 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Semantic Multi-Object Tracking with Vision-Language Models
Apr 15, 2026Semantic Multi-Object Tracking (SMOT) extends multi-object tracking with semantic outputs such as video summaries, instance-level captions, and interaction labels, aiming to move from trajectories to human-interpretable descriptions of dynamic scenes. Existing SMOT systems are trained end-to-end, coupling progress to expensive supervision, limiting the ability to rapidly adapt to new foundation models and new interactions. We propose TF-SMOT, a training-free SMOT pipeline that composes pretrained components for detection, mask-based tracking, and video-language generation. TF-SMOT combines D-FINE and the promptable SAM2 segmentation tracker to produce temporally consistent tracklets, uses contour grounding to generate video summaries and instance captions with InternVideo2.5, and aligns extracted interaction predicates to BenSMOT WordNet synsets via gloss-based semantic retrieval with LLM disambiguation. On BenSMOT, TF-SMOT achieves state-of-the-art tracking performance within the SMOT setting and improves summary and caption quality compared to prior art. Interaction recognition, however, remains challenging under strict exact-match evaluation on the fine-grained and long-tailed WordNet label space; our analysis and ablations indicate that semantic overlap and label granularity substantially affect measured performance.
Towards Unconstrained Human-Object Interaction
Apr 15, 2026Human-Object Interaction (HOI) detection is a longstanding computer vision problem concerned with predicting the interaction between humans and objects. Current HOI models rely on a vocabulary of interactions at training and inference time, limiting their applicability to static environments. With the advent of Multimodal Large Language Models (MLLMs), it has become feasible to explore more flexible paradigms for interaction recognition. In this work, we revisit HOI detection through the lens of MLLMs and apply them to in-the-wild HOI detection. We define the Unconstrained HOI (U-HOI) task, a novel HOI domain that removes the requirement for a predefined list of interactions at both training and inference. We evaluate a range of MLLMs on this setting and introduce a pipeline that includes test-time inference and language-to-graph conversion to extract structured interactions from free-form text. Our findings highlight the limitations of current HOI detectors and the value of MLLMs for U-HOI. Code will be available at https://github.com/francescotonini/anyhoi
From Weights to Concepts: Data-Free Interpretability of CLIP via Singular Vector Decomposition
Mar 25, 2026As vision-language models are deployed at scale, understanding their internal mechanisms becomes increasingly critical. Existing interpretability methods predominantly rely on activations, making them dataset-dependent, vulnerable to data bias, and often restricted to coarse head-level explanations. We introduce SITH (Semantic Inspection of Transformer Heads), a fully data-free, training-free framework that directly analyzes CLIP's vision transformer in weight space. For each attention head, we decompose its value-output matrix into singular vectors and interpret each one via COMP (Coherent Orthogonal Matching Pursuit), a new algorithm that explains them as sparse, semantically coherent combinations of human-interpretable concepts. We show that SITH yields coherent, faithful intra-head explanations, validated through reconstruction fidelity and interpretability experiments. This allows us to use SITH for precise, interpretable weight-space model edits that amplify or suppress specific concepts, improving downstream performance without retraining. Furthermore, we use SITH to study model adaptation, showing how fine-tuning primarily reweights a stable semantic basis rather than learning entirely new features.
Dynamic Scoring with Enhanced Semantics for Training-Free Human-Object Interaction Detection
Jul 23, 2025



Human-Object Interaction (HOI) detection aims to identify humans and objects within images and interpret their interactions. Existing HOI methods rely heavily on large datasets with manual annotations to learn interactions from visual cues. These annotations are labor-intensive to create, prone to inconsistency, and limit scalability to new domains and rare interactions. We argue that recent advances in Vision-Language Models (VLMs) offer untapped potential, particularly in enhancing interaction representation. While prior work has injected such potential and even proposed training-free methods, there remain key gaps. Consequently, we propose a novel training-free HOI detection framework for Dynamic Scoring with enhanced semantics (DYSCO) that effectively utilizes textual and visual interaction representations within a multimodal registry, enabling robust and nuanced interaction understanding. This registry incorporates a small set of visual cues and uses innovative interaction signatures to improve the semantic alignment of verbs, facilitating effective generalization to rare interactions. Additionally, we propose a unique multi-head attention mechanism that adaptively weights the contributions of the visual and textual features. Experimental results demonstrate that our DYSCO surpasses training-free state-of-the-art models and is competitive with training-based approaches, particularly excelling in rare interactions. Code is available at https://github.com/francescotonini/dysco.
AL-GTD: Deep Active Learning for Gaze Target Detection
Sep 27, 2024



Gaze target detection aims at determining the image location where a person is looking. While existing studies have made significant progress in this area by regressing accurate gaze heatmaps, these achievements have largely relied on access to extensive labeled datasets, which demands substantial human labor. In this paper, our goal is to reduce the reliance on the size of labeled training data for gaze target detection. To achieve this, we propose AL-GTD, an innovative approach that integrates supervised and self-supervised losses within a novel sample acquisition function to perform active learning (AL). Additionally, it utilizes pseudo-labeling to mitigate distribution shifts during the training phase. AL-GTD achieves the best of all AUC results by utilizing only 40-50% of the training data, in contrast to state-of-the-art (SOTA) gaze target detectors requiring the entire training dataset to achieve the same performance. Importantly, AL-GTD quickly reaches satisfactory performance with 10-20% of the training data, showing the effectiveness of our acquisition function, which is able to acquire the most informative samples. We provide a comprehensive experimental analysis by adapting several AL methods for the task. AL-GTD outperforms AL competitors, simultaneously exhibiting superior performance compared to SOTA gaze target detectors when all are trained within a low-data regime. Code is available at https://github.com/francescotonini/al-gtd.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024



Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Object-aware Gaze Target Detection
Jul 18, 2023Gaze target detection aims to predict the image location where the person is looking and the probability that a gaze is out of the scene. Several works have tackled this task by regressing a gaze heatmap centered on the gaze location, however, they overlooked decoding the relationship between the people and the gazed objects. This paper proposes a Transformer-based architecture that automatically detects objects (including heads) in the scene to build associations between every head and the gazed-head/object, resulting in a comprehensive, explainable gaze analysis composed of: gaze target area, gaze pixel point, the class and the image location of the gazed-object. Upon evaluation of the in-the-wild benchmarks, our method achieves state-of-the-art results on all metrics (up to 2.91% gain in AUC, 50% reduction in gaze distance, and 9% gain in out-of-frame average precision) for gaze target detection and 11-13% improvement in average precision for the classification and the localization of the gazed-objects. The code of the proposed method is available https://github.com/francescotonini/object-aware-gaze-target-detection
Multimodal Across Domains Gaze Target Detection
Aug 23, 2022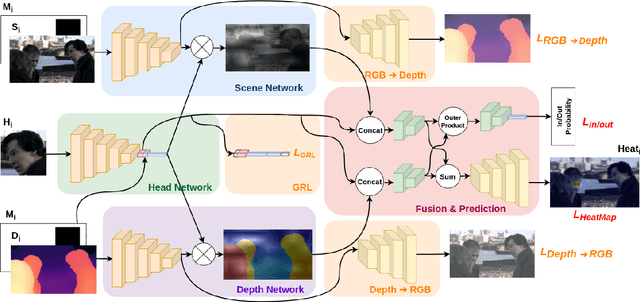

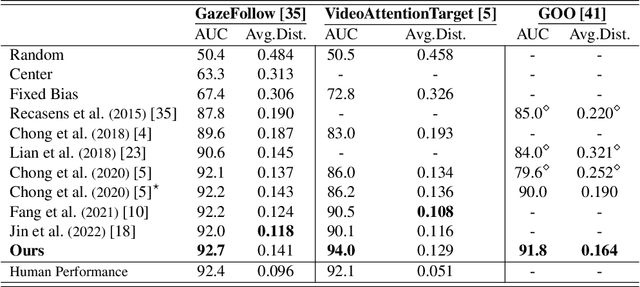

This paper addresses the gaze target detection problem in single images captured from the third-person perspective. We present a multimodal deep architecture to infer where a person in a scene is looking. This spatial model is trained on the head images of the person-of- interest, scene and depth maps representing rich context information. Our model, unlike several prior art, do not require supervision of the gaze angles, do not rely on head orientation information and/or location of the eyes of person-of-interest. Extensive experiments demonstrate the stronger performance of our method on multiple benchmark datasets. We also investigated several variations of our method by altering joint-learning of multimodal data. Some variations outperform a few prior art as well. First time in this paper, we inspect domain adaption for gaze target detection, and we empower our multimodal network to effectively handle the domain gap across datasets. The code of the proposed method is available at https://github.com/francescotonini/multimodal-across-domains-gaze-target-detection.