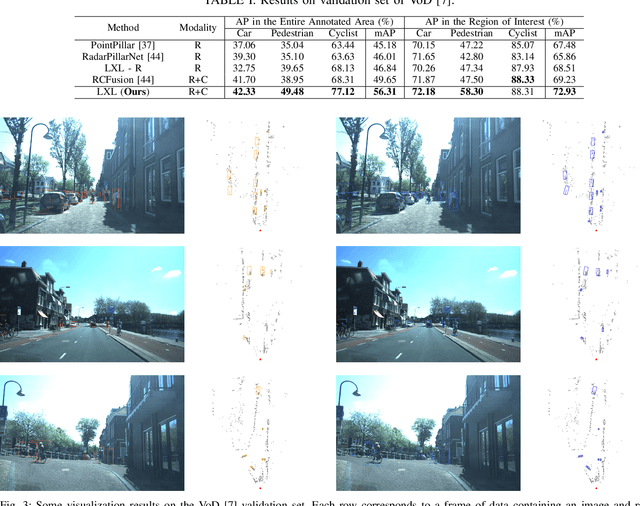

As an emerging technology and a relatively affordable device, the 4D imaging radar has already been confirmed effective in performing 3D object detection in autonomous driving. Nevertheless, the sparsity and noisiness of 4D radar point clouds hinder further performance improvement, and in-depth studies about its fusion with other modalities are lacking. On the other hand, most of the camera-based perception methods transform the extracted image perspective view features into the bird's-eye view geometrically via "depth-based splatting" proposed in Lift-Splat-Shoot (LSS), and some researchers exploit other modals such as LiDARs or ordinary automotive radars for enhancement. Recently, a few works have applied the "sampling" strategy for image view transformation, showing that it outperforms "splatting" even without image depth prediction. However, the potential of "sampling" is not fully unleashed. In this paper, we investigate the "sampling" view transformation strategy on the camera and 4D imaging radar fusion-based 3D object detection. In the proposed model, LXL, predicted image depth distribution maps and radar 3D occupancy grids are utilized to aid image view transformation, called "radar occupancy-assisted depth-based sampling". Experiments on VoD and TJ4DRadSet datasets show that the proposed method outperforms existing 3D object detection methods by a significant margin without bells and whistles. Ablation studies demonstrate that our method performs the best among different enhancement settings.