 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHREC 2025: Protein surface shape retrieval including electrostatic potential
Sep 16, 2025



This SHREC 2025 track dedicated to protein surface shape retrieval involved 9 participating teams. We evaluated the performance in retrieval of 15 proposed methods on a large dataset of 11,555 protein surfaces with calculated electrostatic potential (a key molecular surface descriptor). The performance in retrieval of the proposed methods was evaluated through different metrics (Accuracy, Balanced accuracy, F1 score, Precision and Recall). The best retrieval performance was achieved by the proposed methods that used the electrostatic potential complementary to molecular surface shape. This observation was also valid for classes with limited data which highlights the importance of taking into account additional molecular surface descriptors.
* Published in Computers & Graphics, Elsevier. 59 pages, 12 figures
Histopathology image embedding based on foundation models features aggregation for patient treatment response prediction
Jul 23, 2024Predicting the response of a patient to a cancer treatment is of high interest. Nonetheless, this task is still challenging from a medical point of view due to the complexity of the interaction between the patient organism and the considered treatment. Recent works on foundation models pre-trained with self-supervised learning on large-scale unlabeled histopathology datasets have opened a new direction towards the development of new methods for cancer diagnosis related tasks. In this article, we propose a novel methodology for predicting Diffuse Large B-Cell Lymphoma patients treatment response from Whole Slide Images. Our method exploits several foundation models as feature extractors to obtain a local representation of the image corresponding to a small region of the tissue, then, a global representation of the image is obtained by aggregating these local representations using attention-based Multiple Instance Learning. Our experimental study conducted on a dataset of 152 patients, shows the promising results of our methodology, notably by highlighting the advantage of using foundation models compared to conventional ImageNet pre-training. Moreover, the obtained results clearly demonstrates the potential of foundation models for characterizing histopathology images and generating more suited semantic representation for this task.
Ensembling and Test Augmentation for Covid-19 Detection and Covid-19 Domain Adaptation from 3D CT-Scans
Mar 17, 2024



Since the emergence of Covid-19 in late 2019, medical image analysis using artificial intelligence (AI) has emerged as a crucial research area, particularly with the utility of CT-scan imaging for disease diagnosis. This paper contributes to the 4th COV19D competition, focusing on Covid-19 Detection and Covid-19 Domain Adaptation Challenges. Our approach centers on lung segmentation and Covid-19 infection segmentation employing the recent CNN-based segmentation architecture PDAtt-Unet, which simultaneously segments lung regions and infections. Departing from traditional methods, we concatenate the input slice (grayscale) with segmented lung and infection, generating three input channels akin to color channels. Additionally, we employ three 3D CNN backbones Customized Hybrid-DeCoVNet, along with pretrained 3D-Resnet-18 and 3D-Resnet-50 models to train Covid-19 recognition for both challenges. Furthermore, we explore ensemble approaches and testing augmentation to enhance performance. Comparison with baseline results underscores the substantial efficiency of our approach, with a significant margin in terms of F1-score (14 %). This study advances the field by presenting a comprehensive methodology for accurate Covid-19 detection and adaptation, leveraging cutting-edge AI techniques in medical image analysis.
A vision transformer-based framework for knowledge transfer from multi-modal to mono-modal lymphoma subtyping models
Aug 02, 2023



Determining lymphoma subtypes is a crucial step for better patients treatment targeting to potentially increase their survival chances. In this context, the existing gold standard diagnosis method, which is based on gene expression technology, is highly expensive and time-consuming making difficult its accessibility. Although alternative diagnosis methods based on IHC (immunohistochemistry) technologies exist (recommended by the WHO), they still suffer from similar limitations and are less accurate. WSI (Whole Slide Image) analysis by deep learning models showed promising new directions for cancer diagnosis that would be cheaper and faster than existing alternative methods. In this work, we propose a vision transformer-based framework for distinguishing DLBCL (Diffuse Large B-Cell Lymphoma) cancer subtypes from high-resolution WSIs. To this end, we propose a multi-modal architecture to train a classifier model from various WSI modalities. We then exploit this model through a knowledge distillation mechanism for efficiently driving the learning of a mono-modal classifier. Our experimental study conducted on a dataset of 157 patients shows the promising performance of our mono-modal classification model, outperforming six recent methods from the state-of-the-art dedicated for cancer classification. Moreover, the power-law curve, estimated on our experimental data, shows that our classification model requires a reasonable number of additional patients for its training to potentially reach identical diagnosis accuracy as IHC technologies.
SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix Data Augmentation
Apr 11, 2022
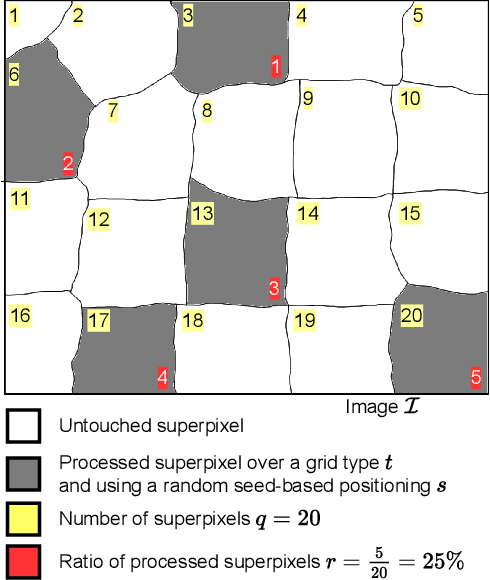

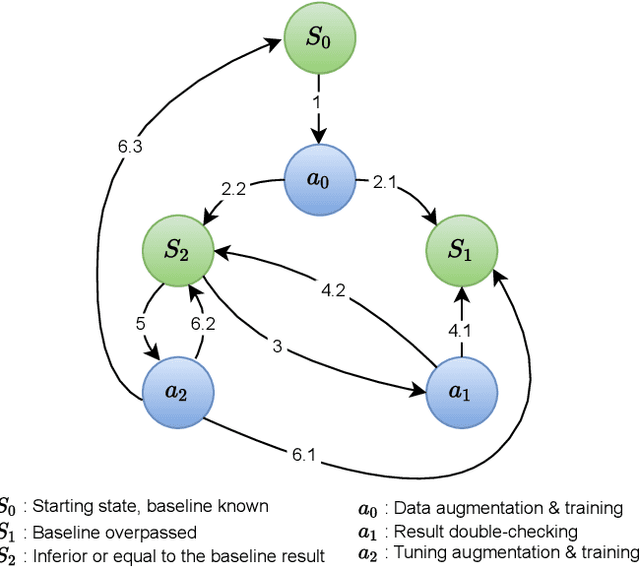
A novel approach of data augmentation based on irregular superpixel decomposition is proposed. This approach called SuperpixelGridMasks permits to extend original image datasets that are required by training stages of machine learning-related analysis architectures towards increasing their performances. Three variants named SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix are presented. These grid-based methods produce a new style of image transformations using the dropping and fusing of information. Extensive experiments using various image classification models and datasets show that baseline performances can be significantly outperformed using our methods. The comparative study also shows that our methods can overpass the performances of other data augmentations. Experimental results obtained over image recognition datasets of varied natures show the efficiency of these new methods. SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix codes are publicly available at https://github.com/hammoudiproject/SuperpixelGridMasks
MaskedFace-Net -- A Dataset of Correctly/Incorrectly Masked Face Images in the Context of COVID-19
Aug 18, 2020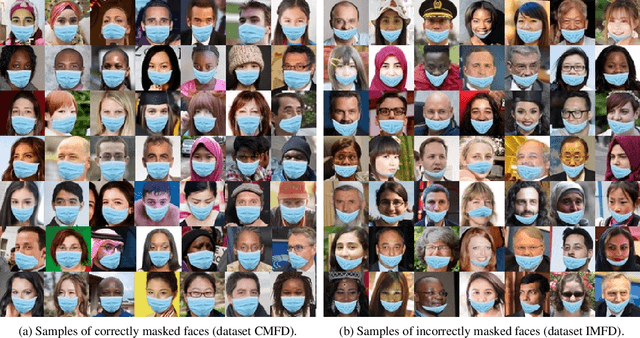
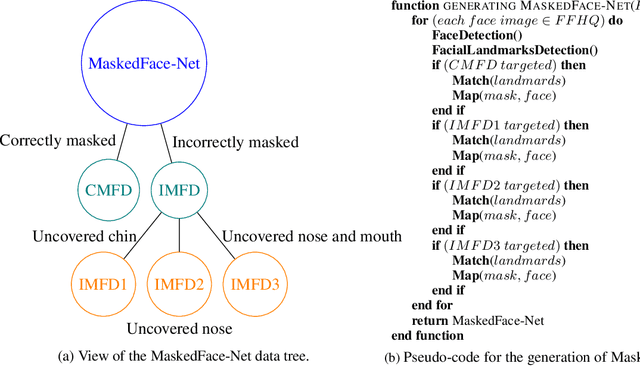

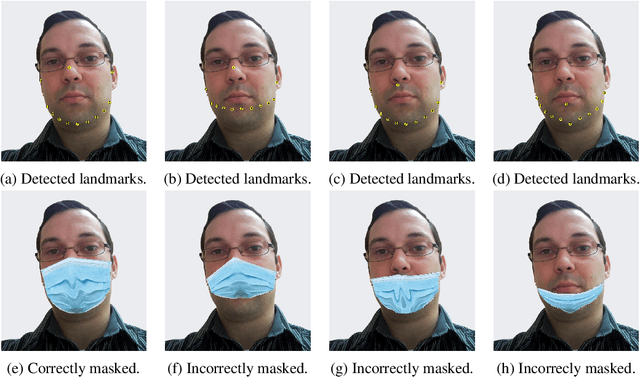
The wearing of the face masks appears as a solution for limiting the spread of COVID-19. In this context, efficient recognition systems are expected for checking that people faces are masked in regulated areas. To perform this task, a large dataset of masked faces is necessary for training deep learning models towards detecting people wearing masks and those not wearing masks. Some large datasets of masked faces are available in the literature. However, at the moment, there are no available large dataset of masked face images that permits to check if detected masked faces are correctly worn or not. Indeed, many people are not correctly wearing their masks due to bad practices, bad behaviors or vulnerability of individuals (e.g., children, old people). For these reasons, several mask wearing campaigns intend to sensitize people about this problem and good practices. In this sense, this work proposes three types of masked face detection dataset; namely, the Correctly Masked Face Dataset (CMFD), the Incorrectly Masked Face Dataset (IMFD) and their combination for the global masked face detection (MaskedFace-Net). Realistic masked face datasets are proposed with a twofold objective: i) to detect people having their faces masked or not masked, ii) to detect faces having their masks correctly worn or incorrectly worn (e.g.; at airport portals or in crowds). To the best of our knowledge, no large dataset of masked faces provides such a granularity of classification towards permitting mask wearing analysis. Moreover, this work globally presents the applied mask-to-face deformable model for permitting the generation of other masked face images, notably with specific masks. Our datasets of masked face images (137,016 images) are available at https://github.com/cabani/MaskedFace-Net.
Deep Learning on Chest X-ray Images to Detect and Evaluate Pneumonia Cases at the Era of COVID-19
Apr 05, 2020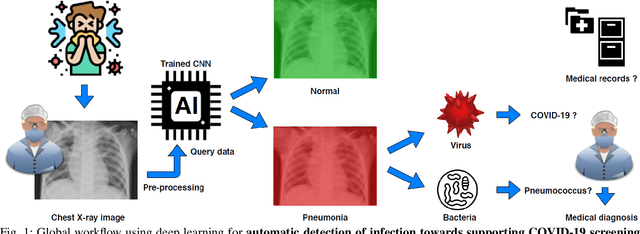
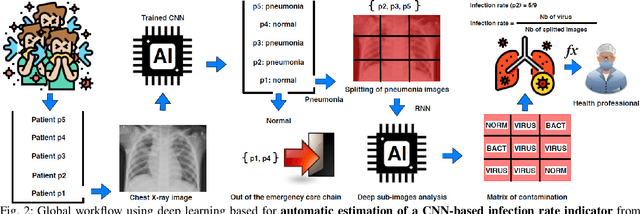
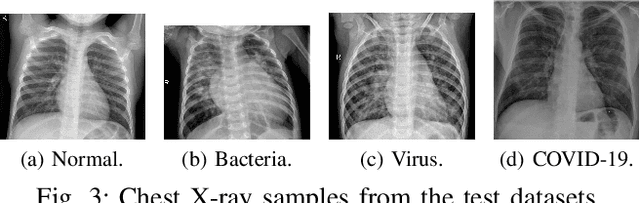
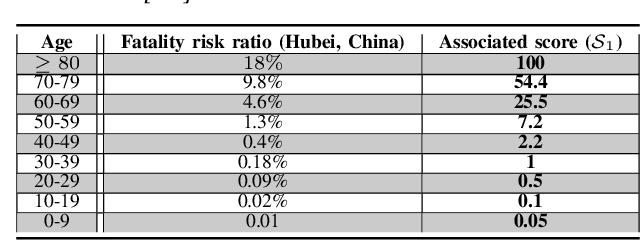
Coronavirus disease 2019 (COVID-19) is an infectious disease with first symptoms similar to the flu. COVID-19 appeared first in China and very quickly spreads to the rest of the world, causing then the 2019-20 coronavirus pandemic. In many cases, this disease causes pneumonia. Since pulmonary infections can be observed through radiography images, this paper investigates deep learning methods for automatically analyzing query chest X-ray images with the hope to bring precision tools to health professionals towards screening the COVID-19 and diagnosing confirmed patients. In this context, training datasets, deep learning architectures and analysis strategies have been experimented from publicly open sets of chest X-ray images. Tailored deep learning models are proposed to detect pneumonia infection cases, notably viral cases. It is assumed that viral pneumonia cases detected during an epidemic COVID-19 context have a high probability to presume COVID-19 infections. Moreover, easy-to-apply health indicators are proposed for estimating infection status and predicting patient status from the detected pneumonia cases. Experimental results show possibilities of training deep learning models over publicly open sets of chest X-ray images towards screening viral pneumonia. Chest X-ray test images of COVID-19 infected patients are successfully diagnosed through detection models retained for their performances. The efficiency of proposed health indicators is highlighted through simulated scenarios of patients presenting infections and health problems by combining real and synthetic health data.