 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Named Entity Recognition
Nested named entity recognition is the process of identifying and categorizing named entities with nested or overlapping spans.
Papers and Code
Using LSTM and GRU With a New Dataset for Named Entity Recognition in the Arabic Language
Apr 06, 2023Named entity recognition (NER) is a natural language processing task (NLP), which aims to identify named entities and classify them like person, location, organization, etc. In the Arabic language, we can find a considerable size of unstructured data, and it needs to different preprocessing tool than languages like (English, Russian, German...). From this point, we can note the importance of building a new structured dataset to solve the lack of structured data. In this work, we use the BIOES format to tag the word, which allows us to handle the nested name entity that consists of more than one sentence and define the start and the end of the name. The dataset consists of more than thirty-six thousand records. In addition, this work proposes long short term memory (LSTM) units and Gated Recurrent Units (GRU) for building the named entity recognition model in the Arabic language. The models give an approximately good result (80%) because LSTM and GRU models can find the relationships between the words of the sentence. Also, use a new library from Google, which is Trax and platform Colab
Nested Named Entity Recognition as Holistic Structure Parsing
Apr 17, 2022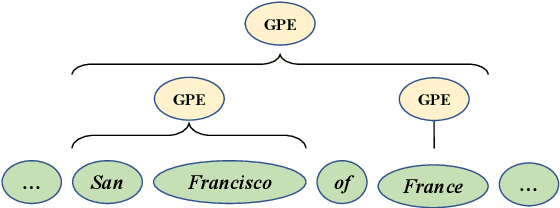
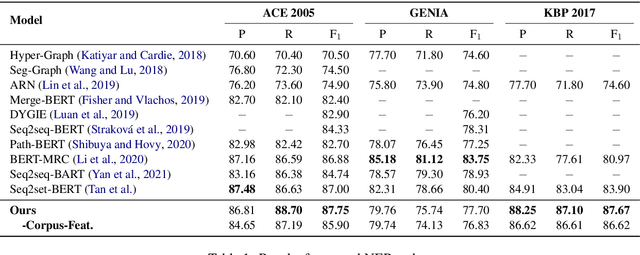
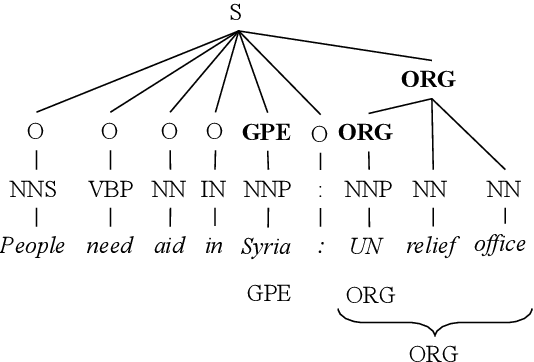
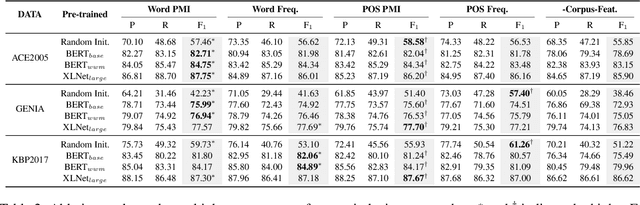
As a fundamental natural language processing task and one of core knowledge extraction techniques, named entity recognition (NER) is widely used to extract information from texts for downstream tasks. Nested NER is a branch of NER in which the named entities (NEs) are nested with each other. However, most of the previous studies on nested NER usually apply linear structure to model the nested NEs which are actually accommodated in a hierarchical structure. Thus in order to address this mismatch, this work models the full nested NEs in a sentence as a holistic structure, then we propose a holistic structure parsing algorithm to disclose the entire NEs once for all. Besides, there is no research on applying corpus-level information to NER currently. To make up for the loss of this information, we introduce Point-wise Mutual Information (PMI) and other frequency features from corpus-aware statistics for even better performance by holistic modeling from sentence-level to corpus-level. Experiments show that our model yields promising results on widely-used benchmarks which approach or even achieve state-of-the-art. Further empirical studies show that our proposed corpus-aware features can substantially improve NER domain adaptation, which demonstrates the surprising advantage of our proposed corpus-level holistic structure modeling.
DiffusionNER: Boundary Diffusion for Named Entity Recognition
May 22, 2023In this paper, we propose DiffusionNER, which formulates the named entity recognition task as a boundary-denoising diffusion process and thus generates named entities from noisy spans. During training, DiffusionNER gradually adds noises to the golden entity boundaries by a fixed forward diffusion process and learns a reverse diffusion process to recover the entity boundaries. In inference, DiffusionNER first randomly samples some noisy spans from a standard Gaussian distribution and then generates the named entities by denoising them with the learned reverse diffusion process. The proposed boundary-denoising diffusion process allows progressive refinement and dynamic sampling of entities, empowering DiffusionNER with efficient and flexible entity generation capability. Experiments on multiple flat and nested NER datasets demonstrate that DiffusionNER achieves comparable or even better performance than previous state-of-the-art models.
Recognizing Nested Entities from Flat Supervision: A New NER Subtask, Feasibility and Challenges
Nov 01, 2022



Many recent named entity recognition (NER) studies criticize flat NER for its non-overlapping assumption, and switch to investigating nested NER. However, existing nested NER models heavily rely on training data annotated with nested entities, while labeling such data is costly. This study proposes a new subtask, nested-from-flat NER, which corresponds to a realistic application scenario: given data annotated with flat entities only, one may still desire the trained model capable of recognizing nested entities. To address this task, we train span-based models and deliberately ignore the spans nested inside labeled entities, since these spans are possibly unlabeled entities. With nested entities removed from the training data, our model achieves 54.8%, 54.2% and 41.1% F1 scores on the subset of spans within entities on ACE 2004, ACE 2005 and GENIA, respectively. This suggests the effectiveness of our approach and the feasibility of the task. In addition, the model's performance on flat entities is entirely unaffected. We further manually annotate the nested entities in the test set of CoNLL 2003, creating a nested-from-flat NER benchmark. Analysis results show that the main challenges stem from the data and annotation inconsistencies between the flat and nested entities.
RuNNE-2022 Shared Task: Recognizing Nested Named Entities
May 23, 2022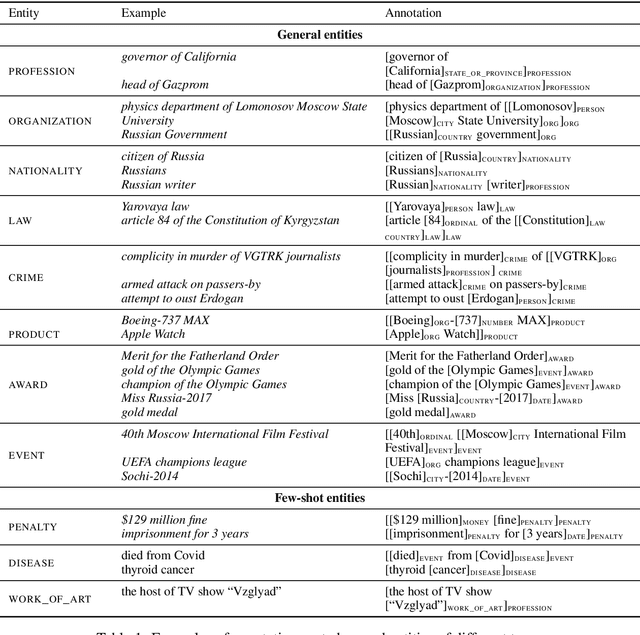
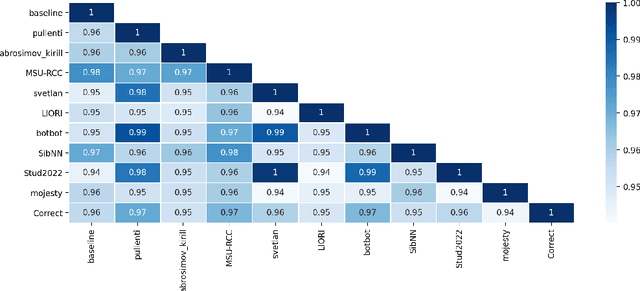
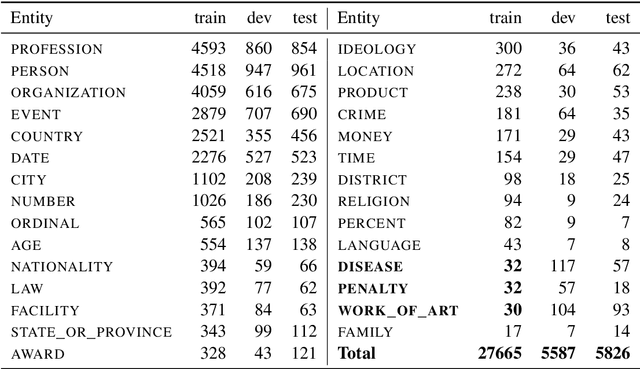
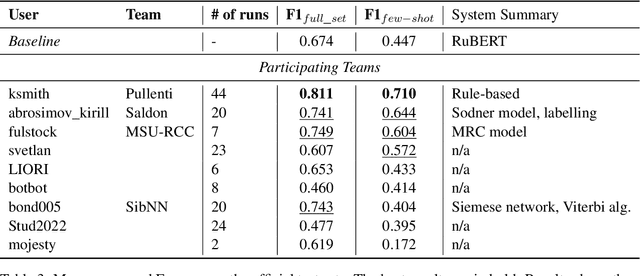
The RuNNE Shared Task approaches the problem of nested named entity recognition. The annotation schema is designed in such a way, that an entity may partially overlap or even be nested into another entity. This way, the named entity "The Yermolova Theatre" of type "organization" houses another entity "Yermolova" of type "person". We adopt the Russian NEREL dataset for the RuNNE Shared Task. NEREL comprises news texts written in the Russian language and collected from the Wikinews portal. The annotation schema includes 29 entity types. The nestedness of named entities in NEREL reaches up to six levels. The RuNNE Shared Task explores two setups. (i) In the general setup all entities occur more or less with the same frequency. (ii) In the few-shot setup the majority of entity types occur often in the training set. However, some of the entity types are have lower frequency, being thus challenging to recognize. In the test set the frequency of all entity types is even. This paper reports on the results of the RuNNE Shared Task. Overall the shared task has received 156 submissions from nine teams. Half of the submissions outperform a straightforward BERT-based baseline in both setups. This paper overviews the shared task setup and discusses the submitted systems, discovering meaning insights for the problem of nested NER. The links to the evaluation platform and the data from the shared task are available in our github repository: https://github.com/dialogue-evaluation/RuNNE.
Fusing Heterogeneous Factors with Triaffine Mechanism for Nested Named Entity Recognition
Oct 14, 2021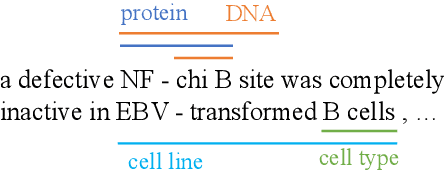
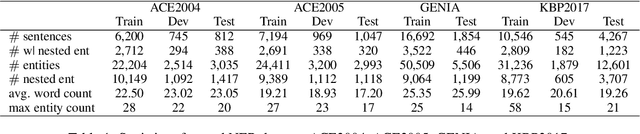
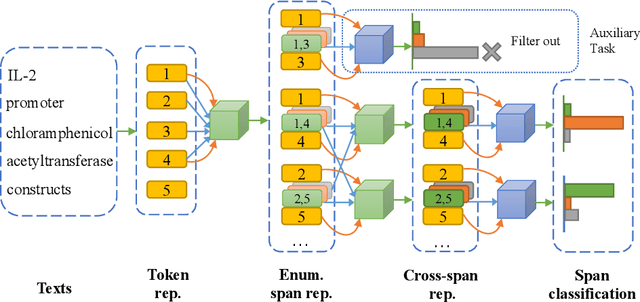
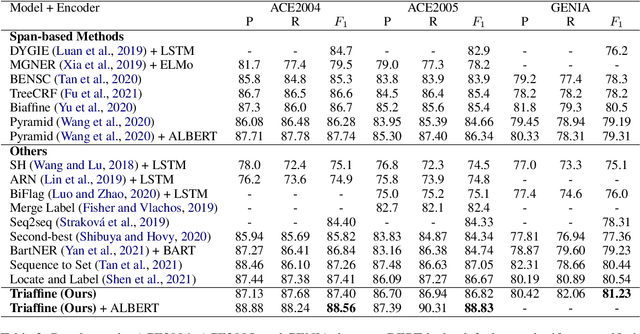
Nested entities are observed in many domains due to their compositionality, which cannot be easily recognized by the widely-used sequence labeling framework. A natural solution is to treat the task as a span classification problem. To increase performance on span representation and classification, it is crucial to effectively integrate all useful information of different formats, which we refer to heterogeneous factors including tokens, labels, boundaries, and related spans. To fuse these heterogeneous factors, we propose a novel triaffine mechanism including triaffine attention and scoring, which interacts with multiple factors in both the stages of representation and classification. Experiments results show that our proposed method achieves the state-of-the-art F1 scores on four nested NER datasets: ACE2004, ACE2005, GENIA, and KBP2017.
Bottom-Up Constituency Parsing and Nested Named Entity Recognition with Pointer Networks
Oct 11, 2021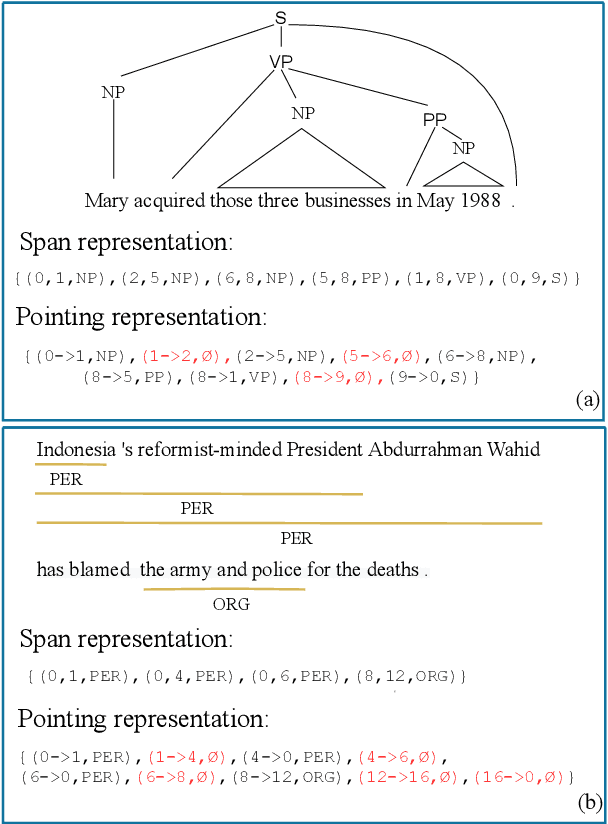

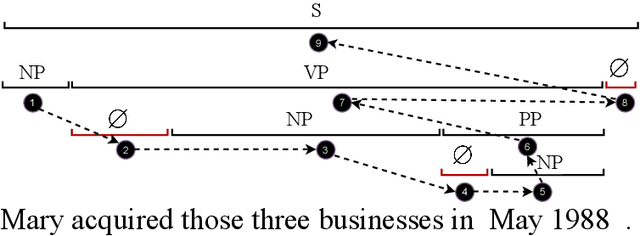
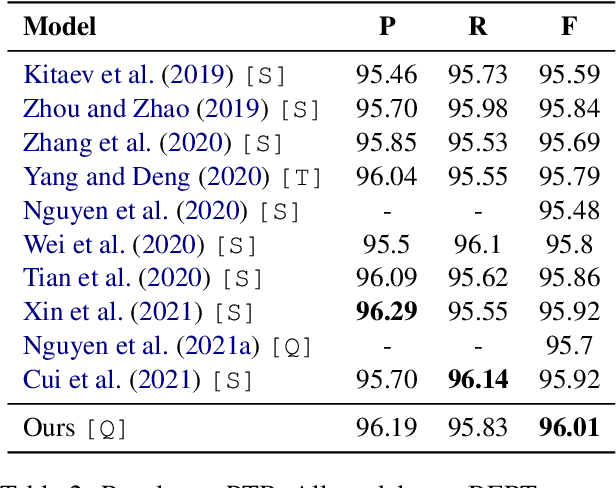
Constituency parsing and nested named entity recognition (NER) are typical \textit{nested structured prediction} tasks since they both aim to predict a collection of nested and non-crossing spans. There are many previous studies adapting constituency parsing methods to tackle nested NER. In this work, we propose a novel global pointing mechanism for bottom-up parsing with pointer networks to do both tasks, which needs linear steps to parse. Our method obtain the state-of-the-art performance on PTB among all BERT-based models (96.01 F1 score) and competitive performance on CTB7 in constituency parsing; and comparable performance on three benchmark datasets of nested NER: ACE2004, ACE2005, and GENIA. Our code is publicly available at \url{https://github.com/sustcsonglin/pointer-net-for-nested}
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023



Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.
End-to-End Entity Detection with Proposer and Regressor
Oct 19, 2022
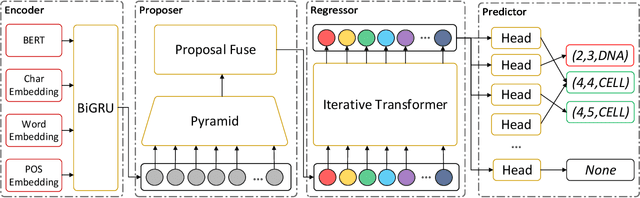
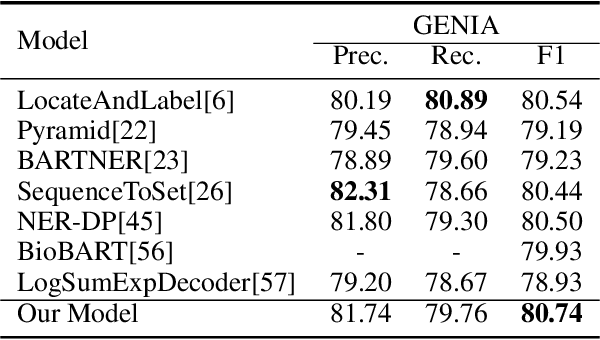
Named entity recognition is a traditional task in natural language processing. In particular, nested entity recognition receives extensive attention for the widespread existence of the nesting scenario. The latest research migrates the well-established paradigm of set prediction in object detection to cope with entity nesting. However, the manual creation of query vectors, which fail to adapt to the rich semantic information in the context, limits these approaches. An end-to-end entity detection approach with proposer and regressor is presented in this paper to tackle the issues. First, the proposer utilizes the feature pyramid network to generate high-quality entity proposals. Then, the regressor refines the proposals for generating the final prediction. The model adopts encoder-only architecture and thus obtains the advantages of the richness of query semantics, high precision of entity localization, and easiness for model training. Moreover, we introduce the novel spatially modulated attention and progressive refinement for further improvement. Extensive experiments demonstrate that our model achieves advanced performance in flat and nested NER, achieving a new state-of-the-art F1 score of 80.74 on the GENIA dataset and 72.38 on the WeiboNER dataset.
Type-supervised sequence labeling based on the heterogeneous star graph for named entity recognition
Oct 19, 2022

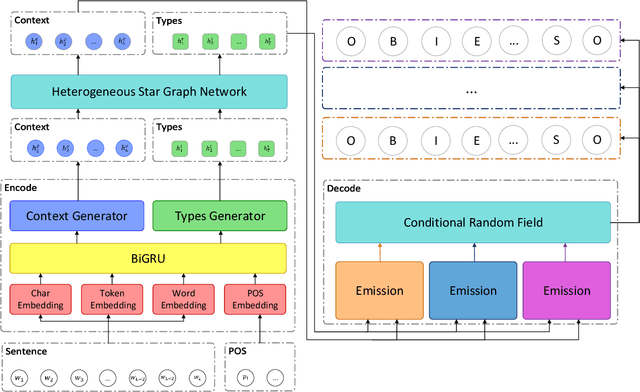
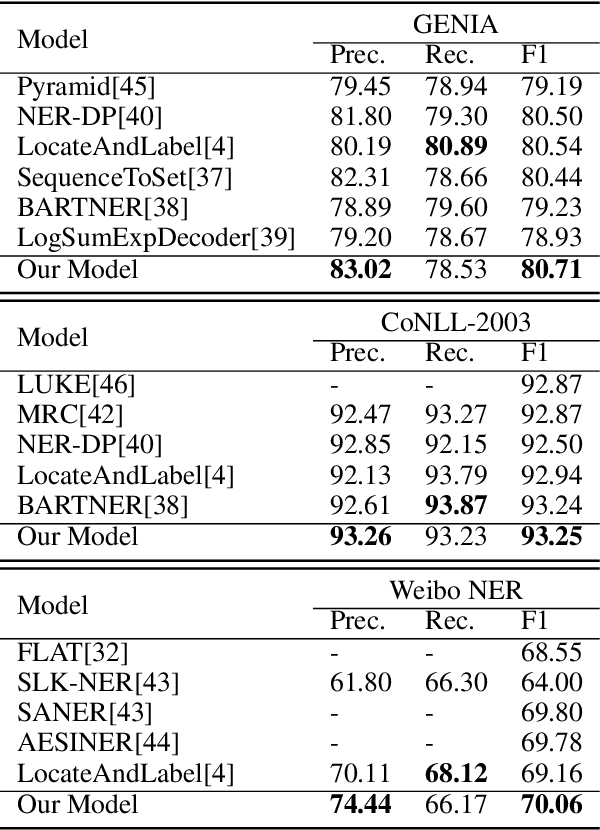
Named entity recognition is a fundamental task in natural language processing, identifying the span and category of entities in unstructured texts. The traditional sequence labeling methodology ignores the nested entities, i.e. entities included in other entity mentions. Many approaches attempt to address this scenario, most of which rely on complex structures or have high computation complexity. The representation learning of the heterogeneous star graph containing text nodes and type nodes is investigated in this paper. In addition, we revise the graph attention mechanism into a hybrid form to address its unreasonableness in specific topologies. The model performs the type-supervised sequence labeling after updating nodes in the graph. The annotation scheme is an extension of the single-layer sequence labeling and is able to cope with the vast majority of nested entities. Extensive experiments on public NER datasets reveal the effectiveness of our model in extracting both flat and nested entities. The method achieved state-of-the-art performance on both flat and nested datasets. The significant improvement in accuracy reflects the superiority of the multi-layer labeling strategy.